Chapter 10 Web Scraping
Most webpages are designed for humans to look and read. But sometimes we do not want to look and read, but collect the data from the pages instead. This is called web scraping. The challenge with web scraping is getting the data out of pages that are not designed for this purpose.
Most webpages are designed for humans to look and read. But sometimes we do not want to look and read, but collect the data from the pages instead. This is called web scraping. The challenge with web scraping is getting the data out of pages that are not designed for this purpose.
10.1 Before you begin
Web scraping means extracting data from the “web”. However, web is not just an anonymous internet “out there” but a conglomerat of servers and sites, built and maintained by individuals, businesses and governments. Extracting data from there inevitably means using the resources and knowledge someone else has put into the websites. So we have to be careful from both legal and ethical perspective.
From the ethical side, you should try to minimize the problems you cause to the websites you are scraping. This involves the following steps:
limit the number of queries to the necessary minimum. For instance, when developing your code, download the webpage once, and use the cached version for developing and debugging. Do not download more before you actually need more for further development. Do the full scrape only after the code as been well-enough tested. Store the final results in a local file.
limit the frequency of queries to something the server can easily handle. For a small non-profit, consider to send only a handful of requests per minute, while a huge business like google can easily handle thousands of requests per second (but they may recognize you scraping and block you).
consult the robots.txt file and understand what is allowed, what is not allowed. Do not download pages that the file does not allow to scrape.
robots.txt is a text file with simple commands for web crawlers, describing what the robots should and should not do. The file can obtained by adding robots.txt at the end of the base url of the website. For instance, the robots.txt for the web address https://ischool.uw.edu/events is at https://ischool.uw.edu/robots.txt as the base url is https://ischool.uw.edu. A robots.txt file may look like:
User-agent: *
Allow: /core/*.css$
Disallow: /drawer/This means all crawlers (user agent *) are allowed to read all files
ending with css in core,
e.g. https://ischool.uw.edu/core/main.css. But they are not allowed
to read anything from drawer,
e.g. https://ischool.uw.edu/drawer/schedule.html. There are various
simple introductions to robots.txt, see for instance
moz.com.
A related issue is legality. You should only scrape websites and services where it is legal. But in recent years it is getting more and more common for the sites to explicitly ban it. For instance, allrecipes.com states in Terms of Service that:
(e) you shall not use any manual or automated software, devices or
other processes (including but not limited to spiders, robots,
scrapers, crawlers, avatars, data mining tools or the like) to
"scrape" or download data from the Services ...Some websites permit downloading for “personal non-commercial use”. GitHub states in its Acceptable Use Policies that
You may scrape the website for the following reasons:
* Researchers may scrape public, non-personal information from the
Service for research purposes, only if any publications resulting
from that research are open access.
* Archivists may scrape the Service for public data for archival purposes.
You may not scrape the Service for spamming purposes, including for
the purposes of selling User Personal Information (as defined in the
GitHub Privacy Statement), such as to recruiters, headhunters, and job
boards.
All use of data gathered through scraping must comply with the GitHub
Privacy Statement.
There is also a plethora of websites that do not mention downloading, robots and scraping. Scraping such pages is a legally gray area. Other websites that are concerned with what happens to the scraped data. Feasting at home states:
You may NOT republish my recipe(s). I want Feasting at Home to
remain the exclusive source for my recipes. Do not republish on
your blog, printed materials, website, email newsletter or even on
social media- always link back to the recipe.
Again, my recipes are copyrighted material and may not be
published elsewhere.While the legal issues may feel like a nuisance for a technology enthusiast, web scraping touches genuine questions about property rights, privacy, and free-riding. After all, many website creators have done a real effort and spent non-trivial resources to build and maintain the website. They may make the data available for browsers (not scrapers!) to support their business plan. But scrapers do not help with their business plan, and in some case may forward the data to a competitor instead.
In certain cases it also rises questions of privacy. Scraping even somewhat personal data (say, public social media profiles) for a large number of people and connecting this data with other resources may be a privacy violation. If you do this for research purposes, you should store the scraped data in a secure location, and not attempt to identify the real people in data!
In conclusion, before starting your first scraping project, you should answer these questions:
- Is it ethical to download and use the data for the purpose I have in mind?
- What can I do to minimize burden to the service providers?
- Is it legal?
- How should I store and use data?
10.2 HTML Basics
This section introduces basics of HTML. If you are familiar with HTML then you can safely skip forward to Beautiful Soup section.
HTML (hypertext markup language) is a way to write text using tags and attributes to mark the text structure. HTML is the standard language of internet, by far the most webpages are written in html and hence one needs to understand some HTML in order to be able to process the web. Below we briefly discuss the most important structural elements from the web scraping point of view.
10.2.2 Overall structure
A valid html document contains the doctype declaration, followed by
<html> tag (see the example below).
Everything that is important from the scraping
perspective is embedded in the html-element. Html-element in turn
contains two elements: head and body. Head contains various
header information, including the page title, stylesheets and other general
information. Body contains all the text and other visual elements
that the browser actually displays. So a minimalistic html-file might
look like:
<!DOCTYPE html>
<html>
<head>
<title>Mad Monk Ji Gong</title>
</head>
<body>
<h1>Ji Visits Buddha</h1>
<p>Ji Gong went to visit Buddha</p>
</body>
</html>This tiny file demonstrates all the structure we have discussed so far:
- The first declaration in the file is DOCTYPE entry.
- All the content is embedded in the html-element.
- The html-element contains head and body elements.
- head includes element title, the title of the webpage. This is not what you see on the page, but browser may show it on the window or tab title bar, and it may use it as the file name when you download and save the page.
- The standard structure ends with body. It is the most important part of the page, almost all of the page content is here. How exactly the body is set up differs between the webpages, there is no standard structure. In this example body-element contains two elements: h1, this is the top title that is actually rendered on screen (typically big and bold), and a paragraph of text.
Because HTML elements are nested inside each other, we can depict an HTML page as a tree. The html element is the trunk that branches into two, head and body; and body in turn branches into other elements. Thinking about the page as a tree is a extremely useful way when designing code to navigate it.
10.2.4 Html tables
A lot of data on html pages is in form of tables, marked with tag table. Webscrapers may also have special functionality to automatically convert html tables to data frames. The basic tables are fairly simple. The table contains thead element with column names and tbody element with the values. Each row in the table is tr element, each header cell (column names) is th element, and each value cell is td element. Here is a simple table for course grading system:
<table>
<thead>
<tr>
<th>Task</th>
<th>How many</th>
<th>pt each</th>
</tr>
</thead>
<tbody>
<tr>
<td>Assignments</td>
<td>8</td>
<td>9</td>
</tr>
<tr>
<td>Labs</td>
<td>8</td>
<td>1</td>
</tr>
</tbody>
</table>This table contains three colums and three rows, one of which is the header. In the rendered form it looks something like this (but it depends on the exact layout formatting):
| Task | How many | pt each |
|---|---|---|
| Assignments | 8 | 9 |
| Labs | 8 | 1 |
The default formatting is fairly unimpressive, more advanced webpages typically add custom formatting using CSS styles.
This basic introduction is enough to help you to understand the webpages from the scraping perspective. There are many good sources for further information, you may consider W3Schools for html and css tutorials, and W3C for detailed html specifications.
10.3 Web scraping in R and the rvest package
rvest is probably the most popular package for webscraping in R. It
is a powerful and easy-to-use package but unfortunately its
documentation is rather sparse.
In
essence it is an HTML parser with added functionality to search tags,
classes and attributes, and move up and down in the HTML tree.
Normally one scrapes web by downloading the pages from the internet
(one can use read_html function) and thereafter parses the pages using
rvest. The most complex step is to navigate the parsed html
structure to locate the correct elements.
rvest library follows the common tidyverse style and works perfectly with magrittr pipes. We load it with
library(rvest)rvest is relying heavily on another package, xml2 and although the main functionality is accessible without explicitly loading xml2 package, we may get some additional tools when we load that one. See removing elements below.
10.3.1 Example html file
In the following we demonstrate the usage of the library on the following html file:
<!DOCTYPE html>
<html>
<head>
<title>Mad Monk Ji Gong</title>
</head>
<body>
<h1>Li Visits Buddha</h1>
<p>This happened
during <a href="https://en.wikipedia.org/wiki/Song_dynasty">Song Dynasty</a>.
The patchwork robe made for <strong>Guang Liang</strong>...</p>
<h2>Li Begs for a Son</h2>
<p class="quote">When I wa strolling in the street,
<footnote>They lived in Linan</footnote> almost
everyone was calling me
<span class="nickname">Virtuous Li</span> ...</p>
<h2>Dynasties</h2>
<div style="align:center;">
<table>
<thead>
<tr>
<th>Dynasty</th>
<th>years</th>
</tr>
</thead>
<tbody>
<tr>
<td>Song</td>
<td>960--1279</td>
</tr>
<tr>
<td>Yuan</td>
<td>1271--1368</td>
</tr>
</tbody>
</table>
</div>
</body>
</html>This file includes a number of common html tags and attributes and a suitably rich structure for explaining the basics of web scraping. If you want to follow the examples, then you may copy the file from here and save it as “scrape-example.html”, or download it directly from the repo.
10.3.2 First part: download the webpage
A more serious web scraping project typically begins with finding the
correct page and understanding its structure as the structure
may not be obvious in case of more complex websites. However, we
leave this task later, see Finding elements on
webpage below. Instead, we
immediately get hands dirty and download the page.
Normally we do it using read_html function as
page <- read_html("https://www.example.com")But this time we extract data from a local file so we use the
file name, not the webpage url.
read_html can read various inputs including the webpages and files,
the entry is assumed to be a webpage if it begins with “http://” or a
similar protocol marker. (Note: read_html is not part of rvest
but a part of xml2 library but it is
automatically loaded when you load rvest.)
page <- read_html("../files/scrape-example.html")This loads the example file into a variable page.
Now we are done with both downloading and parsing (or loading and
parsing as we just loaded a local file) and we
do not need internet any more.
load_html
also strips the website from its metadata and only returns the html part of the
page. The result can be printed, but it is not designed for humans to be
read:
page## {html_document}
## <html>
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body>\n\t<h1>Li Visits Buddha</h1>\n\t<p>This happened\n\t during <a hr ...The resulting variable page is of class
xml_node. It is structured as a tree and
all our following tasks are about navigating the tree and extracting
the right
information from there.
10.4 Finding elements on webpage
All the examples above were done using a very simple webpage. But modern website are often much more complex. How can one locate the elements of interest in the source?
For simple webpages one can just look at the page source in the browser, or open the html document in a text editor. If you understand the source, you can be translate it into a way to navigate and parse the html tree. But modern complex pages are often very complicated and hard to understand by just consulting the source.
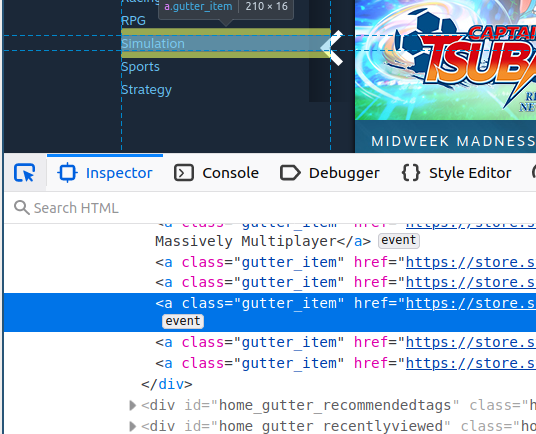
For complex pages, the easiest approach is to use web browser’s developer tools. Modern browser, such as Firefox and Chrome, contain web developers’ tools. These can be invoked by Ctrl-Shift-I in both Firefox and Chromium (Linux and Windows) or Cmd-option-I (⌘ - ⌥ - I) (Mac6). These tools are excellent means to locate elements of interest on the page.
A particularly useful tool is element picker
(labeled ![]() both in
Firefox and Chromium) that lets you to point html elements in the
browser window, and highlights the corresponding lines in the
html source.
In the figure at right one can see that the
menu links are contained in an a element with class “gutter_item”. If
we are interested in scraping the menu, we may try to locate such
elements in the parsed html tree.
both in
Firefox and Chromium) that lets you to point html elements in the
browser window, and highlights the corresponding lines in the
html source.
In the figure at right one can see that the
menu links are contained in an a element with class “gutter_item”. If
we are interested in scraping the menu, we may try to locate such
elements in the parsed html tree.
However, this approach only works if both browser and scraper actually download the same page. If browser shows you the javascript-enabled version targeted for your powerful new browser, but scraper gets a different version for non-javascript crawlers, one has to dive deeper into the developer tools and fool the website to send the crawler version to the browser too.
Finally, one can always just download the page, parse its html and walk through the various elements in a search for the data in question. But this is often tedious for even small pages.
It works on Safari but you have to explicitly allow developer tools in preferences.↩︎