Intro to Data Science
INFO 180 book
2025-11-26
Chapter 1 Introduction
This is a collection of reading notes for INFO180 class. This is an introductory data science class, assuming no prerequisites, including mathematics or coding. It covers certain coding concepts and certain mathematics, but at a very superficial level.
The compiled version of the text is at my UW faculty page.
The text are licensed as CC BY 4.0. The images are Public Domain CC0 1.0, unless marked otherwise. See the readme files in the corresponding repo folder.
1.1 What does this book cover?
The aim of the book is to introduce students to the topic of “data analysis”. It aims to be less technical than many other similar texts with only extremely superficial mathematics and very superficial coding. In particular, we do not introduce the traditional coding constructs like loops and conditional execution, and rely solely on dplyr pipelines. However, in order to cope with the different data types (numbers, strings, vectors and data frames), we still need to cover certain coding technicalities.
## [1] 0.0000 512.3292dplyr pipelines offer an intuitive way of doing data analysis. Here: a) take Titanic data; b) pull out variable “fare”; and c) compute its range. Who were those passengers who paid zero pounds for a 2-week trip?
More space is devoted to data quality and reliability issues, such as missing values, data origin, unrealistic values, sampling, and such. The students should aquire a critical attitude to datasets–not all data is useful, and telling if any particular dataset is good requires quite a bit of work and knowledge. A related topic is suitability of datasets to answer certain questions. One should realize that most datasets are not well suited to answer most questions, some questions cannot be answered on any realistically available data, and others need expensive and complicated work.
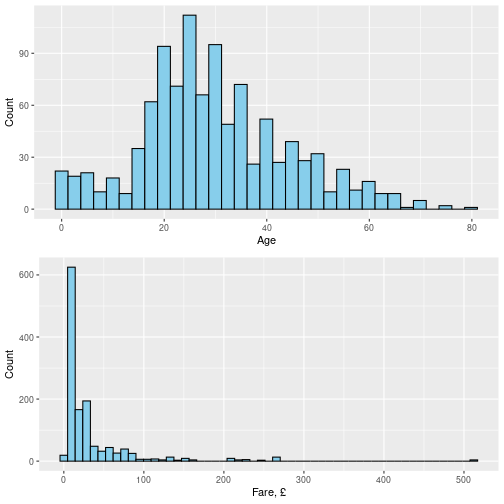
Distribution of passengers’ age and fare paid on Titanic. Why are these two distributions so different?
We’ll analyze datasets through descriptive statistics, visualizations and regression models. All these topics remain superficial as our focus is not on the details of the methods but broad understanding–what can the methods do and what they cannot and why certain values look different from others.
The final topic here is predictive modeling and model goodness evaluation. Extra time is devoted to classification and confusion matrix, in particular about Type-1 and Type-2 errors. Which of these errors are more important for any particular problem?
I am grateful for Zoe Huang for help with the images.