
A History of Interfaces
In a rapidly evolving field of augmented reality, driverless cars, and rich social media, is there any more mundane way to start a book on user interfaces than history? Probably not. And yet, for a medium that is invented entirely from imagination, the history of user interfaces is reminder that the interactive world we experience today could have been different. Files, keyboards, mice, and touchscreens—all of these concepts were invented to solve very real challenges with interacting with computers, and but for a few important people and places in the 20th century, we might have invented entirely different ways of interacting with computers 2 .
Computing began as an idea: Charles Babbage, a mathematician, philosopher, and inventor in London in the early 19th century, began imagining a kind of mechanical machine that could automatically calculate mathematical formulas. He called it the “Analytical Engine”, and conceived of it as a device that would encode instructions for calculations. Taking arbitrary data encoded as input on punch cards, this engine would be able to quickly and automatically calculate formulas much faster than people. And indeed, at the time, people were the bottleneck: if a banker wanted a list of numbers to be added, they needed to hire a computer—a person that quickly and correctly performed arithmetic—to add them. Babbage’s “Analytical Engine” promised to do the work of (human) computers much more quickly and accurately. Babbage later mentored Ada Lovelace, the daughter of a wealthy aristocrat; Lovelace loved the beauty of mathematics, and was enamored by Babbage’s vision, publishing the first algorithms intended to executed by such a machine. Thus began the age of computing, shaped largely by values of profit but also the beauty of mathematics.

While no one ever succeeded in making a mechanical analytical engine, one hundred years later, electronic technology made digital ones possible 3 . But Babbage’s vision of using punch cards for input remained intact: if you used a computer, it meant constructing programs out of individual machine instructions like add, subtract, or jump, and encoding them onto punch cards to be read by a mainframe. And rather than being driven by a desire to lower costs and increase profit in business, these computers were instruments of war, decrypting German secret messages and more quickly calculating ballistic trajectories.
As wars came to a close, some found the vision of computers as business and war machines too limiting. Vannevar Bush , a science administrator who headed the U.S. Office of Scientific Research and Development, had a much bigger vision. He wrote a 1945 article in The Atlantic Monthly , called “As We May Think.” In it, he envisioned a device called the “Memex” in which people could store all of their information, including books, records, and communications, and access them with speed and flexibility 1 . Notably, Bush imagined the Memex as an “enlarged intimate supplement to one’s memory.” This vision, far from being driven by defense or business, was driven by a dream of human augmentation, expanding our abilities as a species to learn, think, and understand through information.
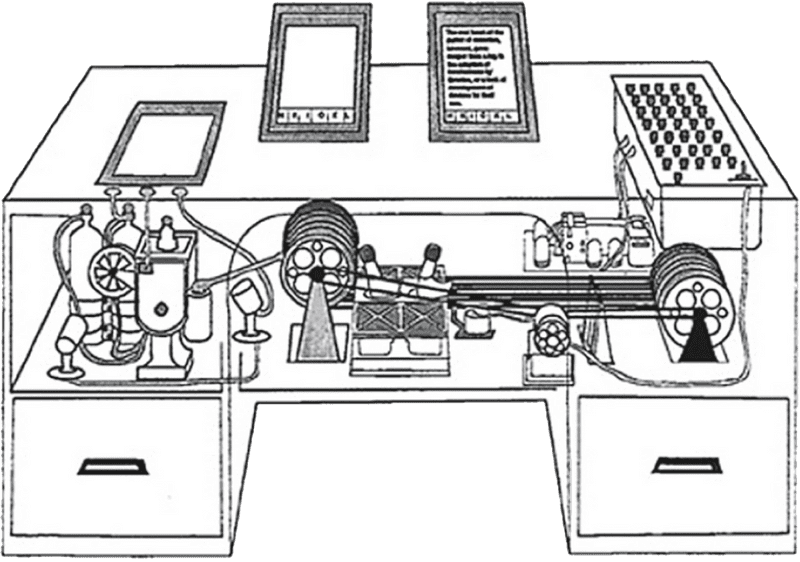
Here is how Bush described the Memex:
Consider a future device for individual use, which is a sort of mechanized private file and library. It needs a name, and, to coin one at random, “memex” will do. A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory... Wholly new forms of encyclopedias will appear, ready made with a mesh of associative trails running through them, ready to be dropped into the memex and there amplified. The lawyer has at his touch the associated opinions and decisions of his whole experience, and of the experience of friends and authorities. The patent attorney has on call the millions of issued patents, with familiar trails to every point of his client’s interest. The physician, puzzled by a patient’s reactions, strikes the trail established in studying an earlier similar case, and runs rapidly through analogous case histories, with side references to the classics for the pertinent anatomy and histology. The chemist, struggling with the synthesis of an organic compound, has all the chemical literature before him in his laboratory, with trails following the analogies of compounds, and side trails to their physical and chemical behavior.
Does this remind you of anything? The internet, hyperlinks, Wikipedia, networked databases, social media. All of it is there in this prescient description of human augmentation, including rich descriptions of the screens, levers, and other controls for accessing information.
J.C.R. Licklider, an American psychologist and computer scientist, was fascinated by Bush’s vision, writing later in his “Man-Computer Symbiosis” 4 .
...many problems that can be thought through in advance are very difficult to think through in advance. They would be easier to solve, and they could be solved faster, through an intuitively guided trial-and-error procedure in which the computer cooperated, turning up flaws in the reasoning or revealing unexpected turns in the solution. Other problems simply cannot be formulated without computing-machine aid. Poincare anticipated the frustration of an important group of would-be computer users when he said, “The question is not, ‘What is the answer?’ The question is, ‘What is the question?’” One of the main aims of man-computer symbiosis is to bring the computing machine effectively into the formulative parts of technical problems.
He then talked about visions of a “thinking center” that “ will incorporate the functions of present-day libraries together with anticipated advances in information storage and retrieval ,” connecting individuals and computers through desk displays, wall displays, speech production and recognition, and other forms of artificial intelligence. In his role in the United States Department of Defense Advanced Research Projects Agency and as a professor at MIT, Licklider funded and facilitated the research that eventually led to the internet and the graphical user interface.
One person that Bush and Licklider’s ideas influenced was MIT computer scientist Ivan Sutherland . He followed this vision of human augmentation by exploring interactive sketching on computers, working on a system called Sketchpad for his dissertation 7 . Sketchpad, seen in the video below, allowed drawing of segments, arcs, and constraints between shapes. Shapes could be transformed, resized, repositioned, and clipped, and a notion of windowing allowed zooming and panning. The entire interactive experience was stylus-based and the implementation paradigm was object-based. This was the first system to ever demonstrate an interactive dialog with a computer, rather than a “batch processing” programming-based interaction. You can see Sketchpad in action in the video below.
Sketchpad and Bush and Licklider’s article inspired Douglas Engelbart to found the Augmentation Research Center at the Stanford Research Institute (SRI) in the early 1960’s. Over the course of about six years, with funding from NASA and the U.S. Defense Department’s Advanced Research Projects Agency (known today as DARPA), Engelbart and his team prototyped the “oN-Line System” (or the NLS), which attempted to engineer much of Bush’s vision. NLS had networking, windows, hypertext, graphics, command input, video conferencing, the computer mouse, word processing, file version control, text editing, and numerous other features of modern computing. Engelbart himself demoed the system to a live audience in what is often called “The Mother of all Demos.” You can see the entire demonstration in the below above.
Engelbart’s research team eventually disbanded and many of them ended up at the Xerox Palo Alto Research Center (Xerox PARC). Many were truly inspired by the demo and wanted to use the freedom Xerox had given them to make the NLS prototype a reality. One of the key members of this team was Alan Kay , who had worked with Ivan Sutherland and seen Engelbart’s demo. Kay was interested in ideas of objects, object-oriented programming, and windowing systems, and created the programming language and environment Smalltalk. He was a key member of a team at PARC that developed the Alto in the mid 1970’s. The Alto included the first operating system based on a graphical user interface with a desktop metaphor, and included WYSIWYG word processing, an email client, a vector graphics editor, a painting program, and a multi-player networked video game.
Now, these were richly envisioned prototypes, but they were not products. You couldn’t buy an Alto at a store. This changed when Steve Jobs visited Xerox PARC in 1979, where he saw a demo of the Alto’s GUI, its Smalltalk-based programming environment, and its networking. Jobs was particularly excited about the GUI, and recruited several of the Xerox PARC researchers to join Apple, leading to the Lisa and later Macintosh computers, which offered the first mass-market graphical user interfaces. Apple famously marketed the Macintosh in its 1984 advertisement, framing the GUI the first salvo in a war against Big Brother, a reference to the book, 1984 .
As the Macintosh platform expanded, it drew many innovators, including many Silicon Valley entreprenuers with ideas for how to make personal computers even more powerful. This included ideas like presentation software such as PowerPoint , which grew out of the same Xerox PARC vision of what-you-see-is-what-you-get text and graphics manipulation.
Since the release of the Macintosh, companies like Apple, Microsoft, and now Google have driven much of the engineering of user interfaces, deviating little from the original visions inspired by Bush, Licklider, Sutherland, Engelbart, and Kay. But governments and industry continued to harvest basic research for new paradigms of interaction, including the rapid proliferation of capacitive touch screens in the early 2000’s in smartphones 6 . Around the same time as the release of the Macintosh, many computer scientists who had worked in computer graphics (a field started by Sutherland) spun off a new conference in 1988, the ACM Symposium on User Interface Software and Technology . This community brought together researchers interested in not only the useful output that computers could produce, but also the novel forms of input , and the interaction paradigms that combinations of input and output could produce. This community has since worked alongside industry, establishing the basic paradigms for graphical user interfaces, while continuing to invent new ways of interacting with computers, including paradigms such as augmented reality, touchscreens, more efficient text entry, and animation 5,8,9 .
Reflecting on this history, one of the most remarkable things is how powerful one vision was to catalyze an entire world’s experience with computers. Is there something inherently fundamental about networked computers, graphical user interfaces, and the internet that was inevitable? Or if someone else had written an alternative vision for computing, would we be having different interactions with computers and therefore different interactions with each other through computing? And is it still possible to imagine different futures of interactive computing that will shape the future yet? This history and these questions remind us that nothing about our interactions with computing is necessarily “true” or “right”: they’re just ideas that we’ve collectively built, shared, and learned—and they can change. In the coming chapters, we’ll uncover what is fundamental about user interfaces and explore alternative visions of interacting with computers that may require new fundamentals.
References
-
Vannevar Bush (1945). As we may think. The Atlantic Monthly, 176(1), 101-108.
-
Stuart K. Card, Thomas P. Moran (1986). User technology: From pointing to pondering. ACM Conference on the History of Personal Workstations.
- James Gleick and Rob Shapiro (2011). The Information
-
J. C. R. Licklider (1960). Man-Computer Symbiosis. IRE Transactions on Human Factors in Electronics.
-
Brad Myers, Scott E. Hudson, Randy Pausch (2000). Past, Present and Future of User Interface Software Tools. ACM Transactions on Computer-Human Interaction.
-
Brad A. Myers (1998). A brief history of human-computer interaction technology. ACM interactions.
-
Ivan Sutherland (1963). Sketchpad, A Man-Machine Graphical Communication System. Massachusetts Institute of Technology, Introduction by A.F. Blackwell & K. Rodden. Technical Report 574. Cambridge University Computer Laboratory.
-
Andries van Dam (1997). Post-WIMP user interfaces. Communications of the ACM.
-
Mark Weiser (1991). The Computer for the 21st Century. Scientific American 265, 3 (September 1991), 94-104.
A Theory of Interfaces
First history and now theory? What a way to start a practical book about user interfaces. But as social psychologist Kurt Lewin said, “There’s nothing as practical as a good theory” 6 .
Let’s start with why theories are practical. Theories, in essence, are explanations for what something is and how something works. These explanatory models of phenomena in the world help us not only comprehend the phenomena, but also predict what will happen in the future with some confidence, and perhaps more importantly, they give us a conceptual vocabulary to exchange ideas about the phenomena. A good theory about user interfaces would be practical because it would help explain what user interface are, and what governs whether they are usable, learnable, efficient, error-prone, etc.
HCI researchers have written a lot about theory, including theories from other disciplines, and new theories specific to HCI 5,9 . There are theories of activities, conceptual models, design processes, experiences, information seeking, work, symbols, communication, and countless other aspects of people’s interaction with computers. Most of these are theories about people and their behavior in situations where computers are critical, but the interaction with computers is not the primary focus. The theory I want to share, however, is about user interfaces at the center, and the human world at the periphery.

What are interfaces?
Let’s begin with what user interfaces are . User interfacesuser interface: A special kind of software designed to map human activities in the physical world (clicks, presses, taps, speech, etc.) to functions defined in a computer program. are software and/or hardware that bridge the world of human action and computer action . The first world is the natural world of matter, motion, sensing, action, reaction, and cognition, in which people (and other living things) build models of the things around them in order to make predictions about the effects of their actions. It is a world of stimulus, response, and adaptation. For example, when an infant is learning to walk, they’re constantly engaged in perceiving the world, taking a step, and experiencing things like gravity and pain, all of which refine a model of locomotion that prevents pain and helps achieve other objectives. Our human ability to model the world and then reshape the world around us using those models is what makes us so adaptive to environmental change. It’s the learning we do about the world that allows us to survive and thrive in it. Computers, and the interfaces we use to operate them, are one of the things that humans adapt to.
The other world is the world of computing. This is a world ultimately defined by a small set of arithmetic operations such as adding, multiplying, and dividing, and an even smaller set of operations that control which operations happen next. These instructions, combined with data storage, input devices to acquire data, and output devices to share the results of computation, define a world in which there is only forward motion. The computer always does what the next instruction says to do, whether that’s reading input, writing output, computing something, or making a decision. Sitting atop these instructions are functionsfunction: An idea from mathematics of using algorithms to map some input (e.g., numbers, text, or other data), to some output. Functions can be as simple as basic arithmetic (e.g., multiply , which takes two numbers and computes their product), or as complex as machine vision ( object recognition , which takes an image and a machine learned classifier trained on millions of images and produces a set of text descriptions of objects in the image. , which take input and produce output using some algorithms. Essentially all computer behavior leverages this idea of a function, and the result is that all computer programs (and all software) are essentially collections of functions that humans can invoke to compute things and have effects on data. All of this functional behavior is fundamentally deterministic; it is data from the world (content, clocks, sensors, network traffic, etc.), and increasingly, data that models the world and the people in it, that gives it its unpredictable, sometimes magical or intelligent qualities.
Now, both of the above are basic theories of people and computers. In light of this, what are user interfaces? User interfaces are mappings from the sensory, cognitive, and social human world to computational functions in computer programs. For example, a save button in a user interface is nothing more than an elaborate way of mapping a person’s physical mouse click or tap on a touch screen to a command to execute a function that will take some data in memory and permanently store it somewhere. Similarly, a browser window, displayed on a computer screen, is an elaborate way of taking the carefully rendered pixel-by-pixel layout of a web page, and displaying it on a computer screen so that sighted people can perceive it with their human perceptual systems. These mappings from physical to digital, digital to physical, are how we talk to computers.
Learning interfaces
If we didn’t have user interfaces to execute functions in computer programs, it would still be possible to use computers. We’d just have to program them using programming languages (which, as we discuss later in Programming Interfaces , can be hard to learn). What user interfaces offer are more learnable representations of these functions, their inputs, their algorithms, and their outputs, so that a person can build mental models of these representations that allow them to sense, take action, and achieve their goals, as they do with anything in the natural world. However, there is nothing natural about user interfaces: buttons, scrolling, windows, pages, and other interface metaphors are all artificial, invented ideas, designed to help people use computers without having to program them. While this makes using computers easier, interfaces must still be learned.
Don Norman, in his book, The Design of Everyday Things 8 , does a nice job giving labels to some of the challenges that arise in this learning. One of his first big ideas is the gulf of executiongulf of execution: Everything a person must learn in order to acheive their goal with an interface, including learning what the interface is and is not capable of and how to operate it correctly. . Gulfs of execution are gaps between the user’s goal and the input they have to provide to achieve it. To illustrate, think back to the first time you used a voice user interface, such as a personal assistant on your smartphone or an automated voice interface on a phone. In that moment, you experienced a gulf of execution: what did you have to say to the interface to achieve your goal? What concepts did you have to learn to understand that there was a command space and a syntax for each command? You didn’t have the concepts to even imagine those actions. Someone or something had to “bridge” that gulf of execution, teaching you some of the actions that were possible and how those actions mapped onto your goals. (They probably also had to teach you the goals, but that’s less about user interfaces and more about culture). Learning is therefore at the heart of both using user interfaces and designing them 3 .
What is it that people need to learn to take action on an interface? Norman (and later Gaver 2 , Hartson 4 , and Norman again 8 ), argued that what we’re really learning is affordancesaffordance: The potential for action in an interface, ultimately defined by what underlying functionalty it has been designed and engineered to support. . An affordance is a relationship between a person and a property of what can be done to an interface in order to produce some effect. For example, a physical computer mouse can be clicked, which allows information to be communicated to a computer. A digital personal assistant like Amazon’s Alexa can be invoked by saying “Alexa”. However, these are just a property of a mouse and Alexa; affordances arise when a person recognizes that opportunity and knows how to act upon it.

How can a person know what affordances an interface has? That’s where the concept of a signifiersignifier: Any indicator of an affordance in an interface. becomes important. Signifiers are any sensory or cognitive indicator of the presence of an affordance. Consider, for example, how you know that a computer mouse can be clicked. It’s physical shape might evoke the industrial design of a button. It might have little tangible surfaces that entreat you to push your finger on them. A mouse could even have visual sensory signifiers, like a slowly changing colored surface that attempts to say, “ I’m interactive, try touching me. ” These are mostly sensory indicators of an affordance. Personal digital assistants like Alexa, in contrast, lack most of these signifiers. What about an Amazon Echo says, “ You can say Alexa and speak a command? ” In this case, Amazon relies on tutorials, stickers, and even television commercials to signify this affordance.
While both of these examples involve hardware, the same concepts of affordance and signifier apply to software too. Buttons in a graphical user interface have an affordance: if you click within their rectangular boundary, the computer will execute a command. If you have sight, you know a button is clickable because long ago you learned that buttons have particular visual properties such as a rectangular shape and a label. If you are blind, you might know a button is clickable because your screen reader announces that something is a “button” and reads its label. All of this requires you knowing that interfaces have affordances such as buttons that are signified by a particular visual motif. Therefore, a central challenge of designing a user interface is deciding what affordances an interface will have and how to signify that they exist.
But execution is only half of the story. Norman also discussed gulfs of evaluationgulf of evaluation: Everything a person must learn in order to understand the effect of their action on an interface, including understanding error messages or a lack of response from an interface. , which are the gaps between the output of a user interface and a user’s goal. Once a person has performed some action on a user interface via some functional affordance, the computer will take that input and do something with it. It’s up to the user to then map that feedback onto their goal. If that mapping is simple and direct, then the gulf is a small. For example, consider an interface for printing a document. If after pressing a print button, the feedback was “ Your document was sent to the printer for printing, ” that would clearly convey progress toward the user’s goal, minimizing the gulf between the output and the goal. If after pressing the print button, the feedback was “ Job 114 spooled, ” the gulf is larger, forcing the user to know what a “ job ” is, what “ spooling ” is, and what any of that has to do with printing their document.
In designing user interfaces, there are many ways to bridge gulfs of execution and evaluation. One is to just teach people all of these affordances and help them understand all of the user interface’s feedback. A person might take a class to learn the range of tasks that can be accomplished with a user interface, steps to accomplish those tasks, concepts required to understand those steps, and deeper models of the interface that can help them potentially devise their own procedures for accomplishing goals. Alternatively, a person can read tutorials, tooltips, help, and other content, each taking the place of a human teacher, approximating the same kinds of instruction a person might give. There are entire disciplines of technical writing and information experience that focus on providing seamless, informative, and encouraging introductions to how to use a user interface. 7
To many user interface designers, the need to explicitly teach a user interface is a sign of design failure. There is a belief that designs should be “self-explanatory” or “intuitive.” What these phrases actually mean are that the interface is doing the teaching rather than a person or some documentation. To bridge gulfs of execution , a user interface designer might conceive of physical, cognitive, and sensory affordances that are quickly learnable, for example. One way to make them quickly learnable is to leverage conventionsconvention: A widely-used and widely-learned interface design pattern (e.g., a web form, a login screen, a hamburger menu on a mobile website). , which are essentially user interface design patterns that people have already learned by learning other user interfaces. Want to make it easy to learn how to add an item to a cart on an e-commerce website? Use a button labeled “ Add to cart, ” a design convention that most people will have already learned from using other e-commerce sites.Alternatively, interfaces might even try to anticipate what people want to do, personalizing what’s available, and in doing so, minimizing how much a person has to learn. From a design perspective, there’s nothing inherently wrong with learning, it’s just a cost that a designer may or may not want to impose on a new user. (Perhaps learning a new interface affords new power not possible with old conventions, and so the cost is justified).
To bridge gulfs of evaluation , a user interface needs to provide feedbackfeedback: Output from a computer program intended to explain what action a computer took in response to a user’s input (e.g., confirmation messages, error messages, or visible updates). that explains what effect the person’s action had on the computer. Some feedback is explicit instruction that essentially teaches the person what functional affordances exist, what their effects are, what their limitations are, how to invoke them in other ways, what new functional affordances are now available and where to find them, what to do if the effect of the action wasn’t desired, and so on. Clicking the “ Add to cart ” button, for example, might result in some instructive feedback like this:
I added this item to your cart. You can look at your cart over there. If you didn’t mean to add that to your cart, you can take it out like this. If you’re ready to buy everything in your cart, you can go here. Don’t know what a cart is? Read this documentation.
Some feedback is implicit, suggesting the effect of an action, but not explaining it explicitly. For example, after pressing “ Add to cart ,” there might be an icon showing an abstract icon of an item being added to a cart, with some kind of animation to capture the person’s attention. Whether implicit or explicit, all of this feedback is still contextual instruction on the specific effect of the user’s input (and optionally more general instruction about other affordances in the user interface that will help a user accomplish their goal).
The result of all of this learning is a mental modelmental model: A person’s beliefs about an interface’s affordances and how to operate them. 1 in a person’s head of what inputs are possible, what outputs those result in, and how all of those inputs and outputs are related to various goals that person might have. However, because human learning is imperfect, and all of people, documentation, and contextual help provided to teach an interface is imperfect, people’s mental models about user interfaces are nearly always imperfect. People end up with brittle, fragile, and partially correct predictive models of what effect their actions in user interfaces will have, and this results in unintended effects and confusion. If there’s no one around to correct the person’s mental model, or the user interface itself isn’t a very good teacher, the person will fail to learn, and get confused and probably frustrated (in the same way you might fumble to open a door with a confusing handle). These episodes of user interface failure, which we can also describe as breakdownsbreakdown: Mistakes and confusion that occur because a user’s mental model is inconsistent with an interface’s actual functionality. , are signs that a user’s mental model is inconsistent with the actual behavior of some software system. In HCI, we blame these breakdowns on designers rather than users, and so we try to maximize the learnability and minimize the error-proneness of user interface designs using usability evaluation methods.
Note that in this entire discussion, we’ve said little about tasks or goals. The broader HCI literature theorizes about those broadly 5,9 , and the gist is this: rarely does a person have such a well-defined goal in their head that tasks can be perfectly defined to fit them. For example, imagine you have a seamless, well-defined interaction flow for adding tissues to shopping carts, and checking out with carts, but a person’s goal was vaguely to “ get some tissues that don’t hurt my skin, but also don’t cost much. ” The breakdown in your user interface may occur long after a person has used your user interface, after a few days of actually using the tissues, finding them uncomfortable, and therefore not worth the cost. Getting the low-level details of user interface design to be learnable is one challenge — designing experiences that support vague, shifting, unobservable human goals is an entirely different one.
Using theory
You have some new concepts about user interfaces, and an underlying theoretical sense about what user interfaces are and why designing them is hard. Let’s recap:
- User interfaces bridge human goals and cognition to functions defined in computer programs.
- To use interfaces successfully, people must learn an interface’s affordances and how they can be used to achiever their goals.
- This learning must come from somewhere, either instruction by people, explanations in documentation, or teaching by the user interface itself.
- Most user interfaces have large gulfs of execution and evaluation, requiring substantial learning.
The grand challenge of user interface design is therefore trying to conceive of interaction designs that have small gulfs of execution and evaluation, while also offering expressiveness, efficiency, power, and other attributes that augment human ability.
These ideas are broadly relevant to all kinds of interfaces, including all those already invented, and new ones invented every day in research. And so these concepts are central to design. Starting from this theoretical view of user interfaces allows you to ask the right questions. For example, rather than trying to vaguely identify the most “intuitive” experience, you can systematically ask: “ Exactly what is our software’s functionality affordances and what signifiers will we design to teach it? ” Or, rather than relying on stereotypes, such as “ older adults will struggle to learn to use computers, ” you can be more precise, saying, “ This particular population of adults has not learned the design conventions of iOS, and so they will need to learn those before successfully utilizing this application’s interface. ”
Approaching user interface design and evaluation from this perspective will help you identify major gaps in your user interface design analytically and systematically, rather than relying only on observations of someone struggling to use an interface, or worse yet, stereotypes or ill-defined concepts such as “intuitive” or “user-friendly.” Of course, in practice, not everyone will know these theories, and other constraints will often prevent you from doing what you know might be right. That tension between theory and practice is inevitable, and something we’ll return to throughout this book.
References
-
Carroll, J. M., Anderson, N. S. (1987). Mental models in human-computer interaction: Research issues about what the user of software knows. National Academies.
-
Gaver, W.W. (1991). Technology affordances. Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI '91). New Orleans, Louisiana (April 27-May 2, 1991). New York: ACM Press, pp. 79-84.
-
Grossman, T., Fitzmaurice, G., & Attar, R. (2009). A survey of software learnability: metrics, methodologies and guidelines. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Rex Hartson (2003). Cognitive, physical, sensory, and functional affordances in interaction design. Behaviour & Information Technology.
-
Jacko, J. A. (2012). Human computer interaction handbook: Fundamentals, evolving technologies, emerging applications. CRC Press.
-
Lewin (1943). Theory and practice in the real world. The Oxford Handbook of Organization Theory.
-
Linda Newman Lior (2013). Writing for Interaction: Crafting the Information Experience for Web and Software Apps. Morgan Kaufmann.
-
Don Norman (2013). The design of everyday things: Revised and expanded edition. Basic Books.
-
Rogers, Y. (2012). HCI theory: classical, modern, contemporary. Synthesis Lectures on Human-Centered Informatics, 5(2), 1-129.

What Interfaces Mediate
In the last two chapters, we considered two fundamental perspectives on user interface software and technology: a historical one, which framed user interfaces as a form of human augmentation, and a theoretical one, which framed interfaces as a bridge between sensory worlds and computational world of inputs, functions, outputs, and state. A third and equally important perspective on interfaces is what role interfaces play in individual lives and society broadly. While user interfaces are inherently computational artifacts, they are also inherently sociocultural and sociopolitical entities.
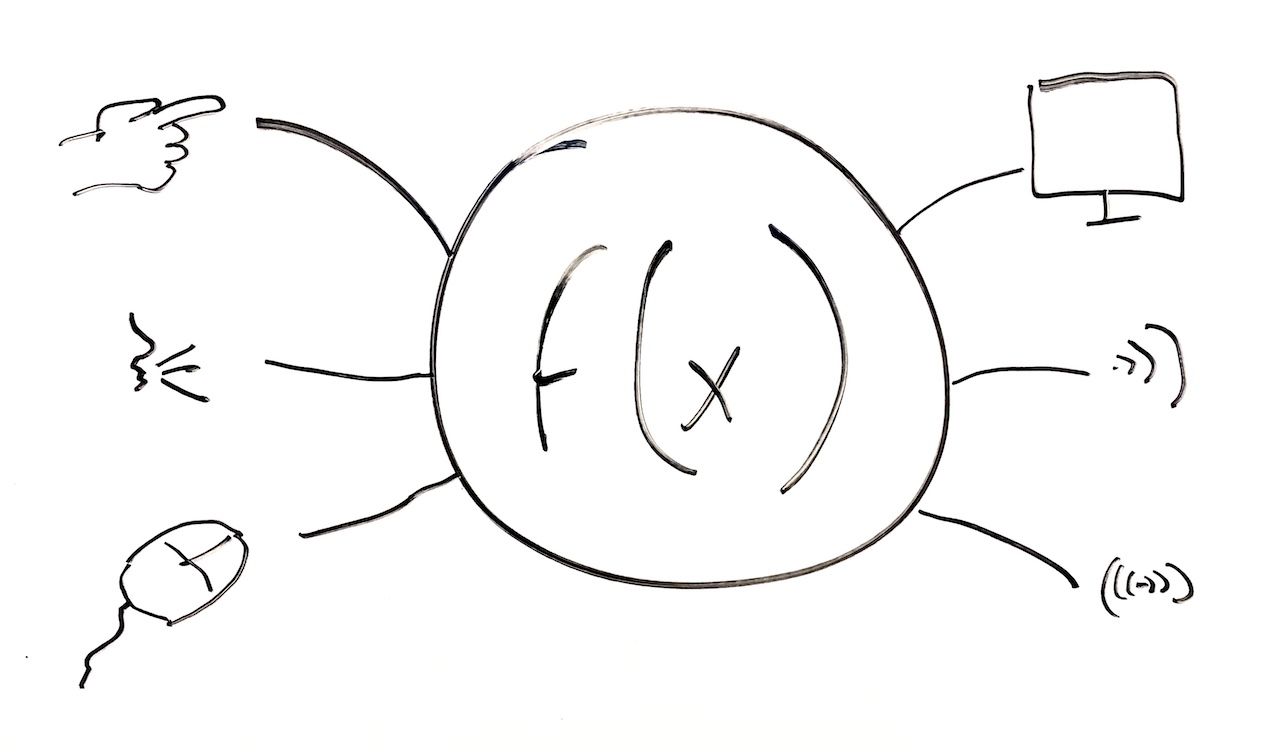
Broadly, I view the social role of interfaces as a mediating one. Mediation is the idea that rather than two entities interacting directly, something controls, filters, transacts, or interprets interaction between two entities. For example, one can think of human-to-human interactions as mediated, in that our thoughts, ideas, and motivations are mediated by language. In that same sense, user interfaces can mediate human interaction with many things. Mediation is important, because, as Marshall McLuhan argued, media (which by definition mediates) can lead to subtle, sometimes invisible structural changes in society’s values, norms, and institutions 5 . In other words, how you design a user interface can change society, in addition to providing functionality. Apple’s Face ID, for example, may be a convenient alternative to passwords, but it may also lead to transformations in how society thinks of privacy and identity.
In this chapter, we will discuss how user interfaces mediate access to three things: automation, information, and other humans. aa Computer interfaces might mediate other things too: these are just the three most prominent society.

Mediating automation
As the theory in the last chapter claimed, interfaces primarily mediate computation. Whether it’s calculating trajectories in World War II or detecting faces in a collection of photos, the vast range of algorithms from computer science that process, compute, filter, sort, search, and classify information provide real value to the world, and interfaces are how people access that value.
Interfaces that mediate automation are much like application programming interfacesapplication programming interface (API): A collection of code used for computing particular things, designed for reuse by others without having to understand the details of the computation. For example, an API might mediate access to facial recognition algorithms, date arithmetic, or trigonometric functions. (APIs) that software developers use. APIs organize collections of functionality and data structures that encapsulate functionality, hiding complexities, and providing a simpler interface for developers to use to build applications. For example, instead of a developer having to learn how to build a machine learning classification algorithm themselves, they can use a machine learning API, which only requires the developer to provide some data and parameters, which the API uses to train the classifier.
In the same way, user interfaces are simply often direct manipulation ways of providing inputs to APIs. For example, think about what operating a calculator app on a phone actually involves: it’s really a way of delegating arithmetic operations to a computer. Each operation is a function that takes some arguments (addition, for example, is a function that takes two numbers and returns their sum). In this example, the calculator is literally an interface to an API of mathematical functions that compute things for a person. But consider a very different example, such as the camera application on a smartphone. This is also an interface to an API, with a single function that takes as input all of the light into a camera sensor, a dozen or so configuration options for focus, white balance, orientation, etc., and returns a compressed image file that captures that moment in space and time. This even applies to more intelligent interfaces you might not think of as interfaces at all, such as driverless cars. A driverless car is basically one complex function that is called dozens of times a second that take a car’s location, destination, and all of the visual and spatial information around the car via sensors as input, and computes an acceleration and direction for the car to move. The calculator, the camera, and the driverless car are really both just interfaces to APIs that expose a set of computations, and user interfaces are what we use to access this computation.
From this API perspective, user interfaces mediate access to APIs, and interaction with an interface is really identical, from a computational perspective, to executing a program that uses those APIs to compute. In the calculator, when you press the sequence of buttons “1”, “+”, “1”, “=”, you just wrote a program add(1,1) and get the value 2 in return. When you open the camera app, point it at your face for a selfie, and tap on the screen to focus, you’re writing the program capture(focusPoint, sensorData) and getting the image file in return. When you enter your destination in a driverless car, you’re really invoking the program while(!at(destination)) { drive(destination, location, environment); } . From this perspective, interacting with user interfaces is really about executing “one-time use” programs that compute something on demand.
How is this mediation? Well, the most direct way to access computation would be to write computer programs and then execute them. That’s what people did in the 1960’s before there were graphical user interfaces, but even those were mediated by punchcards, levers, and other mechanical controls. Our more modern interfaces are better because we don’t have to learn as much to communicate to a computer what computation we want. But, we still have to learn interfaces that mediate computation: we’re just learning APIs and how to program with them in graphical, visual, and direct manipulation forms, rather than as code.
Of course, as this distance between what we want a computer to do and how it does it grows, so does fear about how much trust to put in computers to compute fairly. A rapidly growing body of research is considering what it means for algorithms to be fair, how people perceive fairness, and how explainable algorithms are 1,7,9 . All of these issues of trust emerge from the fact that algorithms are mediating an increasing amount of our interactions, with decreasing amount of transparency around the hidden complexities of the computation inside them.
Mediating information
Interfaces aren’t just about mediating computation, however. They’re also about accessing information. Before software, other humans mediated our access to information. We asked friends for advice, we sought experts for wisdom, and when we couldn’t find people to inform us, we consulted librarians to help us find recorded knowledge, written by experts we didn’t have access to. Searching and browsing for information was always an essential human activity.
Computing changed this. Now we use software to search the web, to browse documents, to create information, and to organize it. Because computers allow us to store information and access it much more quickly than we could access information through people or documents, we started to build systems for storing, curating, and provisioning information on computers and access it through user interfaces. We took all of the old ideas from information science such as documents, metadata, searching, browsing, indexing, and other knowledge organization ideas, and imported those ideas into computing. Most notably, the Stanford Digital Library Project leveraged all of these old ideas from information science and brought them to computers. This inadvertently led to Google, which still views its core mission as organizing the world’s information, which is what libraries were originally envisioned to do. But there is a difference: librarians, card catalogs, and libraries in general view their core values as access and truth, Google and other search engines ultimately prioritize convenience and profit, often at the expense of access and truth.
The study of how to design user interfaces to optimally mediate access to information is usually called information architectureinformation architecture: The study and practice of organizing information and inferfaces to support searching, browsing, and sensemaking. 8 . Accessing information is different from accessing computation in that rather than invoking functions to compute results, we’re specifying information needs that facilitate information retrieval and browsing. Information architecture is therefore about defining metadatametadata: Data about data; for example, metadata about a digital photograph might include where it was taken, who took it, and a description of what is in the image. on data and documents that can map information needs to information. Consider, for example, the crucial metadata about the credibility of some information source. Information used to be mediated by institutions that centrally assessed credibility through gatekeeping (e.g., curators at libraries refusing to archive and led material that had misinformation). However, now that we have shifted our attention away from public institutions like libraries and journalism that prioritize truth over speech, and towards institutions that prioritize free speech over truth, credibility metadata has become far less common. It’s only recently that some information sources such as Twitter and Facebook have decided to invest in the same practices to assess and share credibility metadata, and reluctantly. Of course, credibility metadata is only one kind of metadata: information has authors, dates, citations, languages, fact checking, and much more. As user interfaces has been digitized, so has much of this metadata, and design patterns for organizing it, such as tagging systems, controlled vocabularies, indices, hierarchies, classifications, and more. Each of these facilitate searching, browsing and sensemaking.
In practice, user interfaces for information technologies can be quite simple. They might consist of a programming language, like Google’s query language , in which you specify an information need (e.g., cute kittens ) that is satisfied with retrieval algorithms (e.g., an index of all websites, images, and videos that might match what that phrase describes, using whatever metadata those documents have). Google’s interface also includes systems for generating user interfaces that present the retrieved results (e.g., searching for flights might result in an interface for purchasing a matching flight). User interfaces for information technologies might instead be browsing-oriented, exposing metadata about information and facilitating navigation through an interface. For example, searching for a product on Amazon often involves setting filters and priorities on product metadata to narrow down a large set of products to those that match your criteria. Whether an interface is optimized for searching, browsing, or both, all forms of information mediation require metadata.

Mediating communication
While computation and information are useful, most of our socially meaningful interactions still occur with other people. That said, more of these interactions than ever are mediated by user interfaces. Every form of social media — messaging apps, email, video chat, discussion boards, chat rooms, blogs, wikis, social networks, virtual worlds, and so on — is a form of computer-mediated communicationcomputer-mediated communication: Any form of communication that is conducted through some computational device, such as a phone, tablet, laptop, desktop, smart speaker, etc. 4 .
What makes user interfaces that mediate communication different from those that mediate automation and information? Whereas mediating automation requires clarity about an API’s functionality and input requirements, and mediating information requires metadata to support searching and browsing, mediating communication requires social context . For example, in their seminal paper, Gary and Judy Olson discussed the vast array of social context present in collocated synchronous interactions that have to be reified in computer-mediated communication 6 . Examples of social context abound. Consider, for example, the now ubiquitous video chat. Ideally, such tools would help us know who is speaking, who wants to speak next, non-verbal reactions to our speech, visual and auditory cues of emotional state, whether others are paying attention and how closely, and what else is happening in someone’s space. Video chat can make some of this information available, but when compared to face-to-face settings, such information is often lower latency, lower resolution, and therefore lower reliability, eroding our ability to use this information to establish common ground in communication. Facebook does with even less: it offers no non-verbal cues, few signals of emotion, no sense of physical space, and little temporal context other than timestamps. It’s this missing social context that usually leads computer-mediated communication to be more dysfunctional 2 , leading to misunderstandings, mistrust, and division.
Many researchers in the field of computer-supported collaborative work have sought to find designs that better support social processes, including ideas of “social translucence,” which achieves similar context as collocation, but through new forms of visibility, awareness, and accountability 3 . This work, and the work that followed, generally has found that designing social interfaces is really about designing social cues, to replace the kinds of cues we find in collocated settings.
These three types of mediation each require different architectures, different affordances, and different feedback to achieve their goals:
- Interfaces for computation have to teach a user about what computation is possible and how to interpret the results.
- Interfaces for information have to teach the kinds of metadata that conveys what information exists and what other information needs could be satisfied.
- Interfaces for communication have to teach a user about new social cues that convey the emotions and intents of the people in a social context, mirroring or replacing those in the physical world.
Of course, one interface can mediate many of these things. Twitter, for example, mediates information to resources, but it also mediates communication between people. Similarly, Google, with its built in calculator support, mediates information, but also computation. Therefore, complex interfaces might be doing many things at once, requiring even more careful teaching. Because each of these interfaces must teach different things, one must know foundations of what is being mediated to design effective interfaces. Throughout the rest of this book, we’ll review both the foundations of user interface implementation, but also how the subject of mediation constrains and influences what we implement.
References
-
Abdul, A., Vermeulen, J., Wang, D., Lim, B.Y., Kankanhalli, M (2018). Trends and trajectories for explainable, accountable, intelligible systems: an HCI research agenda. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Cho, D., & Kwon, K. H. (2015). The impacts of identity verification and disclosure of social cues on flaming in online user comments. Computers in Human Behavior.
-
Erickson, T., & Kellogg, W. A. (2000). Social translucence: an approach to designing systems that support social processes. ACM transactions on computer-human interaction (TOCHI), 7(1), 59-83.
- Fussell, S. R., & Setlock, L. D. (2014). Computer-mediated communication. Handbook of Language and Social Psychology. Oxford University Press, Oxford, UK, 471-490
-
Marshall McLuhan (1994). Understanding media: The extensions of man. MIT press.
-
Olson, G. M., & Olson, J. S. (2000). Distance matters. Human-Computer Interaction.
-
Rader, E., Cotter, K., Cho, J. (2018). Explanations as mechanisms for supporting algorithmic transparency. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Rosenfeld, L., & Morville, P. (2002). Information architecture for the world wide web. O'Reilly Media, Inc..
-
Woodruff, A., Fox, S.E., Rousso-Schindler, S., Warshaw, J (2018). A qualitative exploration of perceptions of algorithmic fairness. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).

Accessibility
Thus far, most of our discussion has focused on what user interfaces are . I described them theoretically as a mapping from the sensory, cognitive, and social human world to these collections of functions exposed by a computer program . While that’s true, most of the mappings we’ve discussed have been input via our fingers and output to our visual perceptual systems. Most user interfaces have largely ignored other sources of human action and perception. We can speak. We can control over 600 different muscles. We can convey hundreds of types of non-verbal information through our gaze, posture, and orientation. We can see, hear, taste, smell, sense pressure, sense temperature, sense balance, sense our position in space, and feel pain, among dozens of other senses. This vast range of human abilities is largely unused in interface design.
This bias is understandable. Our fingers are incredibly agile, precise, and high bandwidth sources of action. Our visual perception is similarly rich, and one of the dominant ways that we engage with the physical world. Optimizing interfaces for these modalities is smart because it optimizes our ability to use interfaces.
However, this bias is also unreasonable because not everyone can see, use their fingers precisely, or read text. Designing interfaces that can only be used if one has these abilities means that vast numbers of people simply can’t use interfaces 11 . And this is no small population: according to a 2004 World Bank survey (World Bank is an international financial institution that seeks to reduce poverty), one billion people (15% of humanity) have some form of disability that impacts their daily activities. That includes people who are blind, low-vision, color blind, deaf, hard of hearing, unable to speak, or possess speech impediments, the inability to walk or use limbs, or have some form of cognitive disorder such as dyslexia, dysgraphia, dyscalculia, memory loss, or learning disabilities. And many people have multiple disabilities.
This might describe you or people you know. And in all likelihood, you will be disabled in one or more of these ways someday, as you age or temporarily, due to injuries, surgeries, or other situational impairments. And that means you’ll struggle or be unable to use the graphical user interfaces you’ve worked so hard to learn. And if you know no one that struggles with interfaces, it may be because they are stigmatized by their difficulties, not sharing their struggles and avoiding access technologies because they signal disability 14 . Or worse yet, they are not even in your social world, because their inability to use interfaces has led to their systematic exclusion. And if justice and inclusion are not justification enough, remember that every business that ignores accessibility is ignoring 15% of people in the world as potential customers.
Of course, abilities vary, and this variation has different impacts on people’s ability to use interfaces. One of the most common forms of disability is blindness and low-vision. But even within these categories, there is diversity. Some people are completely blind, some have some sight but need magnification. Some people have color blindness, which can be minimally impactful, unless an interface relies heavily on colors that a person cannot distinguish. I am near-sighted, but still need glasses to interact with user interfaces close to my face. When I do not have my glasses, I have to rely on magnification to see visual aspects of user interface. And while the largest group of people with disabilities are those with vision issues, the long tail of other disabilities around speech, hearing, and motor ability, when combined, is just as large.
Accessibility
Of course, most interfaces assume that none of this variation exists. And ironically, it’s partly because the user interface toolkits we described in the architecture chapter embed this assumption deep in their architecture. Toolkits make it so easy to design graphical user interfaces that these are the only kind of interfaces designers make. This results in most interfaces being difficult or sometimes impossible for vast populations to use, which really makes no business sense 8 . We use the word accessibilityaccessibility: A quality of user interfaces that determines what abilities are required to use an interface. Accessible interfaces include people regardless of ability; inaccessible interfaces exclude people with particular abilities. to refer to the extent to which an interface can be used by people regardless of their abilities. We describe user interfaces as universaluniversal design: Interfaces that are accessible to any person, regardless of their abilities. if they can be used by people regardless of what combination of abilities they have 16 . Achieving universal design means achieving principles like ensuring that use is equitable, flexible, simple, that information be perceived and accessed by all, that error rates are low for everyone, and that physical effort is minimal. These principles can be vague, but that is because abilities are diverse: no one statement can summarize all of the abilities one must account for in user interface design.
Whereas universal interfaces work for everyone as is, access technologiesaccess technology: Interfaces that are used in tadem with other intefaces to improve their poor accessibility. are alternative user interfaces that attempt to make an existing user interface more universal. Access technologies include things like:
- Screen readers convert text on a graphical user interface to synthesized speech so that people who are blind or unable to read can interact with the interface.
- Captions annotate the speech and action in video as text, allowing people who are deaf or hard of hearing to consume the audio content of video.
- Braille , as shown in the image at the top of this chapter, is a tactile encoding of words for people who are visually impaired.
Consider, for example, this demonstration of screen readers and a braille display:
Fundamentally, universal user interface designs are ones that can be operated via any input and output modality . If user interfaces are really just ways of accessing functions defined in a computer program, there’s really nothing about a user interface that requires it to be visual or operated with fingers. Take, for example, an ATM machine. Why is it structured as a large screen with several buttons? A speech interface could expose identical banking functionality through speech and hearing. Or, imagine an interface in which a camera just looks at someone’s wallet and their face and figures out what they need: more cash, to deposit a check, to check their balance. The input and output modalities an interface uses to expose functionality is really arbitrary: using fingers and eyes is just easier for most people in most situations.
Advances in Accessibility
The challenge for user interface designers then is to not only design the functionality a user interface exposes, but also design a myriad of ways of accessing that functionality through any modality. Unfortunately, conceiving of ways to use all of our senses and abilities is not easy. It took us more than 20 years to invent graphical user interfaces optimized for sight and hands. It’s taken another 20 years to optimize touch-based interactions. It’s not surprising that it’s taking us just as long or longer to invent seamless interfaces for speech, gesture, and other uses of our muscles, and efficient ways of perceiving user interface output through hearing, feeling, and other senses.
These inventions, however, are numerous and span the full spectrum of modalities. For instance, access technologies like screen readers have been around since shortly after Section 508 of the Rehabilitation Act of 1973, and have converted digital text into synthesized speech. This has made it possible for people who are blind or have low-vision to interact with graphical user interfaces. But now, interfaces go well beyond desktop GUIs. For example, just before the ubiquity of touch screens, the SlideRule system showed how to make touch screens accessible to blind users by reading labels of UI throughout multi-touch 10 . This research impacted the design of Apple’s VoiceOver functionality in iOS, which influenced Microsoft and Google to add multi-touch screen reading to Windows and Android. These advances in access technologies, especially when built in at the operating system level, have greatly increased the diversity of people who can access computing.
For decades, screen readers have only worked on computers, but recent innovations like VizLens (above) have combined machine vision and crowdsourcing to support arbitrary interfaces in the world, such as microwaves, refrigerators, ATMs, and other appliances 7 . Innovations like this allow users to capture the interface with a camera, then get interactive guidance of the layout and labels of the interface. Solutions like this essentially provide screen reading for anything in the world, converting visual interfaces into auditory ones.
With the rapid rise in popularity of the web, web accessibility has also been a popular topic of research. Problems abound, but one of the most notable is the inaccessibility of images. Images on the web often come without alt tags that describe the image for people unable to see. User interface controls often lack labels for screen readers to read. Some work shows that some of the the information needs in these descriptions are universal—people describing needing descriptions of people and objects in images—but other needs are highly specific to a context, such as subjective descriptions of people on dating websites 15 . Other works hows that emoji are a particularly inaccessible form of text content, lacking not only descriptors, but also disruptive features like repeated emoji sequences that are read by screen readers redundantly 18 . Researchers have only just begun inventing ways of inferring these descriptions and labels by mining the surrounding context of a page for a reasonable description 9 or by using machine vision to identify and track personal objects at someone’s home while giving verbal and auditory feedback about location 1 . People with low-vision often just need magnification of content. While web browsers allow people to increase text size, this often breaks the layout of pages, and so researchers have invented ways of automatically resizing images and text to a size that doesn’t break layout, improving readability automatically 2 . One way to view these innovations is as bandages to accessibility flaws at the architectural level. For example, why is it valid to leave an “alt” tag empty in HTML? Why do HTML layout algorithms allow text to overlap? Little work has considered how to design architectures, user interface tools, and toolkits that prevent accessibility problems. And the patches that have been invented are still far from meeting even basic needs of people with visual disabilities.
For people who are deaf or hard of hearing, videos, dialog, or other audio output interfaces are a major accessibility barrier to using computers or engaging in computer-mediated communication. Researchers have invented systems like Legion , which harness crowd workers to provide real-time captioning of arbitrary audio streams with only a few seconds of latency 12 . People who are deaf may also use sign language, but computer-mediated communication like video chat often has insufficient frame rates and resolution to read signs. Researchers have invented video compression algorithms that optimize for detail in hands at the expense of other visual information 3 . Not only did this technique make it more feasible for people to sign via low-frame-rate video chat, but the compression algorithm also increased battery life by 47% by reducing bandwidth requirements.
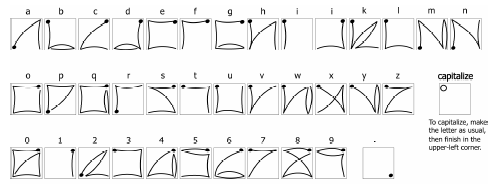
For people who have motor impairments, such as motor tremors , fine control over mouse, keyboards, or multi-touch interfaces can be quite challenging, especially for tasks like text-entry, which require very precise movements. Researchers have explored several ways to make interfaces more accessible for people without fine motor control. EdgeWrite , for example, is a gesture set (shown above) that only requires tracing the edges and diagonals of a square 19 . This stabilizes motion even in the presence of tremors, significantly increasing text entry speed and correctness. To make mouse and touch-based interfaces more accessible, systems like SUPPLE aimed to model users’ motor control abilities, and used that model to generate a custom interface layout that made user interface controls easier to click, while preventing accidental clicks 5 . SmartTouch used a similar approach, modeling how people with a wide range of motor impairments touched touch-screens, and adapting the algorithms that inferred the intended touch point based on these models 13 . Both SUPPLE and SmartTouch are examples of ability-based designability-based design: Interface designs that adapt to the abilities of their users. , in which the user interface models the user and adapts itself to the users’ abilities 20 .
Sight, hearing, and motor abilities have been the major focus of innovation, but an increasing body of work also considers neurodiversity. For example, autistic people, people with down syndrome, and people with dyslexia may process information in different and unique ways, requiring interface designs that support a diversity of interaction paradigms. As we have discussed, interfaces can be a major source of such information complexity. This has led to interface innovations that facilitate a range of aids, including images and videos for conveying information, iconographic, recognition-based speech generation for communication, carefully designed digital surveys to gather information in health contexts, and memory-aids to facilitate recall. Some work has found that while these interfaces can facilitate communication, they are often not independent solutions, and require exceptional customization to be useful 6 .
Whereas all of the innovations above aimed to make particular types of information accessible to people with particular abilities, some techniques target accessibility problems at the level of software architecture. For example, accessibility frameworks and features like Apple’s VoiceOver in iOS are system-wide: when a developer uses Apple’s standard user interface toolkits to build a UI, the UI is automatically compatible with VoiceOver , and therefore automatically screen-readable. Because it’s often difficult to convince developers of operating systems and user interfaces to make their software accessible, researchers have also explored ways of modifying interfaces automatically. For example, Prefab (above) is an approach that recognizes the user interface controls based on how they are rendered on-screen, which allows it to build a model of the UI’s layout 4 . This allows Prefab to intercept mouse and touch input and leverage the wide range of accessibility optimizations for pointing from other researchers to make the target interface easier to operate. While Prefab focuses on user interface controls, the Genie system focuses on the underlying functions and commands of a user interface 17 . It reverse engineers a model of all of the commands in an interface, and then can automatically repackage those commands in alternative user interfaces that are more accessible.
While all of the ideas above can make interfaces more universal, they can also have other unintended benefits for people without disabilities. For example, it turns out screen readers are great for people with ADHD, who may have an easier time attending to speech than text. Making web content more readable for people with low-vision also makes it easier for people with situational impairments, such as dilated pupils after a eye doctor appointment. Captions in videos aren’t just good for people who are deaf and hard of hearing; they’re also good for watching video in quiet spaces. Investing in these accessibility innovations then isn’t just about impacting that 15% of people with disabilities, but also the rest of humanity.
References
-
Dragan Ahmetovic, Daisuke Sato, Uran Oh, Tatsuya Ishihara, Kris Kitani, and Chieko Asakawa (2020). ReCog: Supporting Blind People in Recognizing Personal Objects. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Jeffrey P. Bigham (2014). Making the web easier to see with opportunistic accessibility improvement. ACM Symposium on User Interface Software and Technology (UIST).
-
Neva Cherniavsky, Jaehong Chon, Jacob O. Wobbrock, Richard E. Ladner, Eve A. Riskin (2009). Activity analysis enabling real-time video communication on mobile phones for deaf users. ACM Symposium on User Interface Software and Technology (UIST).
-
Morgan Dixon and James Fogarty (2010). Prefab: implementing advanced behaviors using pixel-based reverse engineering of interface structure. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Krzysztof Z. Gajos, Jacob O. Wobbrock, Daniel S. Weld (2007). Automatically generating user interfaces adapted to users' motor and vision capabilities. ACM Symposium on User Interface Software and Technology (UIST).
-
Ryan Colin Gibson, Mark D. Dunlop, Matt-Mouley Bouamrane, and Revathy Nayar (2020). Designing Clinical AAC Tablet Applications with Adults who have Mild Intellectual Disabilities. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Anhong Guo, Xiang 'Anthony' Chen, Haoran Qi, Samuel White, Suman Ghosh, Chieko Asakawa, Jeffrey P. Bigham (2016). VizLens: A robust and interactive screen reader for interfaces in the real world. ACM Symposium on User Interface Software and Technology (UIST).
-
Sarah Horton and David Sloan (2015). Accessibility for business and pleasure. ACM interactions.
-
Muhammad Asiful Islam, Yevgen Borodin, I. V. Ramakrishnan (2010). Mixture model based label association techniques for web accessibility. ACM Symposium on User Interface Software and Technology (UIST).
-
Shaun K. Kane, Jeffrey P. Bigham, Jacob O. Wobbrock (2008). Slide rule: making mobile touch screens accessible to blind people using multi-touch interaction techniques. ACM SIGACCESS Conference on Computers and Accessibility.
-
Richard E. Ladner (2012). Communication technologies for people with sensory disabilities. Proceedings of the IEEE.
-
Walter Lasecki, Christopher Miller, Adam Sadilek, Andrew Abumoussa, Donato Borrello, Raja Kushalnagar, Jeffrey Bigham (2012). Real-time captioning by groups of non-experts. ACM Symposium on User Interface Software and Technology (UIST).
-
Martez E. Mott, Radu-Daniel Vatavu, Shaun K. Kane, Jacob O. Wobbrock (2016). Smart touch: Improving touch accuracy for people with motor impairments with template matching. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Kristen Shinohara and Jacob O. Wobbrock (2011). In the shadow of misperception: assistive technology use and social interactions. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Abigale Stangl, Meredith Ringel Morris, and Danna Gurari (2020). Person, Shoes, Tree. Is the Person Naked? What People with Vision Impairments Want in Image Descriptions. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Molly Follette Story (1998). Maximizing Usability: The Principles of Universal Design. Assistive Technology, 10:1, 4-12.
-
Amanda Swearngin, Amy J. Ko, James Fogarty (2017). Genie: Input Retargeting on the Web through Command Reverse Engineering. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Garreth W. Tigwell, Benjamin M. Gorman, and Rachel Menzies (2020). Emoji Accessibility for Visually Impaired People. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Jacob O. Wobbrock, Brad A. Myers, John A. Kembel (2003). EdgeWrite: a stylus-based text entry method designed for high accuracy and stability of motion. ACM Symposium on User Interface Software and Technology (UIST).
-
Jacob O. Wobbrock, Shaun K. Kane, Krzysztof Z. Gajos, Susumu Harada, Jon Froehlich (2011). Ability-Based Design: Concept, Principles and Examples. ACM Transactions on Accessible Computing.

Programming Interfaces
If you don’t know the history of computing, it’s easy to overlook the fact that all of the interfaces that people used to control computers before the graphical user interface were programming interfaces. But that’s no longer true; why then talk about programming in a book about user interface technology? Two reasons: programmers are users too, and perhaps more importantly, user interfaces quite often have programming-like features embedded in them. For example, spreadsheets aren’t just tables of data; they also tend to contain formulas that perform calculations on that data. Or, consider the increasingly common trend of smart home devices: to make even basic use of them, one must often write basic programs to automate their use (e.g., turning on a light when one arrives home, or defining the conditions in which a smart doorbell sends a notification). Programming interfaces are therefore far from niche: they are the foundation of how all interfaces are built and increasingly part of using interfaces to control and configure devices.
But it’s also important to understand programming interfaces in order to understand why interactive interfaces — the topic of our next chapter — are so powerful. This chapter won’t teach you to code if you don’t already know how, but it will give you the concepts and vocabulary to understand the fundamental differences between these two interface paradigms, when one might be used over the other, and what challenges each poses to people using computers.
Properties of programming interfaces
In some ways, programming interfaces are like any other kind of user interface: they take input, present output, have affordances and signifiers, and present a variety of gulfs of evaluation and execution. They do this by using a collection of tools, which make up the “interface” a programmer users to write computer programs:
- Programming languages . These are interfaces that take computer programs, translate them into instructions that a computer can execute, and then execute them. Popular examples include languages like
Python(depicted at the beginning of this chapter) andJavaScript(which is used to build interactive web sites) but also less well-known languages such as `Scratch` , which youth often use to create interactive 2D animations and games, orR, which statisticians and data scientists use to analyze data. - Editors . These are editors, much like word processes, that programmers use to read and edit computer programs. Some languages are editor-agnostic (e.g., you can edit Python code in any text editor), whereas others come with dedicated editors (e.g., Scratch programs can only be written with the Scratch editor).
These two tools, along with many other optional tools to help streamline the many challenges that come with programming, are the core interfaces that people use to write computer programs. Programming, therefore, generally involves reading and editing code in an editor, and repeatedly asking a programming language to read the code to see if there are any errors in it, and then executing the program to see if it has the intended behavior. It often doesn’t, which requires people to debug their code, finding the parts of it leading the program to misbehave. This edit-run-debug cycle is the general experience of programming, slowly writing and revising a program until it behaves as intended (much like slowly sculpting a sculpture, writing an essay, or painting a painting).
While it’s obvious this is different from using a website or mobile application, it’s helpful to talk in more precise terms about exactly how it is different. In particular, there are three attributes in particular that make an interface a programming interface 3 :
- No direct manipulation . In interactive interfaces like a web page or mobile app, concrete physical actions by a user on some data — moving a mouse, tapping on an object — result in concrete, immediate feedback about the effect of those actions. For example, dragging a file from one folder to another immediately moves the file, both visually, and on disk; selecting and dragging some text in a word processor moves the text. In contrast, programming interfaces offer no such direct manipulation: one declares what a program should do to some data, and then only after the program is executed does that action occur (if it was declared correctly). Programming interfaces therefore always involve indirect manipulation, describing.
- Use of notation . In interactive interfaces, most interactions involve concrete representations of data and action. For example, a web form has controls for entering information, and a submit button for saving it. But in programming interfaces, references to data and actions always involves using some programming language notation to refer to data and actions. For example, to open a new folder in the Unix or Linux operating systems, one has to type
cd myFolder, which is a particular notation for executing thecdcommand (standing for “change directory” and specifying which folder to navigate to (myFolder). Programming interfaces therefore always involve specific rules for describing what a user wants the computer to do. - Use of abstraction . An inherent side effect of using notations is that one must also use abstractions to refer to a computer’s actions. For example, when one uses the Unix command line program
mv file.txt ../(which movesfile.txtto its parent directory), they are using a command, a file name, and a symbolic reference../to refer to the parent directory of the current directory. Commands, names, and relative path references are all abstractions in that they all abstractly represent the data and actions to be performed. Visual icons in a graphical user interface are also abstract, but because they support direct manipulation, such as moving files from one folder to another, they can be treated as concrete objects. Not so with programming interfaces, where everything is abstract.
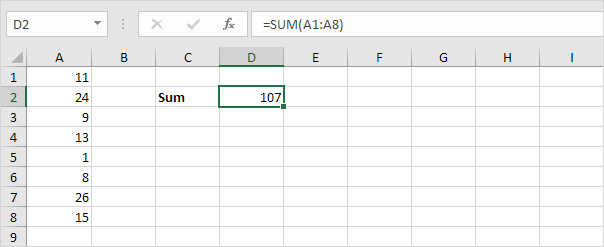
Clearly, textual programming languages such as the popular Python , Java or JavaScript fit all all of the descriptions above. But what about programming interfaces like Excel spreadsheets? Thinking through each of the properties above, we see spreadsheets have many of the same properties. While one can directly manipulate data in cells, there are no direct manipulation ways to use formulas: those must be written in a notation, the Excel programming language. And the notation invokes abstract ideas like sum rows and columns. Spreadsheets blur the line between programming and interactive interfaces, however, by immediately executing formulas as soon as they are edited, recomputing everything in the spreadsheet. This gives a a similar sense of immediacy as direct manipulation, even though it is not direct.
Another interesting case is that of chat bots, including those with pre-defined responses like in help tools and Discord, as well as more sophisticated ones like ChatGPT and others that use large language models (LLMs) trained on all of the internet’s public documents. Is writing prompts a form of programming? They seem to satisfy all of the properties above. They do not support direct manipulation, because they require a descriptions of commands. They do use notation, just natural language instead of a formal notation like a programming language. And they definitely use abstraction, in that they rely on sequences of symbols that represent abstract ideas (otherwise known as words ) to refer to what one wants a computer to do. If we accept the definition above, then yes, chat bots and voice interfaces are programming interfaces, and may entail similar challenges as more conventional programming interfaces do. And we shouldn’t be surprised: all large-language models do (along with more rudimentary approaches to responding to language) is take a series of symbols as inputs, and generate a series of symbols in response, just like any other function in a computer program.

Learning programming interfaces
Because programming interfaces are interfaces, they also have gulfs of executiongulf of execution: Everything a person must learn in order to acheive their goal with an interface, including learning what the interface is and is not capable of and how to operate it correctly. and evaluationgulf of evaluation: Everything a person must learn in order to understand the effect of their action on an interface, including understanding error messages or a lack of response from an interface. as well. Their gulfs are just much larger because of the lack of direct manipulation, the use of notation, and the centrality of abstraction. All of these create a greater distance between someone’s goal, which often involves delegating or automating some task with code.
At the level of writing code, the gulfs of execution are immense. Imagine, for example, you have an idea for an mobile app, and are starting at a blank code editor. To have any clue what to type, people must know 1) a programming language, including its notation, and the various rules for using the notation correctly; 2) basic concepts in computer science about data structures and algorithms, and 3) how to operate the code editor, which may have many features designed assuming all of this prior knowledge. Its rare, therefore, that a person might just poke around an editor or programming language to learn how it works. Instead, learning usually requires good documentation, perhaps some tutorials, and quite possibly a teacher and an education system. The same can be true of complex interactive interfaces (e.g., learning Photoshop ), but at least in the case of interactive interfaces, the functional affordances is explicitly presented in menus. With programming interfaces, affordances are invisible.
Once one has some code and executes it, programming interfaces pose similarly large gulfs of evaluation. Most programs start off defective in some way, not quite doing what a person intended: when the program misbehaves, or gives an error message, what is a programmer to do? To have any clue, people lean on their knowledge of programming language to interpret error messages, carefully analyze their code, and potentially use other tools like debuggers to understand where their instructions might have gone wrong. These debugging skills are similar to the troubleshooting skills required by in interactive interfaces (e.g., figuring out why Microsoft Word keeps autocorrecting something), but the solutions are often more than just unchecking a checkbox: they may involve revising or entirely rewriting a part of a program.
If these two gulfs were not enough, modern programming interfaces have come to introduce new gulfs. These new gulfs primarily emerge from the increasing use of APIsapplication programming interface (API): A collection of code used for computing particular things, designed for reuse by others without having to understand the details of the computation. For example, an API might mediate access to facial recognition algorithms, date arithmetic, or trigonometric functions. to construct applications by reusing other people’s code. Some of the gulfs that reuse impose include 11 :
- Design gulfs . APIs make some things easy to create, while making other things hard or impossible. This gulf of execution requires programmers to know what is possible to express.
- Selection gulfs . APIs may offer a variety of functionality, but it’s not always clear what functionality might be relevant to implementing something. This gulf of execution requires programmers to read documentation, scour web forums, and talk to experts to find the API that might best serve their need.
- Use gulfs . Once someone find an API that might be useful for creating what they want, they have to learn how to use the API. Bridging this gulf of execution might entail carefully reading documentation, finding example code, and understanding how the example code works.
- Coordination gulfs . Once someone learns how to use one part of an API, they might need to use it in coordination with another part to achieve the behavior they want. Bridging this gulf of execution might require finding more complex examples, or creatively tinkering with the API to understand its limitations.
- Understanding gulfs . Once someone has written some code with an API, they may need to debug their code, but without the ability to see the API’s own code. This poses gulfs of evaluation, requiring programmers to carefully interpret and analyze API behavior, or find explanations of its behavior in resources or online communities.
These many gulfs of execution and evaluation mean have two implications: 1) programming interfaces are hard to learn and 2) designing programming interfaces is about more than just programming language design. It’s about supporting a whole ecosystem of tools and resources to support learning.
If we return to our examination of chat bots, we can see that they also have the same gulfs. It’s not clear what one has to say to a chat bot to get the response one wants. Different phrases have different effects, in unpredictable ways. And once one does say something, if the results are unexpected, it’s not clear why the model produced the results it did, and what action needs to be taken to produce a different response. “Prompt engineering” may just be modern lingo for “programming” and “debugging”, just without all of the usual tools, documentation, and clarity of how to use them to get what you want.
Simplifying programming interfaces
Given all of the difficulties that programming interfaces pose, its reasonable to wonder why we use them at all, instead of just creating interactive interfaces for everything we want computers to do. Unfortunately, that simply isn’t possible: creating new applications requires programming; customizing the behavior of software to meet our particular needs requires programming; and automating any task with a computer requires programming. Therefore, many researchers have worked hard to reduce the gulfs in programming interfaces as much as possible, to enable more people to succeed in using them.
While there is a vast literature on programming languages and tools, and much of it focuses on bridging gulfs of execution and evaluation, in this chapter, we’ll focus on the contributions that HCI researchers have made to solving these problems, as they demonstrate the rich, under-explored design space of ways that people can program computers beyond using general purpose languages. Much of this work can be described as supporting end-user programmingend-user programming: Any programming done as a means to accomplish some other goal (in contrast to software engineering, which is done for the sole purpose of creating software for others to use). , which is any programming that someone does as a means to accomplishing some other goal 13 . For example, a teacher writing formulas in a spreadsheet to compute grades, a child using Scratch to create an animation, or a data scientist writing a Python script to wrangle some data — none of these people are writing code for the code itself (as professional software engineers do), they’re writing code for the output their program will produce (the teacher wants the grades, the child wants the animation, the data scientist wants the wrangled data).
This vast range of domains in which programming interfaces can be used has lead to an abundance of unique interfaces. For example, several researchers have explored ways to automate interaction with user interfaces, to take repetitive tasks and automate them. One such system is Sikuli (above), which allows users to use screenshots of user interfaces to write scripts that automate interactions 28 . Similar systems have used similar ideas to enable users to write simple programs to automate web tasks. CoScripter 16 allowed a user to demonstrate an interaction with an interface, which generated a program in a natural-language-like syntax that could then be executed to replay that action. CoCo 15 allowed a user to write a command like “get road conditions for highway 88,” which the system then translates into operations on a website using the user’s previous browsing history and previously recorded web scripts. Two related contributions used the metaphor of a command line interface for the web and desktop applications: one recommended commands based on natural language descriptions of tasks 22 and the other used a “sloppy” syntax of keywords 17 . All of these ideas bridge the gulf of execution, helping a user express their goal in terms they understand such as demonstrating an action, selecting part of an interface, or describing their goal, then having the system translate these into an executable program.
Another major focus has been supporting people interacting with data. Some systems like Vega above have offered new programming languages for declaratively specifying data visualizations 25 . Others have provided programmatic means for wrangling and transforming data with interactive support for previewing the effects of candidate transformation programs 7,18 . One system looked at interactive ways of helping users search and filter data with regular expressions by identifying examples of outlier data 21 , whereas other systems have helped translate examples of desired database queries into SQL queries 1 . Again, a major goal of all of these systems is to help bridge the gulf of evaluation between a user’s goal and the program necessary to achieve it.

Some systems have attempted to support more ambitious automation, empowering users to create entire applications that better support their personal information needs. For example, many systems have combined spreadsheets with other simple scripting languages to enable users to write simple web applications with rich interfaces, using the spreadsheet as a database 2,6 . Other systems like Mavo above and Dido have encapsulated the entire application writing process to just editing HTML by treating HTML as a specification for both the layout of a page and the layout of data 9,27 . An increasing number of systems have explored home automation domains, finding clear tradeoffs between simplicity and expressiveness in rule-based programs 4 .
Perhaps the richest category of end-user programming systems are those supporting the creation of games. Hundreds of systems have provided custom programming languages and development environments for authoring games, ranging from simple game mechanics to entire general purpose programming languages to support games 10 . For example, the system above, called Hands, carefully studied how children express computation with natural language, and designed a programming language inspired by the computational ideas inherent in children’s reasoning about game behavior 23 . Other systems, most notably Gamut 19 , used a technique called programming by demonstration , in which users demonstrate the behavior they want the computer to perform, and the computer generalizes that into a program that can be executed later on a broader range of situations than the original demonstration. Gamut was notable for its ability to support the construction of an entire application by demonstration, unlike many of the systems discussed above, which only partially used demonstration.
Most innovations for programming interfaces have focused on bridging the gulf of execution. Fewer systems have focused on bridging gulfs of evaluation by supporting, testing, and debugging behaviors a user is trying to understand. One from my own research was a system called the Whyline 11 (see the video above), which allowed users to ask “why” and “why not” questions when their program did something they didn’t expect, bridging a gulf of evaluation. It identified questions by scanning the user’s program for all possible program outputs, and answered questions by precisely trying the cause of every operation in the program, reasoning backwards about the chain of causality that caused an unwanted behavior or prevented a desired behavior. More recent systems have provided similar debugging and program comprehension support for understanding web pages 5,8 , machine learned classifiers 14,24 , and even embedded systems that use a combination of hardware and software to define a user interface 20,26 .
One way to think about all of these innovations is as trying to bring all of the benefits of interactive interfaces — direct manipulation, no notation, and concreteness — to notations that inherently don’t have those properties, by augmenting programming environments with these features. This work blurs the distinction between programming interfaces and interactive interfaces, bringing the power of programming to broader and more diverse audiences. But the work above also makes it clear that there are limits to this blurring: no matter how hard we try, describing what we want rather than demonstrating it directly, always seems to be more difficult, and yet more powerful.
References
-
Azza Abouzied, Joseph Hellerstein, Avi Silberschatz (2012). DataPlay: interactive tweaking and example-driven correction of graphical database queries. ACM Symposium on User Interface Software and Technology (UIST).
-
Edward Benson, Amy X. Zhang, David R. Karger (2014). Spreadsheet driven web applications. ACM Symposium on User Interface Software and Technology (UIST).
-
Blackwell, A. F. (2002). First steps in programming: A rationale for attention investment models. In Human Centric Computing Languages and Environments, 2002. Proceedings. IEEE 2002 Symposia on (pp. 2-10). IEEE.
-
Julia Brich, Marcel Walch, Michael Rietzler, Michael Weber, Florian Schaub (2017). Exploring End User Programming Needs in Home Automation. ACM Trans. Comput.-Hum. Interact. 24, 2, Article 11 (April 2017), 35 pages.
-
Brian Burg, Amy J. Ko, Michael D. Ernst (2015). Explaining Visual Changes in Web Interfaces. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology (UIST '15).
-
Kerry Shih-Ping Chang and Brad A. Myers (2014). Creating interactive web data applications with spreadsheets. ACM Symposium on User Interface Software and Technology (UIST).
-
Philip J. Guo, Sean Kandel, Joseph M. Hellerstein, Jeffrey Heer (2011). Proactive wrangling: mixed-initiative end-user programming of data transformation scripts. ACM Symposium on User Interface Software and Technology (UIST).
-
Joshua Hibschman and Haoqi Zhang (2015). Unravel: Rapid web application reverse engineering via interaction recording, source tracing, library detection. ACM Symposium on User Interface Software and Technology (UIST).
-
David R. Karger, Scott Ostler, Ryan Lee (2009). The web page as a WYSIWYG end-user customizable database-backed information management application. ACM Symposium on User Interface Software and Technology (UIST).
-
Caitlin Kelleher and Randy Pausch (2005). Lowering the barriers to programming: A taxonomy of programming environments and languages for novice programmers. ACM Computing Surveys.
-
Amy J. Ko, Brad A. Myers, Htet Htet Aung (2004). Six learning barriers in end-user programming systems. IEEE Symposium on Visual Languages-Human Centric Computing (VL/HCC).
-
Amy J. Ko, Brad A. Myers (2004). Designing the Whyline: A Debugging Interface for Asking Questions About Program Failures. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Amy J. Ko, Robin Abraham, Laura Beckwith, Alan Blackwell, Margaret Burnett, Martin Erwig, Chris Scaffidi, Joseph Lawrance, Henry Lieberman, Brad Myers, Mary Beth Rosson, Gregg Rothermel, Mary Shaw, Susan Wiedenbeck (2011). The state of the art in end-user software engineering. ACM Computing Surveys.
-
Todd Kulesza, Weng-Keen Wong, Simone Stumpf, Stephen Perona, Rachel White, Margaret M. Burnett, Ian Oberst, Amy J. Ko (2009). Fixing the program my computer learned: barriers for end users, challenges for the machine. International Conference on Intelligent User Interfaces (IUI).
-
Tessa Lau, Julian Cerruti, Guillermo Manzato, Mateo Bengualid, Jeffrey P. Bigham, Jeffrey Nichols (2010). A conversational interface to web automation. ACM Symposium on User Interface Software and Technology (UIST).
-
Gilly Leshed, Eben M. Haber, Tara Matthews, Tessa Lau (2008). CoScripter: automating & sharing how-to knowledge in the enterprise. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Greg Little and Robert C. Miller (2006). Translating keyword commands into executable code. ACM Symposium on User Interface Software and Technology (UIST).
-
Mikaël Mayer, Gustavo Soares, Maxim Grechkin, Vu Le, Mark Marron, Oleksandr Polozov, Rishabh Singh, Benjamin Zorn, Sumit Gulwani (2015). User Interaction Models for Disambiguation in Programming by Example. ACM Symposium on User Interface Software and Technology (UIST).
-
Richard G. McDaniel and Brad A. Myers (1997). Gamut: demonstrating whole applications. ACM Symposium on User Interface Software and Technology (UIST).
-
Will McGrath, Daniel Drew, Jeremy Warner, Majeed Kazemitabaar, Mitchell Karchemsky, David Mellis, Björn Hartmann (2017). Bifröst: Visualizing and checking behavior of embedded systems across hardware and software. ACM Symposium on User Interface Software and Technology (UIST).
-
Robert C. Miller and Brad A. Myers (2001). Outlier finding: focusing user attention on possible errors. ACM Symposium on User Interface Software and Technology (UIST).
-
Robert C. Miller, Victoria H. Chou, Michael Bernstein, Greg Little, Max Van Kleek, David Karger, mc schraefel (2008). Inky: a sloppy command line for the web with rich visual feedback. ACM Symposium on User Interface Software and Technology (UIST).
-
J. F. Pane, B. A. Myers and L. B. Miller, (2002). Using HCI techniques to design a more usable programming system. IEEE Symposium on Visual Languages-Human Centric Computing (VL/HCC).
-
Kayur Patel, Naomi Bancroft, Steven M. Drucker, James Fogarty, Amy J. Ko, James Landay (2010). Gestalt: integrated support for implementation and analysis in machine learning. ACM Symposium on User Interface Software and Technology (UIST).
-
Arvind Satyanarayan, Kanit Wongsuphasawat, Jeffrey Heer (2014). Declarative interaction design for data visualization. ACM Symposium on User Interface Software and Technology (UIST).
-
Evan Strasnick, Maneesh Agrawala, Sean Follmer (2017). Scanalog: Interactive design and debugging of analog circuits with programmable hardware. ACM Symposium on User Interface Software and Technology (UIST).
-
Lea Verou, Amy X. Zhang, David R. Karger (2016). Mavo: Creating Interactive Data-Driven Web Applications by Authoring HTML. ACM Symposium on User Interface Software and Technology (UIST).
-
Tom Yeh, Tsung-Hsiang Chang, Robert C. Miller (2009). Sikuli: using GUI screenshots for search and automation. ACM Symposium on User Interface Software and Technology (UIST).

Interactive Interfaces
It’s hard to imagine, but the interactive digital world we have to today only become a reality in the early 1980’s. Before that, interacting with a computer was much like we described in the previous chapter : carefully writing computer programs, one instruction at a time, and executing it to get a result. Nearly all of the things that define our modern world: the internet, social media, instant video streaming, messaging, and millions of apps, websites, and games — simply hadn’t been invited.
This is a reminder that nothing about the user interface designs we use today is fundamental or inevitable. Consider, for example, if researchers in the 1960’s had devoted their attention to making programming easier rather than inventing the graphical user interface. That alternate future might have created a world in which we were all coders rather than clickers.
What happened instead was a series of inventions by researchers tackling a foundational question: what if communicating with computers was less like carefully crafting instructions, and more like a conversation with a computer? In our first chapter on history , we talked about Ivan Sutherland’s 1962 experiments with Sketchpad , which envisioned pen-based interactions with constrained graphical objects, where a user could interactively create diagrams with tap and drag of a pen. Around the same time, Douglas Englebart began work on NLS , which envisioned an entire system of commands, file systems, mice, keyboards, and the internet. Inspired by this work, Alan Kay joined Xerox PARC in 1970, envisioning graphical objects in virtual windowed worlds in Smalltalk . All of these offered very different but converging visions for how people would engage computing interactively instead of through code, and elements of each of these systems emerged as the core components of modern graphical user interfaces.
Most of these ideas came together at Xerox PARC during the design and development of the Star. Its interface, shown at the beginning of this chapter, contained all of the elements you’re familiar with today. These elements are typically referred to with the acronym WIMP , which stands for Windows , Icons , Menus , and Pointer . This paradigm, which leveraged a desktop metaphor full of files, programs, and interactive widgets such as buttons, scroll bars, toggles, and other controls, became the dominant paradigm for desktop computing. And the paradigm persists: even in the newest smartphone, tablet, and AR/VR operating systems, we still interact with windows, icons, menus and other widgets in nearly identical ways. We may use multi-touch or gesture interactions, but these are just other ways of pointing.
In this chapter, we’ll discuss each of these concepts, and the ideas that followed, describing the problems WIMP was trying to solve and that ideas emerged to solve these problems. Understanding this history and foundation will help us understand the interface innovations that have come since.
Windows
The first big idea that emerged at Xerox PARC was the concept of a window . The fundamental problem that windows solved is how to provide visual access to a potentially infinite amount of content larger than the size of a screen on a fixed size display . It’s hard to imagine a world before windows, and to appreciate how much they shape our interactions with computers today until you think about the world in terms of programming interfaces: prior to windows, the only way of seeing a computer’s output was in a long temporal log of textual output. The idea of using two dimensions to display program output, and to use pixels instead of characters, and to allow for an infinite canvas of pixels, was incomprehensible.
Part of making windows work required inventing scroll bars , which solve the problem of how to navigate an infinite canvas of content. This invention was far from straightforward. For example, in this “All the Widgets” video, you can see a wide range of alternatives for how windows and scroll bars could work:
Some were just directional, instructing the window to move up or down a content area, much like the swiping gestures we use on touchscreens today to scroll. Others used a scroll bar “knob” to control what part of a larger document the window would show, where the size of the knob was proportional to the amount of content visible in the window (this is the idea that we see in operating systems today). These many iterations eventually converged toward the scroll bars we use today, which are sized proportional to the amount of content visible, and are draggable.
Researchers have since explored many more advanced techniques for windows and scrolling, including forms of scrolling that are aware of the underlying content to support non-linear navigation paths 6 , hardware input devices such as “scroll rings” to support movement through documents 11 , and techniques for intelligently collapsing content in displays to help a user focus on the content most relevant to their task 1 . Responsive web design, in which windows lay out their content based on the size of a window, shares similar ideas to these content aware techniques, in that it aims to automatically lay out content on a screen to fit the physical dimensions of different screen sizes 9 . All of these techniques involve linking metadata about the content to the layout and navigation of that content.
The invention of windows also required the invention of window managers . The problem here was deciding how to lay out windows on to a fixed sized display. There were countless ideas for different arrangements. The Star had windows that could be resized, dragged, and overlapped, which the Macintosh adopted, and led to the interaction designs we all use today. But early versions of Microsoft Windows had tiled windows (as shown above), which were non-overlapping grids of windows. Other variations involved “stacks” of windows, and keyboard shortcuts for flipping between them.
Of course, Windows, macOS, and Ubuntu now have many advanced window management features, allowing the user to see a zoomed out view with all active windows and move them to different virtual desktops. Modern mobile operating systems such as iOS, Android, and Windows Phone all eschewed multiple windows for a paradigm of one full-screen window at a time with navigation features for moving between full-screen applications. Researchers in the 1980’s were behind many of these innovations 12 , and researchers continue to innovate. For example, some have explored windows that are organized by tasks 18 .
Icons
How to display infinite content was one problem; another challenge was how to represent all of the code and data stored inside of a computer’s memory. Prior to the WIMP interfaces, invisibility was the norm: to know what applications or data were available, one had to type a command to list programs and files. This forced users to have to remember these commands, but also to constantly request these listings in order to navigate and find the applications or data they needed.
The Star eliminated the burden of remembering commands and requesting listings by inventing icons . With icons, all of these operations of seeing what was available, starting a program, or opening a file were mapped to a pointing device instead of a keyboard: double-clicking on a program to launch it, double-clicking on a document to open it, and dragging an icon to change its location in a file system. This also necessitated some notion of a “desktop,” on which program and document icons would be stored, providing a convenient place to start work. Again, none of these ideas had to work this way, and in fact, newer operating systems don’t: for many years, iOS did not expose a concept of files or a desktop. Instead, there were only icons for programs, and data is presented as living only “inside” that application. Of course, there are still files stored on the device, they are just managed by the application instead of by the user. Eventually, after much demand, Apple released a Files application to make files visible.
Menus and Forms
Programs have commands, which are essentially an API of functions that can be called to perform useful operations. The command lines that existed before WIMP interfaces required people to remember all of the commands available and how to property construct a command to execute them. Menus solved this problem by providing an always available visual list of commands, and forms for gathering data to execute them.
The earliest menus were simple lists of commands that could be selected with a pointing device. Some menus were attached to the border of a window, others were anchored to the top of the screen, and others still were contextual and attached to a specific icon or object representing some data, document, or program. You see all of these different types of menus in modern interfaces, with wide variation in where a menu is invoked. But all menus still behave like the original Star , and were mainstreamed with the introduction of the Macintosh, which borrowed the Star ’s design.
A key part of menu design was handling commands that required more input than a click. For example, imagine a menu item labeled “Sign in...” that signs the user into a service, asking for an email address and password. WIMP interfaces needed a way to gather that input. The Star team invented forms to solve this problem. Most forms are displayed in popup windows that solicit input from users before executing a command, though they come in many forms, such as sheets or “wizards” with multiple screens of forms.
While menus and forms don’t seem like a major opportunity for innovation, researchers have long studied more effective and efficient forms. For example, rather than linear lists of labels, researchers have explored things like hierarchical marking menus that are radial, can be moved through without clicking, and can result in a memory for pointing trajectories for rapid selection of items 19 . Other ideas have included menus that follow the mouse for quick access to contextual functionality 2 and fisheye menus that scale the size of command descriptions to fit larger numbers of commands in the same amount of space. Researchers have also explored forms that gather input from users in a floating dialog that still allows the user to interact with an application, so they can get information necessary to provide input 13 . And of course, modern voice interfaces found in smart speakers and phones are nothing more than spoken forms, which require all input to be conveyed as part of a spoken sentence.

Pointers
None of the core WIMP actions — moving a window, opening an application, selecting a command — are possible without the last element of WIMP, pointers . They solved a fundamental problem of interacting with a 2-dimensional display: how can a user indicate the window they want to move or resize, the icon they want to select, or the menu item they want to invoke? The key insight behind pointing is that so much about interacting with a computer requires a precise statement of what is being “discussed” in the dialog between the user and the computer. Pointers are a way of indicating the topic of discussion, just as pointing is in conversations between people.
The power of this idea becomes apparent when we consider interfaces without pointers. Consider, for example, speech interfaces. How might you tell a computer that you want to delete a file? In a speech interface, we might have to say something like “Delete the file in the folder named ‘Documents’ that has the name ‘report.txt’”, and it would be up to the computer to search for such a file, ask for clarification if there was more than one match, return an error if nothing was found, and of course, deal with any speech recognition mistakes that it made. Pointers solve all of those problems with a single elegant interaction, borrowed from human embodied interaction. We will talk about pointing in more detail in a later chapter.
Widgets
One can build entire interfaces out of windows, icons, menus, and pointers. However, application designers quickly realized that users need to do more than just open files, folders, and programs: they also need to provide input, and do so without making mistakes. Widgets are how we do this: sliders, check boxes, text boxes, radio buttons, drop down menus, and the many other controls found in graphical user interfaces are generally designed to make it possible to precisely specify an input within a certain set of constraints:
- Sliders provide a control for specifying continuous numeric values within a numeric range.
- Check boxes provide an error-free mechanism for specifying binary values (and sometimes tertiary values, which are often represented by a dash).
- Text boxes provide an interface for specifying string values, often with sophisticated error-prevention mechanisms such as form validation and user efficiency features such as auto-complete.
- Radio buttons and drop down menus provide error-preventing interfaces for specifying categorical values.
Each one of these widgets has been carefully designed to allow rapid, error-free, efficient input of each of these data types, and none were immediately obvious.
Of course, since these early widgets were invented, researchers have discovered many other types of widgets designed for data types that don’t map well onto this small set of primitive widgets. For example, some researchers have designed widgets for selecting time values on non-linear scales 8 .
Copy and paste
Another gap that the early inventors of WIMP interfaces noticed is that there was no easy way to move data between parts of WIMP interfaces. Prior to WIMP, copying information meant storing some information in a file, copying the file or concatenating its contents to another file, and then saving that file. Copy and paste brilliantly streamlined this data transfer process by simply creating a temporary storage place for data is not stored in a file.
Researchers have explored many ways to improve the power of this feature, including techniques that have greater semantic awareness of the content being copied, allowing it to be parsed and pasted in more intelligent ways 17 . Others have explored ways of moving data between different machines by giving copied data identity 15 or by synchronizing clipboards across devices 10 . Some of these features are now mainstream; for example, iOS supports a cloud synchronized clipboard that enables pasting content between different devices logged into the same iCloud account.

Direct manipulation
Throughout WIMP interfaces, there is a central notion of immediacy : one takes an action and gets a response. This idea, which we call direct manipulation 5 , is not specific to WIMP, but far more general. The essence behind direct manipulation is:
- The object of interest is always represented visually (e.g., the file you want to move is presented on a screen).
- Operating on the object involves invoking commands through physical action rather than notation (e.g., click and drag the file from the current folder to a different folder instead of writing a command line command telling the computer to move it).
- Feedback on the effect of an operation is immediately visible and is reversible (e.g., as you drag, the file moves, and if you change your mind, you can just move it back).
Direct manipulation interfaces, which include things like drag and drop interactions, or gesture-based interactions is in the Minority Report movie depicted above, can be learned quickly, can be efficient to use, can prevent errors. And because they are reversible, they can support rapid error recovery. Because of these benefits, many researchers have tried to translate tasks that traditionally require programming or other complex sequences of operations into direct manipulation interfaces. Early work explored things like alignment guides in drawing programs 14 , now popular in most graphic design software. Others have explored extensions of drag and drop to multiple devices, or more complex data manipulations 7 . More recently, researchers have applied techniques from programming languages and machine learning to support automatically converting sketches into scalable vector graphics suitable for the web 3 , to define the layout of data visualizations 4 , and to manipulate speech, music, and other audio more directly 16 . All of these leverage the same basic paradigm of explicit representation and manipulation of an object.

Non-WIMP interfaces
While all of the interactive interface ideas above are probably deeply familiar to you, it is important to remember that they are not natural in any way. They are entirely invented, artificial designs that solve very specific problems of presenting information to users, getting data from users, and supporting command invocation. The only reason they feel natural is because we practice using them so frequently. In designing interfaces, it’s reasonable to leverage everyone’s long history of practice with these old ideas. However, it’s also reasonable to question them when dealing with new types of data or interaction.
Games are the perfect example of this. They may have WIMP ideas in home screens and settings like menus and buttons, but the game play itself, and even some aspects of game menus, may avoid many aspects of WIMP. Consider for example, the lack of pointers on many video game consoles: rather than pointing to something, navigation is often by a directional pad or analog stick, giving discrete or continuous input about which trajectory a player wants to navigate in some space, but not a particular target. Or, consider the presence of non-player characters in games: the goal is not to execute commands on those characters, but interact with them for information, fight them, or perhaps even avoid them, and these behaviors are often not triggered by selecting things and invoking commands, but by pressing buttons, coming near something, or other gestures. These interfaces are still graphical, and often still have all of the features of direct manipulation, but are not WIMP in their interface metaphor.
As should be clear from the history above, nothing about graphical user interfaces is natural: every single aspect of them was invented to solve a particular problem, and could have been invented differently. One might argue, however, that humans do have relatively fixed abilities, and so some aspects of interactive interfaces were inevitable (we point to things in the physical world, so why wouldn’t we point to things in the virtual world?). Even if this is the case, it still takes hard work to invent these ways. Only after we find great designs do they become so ubiquitous that we take them for granted.
References
-
Patrick Baudisch, Xing Xie, Chong Wang, Wei-Ying Ma (2004). Collapse-to-zoom: viewing web pages on small screen devices by interactively removing irrelevant content. ACM Symposium on User Interface Software and Technology (UIST).
-
George Fitzmaurice, Azam Khan, Robert Pieké, Bill Buxton, Gordon Kurtenbach (2003). Tracking menus. ACM Symposium on User Interface Software and Technology (UIST).
-
Brian Hempel and Ravi Chugh (2016). Semi-automated SVG programming via direct manipulation. ACM Symposium on User Interface Software and Technology (UIST).
-
Thibaud Hottelier, Ras Bodik, Kimiko Ryokai (2014). Programming by manipulation for layout. ACM Symposium on User Interface Software and Technology (UIST).
-
Hutchins, E. L., Hollan, J. D.,, Norman, D. A. (1985). Direct manipulation interfaces. Human-Computer Interaction.
-
Edward W. Ishak and Steven K. Feiner (2006). Content-aware scrolling. ACM Symposium on User Interface Software and Technology (UIST).
-
Masatomo Kobayashi and Takeo Igarashi (2007). Boomerang: suspendable drag-and-drop interactions based on a throw-and-catch metaphor. ACM Symposium on User Interface Software and Technology (UIST).
-
Yuichi Koike, Atsushi Sugiura, Yoshiyuki Koseki (1997). TimeSlider: an interface to specify time point. ACM Symposium on User Interface Software and Technology (UIST).
- Ethan Marcotte. 2010. Responsive Web Design. A List Apart, No. 306
-
Robert C. Miller and Brad A. Myers (1999). Synchronizing clipboards of multiple computers. ACM Symposium on User Interface Software and Technology (UIST).
-
Tomer Moscovich and John F. Hughes (2004). Navigating documents with the virtual scroll ring. ACM Symposium on User Interface Software and Technology (UIST).
-
Myers, B. A. (1988). A taxonomy of window manager user interfaces. IEEE Computer Graphics and Applications.
-
Dennis Quan, David Huynh, David R. Karger, Robert Miller (2003). User interface continuations. ACM Symposium on User Interface Software and Technology (UIST).
-
Roope Raisamo and Kari-Jouko Räihä (1996). A new direct manipulation technique for aligning objects in drawing programs. ACM Symposium on User Interface Software and Technology (UIST).
-
Jun Rekimoto (1997). Pick-and-drop: a direct manipulation technique for multiple computer environments. ACM Symposium on User Interface Software and Technology (UIST).
-
Steve Rubin, Floraine Berthouzoz, Gautham J. Mysore, Wilmot Li, Maneesh Agrawala (2013). Content-based tools for editing audio stories. ACM Symposium on User Interface Software and Technology (UIST).
-
Jeffrey Stylos, Brad A. Myers, Andrew Faulring (2004). Citrine: providing intelligent copy-and-paste. ACM Symposium on User Interface Software and Technology (UIST).
-
Craig Tashman (2006). WindowScape: a task oriented window manager. ACM Symposium on User Interface Software and Technology (UIST).
-
Shengdong Zhao and Ravin Balakrishnan (2004). Simple vs. compound mark hierarchical marking menus. ACM Symposium on User Interface Software and Technology (UIST).

Interface Architecture
While the previous chapter discussed many of the seminal interaction paradigms we have invented for interacting with computers, we’ve discussed little about how all of the widgets, interaction paradigms, and other user interface ideas are actually implemented as software. This knowledge is obviously important for developers who implement buttons, scroll bars, gestures, and so on, but is this knowledge important for anyone else?
I argue yes. Much like a violinist needs to know whether a bow’s strings are made from synthetic materials or Siberian horse tail, a precise understanding of user interface implementation allows designers to have a precise understanding of how to compose widgets into user experiences. This helps designers and engineers to:
- Analyze limitations of interfaces
- Predict edge cases in their behavior, and
- Discuss their behavior precisely.
Knowing, for example, that a button only invokes its command after the mouse button is released allows one to reason about the assumptions a button makes about ability . The ability to hold a mouse button down, for example, isn’t something that all people have, whether due to limited finger strength, motor tremors that lead to accidental button releases, or other motor-physical limitations. These details allow designers to fully control what you make and how it behaves.
Knowledge of user interface implementation might also be important if you want to invent new interface paradigms. A low-level of user interface implementation knowledge allows you to see exactly how current interfaces are limited, and empowers you to envision new interfaces that don’t have those limitations. For example, when Apple redesigned their keyboards to have shallower (and reviled) depth , their design team needed deeper knowledge than just “pushing a key sends a key code to the operating system.” They needed to know the physical mechanisms that afford depressing a key, the tactile feedback those mechanisms provide, and the auditory feedback that users rely on to confirm they’ve pressed a key. Expertise in these physical qualities of the hardware interface of a keyboard was essential to designing a new keyboard experience.
Precise technical knowledge of user interface implementation also allows designers and engineers to have a shared vocabulary to communicate about interfaces. Designers should feel empowered to converse about interface implementation with engineers, knowing enough to critique designs and convey alternatives. Without this vocabulary and a grasp of these concepts, engineers retain power over user interface design, even though they aren’t trained to design interfaces.
States and Events
There are many levels at which designers might want to understand user interface implementation. The lowest—code—is probably too low level to be useful for the purposes above. Not everyone needs to understand, for example, the source code implementations of all of Windows or macOS’s widgets. Instead, here we will discuss user interface implementation at the architectural level. In software engineering, architecture is a high level view of code’s behavior: how it is organized into different units with a shared purpose, how data moves between different units, and which of these units is in charge of making decisions about how to respond to user interactions.
To illustrate this notion of architecture, let’s return to the example of a graphical user interface button. We’ve all used buttons, but rarely do we think about exactly how they work. Here is the architecture of a simple button, depicted diagrammatically:
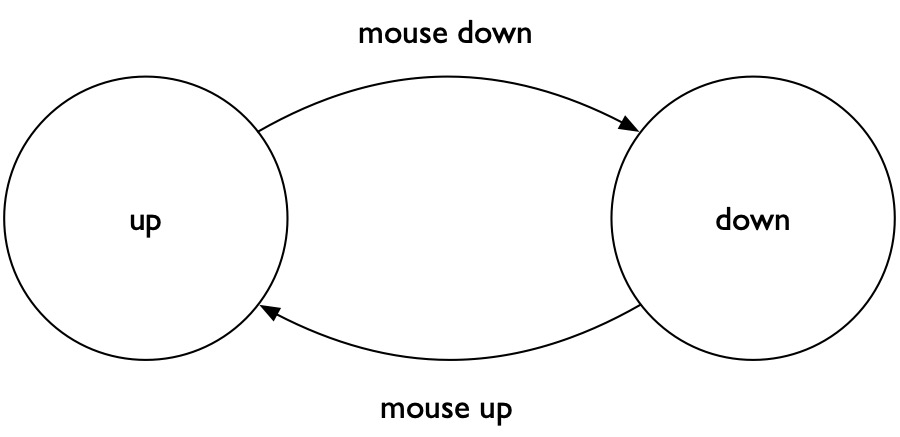
Computer scientists call this diagram a state machine , which is an abstract representation of different statestate: A particular mode or configuration of a user interface that can be changed through user input. For example, a button might be hovered over or not, or user on a web page might be logged in or not. that a computer program might be in. State machines also indicate the inputs that the can receive that cause them to move between different states. The button state machine above has two possible states: up (on the left) and down (on the right). In this state machine, there are two inputs that can cause changes in states. In user interface toolkits, these inputs are usually call eventsevent: A user input such as a mouse click, tap, drag, or verbal utterance that may trigger a state change in a user interface’s state. , because they are things that users do at a particular point in time. The first event is when the button receives a mouse down event, after a user clicks a mouse button while the pointer is over the button. This event causes the state machine to transition from the up state to the down state. The button stays in this state until it later receives a mouse up event from the user, when they release the mouse button; this causes the button to transition to the up state and also executes its command. This is about as simple as button statement machines get.
Representing a state machine in code involves translating the abstract logic as in the diagram above into a programming language and user interface toolkit. For example, here is an implementation of the button above in JavaScript, using the popular React framework:
class MyFancyNewButton extends React.Component {
// This function changes the button's "down" state to false.
// The function "setState" is a powerful React function, which
// tells React to update the state, and at some point in the future,
// call the "render" function below to update the view. It
// then executes the command for the button.
handleUp() {
this.setState({down: false});
this.executeCommand();
}
// Like "handleUp", this function changes the "down" state,
// but to true, and also causes React to call the "render"
// function below to update the view.
handleDown() {
this.setState({down: true});
}
executeCommand() {
// Do something exciting when clicked!
}
// This function renders the presentation of the button
// based on the value of the "down" property. If it's true,
// it renders a dark gray rectangle and the label "I'm down";
// if it's false, it renders a light gray rectangle
// with the label "I'm up".
render() {
if(this.state.down)
return <div
style={{background: "darkGrey"}}
onMouseUp={this.handleUp}>
I'm down!
</div>
else
return <div
style={{background: "lightGrey"}}
onMouseDown={this.handleDown}>
I'm up!
</div>
}
} To understand the code above, the comments marked with the text // are your guide. The render() function at the bottom describes how the button should appear in its two different states: dark grey with the text “I’m down” when in the down state and light gray with the text “I’m up” in the up state. Notice how the handleUp() and handleDown() functions are assigned to the onMouseUp and onMouseDown event handlers. These functions will execute when the button receives those corresponding events, changing the button’s state (and its corresponding appearance) and executing executeCommand() . This function could do anything — submit a form, display a message, compute something — but it currently does nothing. None of this implementation is magic — in fact, we can change the state machine by changing any of the code above, and produce a button with very different behavior. The rest of the details are just particular ways that JavaScript code must be written and particular ways that React expects JavaScript code to be organized and called; all can be safely ignored, as they do not affect the button’s underlying architecture, and could have been written in any other programming language with any other user interface toolkit.
The buttons in modern operating systems actually have much more complex state machines than the one above. Consider, for example, what happens if the button is in a down state, but the mouse cursor moves outside the boundary of the button and then a mouse up event occurs. When this happens, it transitions to the up state, but does not execute the button’s command. (Try this on a touchscreen: tap on a button, slide your finger away from it, then release, and you’ll see the button’s command isn’t executed). Some buttons have an inactive state, in which they will not respond to any events until made active. If the button supports touch input, then a button’s state machine also needs to handle touch events in addition to mouse events. And to be accessible to people who rely on keyboards, buttons also need to have a focused and unfocused state and respond to things like the space or enter key being typed while focused. All of these additional states and events add more complexity to a button’s state machine.
All user interface widgets are implemented in similar ways, defining a set of states and events that cause transitions between those states. Scroll bar handles respond to mouse down , drag , and mouse up events, text boxes respond to keypress events, links respond to mouse down and mouse up events. Even text in a web browser or text editor response to mouse down , drag , and mouse up events to enter a text selection state.
Model-View-Controller
State machines are only part of implementing a widget, the part that encodes the logic of how a widget responds to user input. What about how the widget is presented visually, or how bits of data are stored, such as the text in a text field or the current position of a scroll bar?
The dominant way to implement these aspects of widgets, along with the state machines that determine their behavior, is to follow a model-view-controllermodel-view-controller: A way of organizing a user interface implementation to separate how data is stored (the model), how data is presented (the view), and how data is changed in response to user input (the controller). (MVC) architecture. One can think of MVC as a division of responsibilities in code between storing and retrieving data (the model ), presenting data and listening for user input (the view ), and managing the interaction between the data storage and the presentation using the state machine (the controller ). This architecture is ubiquitous in user interface implementation.
To illustrate how the architecture works, let’s consider a non-user interface example. Think about the signs that are often displayed on gas station or movie theaters. Something is responsible for storing the content that will be shown on the signs; perhaps this is a piece of paper with a message, or a particularly organized gas station owner has a list of ideas for sign messages stored in a notebook. Whatever the storage medium, this is the model . Someone else is responsible for putting the content on the signs based on whatever is in the model; this is the view responsibility. And, of course, someone is in charge of deciding when to retrieve a new message from the model and telling the person in charge of the view to update the sign. This person is the controller .
In the same way as in the example above, MVC architectures in user interfaces take an individual part of an interface (e.g., a button, a form, a progress bar, or even some complex interactive data visualization on a news website) and divide its implementation into these three parts. For example, consider the example below of a post on a social media site like Facebook:
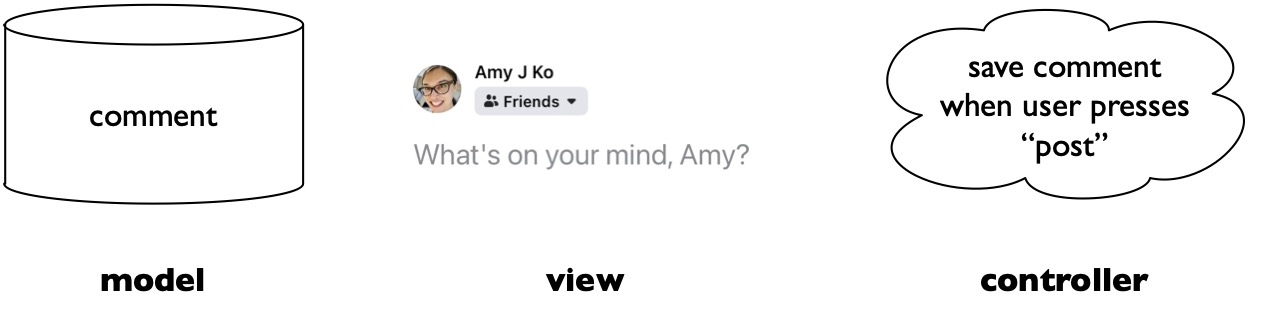
In this interface:
- The model stores the data that a user interface is presenting. For example, in the figure above, this would be the comment that someone is typing and posting. In the case of social media, the model might include both the part of memory storing the comment being typed, but also the database stored on Facebook’s servers that persists the comment for later display.
- The view visualizes the data in the model. For example, in the figure above, this includes the text field for the comment, but also the profile image, the privacy drop down menu, and the name. The view’s job is to render these controls, listen for input from the user (e.g., pressing the post button to submit the comment), and display any output the controller decides to provide (e.g., feedback about links in the post).
- The controller makes decisions about how to handle user input and how to update the model. In our comment example above, that includes validating the comment (e.g., it can’t be empty), and submitting the comment when the user presses enter or the post button. The controller gets and set data in the model when necessary and tells the view to update itself as the model changes.
View Hierarchies
If every individual widget in a user interface is its own self-contained model-view-controller architecture, how are all of these individual widgets composed together into a user interface? There are three big ideas that stitch together individual widgets into an entire interface.
First, all user interfaces are structured as hierarchies in which one widget can contain zero or more other “child” widgets, and each widget has a parent, except for the “root” widget (usually a window). For instance, here’s the Facebook post UI we were discussing earlier and its corresponding hierarchy:
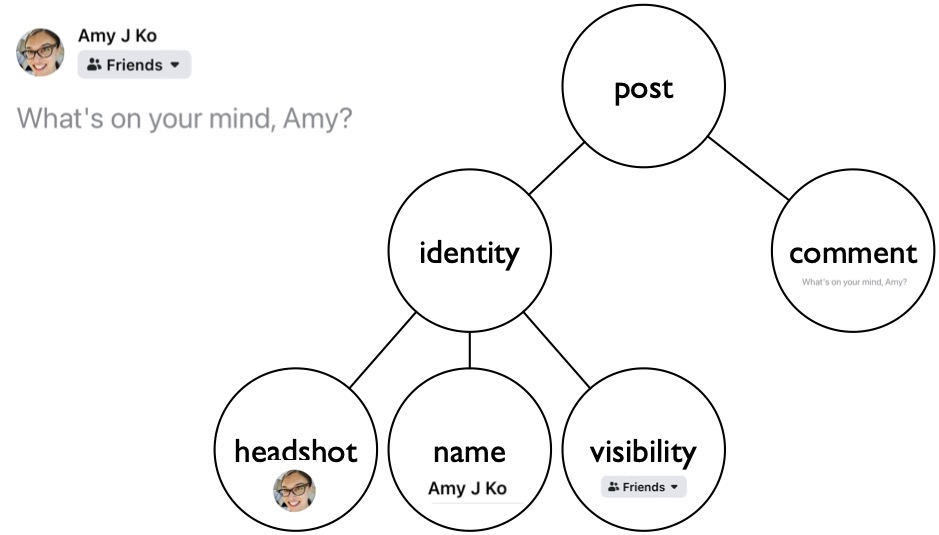
Notice how there are some components in the tree above that aren’t visible in the UI (the “post”, the “editor”, the “special input” container). Each of these are essentially containers that group components together. These containers are used to give widgets a layout , in which the children of each component are organized spatially according to some layout rule. For example, the special input widgets are laid out in a horizontal row within the special inputs container and the special inputs container itself is laid out right aligned in the “editor” container. Each component has its own layout rules that govern the display of its children.
Finally, event propagation is the process by which user interface events move from a physical device to a particular user interface component in a larger view hierarchy. Each device has its own process, because it has its own semantics. For instance:
- A mouse emits mouse move events and button presses and releases. All of these are emitted as discrete hardware events to the operating system. Some events are aggregated into synthetic events like a click (which is really a mouse press followed by a mouse release, but not a discrete event a mouse’s hardware). When the operating system receives events, it first decides which window will receive those events by comparing the position of the mouse to the position and layering of the windows, finding the topmost window that contains the mouse position. Then, the window decides which component will handle the event by finding the topmost component whose spatial boundaries contain the mouse. That event is then sent to that component. If the component doesn’t handle the event (e.g., someone clicks on some text in a web browser that doesn’t respond to clicks), the event may be propagated to its parent, and to its parent’s parent, etc, seeing if any of the ancestors in the component hierarchy want to handle the event. Every user interface framework handles this propagation slightly differently, but most follow this basic pattern.
- A keyboard emits key down and key up events, each with a key code that corresponds to the physical key that was pressed. As with a mouse, sequences are synthesized into other events (e.g., a key down followed by a key up with the same key is a key “press”). Whereas a mouse has a position, a keyboard does not, and so operating systems maintain a notion of window focus to determine which window is receiving key events, and then each window maintains a notion of keyboard focus to determine which component receives key events. Operating systems are then responsible for providing a visible indicator of which component has keyboard focus (perhaps giving it a border highlight and showing a blinking text caret). As with mouse events, if the component with focus does not handle a keyboard event, it may be propagated to its ancestors and handled by one of them. For example, when you press the escape key when a confirmation dialog is in focus, the button that has focus will ignore it, but the dialog window may interpret the escape key press as a “cancel”.
- A touch screen emits a stream of touch events, segmented by start, move, and end events. Other events include touch cancel events, such as when you slide your finger off of a screen to indicate you no longer want to touch. This low-level stream of events is converted by operating systems and applications into touch gestures. Most operating systems recognize a class of gestures and emit events for them as well, allowing user interface controls to respond to them.
- Even speech interfaces emit events. For example, digital voice assistants are continuously listening for activation commands such as “Hey Siri” or “Alexa.” After these are detected, they begin converting speech into text, which is then matched to one or more commands. Applications that expose a set of commands then receive events that trigger the application to process the command. Therefore, the notion of input events isn’t inherently tactile; it’s more generally about translating low-level inputs into high-level commands.
Every time a new input device has been invented, user interface designers and engineers have had to define new types of events and event propagation rules to decide how inputs will be handled by views within a larger view hierarchy.
Advances in Architecture
While the basic ideas presented above are now ubiquitous in desktop and mobile operating systems, the field of HCI has rapidly innovated beyond these original ideas. For instance, much of the research in the 1990’s focused on building more robust, scalable, flexible, and powerful user interface toolkits for building desktop interfaces. The Amulet toolkit was one of the most notable of these, offering a unified framework for supporting graphical objects, animation, input, output, commands, and undo 23 . At the same time, there was extensive work on constraint systems, which would allow interface developers to declaratively express rules the interface must follow (e.g., this button should always be next to this other button) 2,13 . Other projects sought to make it easier to “skin” aa Skin, as in giving the “skeleton” of an interface a different covering. Gross metaphor, huh? the visual appearance of interfaces without having to modify a user interface implementation 14 .
Research in the 2000’s shifted to deepen these ideas. For example, some work investigated alternatives to component hierarchies such as scene graphs 16 and views across multiple machines 19 , making it easier to build heavily animated and connected interfaces. Some works deepened architectures for supporting undo and redo 6 . Many of these ideas are now common in modern user interface toolkits, especially the web, in the form of CSS and its support for constraints, animations, and layout separate from interface behavior.
Other research has looked beyond traditional WIMP interfaces, creating new architectures to support new media. The DART toolkit, for example, invented several abstractions for augmented reality applications 9 . Researchers contributed architectures for digital ink applications 11 , zoomable interfaces 1 , peripheral displays that monitor user attention 22 , data visualizations 3 , tangible user interfaces made of physical components 10,18 , interfaces based on proximity between people and objects 21 , and multi-touch gestures 17 . Another parallel sequence of work explored the general problem of handling events that are uncertain or continuous, investigating novel architectures and error handling strategies to manage uncertainty 12,20,28 . Each one of these toolkits contributed new types of events, event handling, event propagation, synthetic event processing, and model-view-controller architectures tailored to these inputs, enabling modern “natural” interfaces leverage probablistic models from machine learning.
While much of the work in user interface architecture has sought to contribute new architectural ideas for user interface construction, some have focused on ways of modifying user interfaces without modifying their underlying code. For example, one line of work has explored how to express interfaces abstractly, so these abstract specifications can be used to generate many possible interfaces depending on which device is being used 7,25,26 . Other systems have invented ways to modify interface behavior by intercepting events at runtime and forcing applications to handle them differently 5 . Some systems have explored ways of directly manipulating interface layout during use 29 and transforming interface presentation 8 . More recent techniques have taken interfaces as implemented, reverse engineered their underlying commands, and generated new, more accessible, more usable, and more powerful interfaces based on these reverse engineered models 30 .
A smaller but equally important body of work has investigated ways of making interfaces easier to test and debug. Some of these systems expose information about events, event handling, and finite state machine state 15 . Some have invented ways of recording and replaying interaction data with interfaces to help localize defects in user interface behavior 4,24 . Some have even investigated the importance of testing security vulnerabilities in user interfaces, as interfaces like copy and paste transact and manipulate sensitive information 27 .
Conclusion
Considering this body of work as a whole, there are some patterns that become clear:
- Model-view-controller is a ubiquitous architectural style in user interface implementation.
- User interface toolkits are essential to making it easy to implement interfaces.
- New input techniques require new user interface architectures, and therefore new user interface toolkits.
- Interfaces can be automatically generated, manipulated, inspected, and transformed, but only within the limits of the architecture in which they are implemented.
- The architecture an interface is built in determines what is difficult to test and debug.
These “laws” of user interface implementation can be useful for making predictions about the future. For example, if someone proposes incorporating a new sensor in a device, subtle details in the sensor’s interactive potential may require new forms of testing and debugging, new architectures, and potentially new toolkits to fully leverage its potential. That’s a powerful prediction to be able to make and one that many organizations overlook when they ship new devices.
References
-
Benjamin B. Bederson, Jon Meyer, Lance Good (2000). Jazz: an extensible zoomable user interface graphics toolkit in Java. ACM Symposium on User Interface Software and Technology (UIST).
-
Krishna A. Bharat and Scott E. Hudson (1995). Supporting distributed, concurrent, one-way constraints in user interface applications. In Proceedings of the 8th annual ACM symposium on User interface and software technology (UIST '95).
-
Michael Bostock and Jeffrey Heer (2009). Protovis: A Graphical Toolkit for Visualization. IEEE Transactions on Visualizations and Computer Graphics.
-
Brian Burg, Richard Bailey, Amy J. Ko, Michael D. Ernst (2013). Interactive record/replay for web application debugging. ACM Symposium on User Interface Software and Technology (UIST).
-
James R. Eagan, Michel Beaudouin-Lafon, Wendy E. Mackay (2011). Cracking the cocoa nut: user interface programming at runtime. ACM Symposium on User Interface Software and Technology (UIST).
-
W. Keith Edwards, Takeo Igarashi, Anthony LaMarca, Elizabeth D. Mynatt (2000). A temporal model for multi-level undo and redo. ACM Symposium on User Interface Software and Technology (UIST).
-
W. Keith Edwards and Elizabeth D. Mynatt (1994). An architecture for transforming graphical interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
W. Keith Edwards, Scott E. Hudson, Joshua Marinacci, Roy Rodenstein, Thomas Rodriguez, Ian Smith (1997). Systematic output modification in a 2D user interface toolkit. ACM Symposium on User Interface Software and Technology (UIST).
-
Gandy, M., & MacIntyre, B. (2014). Designer's augmented reality toolkit, ten years later: implications for new media authoring tools. In Proceedings of the 27th annual ACM symposium on User interface software and technology (pp. 627-636).
-
Saul Greenberg and Chester Fitchett (2001). Phidgets: easy development of physical interfaces through physical widgets. ACM Symposium on User Interface Software and Technology (UIST).
-
Jason I. Hong and James A. Landay (2000). SATIN: a toolkit for informal ink-based applications. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson and Gary L. Newell (1992). Probabilistic state machines: dialog management for inputs with uncertainty. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson and Ian Smith (1996). Ultra-lightweight constraints. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson and Ian Smith (1997). Supporting dynamic downloadable appearances in an extensible user interface toolkit. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson, Roy Rodenstein, Ian Smith (1997). Debugging lenses: a new class of transparent tools for user interface debugging. ACM Symposium on User Interface Software and Technology (UIST).
-
Stéphane Huot, Cédric Dumas, Pierre Dragicevic, Jean-Daniel Fekete, Gerard Hégron (2004). The MaggLite post-WIMP toolkit: draw it, connect it and run it. ACM Symposium on User Interface Software and Technology (UIST).
-
Kenrick Kin, Bjoern Hartmann, Tony DeRose, Maneesh Agrawala (2012). Proton++: a customizable declarative multitouch framework. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott R. Klemmer, Jack Li, James Lin, James A. Landay (2004). Papier-Mache: toolkit support for tangible input. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Eric Lecolinet (2003). A molecular architecture for creating advanced GUIs. ACM Symposium on User Interface Software and Technology (UIST).
-
Jennifer Mankoff, Scott E. Hudson, Gregory D. Abowd (2000). Interaction techniques for ambiguity resolution in recognition-based interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Nicolai Marquardt, Robert Diaz-Marino, Sebastian Boring, Saul Greenberg (2011). The proximity toolkit: prototyping proxemic interactions in ubiquitous computing ecologies. ACM Symposium on User Interface Software and Technology (UIST).
-
Tara Matthews, Anind K. Dey, Jennifer Mankoff, Scott Carter, Tye Rattenbury (2004). A toolkit for managing user attention in peripheral displays. ACM Symposium on User Interface Software and Technology (UIST).
-
Myers, Brad A., Richard G. McDaniel, Robert C. Miller, Alan S. Ferrency, Andrew Faulring, Bruce D. Kyle, Andrew Mickish, Alex Klimovitski, Patrick Doane (1997). The Amulet environment: New models for effective user interface software development. IEEE Transactions on Software Engineering.
-
Mark W. Newman, Mark S. Ackerman, Jungwoo Kim, Atul Prakash, Zhenan Hong, Jacob Mandel, Tao Dong (2010). Bringing the field into the lab: supporting capture and replay of contextual data for the design of context-aware applications. ACM Symposium on User Interface Software and Technology (UIST).
-
Jeffrey Nichols, Brad A. Myers, Michael Higgins, Joseph Hughes, Thomas K. Harris, Roni Rosenfeld, Mathilde Pignol (2002). Generating remote control interfaces for complex appliances. ACM Symposium on User Interface Software and Technology (UIST).
-
Jeffrey Nichols, Brandon Rothrock, Duen Horng Chau, Brad A. Myers (2006). Huddle: automatically generating interfaces for systems of multiple connected appliances. ACM Symposium on User Interface Software and Technology (UIST).
-
Franziska Roesner, James Fogarty, Tadayoshi Kohno (2012). User interface toolkit mechanisms for securing interface elements. ACM Symposium on User Interface Software and Technology (UIST).
-
Julia Schwarz, Scott Hudson, Jennifer Mankoff, Andrew D. Wilson (2010). A framework for robust and flexible handling of inputs with uncertainty. ACM Symposium on User Interface Software and Technology (UIST).
-
Wolfgang Stuerzlinger, Olivier Chapuis, Dusty Phillips, Nicolas Roussel (2006). User interface facades: towards fully adaptable user interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Amanda Swearngin, Amy J. Ko, James Fogarty (2017). Genie: Input Retargeting on the Web through Command Reverse Engineering. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).

Pointing
Thus far, we have focused on universal issues in user interface design and implementation. This chapter will be the first in which we discuss specific paradigms of interaction and the specific theory that underlies them. Our first topic will be pointing .
What is pointing?
Fingers can be pretty handy (pun intended). When able, we use them to grasp nearly everything. We use them to communicate through signs and gesture. And at a surprisingly frequent rate each day, we use them to point , in order to indicate, as precisely as we can, the identity of something (that person, that table, this picture, those flowers). As a nearly universal form of non-verbal communication, it’s not surprising then that pointing has been such a powerful paradigm of interaction with user interfaces (that icon, that button, this text, etc.).
Pointing is not strictly related to interface design. In fact, back in the early 1950s, Paul M. Fitts was very interested in modeling human performance of pointing. He began developing predictive models about pointing in order to help design dashboards, cockpits, and other industrial designs for manufacturing. His focus was on “aimed” movements, in which a person has a target they want to indicate and must move their pointing device (originally, their hand) to indicate that target. This kind of pointing is an example of a “closed loop” motion, in which a system (e.g., the human) can react to its evolving state (e.g., here the human’s finger is in space relative to its target). A person’s reaction is the continuous correction of their trajectory as they move toward a target. Fitts began measuring this closed loop movement toward targets, searching for a pattern that fit the data, and eventually found this law, which we call Fitts’ Law :
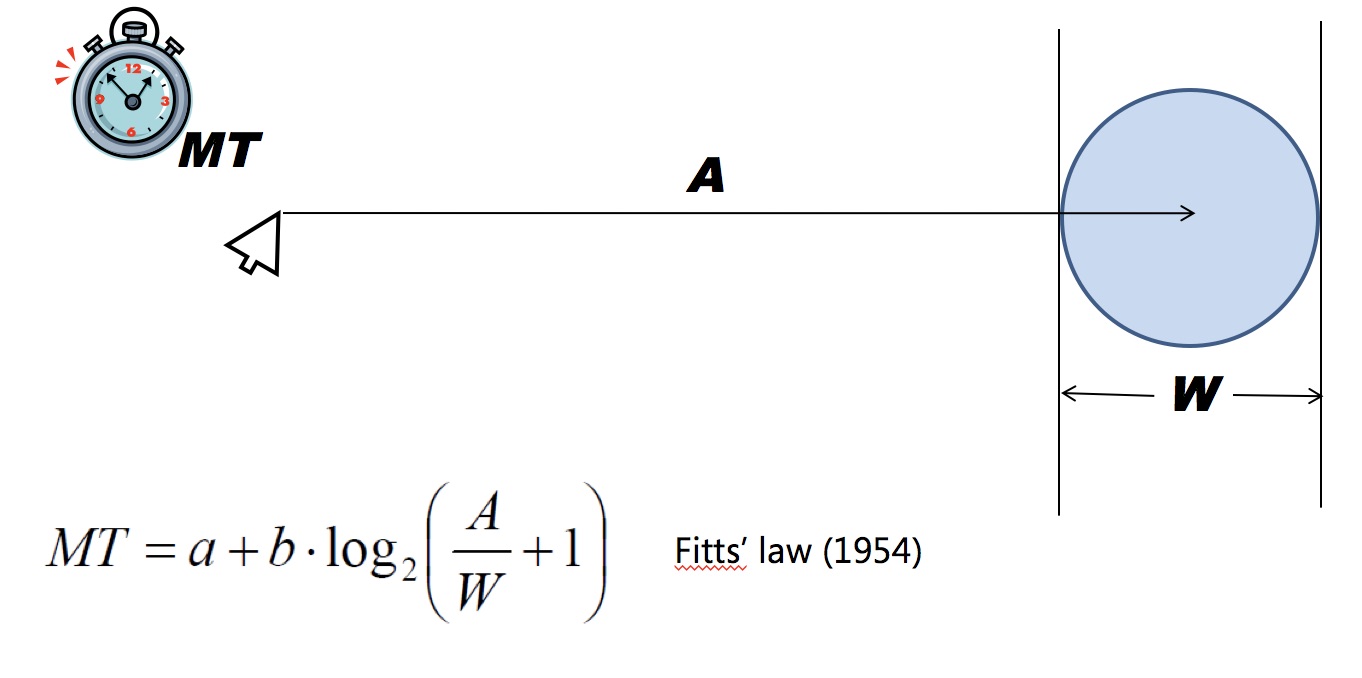
Let’s deconstruct this equation:
- The formula computes the time to reach a target ( MT refers to “motion time”). This is, simply, the amount of time it would take for a person to move their pointer (e.g., finger, stylus) to precisely indicate a target. Computing this time is the goal of Fitt’s law, as it allows us to take some set of design considerations and make a prediction about pointing speed.
- The A in the figure is how far one must move to reach the target (e.g. how far your finger has to move from where it is to reach a target on your phone’s touch screen. Imagine, for example, moving your hand to point to an icon on your smartphone; that’s a small A . Now, imagine moving a mouse cursor on a wall-sized display from one side to the next. That would be a large A . The intuition behind accounting for the distance is that the larger the distance one must move to point, the longer it will take.
- The W is the size (or “width”) of the target. For example, this might be the physical length of an icon on your smartphone’s user interface, or the length of the wall in the example above. The units on these two measures don’t really matter as long as they’re the same, because the formula above computes the ratio between the two, canceling the units out. The intuition behind accounting for the size of the target is that the larger the target, the easier it is to point to (and the smaller the target, the harder it will be).
- The a coefficient is a user- and device-specific constant. It is some fixed constant minimum time to move; for example, this might be the time it takes for your desire to move your hand results in your hand actually starting to move, or any lag between moving a computer mouse and the movement starting on the computer. The movement time is therefore, at a minimum, a . This varies by person and device, accounting for things like reflexes and latency in devices.
- The b coefficient is a measure of how efficiently movement occurs. Imagine, for example, a computer mouse that weighs 5 pounds; that might be a large b , making movement time slower. A smaller b might be something like using eye gaze in a virtual reality setting, which requires very little energy. This also varies by person and device, accounting for things like user strength and the computational efficiency of a digital pointing device.
This video illustrates some of these concepts visually:
So what does the formula mean ? Let’s play with the algebra. When A (distance to target) goes up, time to reach the target increases. That makes sense, right? If you’re using a touch screen and your finger is far from the target, it will take longer to reach the target. What about W (size of target)? When that goes up, the movement time goes down . That also makes sense, because easier targets (e.g., bigger icons) are easier to reach. If a goes up, the minimum movement time will go up. Finally, if b goes up, movement time will also increase, because movements are less efficient. The design implications of this are quite simple: if you want fast pointing, make sure 1) the target is close, 2) the target is big, 3) the minimum movement time is small, and 4) movement is efficient.
There is one critical detail missing from Fitt’s law: errors. You may have the experience, for example, of moving a mouse cursor to a target and missing it, or trying to tap on an icon on a touch screen, and missing it. These types of pointing “errors” are just as important is movement time, because if we make a mistake, we may have to do the movement all over again. Wobbrock et al. considered this gap and found that Fitts’ law itself actually strongly implies a speed accuracy tradeoff: the faster one moves during pointing, the less likely one is to successfully reach a target. However, they also showed experimentally that the particular error rates are more sensitive to some factors than others: a and b strongly influence error rates, and to a lesser extent, target size W matters more than target distance A 16 . Conceptually, this suggests that the likelihood of errors has a lot more to do with a person’s baseline motor abilities and the the design of a device rhather than the difficulty of a particular pointing task.
What does pointing have to do with user interfaces?
But there are some other interesting implications for user interface design in the algebraic extremes. For example, what if the target size is infinite ? An example of this is the command menu in Apple Mac OS applications, which is always placed at the very top of a screen. The target in this case is the top of the screen, which is effectively infinite in size, because no matter how far past the top of the screen you point with a mouse, the operating system always constrains the mouse position to be within the screen boundaries. This makes the top of the screen (and really any side of the screen) a target of infinite size. A similar example is the Windows Start button, anchored to the corner of the screen. And according to Fitts’ Law, these infinite target sizes means effectively zero movement time. That’s why it’s so quick to reach the menu on Mac OS and the Start button on Windows: you can’t miss.

What’s surprising about Fitts’ Law is that, as far as we know, it applies to any kind of pointing: using a mouse, using a touch screen, using a trackball, using a trackpad, or reaching for an object in the physical world. That’s conceptually powerful because it means that you can use the idea of large targets and short distance to design interfaces that are efficient to use. As a mathematical model used for prediction, it’s less powerful: to really predict exactly how long a motion will take, you’d need to estimate a distribution of those a and b coefficients for a large group of possible users and devices. Researchers carefully studying motion might use it to do precise modeling, but for designers, the concepts it uses are more important.
Now that we have Fitts’ law as a conceptual foundation for design, let’s consider some concrete design ideas for pointing in interfaces. There are so many kinds: mice, styluses, touch screens, touch pads, joysticks, trackballs, and many other devices. Some of these devices are direct pointingdirect pointing: Pointing devices in which the input for pointing and the corresponding feedback in response occur in the same physical place (e.g., a touchscreen). devices (e.g., touch screens), in which input and output occur in the same physical place (e.g., a screen or some other surface). In contrast, indirect pointingindirect pointing: Pointing devices in which the input for pointing and the corresponding feedback in response occur in different physical places (e.g., a mouse and a screen). devices (e.g., a mouse, a touchpad, a trackball) provide input in a different physical place from where output occurs (e.g., input on a device, output on a non-interactive screen). Each has their limitations: direct pointing can result in occlusion where a person’s hand obscures output, and indirect pointing requires a person to attend to two different places.
There’s also a difference between absoluteabsolute pointing: Pointing devices in which the physical coordinates of input are mapped directly onto the interface coordinate system (e.g., touchscreens). and relativerelative pointing: Pointing devices in which changes in the physical coordinates of input device are mapped directly changes to the current position in an interface coordinate system (e.g., mice). pointing. Absolute pointing includes input devices where the physical coordinate space of input is mapped directly onto the coordinate space in the interface. This is how touch screens work (bottom left of the touch screen is bottom left of the interface). In contrast, relative pointing maps changes in a person’s pointing to changes in the interface’s coordinate space. For example, moving a mouse left an inch is translated to moving a virtual cursor some number of pixels left. That’s true regardless of where the mouse is in physical space. Relative pointing allows for variable gain , meaning that mouse cursors can move faster or slower depending on a user’s preferences. In contrast, absolute pointing cannot have variable gain, since the speed of interface motion is tied to the speed of a user’s physical motion.
How can we make pointing better?
When you think about these two dimensions from a Fitts’ law perspective, making input more efficient is partly about inventing input devices that minimize the a and b coefficients. For example, researchers have invented new kinds of mice that have multi-touch on them, allowing users to more easily provide input during pointing movements 15 . Other research has explored taking normal pointing devices and preserving the physical measurements of input rather than mapping them to integer number spaces, enabling sub-pixel precision in mouse movement for tasks like minute-level precision in calendar event creation, pixel-level image cropping, and precise video frame selection 14 . Others have invented new types of pointing devices altogether, such as the LightRing (see in the video below), which involves sensing of infrared proximity between a finger and a surface to point 11 . Some devices have been invented for 3D pointing using magnetic field sensing 4 . Other techniques have tried to detect individual fingers on touchscreens, enabling multiple independent streams of pointing input 9 . All of these device manipulations seek to decrease pointing time by increasing how much input a person can provide, while decreasing effort.
Other innovations focus on software, and aim to increase target size or reduce travel distance. Many of these ideas are target-agnostic approaches that have no awareness about what a user might be pointing to . Some target-agnostic techniques include things like mouse pointer acceleration, which is a feature that makes the pointer move faster if it determines the user is trying to travel a large distance 3 . This technique is target-agnostic because it doesn’t know where the mouse is moving to, it just knows that the pointer is moving fast. Another example is the Angle Mouse, which analyzes the angles of movement trajectory, reducing gain when a user is trying to “turn,” effectively making the target larger by slowing down the mouse, making it easier to reach 17 . This technique is target-agnostic because it doesn’t know where the user is turning to, just that the pointer is turning. These ideas are powerful because the operating system does not need any awareness of the things a user is trying to point to in a user interface, making it easier those interfaces easier to implement.
Other pointing innovations are target-aware , in that the technique needs to know the location of things that a user might be pointing to so that it can adapt based on target locations. For example, area cursors are the idea of having a mouse cursor represent an entire two-dimensional space rather than a single point, reducing the distance to targets. These have been applied to help users with motor impairments 7 . The Bubble Cursor is an area cursor that dynamically resizes a cursor’s activation area based on proximity to a target, growing it to the maximum possible size based on the surrounding targets 8 . Cursors like this make it much easier for people with motor impairments (e.g., Parkinson’s disease), to click on targets with a mouse, even when their hands “tremor”, making unexpected, unwanted movements. You can see one improvement to the Bubble Cursor, the Bubble Lens, in the video below, showing how the Lens magnifies content in target-dense spaces 13 , making it even easier for people who lack the ability to finely coordinate their motor movements to click on targets.
Snapping is another target-aware technique commonly found in graphic design tools, in which a mouse cursor is constrained to a location based on nearby targets, reducing target distance. Researchers have made snapping work across multiple dimensions simultaneously 6 and have even applied it to things like scrolling, snapping to interesting content areas 12 . Another clever idea is the notion of crossing , which, instead of pointing and clicking, involves moving across a “goal line” 2 . Shown in the image below, crossing can allow for fluid movements through commands and controls without ever clicking.
While target-aware techniques can be even more efficient than target-agnostic ones, making an operating system aware of targets can be hard, because user interfaces can be architected to process pointing input in such a variety of ways. Some research has focused on overcoming this challenge. For example, one approach reverse-engineered the widgets on a screen by analyzing the rendered pixels to identify targets, then applied targeted-aware pointing techniques like the bubble cursor 5 . Another technique used a data-driven technique, monitoring where in a window users typically point, and then assuming targets are there, applying target-aware pointing techniques 10 . Some have gone as far as using brain-sensing techniques to detect when someone is in a period of difficult multitasking, then during that period, increasing the size of high priority targets, while decreasing the size of low priority targets 1 .
You might be wondering: all this work for faster pointing? Fitts’ law and its focus on speed is a very narrow way to think about the experience of pointing to computers. And yet, it is such a fundamental and frequent part of how we interact with computers; making pointing fast and smooth is key to allowing a person to focus on their task and not on the low-level act of pointing. This is particularly true of people with motor impairments, which interfere with their ability to precisely point: every incremental improvement in one’s ability to precisely point to a target might amount to hundreds or thousands of easier interactions a day, especially for people who depend on computers to communicate and connect with the world.
References
-
Daniel Afergan, Tomoki Shibata, Samuel W. Hincks, Evan M. Peck, Beste F. Yuksel, Remco Chang, Robert J.K. Jacob (2014). Brain-based target expansion. ACM Symposium on User Interface Software and Technology (UIST).
-
Georg Apitz and François Guimbretière (2004). CrossY: a crossing-based drawing application. ACM Symposium on User Interface Software and Technology (UIST).
-
Casiez, G., Vogel, D., Balakrishnan, R., & Cockburn, A. (2008). The impact of control-display gain on user performance in pointing tasks. Human-Computer Interaction.
-
Ke-Yu Chen, Kent Lyons, Sean White, Shwetak Patel (2013). uTrack: 3D input using two magnetic sensors. ACM Symposium on User Interface Software and Technology (UIST).
-
Morgan Dixon, James Fogarty, Jacob Wobbrock (2012). A general-purpose target-aware pointing enhancement using pixel-level analysis of graphical interfaces. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Marianela Ciolfi Felice, Nolwenn Maudet, Wendy E. Mackay, Michel Beaudouin-Lafon (2016). Beyond Snapping: Persistent, Tweakable Alignment and Distribution with StickyLines. ACM Symposium on User Interface Software and Technology (UIST).
-
Leah Findlater, Alex Jansen, Kristen Shinohara, Morgan Dixon, Peter Kamb, Joshua Rakita, Jacob O. Wobbrock (2010). Enhanced area cursors: reducing fine pointing demands for people with motor impairments. ACM Symposium on User Interface Software and Technology (UIST).
-
Tovi Grossman and Ravin Balakrishnan (2005). The bubble cursor: enhancing target acquisition by dynamic resizing of the cursor's activation area. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Aakar Gupta, Muhammed Anwar, Ravin Balakrishnan (2016). Porous interfaces for small screen multitasking using finger identification. ACM Symposium on User Interface Software and Technology (UIST).
-
Amy Hurst, Jennifer Mankoff, Anind K. Dey, Scott E. Hudson (2007). Dirty desktops: using a patina of magnetic mouse dust to make common interactor targets easier to select. ACM Symposium on User Interface Software and Technology (UIST).
-
Wolf Kienzle and Ken Hinckley (2014). LightRing: always-available 2D input on any surface. ACM Symposium on User Interface Software and Technology (UIST).
-
Juho Kim, Amy X. Zhang, Jihee Kim, Robert C. Miller, Krzysztof Z. Gajos (2014). Content-aware kinetic scrolling for supporting web page navigation. ACM Symposium on User Interface Software and Technology (UIST).
-
Martez E. Mott and Jacob O. Wobbrock (2014). Beating the bubble: using kinematic triggering in the bubble lens for acquiring small, dense targets. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Nicolas Roussel, Géry Casiez, Jonathan Aceituno, Daniel Vogel (2012). Giving a hand to the eyes: leveraging input accuracy for subpixel interaction. ACM Symposium on User Interface Software and Technology (UIST).
-
Nicolas Villar, Shahram Izadi, Dan Rosenfeld, Hrvoje Benko, John Helmes, Jonathan Westhues, Steve Hodges, Eyal Ofek, Alex Butler, Xiang Cao, Billy Chen (2009). Mouse 2.0: multi-touch meets the mouse. ACM Symposium on User Interface Software and Technology (UIST).
-
Jacob O. Wobbrock, Edward Cutrell, Susumu Harada, and I. Scott MacKenzie (2008). An error model for pointing based on Fitts' law. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Jacob O. Wobbrock, James Fogarty, Shih-Yen (Sean) Liu, Shunichi Kimuro, Susumu Harada (2009). The angle mouse: target-agnostic dynamic gain adjustment based on angular deviation. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).

Text Entry
Just as pointing is a nearly ubiquitous form of non-verbal communication, text is a ubiquitous form of verbal communication. Every single character we communicate to friends, family, coworkers, and computers—every tweet, every Facebook post, every email—leverages some form of text-entry user interface. These interfaces have one simple challenge: support a person in translating the verbal ideas in their head into a sequence of characters that are stored, processed, and transmitted by a computer.
If you’re reading this, you’re already familiar with common text-entry interfaces. You’ve almost certainly used a physical keyboard, arranged with physical keys labeled with letters and punctuation. You’ve probably also used a virtual on-screen keyboard, like those in smartphones and tablets. You might even occasionally use a digital assistant’s speech recognition as a form of text entry. And because text-entry is so frequent a task with computers, you probably also have very strong opinions about what kinds of text-entry you prefer: some hate talking to Siri, some love it. Some still stand by their physical Blackberry keyboards, others type lightning fast on their Android phone’s virtual on-screen keyboard. And some like big bulky clicky keys, while others are fine with the low travel of most thin modern laptop keyboards.
What underlies these strong opinions? A large set of hidden complexities. Text entry needs to support letters, numbers, and symbols across nearly all of human civilization. How can text entry support the input of the 109,384 distinct symbols from all human languages encoded in Unicode 6.0 ? How can text be entered quickly and error-free, and help users recover from entry errors? How can people learn text entry interfaces, just like they learn handwriting, keyboarding, speech, and other forms of verbal communication. How can people enter text in a way that doesn’t cause pain, fatigue, or frustration? Many people with injuries or disabilities (e.g., someone who is fully paralyzed) may find it excruciatingly difficult to enter text. The ever-smaller devices in our pockets and on our wrists only make this harder, reducing the usable surfaces for comfortable text entry.

The history of text entry interfaces predates computers (Silfverberg 2007). For example, typewriters like the Jewett No. 4 shown above had to solve the same problem as modern computer keyboards, but rather than storing the sequence of characters in computer memory, they were stored on a piece of paper with ink. Typewriters like the Jewett No. 4 and their QWERTY keyboard layout emerged during the industrial revolution when the demand for text increased.
Of course, the difference between mechanical text entry and computer text entry is that computers can do so much more to ensure fast, accurate, and comfortable experiences. Researchers have spent several decades exploiting computing to do exactly this. This research generally falls into three categories: techniques that leverage discretediscrete text entry: Explicitly and unambiguously selecting characters, words, and phrases for entry (e.g., with a keyboard). input, like the pressing of a physical or virtual key, techniques that leverage continuouscontinuous text entry: Providing some ambiguous source of text (e.g., speech, gesture) and having an interface translate it into text. input, like gestures or speech, and statistical techniques that attempt to predictpredictive text entry: Providing input that suggests the desired text and having the interface predict what input might be intended. the text someone is typing to automate text entry.

Discrete input
Discrete text input involves entering a single character or word at a time. We refer to them as discrete because of the lack of ambiguity in input: either a button is pressed and a character or word is generated, or it is not. The most common and familiar forms of discrete text entry are keyboards. Keyboards come in numerous shapes and sizes, both physical and virtual, and these properties shape the speed, accuracy, learnability, and comfort of each.
Keyboards can be as simple as 1-dimensional layouts of characters, navigated with a left, right, and select key. These are common on small devices where physical space is scarce. Multiple versions of the iPod, for example, used 1-dimensional text entry keyboards because of its one dimensional click wheel.
Two-dimensional keyboards like the familiar QWERTY layout are more common. And layout matters. The original QWERTY layout, for example, was designed to minimize mechanical failure, not speed or accuracy. The Dvorak layout was designed for speed, placing the most common letters in the home row and maximizes alternation between hands (Dvorak and Dealey 1936):

Not all two-dimensional keyboards have a 1-to-1 mapping from key to character. Some keyboards are virtual, with physical keys for moving an on-screen cursor:

Cell phones in the early 21st century used a multitap method in which each key on the 12-key numeric keyboard typically found on pre-smartphone cellphones mapped to three or four numbers or letters. To select the letter you wanted, you would press a key multiple times until the desired letter is displayed. A letter was entered when a new key was struck. If the next letter is on the same key as the previous letter, then the user must wait for a short timeout or hold down the key to commit the desired character. Some researchers sped up multitap techniques like this by using other sensors, such as tilt sensors, making it faster to indicate a character 15 . Other researchers explored even more efficient forms of text entry with minimal keys, including one with only 4 keys, where characters are uniquely encoded as sequences of presses of those four keys 12 . On particularly small devices like smartwatches, some researchers have explored having the user move the keyboard to select the character they want 14 . Other approaches include portable Bluetooth-connected chording keyboards like the Twiddler , which can be customized for rapid text entry.
Some keyboards are eyes-free. For example, long used in courtrooms, stenographers who transcribe human speech in shorthand have used chorded keyboards called stenotypes:
With 2-4 years of training, some stenographers can reach 225 words per minute. Researchers have adapted these techniques to other encodings, such as braille, to support non-visual text entry for people who are blind or low-vision 3 :
On-screen virtual keyboards like those found in modern smartphones introduce some degree of ambiguity into the notion of a discrete set of keys, because touch input can be ambiguous. Some researchers have leveraged additional sensor data to disambiguate which key is being typed, such as which finger is typically used to type a key 7 . Other approaches have studied how users conceptualize touch input, allowing for more accurate target acquisition 8 .
The primary benefit of the discrete input techniques above is that they can achieve relatively fast speeds and low errors because input is reliable: when someone presses a key, they probably meant to. But this is not always true, especially for people with motor impairments that reduce stability of motion. Moreover, there are many people that cannot operate a keyboard comfortably or at all, many contexts in which there simply isn’t physical or virtual space for keys, and many people who do not want to learn an entire new encoding for entering text.

Continuous input
Continuous input is an alternative to discrete input, which involves providing a stream of data as input, which the computer then translates into characters or words. This helps avoid some of the limitations above, but often at the expense of speed or accuracy. For example, popular in the late 1990’s, the Palm Pilot, seen in the video below, used a unistroke gesture alphabet for text entry. It did not require a physical keyboard, nor did it require space on screen for a virtual keyboard. Instead, users learned a set of gestures for typing letters, numbers, and punctuation.
As the video shows, this wasn’t particularly fast or error-free, but it was relatively learnable and kept the Palm Pilot small.
Researchers envisioned other improved unistroke alphabets. Most notably, the EdgeWrite system was designed to stabilize the motion of people with motor impairments by defining gestures that traced around the edges and diagonals of a square 16 . This way, even if someone had motor tremors that prevented fine motor control, they could still accurately enter text. EdgeWrite has been tested on desktops, mobile devices, joysticks, and even tiny vibrotactile displays like smartwatches 10 .
Whereas the unistroke techniques focus on entering one character at a time, others have explored strokes that compose entire words. Most notably, the SHARK technique allowed users to trace across multiple letters in a virtual keyboard layout, spelling entire words in one large stroke 9 :
Researchers have built upon this basic idea, allowing users to use two hands instead of one for tablets 5 , allowing unused parts of the gesture space for creative expression 1 , and optimizing the layout of keyboards using Fitts’ law for speed 13 .
As interfaces move increasingly away from desktops, laptops, and even devices, researchers have investigated forms of text-entry that involve no direct interaction with a device at all. This includes techniques for tracking the position and movement of fingers in space for text entry 17 :
Other techniques leveraging spatial memory of keyboard layout for accurate text input on devices with no screens 6 and eyes-free entry of numbers 4 .
Handwriting and speech recognition have also long been a goal in research and industry. While both continue to improve, and speech recognition in particular becomes ubiquitous, both continue to be plagued by recognition errors. People are finding many settings in which these errors are tolerable (or even fun!), but they have yet to reach levels of accuracy to be universal, preferred methods for text entry.
Predictive input
The third major approach to text entry has been predictive input, in which a system simply guesses what a user wants to type based on some initial information. This technique has been used in both discrete and continuous input, and is relatively ubiquitous. For example, before smartphones and their virtual keyboards, most cellphones offered a scheme called T9, which would use a dictionary and word frequencies to predict the most likely word you were trying to type.
These techniques leverage Zipf’s law, an empirical observation that the most frequent words in human language are exponentially more frequent than the less frequent words. The most frequent word in English (“the”) accounts for about 7% of all words in a document, and the second most frequent word (“of”) is about 3.5% of words. Most words rarely occur, forming a long tail of low frequencies.
This law is valuable because it allows techniques like T9 to make predictions about word likelihood. Researchers have exploited it, for example, to increase the relevance of autocomplete predictions 11 , and even to recommend entire phrases rather than just words 2 . These techniques are widely used in speech and handwriting recognition to increase accuracy, and are now ubiquitous in smartphone keyboards.
The past, present, and future of text entry
Our brief tour through the history of text entry reveals a few important trends:
- There are many ways to enter text into computers and they all have speed-accuracy tradeoffs.
- The vast majority of techniques focus on speed and accuracy, and not on the other experiential factors in text entry, such as comfort or accessibility.
- There are many text entry methods that are inefficient, and yet ubiquitious (e.g., QWERTY); adoption therefore isn’t purely a function of speed and accuracy, but many other factors in society and history.
As the world continues to age, and computing moves into every context of our lives, text entry will have to adapt to these shifting contexts and abilities. For example, we will have to design new ways of efficiently entering text in augmented and virtual realities, which may require more sophisticated ways of correcting errors from speech recognition. Therefore, while text entry may seem like a well-explored area of user interfaces, every new interface we invent demands new forms of text input.
References
-
Jessalyn Alvina, Joseph Malloch, Wendy E. Mackay (2016). Expressive Keyboards: Enriching Gesture-Typing on Mobile Devices. ACM Symposium on User Interface Software and Technology (UIST).
-
Kenneth C. Arnold, Krzysztof Z. Gajos, Adam T. Kalai (2016). On Suggesting Phrases vs. Predicting Words for Mobile Text Composition. ACM Symposium on User Interface Software and Technology (UIST).
-
Shiri Azenkot, Jacob O. Wobbrock, Sanjana Prasain, Richard E. Ladner (2012). Input finger detection for nonvisual touch screen text entry in Perkinput. Graphics Interface (GI).
-
Shiri Azenkot, Cynthia L. Bennett, Richard E. Ladner (2013). DigiTaps: eyes-free number entry on touchscreens with minimal audio feedback. ACM Symposium on User Interface Software and Technology (UIST).
-
Xiaojun Bi, Ciprian Chelba, Tom Ouyang, Kurt Partridge, Shumin Zhai (2012). Bimanual gesture keyboard. ACM Symposium on User Interface Software and Technology (UIST).
-
Xiang 'Anthony' Chen, Tovi Grossman, George Fitzmaurice (2014). Swipeboard: a text entry technique for ultra-small interfaces that supports novice to expert transitions. ACM Symposium on User Interface Software and Technology (UIST).
-
Daewoong Choi, Hyeonjoong Cho, Joono Cheong (2015). Improving Virtual Keyboards When All Finger Positions Are Known. ACM Symposium on User Interface Software and Technology (UIST).
-
Christian Holz and Patrick Baudisch (2011). Understanding touch. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Per-Ola Kristensson and Shumin Zhai (2004). SHARK2: a large vocabulary shorthand writing system for pen-based computers. ACM Symposium on User Interface Software and Technology (UIST).
-
Yi-Chi Liao, Yi-Ling Chen, Jo-Yu Lo, Rong-Hao Liang, Liwei Chan, Bing-Yu Chen (2016). EdgeVib: Effective alphanumeric character output using a wrist-worn tactile display. ACM Symposium on User Interface Software and Technology (UIST).
-
I. Scott MacKenzie, Hedy Kober, Derek Smith, Terry Jones, Eugene Skepner (2001). LetterWise: prefix-based disambiguation for mobile text input. ACM Symposium on User Interface Software and Technology (UIST).
-
I. Scott MacKenzie, R. William Soukoreff, Joanna Helga (2011). 1 thumb, 4 buttons, 20 words per minute: design and evaluation of H4-writer. ACM Symposium on User Interface Software and Technology (UIST).
-
Jochen Rick (2010). Performance optimizations of virtual keyboards for stroke-based text entry on a touch-based tabletop. ACM Symposium on User Interface Software and Technology (UIST).
-
Tomoki Shibata, Daniel Afergan, Danielle Kong, Beste F. Yuksel, I. Scott MacKenzie, Robert J.K. Jacob (2016). DriftBoard: A Panning-Based Text Entry Technique for Ultra-Small Touchscreens. ACM Symposium on User Interface Software and Technology (UIST).
-
Daniel Wigdor and Ravin Balakrishnan (2003). TiltText: using tilt for text input to mobile phones. ACM Symposium on User Interface Software and Technology (UIST).
-
Jacob O. Wobbrock, Brad A. Myers, John A. Kembel (2003). EdgeWrite: a stylus-based text entry method designed for high accuracy and stability of motion. ACM Symposium on User Interface Software and Technology (UIST).
-
Xin Yi, Chun Yu, Mingrui Zhang, Sida Gao, Ke Sun, Yuanchun Shi (2015). ATK: Enabling ten-finger freehand typing in air based on 3d hand tracking data. ACM Symposium on User Interface Software and Technology (UIST).

Hand-Based Input
Thus far, we have discussed two forms of input to computers: pointing and text entry . Both are mostly sufficient for operating most forms of computers. But, as we discussed in our chapter on history , interfaces have always been about augmenting human ability and cognition, and so researchers have pushed far beyond pointing and text to explore many new forms of input. In this chapter, we focus on the use of hands to interact with computers, including touchscreens , pens , gestures , and hand tracking .
One of the central motivations for exploring hand-based input came from new visions of interactive computing. For instance, in 1991, Mark Weiser, who at the time was head of the very same Xerox PARC that led to the first GUI, wrote in Scientific American about a vision of ubiquitous computing . 36 In this vision, computing would disappear, become invisible, and become a seamless part of everyday tasks:
Hundreds of computers in a room could seem intimidating at first, just as hundreds of volts coursing through wires in the walls did at one time. But like the wires in the walls, these hundreds of computers will come to be invisible to common awareness. People will simply use them unconsciously to accomplish everyday tasks... There are no systems that do well with the diversity of inputs to be found in an embodied virtuality.
Within this vision, input must move beyond the screen, supporting a wide range of embodied forms of computing. We’ll begin by focusing on input techniques that rely on hands, just as pointing and text-entry largely have: physically touching a surface, using a pen-shaped object to touch a surface, and moving the hand or wrist to convey a gesture. Throughout, we will discuss how each of these forms of interaction imposes unique gulfs of execution and evaluation.
Touch
Perhaps the most ubiquitous and familiar form of hand-based input is using our fingers to touchscreens. The first touchscreens originated in the mid-1960’s. They worked similarly to modern touchscreens, just with less fidelity. The earliest screens consisted of an insulator panel with a resistive coating. When a conductive surface such as a finger made contact, it closed a circuit, flipping a binary input from off to on. It didn’t read position, pressure, or other features of a touch, just that the surface was being touched. Resistive touchscreens came next, and rather than using capacitance to close a circuit, it relied on pressure to measure voltage flow between X wires and Y wires, allowing a position to be read. In the 1980’s, HCI researcher Bill Buxton aa Fun fact: Bill was my “academic grandfather”, meaning that he was my advisor’s advisor. invented the first multi-touch screen while at the University of Toronto, placing a camera behind a frosted glass panel, and using machine vision to detect different black spots from finger occlusion. This led to several other advancements in sensing technologies that did not require a camera, and in the 1990’s, multi-touchscreens launched on consumer devices, including handheld devices like the Apple Newton and the Palm Pilot . The 2000’s brought even more innovation in sensing technology, eventually making multi-touchscreens small enough to embed in the smartphones we use today. (See ArsTechnica’s feature on the history of multi-touch for more history).
As you are probably already aware, touchscreens impose a wide range of gulfs of execution and evaluation on users. On first use, for example, it is difficult to know if a surface is touchable. One will often see children who are used to everything being a touchscreen attempt to touch non-touchscreens, confused that the screen isn’t providing any feedback. Then, of course, touchscreens often operate via complex multi-fingered gestures. These have to be somehow taught to users, and successfully learned, before someone can successfully operate a touch interface. This learning requires careful feedback to address gulfs of evaluation, especially if a gesture isn’t accurately performed. Most operating systems rely on the fact that people will learn how to operate touchscreens from other people, such as through a tutorial at a store.
While touchscreens might seem ubiquitous and well understood, HCI research has been pushing its limits even further. Some of this work has invented new types of touch sensors. For example, researchers have worked on materials that allow touch surfaces to be cut into arbitrary shapes and sizes other than rectangles. 23 Some have worked on touch surfaces made of foil and magnets that can sense bending and pressure 26 , or thin, stretchable, transparent surfaces that can detect force, pinching, and dragging. 30 Others have made 3-dimensional spherical touch surfaces 1 and explored using any surface as a touchscreen using depth-sensing cameras and projectors. 10
Other researchers have explored ways of more precise sensing of how a touchscreen is touched. Some have added speakers to detect how something was grasped or touched 25 , or leveraged variations in the resonance of people’s finger anatomy to recognize different fingers and parts of different fingers 11 , or used the resonance of surfaces to detect and classify different types of surface scratching 9 , including through fabric. 27 Depth cameras can also be used to detect the posture and handedness of touch. 21 All of these represent new channels of input that go beyond position, allowing for new, richer, more powerful interfaces.
Commercial touchscreens still focus on single-user interface, only allowing one person at a time to touch a screen. Research, however, has explored many ways to differentiate between multiple people using a single touch-screen. One approach is to have users sit on a surface that determines their identity, differentiating touch input. 4 Another approach uses wearables to differentiate users. 35 Less obtrusive techniques have successfully used variation in user bone-density, muscle mass, and footwear 12 , or fingerprint detection embedded in a display. 14
While these inventions have richly explored many possible new forms of interaction, there is so far very little appetite for touchscreen innovation in industry. Apple’s force-sensitive touchscreen interactions (called “3D touch”) is one example of an innovation that made it to market, but there are some indicators that Apple will abandon it after just a few short years of users not being able to discover it (a classic gulf of execution).

Pens
In addition to fingers, many researchers have explored the unique benefits of pen-based interactions to support handwriting, sketching, diagramming, or other touch-based interactions. These leverage the skill of grasping a pen or pencil that many are familiar with from manual writing. Pens are similar to using a mouse as a pointing device in that they both involve pointing, but pens are critically different in that they involve direct physical contact with targets of interest. This directness requires different sensing technologies, provides more degrees of freedom for movement and input, and rel more fully on the hand’s complex musculature.
Some of these pen-based interactions are simply replacements for fingers. For example, the Palm Pilot, popular in the 1990’s, required the use of a stylus for it’s resistive touch-screen, but the pens themselves were plastic. They merely served to prevent fatigue from applying pressure to the screen with a finger and to increase the precision of touch during handwriting or interface interactions.
However, pens impose their own unique gulfs of execution and evaluation. For example, many pens are not active until a device is set to a mode to receive pen input. The Apple Pencil, for example, only works in particular modes and interfaces, and so it is up to a person to experiment with an interface to discover whether it is pencil compatible. Pens themselves can also have buttons and switches that control modes in software, which require people to learn what the modes control and what effect they have on input and interaction. Pens also sometimes fail to play well with the need to enter text, as typing is faster than tapping one character at a time with a pen. One consequence of these gulfs of execution and efficiency issues is that pens are often used for specific applications such as drawing or sketching, where someone can focus on learning the pen’s capabilities and is unlikely to be entering much text.
Researchers have explored new types of pen interactions that attempt to break beyond these niche applications. For example, some techniques explore a user using touch input with a non-dominant hand, and pen with a dominant hand 8,13 , affording new forms of bi-manual input that have higher throughput than just one hand. Others have investigated ways of using the size of a pen’s head to add another channel of input 2 , or even using a physical pen barrel, but with a virtual head, allowing for increased efficiency through software-based precision and customization. 17
Other pen-based innovations are purely software based. For example, some interactions improve handwriting recognition by allowing users to correct recognition errors while writing 28 , attempting to make the interplay between pen input and text input more seamless. Others have explored techniques for interacting with large displays for sketching and brainstorming activities. 6 Researchers have developed interactions for particular sketching media, such as algorithms that allow painting that respects edges within images 24 and diagramming tools that follow the paradigms of pencil-based architectural sketching. 40 More recent techniques use software-based motion tracking and a camera to support six degree-of-freedom sub-millimeter accuracy. 39
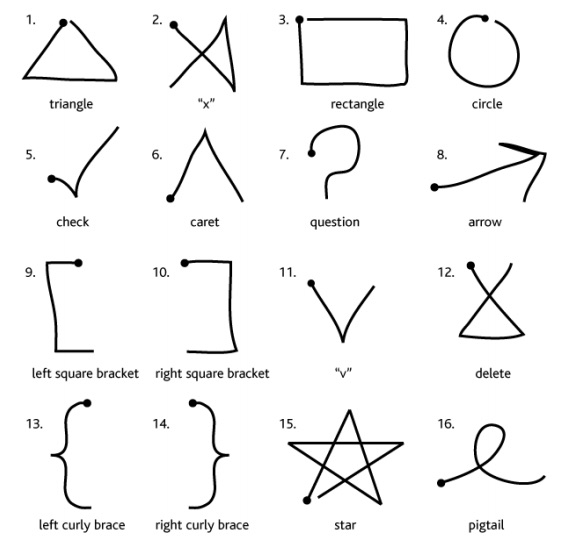
Gestures
Whereas touch and pens involve traditional pointing , gesture-based interactions involve recognizing patterns in hand movement. Some gestures still recognize a gesture from a time-series of points in a 2-dimensional plane, such as the type of multi-touch gestures such as pinching and dragging on a touchscreen, or symbol recognition in handwriting or text entry. This type of gesture recognition can be done with a relatively simple recognition algorithm. 38
Other gestures rely on 3-dimensional input about the position of fingers and hands in space. Some recognition algorithms seek to recognize discrete hand positions, such as when the user brings their thumb and forefinger together (a pinch gesture). 37 Researchers have developed tools to make it easier for developers to build applications that respond to in-air hand gestures. 15 Other techniques try to model hand gestures using alternative techniques such as Electrical Impedance Tomography (EIT) 41 , radio frequencies 34 , the electromagnetic field pulsed by GSM in a phone 43 , or full machine vision of in-air hand gestures. 3,29 Some researchers have leveraged wearables to simplify recognition and increase recognition accuracy. These have included sensors mounted on fingers 7 , movement of a smartwatch through wrist rotations 42 , while walking 5 , or while being tapped or scratched. 16
While all of these inventions are exciting in their potential, gestures have significant gulfs of execution and evaluation. How does someone learn the gestures? How do we create tutorials that give feedback on correct gesture “posture”? When someone performs a gesture incorrectly, how can someone undo it if it had an unintended effect? What if the undo gesture is performed incorrectly? These questions ultimately arise from the unreliability of gesture classification.
Hand Tracking

Gesture-based systems look at patterns in hand motion to recognize a set of discrete poses or gestures. This is often appropriate when the user wants to trigger some action, but it does not offer the fidelity to support continuous hand-based actions, such as physical manipulation tasks in 3D space that require continuous tracking of hand and finger positions over time. Hand tracking systems are better suited for these tasks because they treat the hand as a continuous input device, rather than a gesture as a discrete event, estimating in real-time the hand’s position and orientation.
Most hand tracking systems use cameras and computer vision techniques to track the hand in space. These systems often rely on an approximate model of the hand skeleton, including bones and joints, and solve for the joint angles and hand pose that best fits the observed data. Researchers have used gloves with unique color patterns, shown above, to make the hand easier to identify and to simplify the process of pose estimation. 32
Since then, researchers have developed and refined techniques using depth cameras like the Kinect for tracking the hand without the use of markers or gloves. 20,22,31,33 Commercial devices, such as the Leap Motion have been developed that bring hand tracking to computers or virtual reality devices. These tracking systems have been used for interaction on large displays 18 and haptic devices. 19
For head-mounted virtual and augmented reality systems, a common way to track the hands is through the use of positionally tracked controllers. Systems such as the Oculus Rift or HTC Vive, use cameras and infrared LEDs to track both the position and orientation of the controllers.
Like gesture interactions, the potential for classification error in hand tracking interactions can impose significant gulfs of execution and evaluation. However, because the applications of hand tracking often involve manipulation of 3D objects rather than invoking commands, the severity of these gulfs may be lower in practice. This is because object manipulation is essentially the same as direct manipulation: it’s easy to see what effect the hand tracking is having and correct it if the tracking is failing.
While there has been incredible innovation in hand-based input, there are still many open challenges. They can be hard to learn for new users, requiring careful attention to tutorials and training. And, because of the potential for recognition error, interfaces need some way of helping people correct errors, undo commands, and try again. Moreover, because all of these input techniques use hands, few are accessible to people with severe motor impairments in their hands, people lacking hands altogether, or if the interfaces use visual feedback to bridge gulfs of evaluation, people lacking sight. In the next chapter, we will discuss techniques that rely on other parts of a human body for input, and therefore can be more accessible to people with motor impairments.
References
-
Hrvoje Benko, Andrew D. Wilson, Ravin Balakrishnan (2008). Sphere: multi-touch interactions on a spherical display. ACM Symposium on User Interface Software and Technology (UIST).
-
Xiaojun Bi, Tomer Moscovich, Gonzalo Ramos, Ravin Balakrishnan, Ken Hinckley (2008). An exploration of pen rolling for pen-based interaction. ACM Symposium on User Interface Software and Technology (UIST).
-
Andrea Colaço, Ahmed Kirmani, Hye Soo Yang, Nan-Wei Gong, Chris Schmandt, Vivek K. Goyal (2013). Mime: compact, low power 3D gesture sensing for interaction with head mounted displays. ACM Symposium on User Interface Software and Technology (UIST).
-
Paul Dietz and Darren Leigh (2001). DiamondTouch: a multi-user touch technology. ACM Symposium on User Interface Software and Technology (UIST).
-
Jun Gong, Xing-Dong Yang, Pourang Irani (2016). WristWhirl: One-handed Continuous Smartwatch Input using Wrist Gestures. ACM Symposium on User Interface Software and Technology (UIST).
-
François Guimbretière, Maureen Stone, Terry Winograd (2001). Fluid interaction with high-resolution wall-size displays. ACM Symposium on User Interface Software and Technology (UIST).
-
Aakar Gupta, Antony Irudayaraj, Vimal Chandran, Goutham Palaniappan, Khai N. Truong, Ravin Balakrishnan (2016). Haptic learning of semaphoric finger gestures. ACM Symposium on User Interface Software and Technology (UIST).
-
William Hamilton, Andruid Kerne, Tom Robbins (2012). High-performance pen + touch modality interactions: a real-time strategy game eSports context. ACM Symposium on User Interface Software and Technology (UIST).
-
Chris Harrison and Scott E. Hudson (2008). Scratch input: creating large, inexpensive, unpowered and mobile finger input surfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Chris Harrison, Hrvoje Benko, Andrew D. Wilson (2011). OmniTouch: wearable multitouch interaction everywhere. ACM Symposium on User Interface Software and Technology (UIST).
-
Chris Harrison, Julia Schwarz, Scott E. Hudson (2011). TapSense: enhancing finger interaction on touch surfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Chris Harrison, Munehiko Sato, Ivan Poupyrev (2012). Capacitive fingerprinting: exploring user differentiation by sensing electrical properties of the human body. ACM Symposium on User Interface Software and Technology (UIST).
-
Ken Hinckley, Koji Yatani, Michel Pahud, Nicole Coddington, Jenny Rodenhouse, Andy Wilson, Hrvoje Benko, Bill Buxton (2010). Pen + touch = new tools. ACM Symposium on User Interface Software and Technology (UIST).
-
Christian Holz and Patrick Baudisch (2013). Fiberio: a touchscreen that senses fingerprints. ACM Symposium on User Interface Software and Technology (UIST).
-
Eyal Krupka, Kfir Karmon, Noam Bloom, Daniel Freedman, Ilya Gurvich, Aviv Hurvitz, Ido Leichter, Yoni Smolin, Yuval Tzairi, Alon Vinnikov, Aharon Bar-Hillel (2017). Toward Realistic Hands Gesture Interface: Keeping it Simple for Developers and Machines. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Gierad Laput, Robert Xiao, Chris Harrison (2016). ViBand: High-Fidelity Bio-Acoustic Sensing Using Commodity Smartwatch Accelerometers. ACM Symposium on User Interface Software and Technology (UIST).
-
David Lee, KyoungHee Son, Joon Hyub Lee, Seok-Hyung Bae (2012). PhantomPen: virtualization of pen head for digital drawing free from pen occlusion & visual parallax. ACM Symposium on User Interface Software and Technology (UIST).
-
Mingyu Liu, Mathieu Nancel, Daniel Vogel (2015). Gunslinger: Subtle arms-down mid-air interaction. ACM Symposium on User Interface Software and Technology (UIST).
-
Benjamin Long, Sue Ann Seah, Tom Carter, Sriram Subramanian (2014). Rendering volumetric haptic shapes in mid-air using ultrasound. ACM Transactions on Graphics.
-
Mueller, F., Mehta, D., Sotnychenko, O., Sridhar, S., Casas, D., & Theobalt, C. (2017). Real-time hand tracking under occlusion from an egocentric rgb-d sensor. International Conference on Computer Vision.
-
Sundar Murugappan, Vinayak, Niklas Elmqvist, Karthik Ramani (2012). Extended multitouch: recovering touch posture and differentiating users using a depth camera. ACM Symposium on User Interface Software and Technology (UIST).
-
Oberweger, M., Wohlhart, P., & Lepetit, V. (2015). Hands deep in deep learning for hand pose estimation. arXiv:1502.06807.
-
Simon Olberding, Nan-Wei Gong, John Tiab, Joseph A. Paradiso, Jürgen Steimle (2013). A cuttable multi-touch sensor. ACM Symposium on User Interface Software and Technology (UIST).
-
Dan R. Olsen, Jr. and Mitchell K. Harris (2008). Edge-respecting brushes. ACM Symposium on User Interface Software and Technology (UIST).
-
Makoto Ono, Buntarou Shizuki, Jiro Tanaka (2013). Touch & activate: adding interactivity to existing objects using active acoustic sensing. ACM Symposium on User Interface Software and Technology (UIST).
-
Christian Rendl, Patrick Greindl, Michael Haller, Martin Zirkl, Barbara Stadlober, Paul Hartmann (2012). PyzoFlex: printed piezoelectric pressure sensing foil. ACM Symposium on User Interface Software and Technology (UIST).
-
T. Scott Saponas, Chris Harrison, Hrvoje Benko (2011). PocketTouch: through-fabric capacitive touch input. ACM Symposium on User Interface Software and Technology (UIST).
-
Michael Shilman, Desney S. Tan, Patrice Simard (2006). CueTIP: a mixed-initiative interface for correcting handwriting errors. ACM Symposium on User Interface Software and Technology (UIST).
-
Jie Song, Gábor Sörös, Fabrizio Pece, Sean Ryan Fanello, Shahram Izadi, Cem Keskin, Otmar Hilliges (2014). In-air gestures around unmodified mobile devices. ACM Symposium on User Interface Software and Technology (UIST).
-
Yuta Sugiura, Masahiko Inami, Takeo Igarashi (2012). A thin stretchable interface for tangential force measurement. ACM Symposium on User Interface Software and Technology (UIST).
-
Jonathan Taylor, Lucas Bordeaux, Thomas Cashman, Bob Corish, Cem Keskin, Toby Sharp, Eduardo Soto, David Sweeney, Julien Valentin, Benjamin Luff, Arran Topalian, Erroll Wood, Sameh Khamis, Pushmeet Kohli, Shahram Izadi, Richard Banks, Andrew Fitzgibbon, Jamie Shotton (2016). Efficient and precise interactive hand tracking through joint, continuous optimization of pose and correspondences. ACM Transactions on Graphics.
-
Robert Y. Wang and Jovan Popović (2009). Real-time hand-tracking with a color glove. ACM Transactions on Graphics.
-
Robert Wang, Sylvain Paris, Jovan Popović (2011). 6D hands: markerless hand-tracking for computer aided design. ACM Symposium on User Interface Software and Technology (UIST).
-
Saiwen Wang, Jie Song, Jaime Lien, Ivan Poupyrev, Otmar Hilliges (2016). Interacting with Soli: Exploring fine-grained dynamic gesture recognition in the radio-frequency spectrum. ACM Symposium on User Interface Software and Technology (UIST).
-
Andrew M. Webb, Michel Pahud, Ken Hinckley, Bill Buxton (2016). Wearables as Context for Guiard-abiding Bimanual Touch. ACM Symposium on User Interface Software and Technology (UIST).
-
Mark Weiser (1991). The Computer for the 21st Century. Scientific American 265, 3 (September 1991), 94-104.
-
Andrew D. Wilson (2006). Robust computer vision-based detection of pinching for one and two-handed gesture input. ACM Symposium on User Interface Software and Technology (UIST).
-
Jacob O. Wobbrock, Andrew D. Wilson, Yang Li (2007). Gestures without libraries, toolkits or training: a $1 recognizer for user interface prototypes. ACM Symposium on User Interface Software and Technology (UIST).
-
Wu, P. C., Wang, R., Kin, K., Twigg, C., Han, S., Yang, M. H., & Chien, S. Y. (2017). DodecaPen: Accurate 6DoF tracking of a passive stylus. ACM Symposium on User Interface Software and Technology (UIST).
-
Robert C. Zeleznik, Andrew Bragdon, Chu-Chi Liu, Andrew Forsberg (2008). Lineogrammer: creating diagrams by drawing. ACM Symposium on User Interface Software and Technology (UIST).
-
Yang Zhang and Chris Harrison (2015). Tomo: Wearable, low-cost electrical impedance tomography for hand gesture recognition. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology (UIST '15).
-
Yang Zhang, Robert Xiao, Chris Harrison (2016). Advancing hand gesture recognition with high resolution electrical impedance tomography. ACM Symposium on User Interface Software and Technology (UIST).
-
Chen Zhao, Ke-Yu Chen, Md Tanvir Islam Aumi, Shwetak Patel, Matthew S. Reynolds (2014). SideSwipe: detecting in-air gestures around mobile devices using actual GSM signal. ACM Symposium on User Interface Software and Technology (UIST).

Body-Based Input
In the last chapter , I introduced Weiser’s vision of ubiquitous computing, and argued that part of fulfilling it was fully exploiting the versatility of our hands. In this chapter, we explore all of the sources of human action other than hands — speech, eye gaze, limbs, and entire bodies — and the range of ways this action has been channeled as input to computers. As we shall see, many of the same gulfs of execution and evaluation arise with body-based input as does with hands. Part of this is that all body-based input is based in probabilistically recognizing the actions of muscles. When we speak or make other sounds, we use the muscles in our throat, mouth, and face. When we look with our eyes, we use muscles to shift our gaze, to blink, to squint, and keep our eyes closed. We use our muscles to move and arrange our limbs. Perhaps the only action we perform that isn’t driven by muscles is thought. Our brain drives our muscles through electrical signals, which are detectable through our skin through techniques such as EMG and EEG. All of these forms of action are central to our existence in a physical world. Researchers have explored how to leverage these muscle-based signals to act in virtual worlds.
Speech
Aside from our hands, one of the most versatile ways we use our muscles to engage with our environment is to use our voice. We use it to speak, to hum, to sing, and to make other non-verbal auditory sounds to communicate with humans and other living things. Why not computers?
Voice-based interactions have been a dream for decades, and long-imagined in science fiction. Only after decades of progress on speech recognition, spanning the early 1950’s at Bell Labs, to continued research today in academia, did voice interfaces become reliable enough for interaction. Before the ubiquitous digital voice assistants on smartphones and smart speakers, there were speech recognition programs that dictated text and phone-based interfaces that listened to basic commands and numbers.
The general process for speech recognition begins with an audio sample. The computer records some speech, encoded as raw sound waves, just like that recorded in a voice memo application. Before speech recognition algorithms even try to recognize speech, they apply several techniques to “clean” the recording, trying to distinguish between background and foreground sound, removing background sound. They segment sound into utterances separated by silence, which can be more easily classified. They rely on large databases of phonetic patterns, which define the kinds of sounds that are used in a particular natural language. They use machine learning techniques to try to classify these phonetic utterances. And then finally, once these phonemes are classified, they try to recognize sequences of phonetic utterances as particular words. More advanced techniques used in modern speech recognition may also analyze an entire sequence of phonetic utterances to try to infer the most likely possible nouns, noun phrases, and other parts of sentences, based on the rest of the content of the sentence.
Whether speech recognition works well depends on what data is used to train the recognizers. For example, if the data only includes people with particular accents, recognition will work well for those accents and not others. The same applies to pronunciation variations: for example, for a speech recognizer to handle both the American and British spellings pronunciations of “aluminum” and “aluminium”, both pronunciations need to be in the sample data. This lack of diversity in training data is a significant source of recognition failure. It is also a source of gulf of executions, is it is not always clear when speaking to a recognition engine what it is trained on and therefore what enunciation might be necessary to get it to properly recognize a word or phrase.
Of course, even accounting for diversity, technologies for recognizing speech are insufficient on their own to be useful. Early HCI research explored how to translate graphical user interfaces into speech-based interfaces to make GUIs accessible to people who were blind or low vision 16 . The project that finally pushed voice interactions into the mainstream was the DARPA-funded CALO research project , which, as described by it’s acronym, “Cognitive Assistant that Learns and Organizes,” sought to create intelligent digital assistants using the latest advances in artificial intelligence. One branch of this project at SRI International spun out some of the speech recognition technology, building upon decades of advances to support real-time speech command recognition by applying advances in deep learning from the late 1990’s. The eventual result was assistants like Siri, Alexa, and OK Google, which offer simple command libraries, much like a menu in a graphical user interface, but accessed with voice instead of a pointing device. Speech in these systems was merely the input device; they still required careful designs of commands, error-recovery, and other aspects of user interface design to be usable. And they pose distinct learnability challenges: a menu in a GUI, for example, plainly shows what commands are possible, but a voice interface’s available commands are essentially invisible.
Voice can be useful far beyond giving simple commands. Researchers have explored its use in multi-modal contexts in which a user both points and gives speech commands to control complex interfaces 2,23 . Some have applied voice interactions to support more rapid data exploration by using natural language queries and “ambiguity widgets” to show ranges of possible queries 5 . Others have used non-verbal voice humming to offer hands free interaction with creative tools, like drawing applications 8 . Some have even explored whispering to voice assistants, finding that this different speech modality can surface emotions like creepiness and intimacy 18 . Each of these design explorations consider new possible interactions, surfacing new potential benefits.
Of course, in all of these voice interactions, there are fundamental gulfs of execution and evaluation. Early work on speech interfaces 25 found that users expected conversational fluency in machines, that they struggled to overcome recognition errors, and that the design of commands for GUIs often did not translate well to speech interfaces. They also found that speech itself poses cognitive demands on working memory to form correct commands, retain the state of the machine, and anticipate the behavior of the conversational agent. These all further aggravated recognition errors. All of these gulfs persist in modern speech interfaces, though to a lesser extent as speech recognition has improved with ever larger data sets.
Gaze
Another useful muscle in our bodies are those in our eyes that control our gaze. Gaze is inherently social information that refers to inferences about where someone is looking based on the position of their pupils relative to targets in a space. Gaze tracking technology usually involves machine vision techniques, using infrared illumination of pupils, then time series analysis and individual calibration to track pupil movements over time. These can have many useful applications in things like virtual reality . For example, in a game, gaze detection might allow non-player characters to notice when you are looking at them, and respond to you. In the same way, gaze information might be propagated to a player’s avatar, moving it’s eyes in the player’s eyes move, helping other human players in social and collaborative games know when a teammate is looking your way.
Gaze recognition techniques are similar in concept to speech recognition in that they rely on machine learning and large data sets. However, rather than training on speech utterances, these techniques use data sets of eyes to detect and track the movement of pupils over time. The quality of this tracking depends heavily on the quality of cameras, as pupils are small and their movements are even smaller. Pupil movement is also quite fast, and so cameras need to record at a high frame rate to monitor movement. Eyes also have very particular movements, such as saccades , which are ballistic motions that abruptly shift from one point of fixation to another. Most techniques overcome the challenges imposed by these dynamic properties of eye movement by aggregating and averaging movement over time and using that as input.
Researchers have exploited gaze detection as a form of hands-free interaction, usually discriminating between looking and acting with dwell-times : if someone looks at something long enough, it is interpreted as an interaction. For example, some work has used dwell times and the top and bottom of a window to support gaze-controlled scrolling through content 11 . Other techniques analyze the targets in an interface (e.g., links in a web browser) and make them controllable through gaze and dwell 13 . Some researchers have even extended this to multiple displays, making it easier to quickly interact with different devices at a distance 12 . One way to avoid waiting for dwell times is to combine gaze with other interaction. For example, some systems have combined gaze and touch, as in the video below, to use gaze for pointing and touch for action 20 :
Unfortunately, designing for gaze can require sophisticated knowledge of constraints on human perception. For example, one effort to design a hands-free, gaze-based drawing tool for people with motor disabilities ended up requiring the careful design of commands to avoid frustrating error handling and disambiguation controls 9 . Other work has explored peripheral awareness as a component of gaze, and found that it is feasible to detect degrees of awareness, but that incorporating feedback about awareness into designs can lead to dramatic, surreal, and even scary experiences 1 . Like other forms of recognition-based input, without significant attention to supporting recovery from recognition error, people will face challenges trying to perform the action they want efficiently and correctly. The interplay between gulfs of execution and evaluation with gaze-based interfaces can be particularly frustrating, as we rarely have perfect control over where our eyes are looking.
Limbs
Whereas our hands, voices, and eyes are all very specialized for social interaction, the other muscles in our limbs are more for movement. That said, they also offer rich opportunities for interaction. Because muscles are activated using electrical signals, techniques like electromyography (EMG) can be used to sense muscle activity through electrodes placed on the skin. For example, this technique was used to sense motor actions in the forearm, discriminating between different grips to support applications like games 22 :
Other ideas focused on the movement of the tongue muscles using optical sensors and a mouth retainer 21 and tongue joysticks for menu navigation 24 . Some focused on the breath, localizing where a person was blowing at a microphone installed on a laptop or computer screen 19 . Others have defined entire gesture sets for tongue movement that can be detected non-invasively through wireless X-band Doppler movement detection 6 .
While these explorations of limb-based interactions have all been demonstrated to be feasible to agree, as with many new interactions, they impose many gulfs of execution and evaluation that have not yet been explored.
- How can users learn what a system is trying to recognize about limb movement?
- How much will users be willing to train the machine learned classifiers used to recognize movement?
- When errors inevitably occur, how can we support people in recovering from error, but also improving classification in the future?
Body
Other applications have moved beyond specific muscles to the entire body and its skeletal structure. The most widely known example of this is the Microsoft Kinect , shown in the image at the beginning of this chapter. The Kinect used a range of cameras and infrafred projectors to create a depth map of a room, including the structure and posture of the people in this room. Using this depth map, it build basic skeletal models of players, including the precise position and orientation of arms, legs, and heads. This information was then available in real-time for games to use as sources of input (e.g., mapping the skeletal model on to an avatar, using skeletal gestures to invoke commands).
But Kinect was just one technology that emerged from a whole range of explorations of body-based sensing. For example, researchers have explored whole-body gestures, allowing for hands-free interactions. This technique uses the human body as an antenna for sensing, requiring no instrumentation to the environment, and only a little instrumentation of the user 4 :
Similar techniques sense a person tapping patterns on their body 3 , sensing skin deformation through a band that also provide tactile feedback 17 , and the detection of entire human bodies through electric field distortion requiring no instrumentation of the user 15 . Other techniques coordinate multiple parts of the body, such as gaze detection and foot movement 10 . Even more extreme ideas include entirely imaginary interfaces, in which users perform spatial gestures with no device and no visual feedback, relying on machine vision techniques to map movement to action 7 . Some of these techniques are beginning to be commercialized in products like the Virtuix Omni , which is an omni-directional treadmill that lets players walk and run in virtual worlds while staying in place:
Whole body interactions pose some unique gulfs of execution and evaluation. For example, a false positive for a hand or limb-based gesture might mean unintentionally invoking a command. We might not expect these to be too common, as we often use our limbs only when we want to communicate. But we use our bodies all the time, moving, walking, and changing our posture. If recognition algorithms aren’t tuned to filter out the broad range of things we do with our body in every day life, the contexts in which body-based input might be used might be severely limited.
This survey of body-based input techniques show a wide range of possible ways of providing input. However, like any new interface ideas, there are many unresolved questions about how to train people to use them and how to support error recovery. There are also many questions about the contexts in which such human-computer interaction might be socially acceptable. For example, how close do we want to be with computers. New questions about human-computer integration 14 have been raised, pondering the many ways that we might unify ourselves with computers:
- Symbiosis might entail humans and digital technology working together, in which software works on our behalf, and in return, we maintain and improve it. For example, examples above where computers exhibit agency of their own (e.g., noticing things that we miss, and telling us) are a kind of symbiosis.
- Fusion might entail using computers to extend our bodies and bodily experiences. Many of the techniques described above might be described as fusion, where they expand our abilities.
Do you want this future? If so, the maturity of these ideas are not quite sufficient to bring them to market. If not, what kind of alternative visions might you imagine to prevent these futures?
References
-
Josh Andres, m.c. Schraefel, Nathan Semertzidis, Brahmi Dwivedi, Yutika C Kulwe, Juerg von Kaenel, Florian 'Floyd' Mueller (2020). Introducing Peripheral Awareness as a Neurological State for Human-Computer Integration. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Richard A. Bolt (1980). "Put-that-there": Voice and gesture at the graphics interface. In Proceedings of the 7th annual conference on Computer graphics and interactive techniques (SIGGRAPH '80).
-
Xiang 'Anthony' Chen and Yang Li (2016). Bootstrapping user-defined body tapping recognition with offline-learned probabilistic representation. ACM Symposium on User Interface Software and Technology (UIST).
-
Gabe Cohn, Daniel Morris, Shwetak Patel, Desney Tan (2012). Humantenna: using the body as an antenna for real-time whole-body interaction. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Tong Gao, Mira Dontcheva, Eytan Adar, Zhicheng Liu, Karrie G. Karahalios (2015). DataTone: Managing Ambiguity in Natural Language Interfaces for Data Visualization. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology (UIST '15).
-
Mayank Goel, Chen Zhao, Ruth Vinisha, Shwetak N. Patel (2015). Tongue-in-Cheek: Using Wireless Signals to Enable Non-Intrusive and Flexible Facial Gestures Detection. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (CHI '15).
-
Sean Gustafson, Daniel Bierwirth, Patrick Baudisch (2010). Imaginary interfaces: spatial interaction with empty hands and without visual feedback. ACM Symposium on User Interface Software and Technology (UIST).
-
Susumu Harada, Jacob O. Wobbrock, James A. Landay (2007). Voicedraw: a hands-free voice-driven drawing application for people with motor impairments. ACM SIGACCESS Conference on Computers and Accessibility.
-
Anthony J. Hornof and Anna Cavender (2005). EyeDraw: enabling children with severe motor impairments to draw with their eyes. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Konstantin Klamka, Andreas Siegel, Stefan Vogt, Fabian Göbel, Sophie Stellmach, Raimund Dachselt (2015). Look & Pedal: Hands-free Navigation in Zoomable Information Spaces through Gaze-supported Foot Input. ACM on International Conference on Multimodal Interaction (ICMI).
-
Manu Kumar and Terry Winograd (2007). Gaze-enhanced scrolling techniques. ACM Symposium on User Interface Software and Technology (UIST).
-
Christian Lander, Sven Gehring, Antonio Krüger, Sebastian Boring, Andreas Bulling (2015). GazeProjector: Accurate Gaze Estimation and Seamless Gaze Interaction Across Multiple Displays. ACM Symposium on User Interface Software and Technology (UIST).
-
Christof Lutteroth, Moiz Penkar, Gerald Weber (2015). Gaze vs. mouse: A fast and accurate gaze-only click alternative. ACM Symposium on User Interface Software and Technology (UIST).
-
Florian Floyd Mueller, Pedro Lopes, Paul Strohmeier, Wendy Ju, Caitlyn Seim, Martin Weigel, Suranga Nanayakkara, Marianna Obrist, Zhuying Li, Joseph Delfa, Jun Nishida, Elizabeth M. Gerber, Dag Svanaes, Jonathan Grudin, Stefan Greuter, Kai Kunze, Thomas Erickson, Steven Greenspan, Masahiko Inami, Joe Marshall, Harald Reiterer, Katrin Wolf, Jochen Meyer, Thecla Schiphorst, Dakuo Wang, and Pattie Maes (2020). Next Steps for Human-Computer Integration. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Mujibiya, A., & Rekimoto, J. (2013). Mirage: exploring interaction modalities using off-body static electric field sensing. ACM Symposium on User Interface Software and Technology (UIST).
-
Elizabeth D. Mynatt and W. Keith Edwards (1992). Mapping GUIs to auditory interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Masa Ogata, Yuta Sugiura, Yasutoshi Makino, Masahiko Inami, Michita Imai (2013). SenSkin: adapting skin as a soft interface. ACM Symposium on User Interface Software and Technology (UIST).
-
Emmi Parviainen (2020). Experiential Qualities of Whispering with Voice Assistants. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Shwetak N. Patel and Gregory D. Abowd (2007). Blui: low-cost localized blowable user interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Ken Pfeuffer and Hans Gellersen (2016). Gaze and Touch Interaction on Tablets. ACM Symposium on User Interface Software and Technology (UIST).
-
T. Scott Saponas, Daniel Kelly, Babak A. Parviz, and Desney S. Tan (2009). Optically sensing tongue gestures for computer input. ACM Symposium on User Interface Software and Technology (UIST).
-
T. Scott Saponas, Desney S. Tan, Dan Morris, Ravin Balakrishnan, Jim Turner, and James A. Landay (2009). Enabling always-available input with muscle-computer interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Vidya Setlur, Sarah E. Battersby, Melanie Tory, Rich Gossweiler, Angel X. Chang (2016). Eviza: A Natural Language Interface for Visual Analysis. ACM Symposium on User Interface Software and Technology (UIST).
-
Ronit Slyper, Jill Lehman, Jodi Forlizzi, Jessica Hodgins (2011). A tongue input device for creating conversations. ACM Symposium on User Interface Software and Technology (UIST).
-
Nicole Yankelovich, Gina-Anne Levow, Matt Marx (1995). Designing SpeechActs: issues in speech user interfaces. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).

2D Visual Output
It’s easy to forget that computers didn’t always have screens. The original format for computer output was actually printed, not rendered, and as with even modern printers, printing was slow. It wasn’t until Ivan Sutherland integrated a CRT screen with a computer in Sketchpad that screens enabled interactive, immediate feedback experiences.
But display hardware alone was not enough to support the visual interfaces we used today. There was an entire set of new concepts that needed to be invented to make use of screens, ranging from graphics, typography, images, visualization, and animated versions of all of these media. And researchers continue to innovate in these spaces, including in screen technology itself. In this chapter, we’ll review screen technology, and then discuss how these media were translated to computer screens and further enhanced.
Displays
To begin, let’s consider screens themselves. Some of the earliest screen technology used something called a CRT (Cathode Ray Tube), seen below in the image, and widely used throughout the 1980’s and 90’s for televisions, personal computers, and terminals. CRTs use a vacuum tube with an electron gun and a phosphorescent screen. The device moves the electron gun in a repetitive pattern called a “raster” scan across the two dimensions of the screen, causing the phosphorescent material to glow at whatever points it was active. To make color CRTs, three electron guns are used, one for red, green, and blue color. To determine what to draw on screen, computers stored in memory a long list of color values, and then hardware translated those color values at high frequency during the raster to determine when the electron guns were on and off. When this happens at a high frequency (generally 24 times a second or faster), we get the interactive screens we are used to today.

The problem with CRTs was that they were huge and heavy , making them practical only for desktop use. Display technology evolved to solve these problems, with liquid crystal displays (LCDs) making the next leap. LCDs, which are still quite common in devices today, are grids of red, green, and blue liquid crystals. Liquid crystals are a state of matter between liquid and solid with varying optical qualities. By placing this grid of liquid crystals on top of a big backlight, these crystals filter light in red, green, and blue at different intensities based on the current running through the liquid. (The video below shows in more detail exactly which materials are used to display varying colors). These crystals are tiny, allowing for screens that were flat and with much lower energy consumption than CRTs. This allowed for entirely new mobile devices like laptops and phones.
The latest display technology, light emitting diode displays, are grids of semiconductors that individually emit their own light when activated. Because LEDs can light themselves, unlike an LCD, which requires a backlight, they can be even thinner and use even less energy. This makes them practical for even smaller devices, such as smartwatches, head-mounted displays for VR, and other devices with small, battery-powered displays.
While these advances in display quality might appear only to affect the quality of a picture, they have had dramatic effects on interfaces. For example, none of the mobile devices in use today would be possible with CRT technology. Screens would be far too big and far too inefficient to make mobile interaction possible. And some sizes of devices, like smartwatches, are only possible with LEDs: their thinness and energy efficiency make room for more battery, which is the critical limiting factor for such small devices.
Researchers continue to innovate in display technology, especially with new forms of interaction in mind. For example, researchers have enhanced existing display technologies by making them transparent, allowing for new collaboration opportunities while managing privacy 14 . Others have played with new bendable, foldable displays that allow for depth and parallax in images 6 . Some foldable displays are entering the marketplace, but without much vision yet for how user interfaces will be adapted to exploit them.
Other researchers have experimented with projectors, making them track the movement of projection surfaces 12 , and even allowing projection surfaces to bend 13 . Some have experimented with having multiple users interact with portable projectors, using projection as both a source of output, but also input 3 .
Some have experimented with even smaller displays, such as low-energy displays without batteries 7 or tiny displays intended to view near eyes 16 :
When we step back and consider the role that displays have played in shaping interfaces, the trend has fundamentally been in creating new forms of devices. Form, after all, dictates many things. Large CRTs were heavy and risky to move, and so people designed desks and workstations around which people sat to do work. Smaller LCD displays were fundamental to making mobile devices possible, and so we designed interfaces and interaction techniques that could be used sitting, standing, and even moving, like the tablets and smartphones many of us use today. More energy-efficient LED displays have allowed us to place computing on our wrists, faces, and feet, resulting in new categories of interactions. And the displays being invented in research promise to bring computing even closer to our bodies and our environments, perhaps even in our bodies and environments, via implants. This trend is clearly one of deep integration between visual displays of digital information, our built environment, and ourselves.
Graphics
While displays can enable new interfaces, the content on displays is what makes them valuable, and the basis of all content in displays is computer graphicsgraphics: The use of computer hardware to create static, dynamic, and interactive two and three dimensional imagery. . Graphics can be anything from basic graphical primitives like lines, rectangles, circles, polygons, and other shapes. In a way, all computer graphics are simulations, reconstructing complex visual scenes out of more primitive shapes, from powerful windowed operating systems to photorealistic scenes in computer generated animated movies.
Despite all of this complexity, computer graphics have simple foundations. Because displays are organized as 2-dimensional arrays of pixels, graphical rendering is all about coordinate systems . Coordinate systems have an x-axis, a y-axis, and at each point in a matrix of pixels, a color. Rendering a graphical primitive means specifying a location and color for that shape (and often whether that shape should be filled, or just an outline).

To create more complex visual scenes, computer graphics involves compositingcompositing: Layering visual imagery and filters, from top to bottom, to construct scenes from individual layers of graphics. , which entails layering graphical primitives in a particular order. Much like painting, compositing uses layers to construct objects with backgrounds, foregrounds, and other texture. This is what allows us to render buttons with backgrounds and text labels, scroll bars with depth and texture, and windows with drop shadows.
Operating systems are typically in charge of orchestrating the interface compositing process. They begin with a blank canvas, and then, from back to front, render everything in a recursive object-oriented manner:
- The operating system first renders the background, such as a desktop wallpaper.
- Next, the operating system iterates through visible windows, asking each window to render its contents.
- Each window recursively traverses the hierarchy of user interface element, with each element responsible for compositing its visual appearance.
- After windows are rendered, the operating system composites its own system-wide interface controls, such as task bars, application switcher interfaces.
- Finally, the operating system renders the mouse cursor last, so that it is always visible.
- After everything is done rendering, the entire scene is rendered all at once on the display, so that the person viewing the display doesn’t see the scene partially rendered.
This entire compositing process happens anywhere from 30 to 120 times per second depending on the speed of the computer’s graphics hardware and the refresh rate of the display. The result is essentially the same as any animation, displaying one frame at a time, with each frame making minor adjustments to create the illusion of motion. Computer graphics therefore relies on our human ability to perceive graphical shapes as persistent objects over time.
Just as important as shapes are images. Just like the screen itself, images are represented by 2-dimensional grids of pixels. As most computer users know, there are countless ways of storing and compressing this pixel data (bmp, pict, gif, tiff, jpeg, png). In the 1980’s and 90’s, these formats mattered for experience, especially on the web: if you stored pixels in order, uncompressed, an image in a browser would be rendered line by line, as it downloaded, but if you stored it out of order, you could render low-resolution versions of a picture as the entire image downloaded. The internet is fast enough today that these format differences don’t affect user experience as much.
There are many techniques from computer graphics that ensure a high-level of graphical fidelity. Transparency is the idea of allowing colors to blend with each other, allowing some of an image to appear behind another. Anti-aliasing is the idea of smoothing the ragged edges of the 2D grid of pixels by making some pixels lighter, creating the illusion of a straight line. Sub-pixel rendering is a way of drawing images on a screen that leverages the physical properties of LCD screens to slightly increase resolution. Double-buffering is a technique of rendering a complete graphical scene off screen, then copying it all at once to the screen, to avoid flickering. Graphics processing units (GPUs) take common advanced graphics techniques and move them to hardware so that graphics are high-performance.
All of these techniques and more are the foundation of computer graphics , helping ensure that people can focus on content on their screens rather than the pixels that make them up. These concepts do become important, however, if you’re responsible for the graphic design portion of a user interface. Then, the pixels are something you need to design around, requiring deeper knowledge of how images are rendered on screens.

Typography
While graphical primitives are the foundation of visual scenes, text are the basis of most information in interfaces. A huge part of even being able to operate user interfaces are the words we use to explain the semantics of user interface behavior. In the early days of command line interfaces, typography was rudimentary: just like screens were grids of pixels, text was presented as a grid of characters. This meant that the entire visual language of print, such as typefaces, fonts, font size, and other dimensions of typography, were fixed and inflexible:

Two things changed this. First, Xerox PARC, in its envisioning of graphical user interfaces, brought typography to the graphical user interface. The conduit for this was primarily its vision of word processing, which attempted to translate the ideas from print to the screen, bringing typefaces, fonts, font families, font sizes, font weights, font styles, ligature, kerning, baselines, ascents, descents, and other ideas to graphical user interfaces. Concepts like typefaces—the visual design—and fonts—a particular size and weight of a typeface—had been long developed in print, and were directly adapted to screen. This required answering questions about how to take ideas optimized for ink and paper and translate them to discrete 2-dimensional grids of pixels. Ideas like anti-aliasing and sub-pixel rendering mentioned above, which smooth the harsh edges of pixels, were key to achieving readability.

The second decision that helped bring typography to user interfaces was Steve Jobs taking a calligraphy course at Reed College (calligraphy is like typography, but by hand). He saw that text could be art, that it could be expressive, and that it was central to differentiating the Mac from the full-text horrors of command lines. And so when he saw Xerox PARC’s use of typography and envisioned the Mac, type was at the center of his vision .

Parallel to these efforts was the need to represent all of the symbols in natural language. One of the first standards was ASCII, which represented the Roman characters and Arabic numbers in English, but nothing else. Unicode brought nearly the entire spectrum of symbols and characters to computing, supporting communication within and between every country on Earth.
Research on the technology of typography often focuses on readability. For example, Microsoft, including researchers from Microsoft Research, developed a sub-pixel font rendering algorithm called ClearType, which they found significantly decreased average reading time 5 . Since this work, research on fonts has been limited, with most progress on bringing the full power of fonts in desktop publishing to the web. This has created a much more vibrant marketplace of typeface design.
Animation
While all of the static forms we’ve discussed above are powerful on their own, efforts to animate these forms offered to increase the expressive power of digital media. One early work investigated foundations of animation that might be brought from film animation, including principles of solidity , exaggeration , and reinforcement , which were long used to give life to static images 4 . These principles were tied to specific time-based visual ideas such as arcs, follow-through, slow in/slow out, anticipation, arrivals and departures, and motion blur, all of which are now ubiquitous in things like presentation software and modern graphical user interfaces. Just as these types of motion are used in movies to convey information about action, they are now used in user interfaces to convey information, as in this animation in OS X that simulates a head shaking “no”:
While this basic idea of animating interfaces was straightforward, finding ways to seamlessly implement animation into interfaces was not. Having parts of interfaces move required careful management of the position of interface elements over time, and these were incompatible with the notion of view hierarchies determining element positions at all times. Some of the earliest ideas involved defining constraintsconstraint: A technique of software development in which the value of one thing is made to always be equal to some transofrmation of another value (e.g., the left edge of this square should always be aligned horizontally with the right edge of this circle.) , and letting those constraints determine position over time 17 . For example, a developer might say that an element should be at position A at time t and then at position B at time t+1, and then let the user interface toolkit decide precisely where to render the element between those two times. This same idea could be used to animate any visual property of an element, such as its color, transparency, size, and so on. These same ideas eventually led to more sophisticated animations of direct manipulation interfaces 19 , of icons 8 , and of typography 11 . These ideas coalesced into well-defined transition abstractions that made it easier to express a range of “emotions” through transitions, such as urgency, delay, and confidence 9 .
All of these research ideas are now ubiquitous in toolkits like Apple’s Core Animation and Google’s Material Design , which make it easy to express animation states without having to manage low-level details of user interface rendering.
Data
All of the techniques in the prior section come together in many complex 2D visualizations. One domain in particular that has leveraged displays, graphics, typography, and animation is data visualization. This has provoked questions about how to best render and interact with data sets. The field of data visualization (also known as information visualization) has explored these questions, building upon data visualization efforts in print 15 .
The foundations of data visualization are relatively stable:
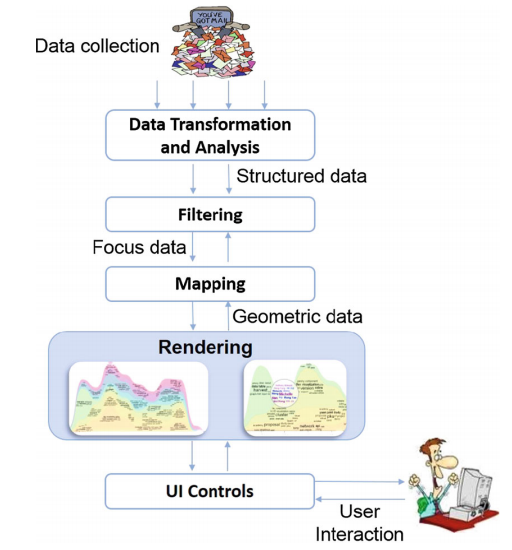
Each of these phases has its own interactive complexities. Data transformation often requires interaction in order to “wrangle” data into a structure suitable for visualization ( 10 . Filtering involves selecting data for view. Mapping involves taking data values and translating them into things like color, shape, space, size, proximity, and other features of visual information. And then there are a wide array of interaction techniques for seeing relationships between data, including selection, filtering, brushing, linking, focus, and facets.
Because of the complexity of this pipeline, actually rendering data visualizations has required more direct toolkit support for abstracting away some of the low-level complexities of these phases.
Toolkits like Protovis 1 , D3 2 , and Vega 18 all offer abstractions that reduce this complexity, making it easier to create both static and interactive data visualizations.

While the 2000’s saw 3D begin to dominate games and movies, 2D rendering is still at the heart of interactions with user interfaces. While much of the research in this space has moved on to interactive 3D experiences, the foundations built over the past fifty years remain with us. Will 2D always be the foundation of interfaces, or will we eventually all shift to pure 3D interfaces?
In some sense, this question is less about technology and more about media. Print, film, animation, games, and other genres of content have often shaped the types of experiences we have on computers. There is no sign that these diverse genres of media are going away; rather, we just continue to invent new media, and add it to an already complex array of visual content. For example, one could imagine a world that was more universally accessible, in which auditory content become more ubiquitous. Podcasts and increasing support for screen readers are one sign that while visual displays may reign, we may begin to broaden the senses we use to interact with computers.
References
-
Michael Bostock and Jeffrey Heer (2009). Protovis: A Graphical Toolkit for Visualization. IEEE Transactions on Visualizations and Computer Graphics.
-
Michael Bostock, Vadim Ogievetsky, Jeffrey Heer (2011). D³ data-driven documents. IEEE transactions on Visualization and Computer Graphics.
-
Xiang Cao, Clifton Forlines, Ravin Balakrishnan (2007). Multi-user interaction using handheld projectors. ACM Symposium on User Interface Software and Technology (UIST).
-
Bay-Wei Chang and David Ungar (1993). Animation: from cartoons to the user interface. ACM Symposium on User Interface Software and Technology (UIST).
-
Andrew Dillon, Lisa Kleinman, Gil Ok Choi, Randolph Bias (2006). Visual search and reading tasks using ClearType and regular displays: two experiments. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Daniel Gotsch, Xujing Zhang, Juan Pablo Carrascal, Roel Vertegaal (2016). HoloFlex: A Flexible Light-Field Smartphone with a Microlens Array and a P-OLED Touchscreen. ACM Symposium on User Interface Software and Technology (UIST).
-
Tobias Grosse-Puppendahl, Steve Hodges, Nicholas Chen, John Helmes, Stuart Taylor, James Scott, Josh Fromm, David Sweeney (2016). Exploring the Design Space for Energy-Harvesting Situated Displays. ACM Symposium on User Interface Software and Technology (UIST).
-
Chris Harrison, Gary Hsieh, Karl D.D. Willis, Jodi Forlizzi, Scott E. Hudson (2011). Kineticons: using iconographic motion in graphical user interface design. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Scott E. Hudson and John T. Stasko (1993). Animation support in a user interface toolkit: flexible, robust, reusable abstractions. ACM Symposium on User Interface Software and Technology (UIST).
-
Sean Kandel, Jeffrey Heer, Catherine Plaisant, Jessie Kennedy, Frank van Ham, Nathalie Henry Riche, Chris Weaver, Bongshin Lee, Dominique Brodbeck, Paolo Buono (2011). Research directions in data wrangling: Visualizations and transformations for usable and credible data. Information Visualization.
-
Johnny C. Lee, Jodi Forlizzi, Scott E. Hudson (2002). The kinetic typography engine: an extensible system for animating expressive text. ACM Symposium on User Interface Software and Technology (UIST).
-
Johnny C. Lee, Scott E. Hudson, Jay W. Summet, Paul H. Dietz (2005). Moveable interactive projected displays using projector based tracking. ACM Symposium on User Interface Software and Technology (UIST).
-
Johnny C. Lee, Scott E. Hudson, Edward Tse (2008). Foldable interactive displays. ACM Symposium on User Interface Software and Technology (UIST).
-
David Lindlbauer, Toru Aoki, Robert Walter, Yuji Uema, Anita Höchtl, Michael Haller, Masahiko Inami, Jörg Müller (2014). Tracs: transparency-control for see-through displays. ACM Symposium on User Interface Software and Technology (UIST).
-
Liu, Shixia, Weiwei Cui, Yingcai Wu, Mengchen Liu (2014). A survey on information visualization: recent advances and challenges. The Visual Computer 30, no. 12 (2014): 1373-1393.
-
Kent Lyons, Seung Wook Kim, Shigeyuki Seko, David Nguyen, Audrey Desjardins, Mélodie Vidal, David Dobbelstein, Jeremy Rubin (2014). Loupe: a handheld near-eye display. ACM Symposium on User Interface Software and Technology (UIST).
-
Brad A. Myers, Robert C. Miller, Rich McDaniel, Alan Ferrency (1996). Easily adding animations to interfaces using constraints. ACM Symposium on User Interface Software and Technology (UIST).
-
Arvind Satyanarayan, Kanit Wongsuphasawat, Jeffrey Heer (2014). Declarative interaction design for data visualization. ACM Symposium on User Interface Software and Technology (UIST).
-
Bruce H. Thomas and Paul Calder (1995). Animating direct manipulation interfaces. ACM Symposium on User Interface Software and Technology (UIST).

3D Visual Output
In the last chapter, we discussed how interfaces communicate data, content, and animations on two-dimensional screens. However, human visual perception is not limited to two dimensions: we spend most of our lives interacting in three-dimensional space. The prevalence of flat screens on our computers, smartwatches, and smartphones is primarily due to limitations in the technology. However, with advances in 3D graphics, display technology, and sensors, we’ve been able to build virtual and augmented reality systems that allow us to interact with technology in immersive 3D environments.
Computing has brought opportunities to create dynamic virtual worlds, but with this has come the need to properly map those virtual worlds onto our ability to perceive our environment. This poses a number of interdisciplinary research challenges that has seen renewed interest over the last decade. In this chapter, we’ll explore some of the current research trends and challenges in building virtual reality and augmented reality systems.
Virtual reality
The goal of virtual realityvirtual reality: Interfaces that attempt to achieve immersion and presence through audio, vidoe, and tactile illusion. (VR) has always been the same as the 2D virtual realities we discussed in the previous chapter: immersionimmersion: The illusory experience of interacting with virtual content for what represents, as opposed to the low-level light, sound, haptics and other sensory information from whic it is composed. . Graphical user interfaces, for example, can result in a degree of immersive flow when well designed. Movies, when viewed in movie theaters, are already quite good at achieving immersion. Virtual reality aims for total immersion, while integrating interactivity.
But VR aims for more than immersion. It also seeks to create a sense of presencepresence: The sense of being physically located in a place and space. . Presence is an inherent quality of being in the physical world. And since we cannot escape the physical world, there is nothing about strapping on a VR headset that inherently lends itself to presence: by default, our exerience will be standing in a physical space with our head covered by a computer. And so a chief goal of VR is creating such a strong illusion that users perceive the visual sensations of being in a virtual environment, actually engaged and psychologically present in the environment.
One of the core concepts behind achieving presence in VR is enabling the perception of 3D graphics by presenting a different image to each eye using stereo displays. By manipulating subtle differences between the image in each eye, it is possible to make objects appear at a particular depth. An early example using this technique was the View-Master , a popular toy developed in the 1930s that showed a static 3D scene using transparencies on a wheel.

One of the first virtual reality systems to be connected to a computer was Ivan Sutherland’s “Sword of Damocles”, shown below, and created in 1968. With his student Bob Sproull, the headmounted display they created was far too heavy for someone to wear. The computer generated basic wireframe rooms and objects. This early work was pure proof of concept, trying to imagine a device that could render any interactive virtual world.
In the 1990s, researchers developed CAVE systems (cave automatic virtual environments) to explore fully immersive virtual reality. These systems used multiple projectors with polarized light and special 3D glasses to control the image seen by each eye. After careful calibration, a CAVE user will perceive a fully 3D environment with a wide field of view.

Jaron Lanier, one of the first people to write and speak about VR in its modern incarnation, originally viewed VR as an “empathy machine” capable of helping humanity have experiences that they could not have otherwise. In an interview with the Verge in 2017 , he lamented how much of this vision was lost in the modern efforts to engineer VR platforms:
If you were interviewing my 20-something self, I’d be all over the place with this very eloquent and guru-like pitch that VR was the ultimate empathy machine — that through VR we’d be able to experience a broader range of identities and it would help us see the world in a broader way and be less stuck in our own heads. That rhetoric has been quite present in recent VR culture, but there are no guarantees there. There was recently this kind of ridiculous fail where [ Mark ] Zuckerberg was showing devastation in Puerto Rico and saying, “This is a great empathy machine, isn’t it magical to experience this?” While he’s in this devastated place that the country’s abandoned. And there’s something just enraging about that. Empathy should sometimes be angry, if anger is the appropriate response.
While modern VR efforts have often been motivated by ideas of empathy, most of the research and development investment has focused on fundamental engineering and design challenges over content:
- Making hardware light enough to fit comfortably on someone’s head
- Untethering a user from cables, allowing freedom of movement
- Sensing movement at a fidelity to mirror movement in virtual space
- Ensuring users don’t hurt themselves in the physical world because of total immersion
- Devising new forms of input that work when a user cannot even see their hands
- Improving display technology to reduce simulator sickness
- Adding haptic feedback to further improve as sense of immersion
Most HCI research on these problems has focused on new forms of input and output. For example, researchers have considered ways of using the backside of a VR headset as touch input 10,12,18,25 , and the use of pens or other tools for sketching in VR 1 . Researchers have also investigated the use of haptics to allow the user to feel aspects of the virtual environment. Recent examples of advances in haptics include placing a flywheel on the headset to simulate inertia 11 , using ultrasound to deliver feedback to the hands 17 , or rendering shear forces on the fingertips with wearable devices 23 . Some of these approaches have been applied to non-virtual immersive experiences for blind people, providing vibrations and spatialized audio on a cane 24 . Another class of haptic devices rely on handheld controllers, adding the ability to render the sensation of weight 26 , grasping an object 7 , or exploring virtual 3D surfaces 6 , as in this demo:
Some approaches to VR content have focused on somewhat creepy ways of exploiting immersion to steer users’ attention or physical direction of motion. Examples include using a haptic reflex on the head to steer users 15 , or this system, which nudges humans to walk in a direction under someone else’s control by shifting the user’s field of view 13 :
Other more mainstream applications have included training simulations and games 27 and some educational applications 21 . But designers are still very much learning about how to exploit the unique properties of the medium in search of killer apps, including decisions like how to ease or heighten the “exit” experience of transitioning from VR back to the world 14 . Beyond gaming, the industry has also explored VR as a storytelling medium. For example, Henry is a short story designed by Oculus Story Studio that won the first Emmy award for a VR short. Because of VR’s roots in the video game industry, designers and storytellers have made use of game engines for storytelling, but custom design tools for storytelling will likely evolve over time.
Augmented reality
Augmented realityaugumented reality: An interface that layers on interactive virtual content into the physical world. (AR), in contrast to virtual reality, does not aim for complete immersion in a virtual environment, but to alter reality to support human augmentation. aa Augmented reality and mixed reality are sometimes used interchangeably, both indicating approaches that superimpose information onto our view of the physical world. However, marketing has often defined mixed reality as augmented reality plus interaction with virtual components. The vision for AR goes back to Ivan Sutherland (of Sketchpad ) in the 1960’s, who dabbled with head mounted displays for augmentation. Only in the late 1990’s did the hardware and software sufficient for augmented reality begin to emerge, leading to research innovation in displays, projection, sensors, tracking, and, of course, interaction design 2 . This has culminated in a range of commercially available techniques and toolkits for AR, most notably Apple’s ARKit , which is the most ubiquitous deployment of a mixed reality platform to date. Other notable examples are ARCore , which emerged from Google’s Project Tango , and Microsoft’s Hololens . All are heavily informed by decades of academic and industry research on augmented reality.
Technical and design challenges in AR are similar to those in VR, but with a set of additional challenges and constraints. For one, the requirements of tracking accuracy and latency are much stricter, since any errors in rendering virtual content will be made more obvious by the physical background. For head-mounted AR systems, the design of displays and optics are challenging, since they must be able to render content without obscuring the user’s view of the real world. When placing virtual objects in a physical space, researchers have looked at how to match the lighting of the physical space so virtual objects look believable 16,22 . HCI contributions to AR have focused primarily on how to coordinate input and output in mixed reality applications. For example, one application envisioned a method for remote participants using VR, with others using AR to view the remote participant as teleported into a target environment 20 :
Interaction issues here abound. How can users interact with the same object? What happens if the source and target environments are not the same physical dimensions? What kind of broader context is necessary to support collaboration? Some research has tried to address some of these lower-level questions. For example, one way for remote participants to interact with a shared object is to make one of them virtual, tracking the real one in 3D 19 . Another project provided an overview of the physical space and the objects in it, helping to facilitate interaction with virtual objects 4 . Research has also dealt with how to annotate physical scenes without occluding important objects, requiring some notion of what is and is not important in a scene 3 . Other researchers have looked at how to use physical objects to interact with virtual characters. 8 .
Some interaction research attempts to solve lower-level challenges. For example, many AR glasses have narrow field of view, limiting immersion, but adding further ambient projections can widen the viewing angle 5 . There are also other geometric limitations in scene tracking, which can manifest as registration errors between the graphics and the physical world, leading to ambiguity in interaction with virtual objects. This can be overcome by propagating geometric uncertainty throughout the scene graph of the rendered scene, improving estimates of the locations of objects in real time 9 .
From smartphone-based VR, to the more advanced augmented and mixed reality visions blending the physical and virtual worlds, designing interactive experiences around 3D output offers great potential for new media, but also great challenges in finding meaningful applications and seamless interactions. Researchers are still hard at work trying to address these challenges, while industry forges ahead on scaling the robust engineering of practical hardware.
There are also many open questions about how 3D output will interact with the world around it:
- How can people seamlessly switch between AR, VR, and other modes of use while performing the same task?
- How can VR engage groups when not everyone has a headset?
- What activities are VR and AR suitable for? What tasks are they terrible for?
These and a myriad of other questions are critical for determining what society chooses to do with AR and VR and how ubiquitous it becomes.
References
-
Rahul Arora, Rubaiat Habib Kazi, Fraser Anderson, Tovi Grossman, Karan Singh, George Fitzmaurice (2017). Experimental Evaluation of Sketching on Surfaces in VR. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Azuma, R., Baillot, Y., Behringer, R., Feiner, S., Julier, S., & MacIntyre, B (2001). Recent advances in augmented reality. IEEE Computer Graphics and Applications.
-
Blaine Bell, Steven Feiner, Tobias Höllerer (2001). View management for virtual and augmented reality. ACM Symposium on User Interface Software and Technology (UIST).
-
Blaine Bell, Tobias Höllerer, Steven Feiner (2002). An annotated situation-awareness aid for augmented reality. ACM Symposium on User Interface Software and Technology (UIST).
-
Hrvoje Benko, Eyal Ofek, Feng Zheng, Andrew D. Wilson (2015). FoveAR: Combining an Optically See-Through Near-Eye Display with Projector-Based Spatial Augmented Reality. ACM Symposium on User Interface Software and Technology (UIST).
-
Hrvoje Benko, Christian Holz, Mike Sinclair, Eyal Ofek (2016). NormalTouch and TextureTouch: High-fidelity 3D Haptic Shape Rendering on Handheld Virtual Reality Controllers. ACM Symposium on User Interface Software and Technology (UIST).
-
Inrak Choi, Heather Culbertson, Mark R. Miller, Alex Olwal, Sean Follmer (2017). Grabity: A wearable haptic interface for simulating weight and grasping in virtual reality. ACM Symposium on User Interface Software and Technology (UIST).
-
Cimen, G., Yuan, Y., Sumner, R. W., Coros, S., & Guay, M. (2017). Interacting with intelligent Characters in AR. Workshop on Artificial Intelligence Meets Virtual and Augmented Worlds (AIVRAR).
-
Enylton Machado Coelho, Blair MacIntyre, Simon J. Julier (2005). Supporting interaction in augmented reality in the presence of uncertain spatial knowledge. ACM Symposium on User Interface Software and Technology (UIST).
-
Jan Gugenheimer, David Dobbelstein, Christian Winkler, Gabriel Haas, Enrico Rukzio (2016). Facetouch: Enabling touch interaction in display fixed uis for mobile virtual reality. ACM Symposium on User Interface Software and Technology (UIST).
-
Jan Gugenheimer, Dennis Wolf, Eythor R. Eiriksson, Pattie Maes, Enrico Rukzio (2016). GyroVR: simulating inertia in virtual reality using head worn flywheels. ACM Symposium on User Interface Software and Technology (UIST).
-
Yi-Ta Hsieh, Antti Jylhä, Valeria Orso, Luciano Gamberini, Giulio Jacucci (2016). Designing a willing-to-use-in-public hand gestural interaction technique for smart glasses. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Akira Ishii, Ippei Suzuki, Shinji Sakamoto, Keita Kanai, Kazuki Takazawa, Hiraku Doi, Yoichi Ochiai (2016). Optical marionette: Graphical manipulation of human's walking direction. ACM Symposium on User Interface Software and Technology (UIST).
-
Jarrod Knibbe, Jonas Schjerlund, Mathias Petraeus, and Kasper Hornbæk (2018). The Dream is Collapsing: The Experience of Exiting VR. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Yuki Kon, Takuto Nakamura, Hiroyuki Kajimoto (2017). HangerOVER: HMD-embedded haptics display with hanger reflex. ACM SIGGRAPH Emerging Technologies.
-
P. Lensing and W. Broll (2012). Instant indirect illumination for dynamic mixed reality scenes. IEEE International Symposium on Mixed and Augmented Reality (ISMAR).
-
Benjamin Long, Sue Ann Seah, Tom Carter, Sriram Subramanian (2014). Rendering volumetric haptic shapes in mid-air using ultrasound. ACM Transactions on Graphics.
-
Franklin A. Lyons (2016). Mobile Head Mounted Display. U.S. Patent USD751072S1.
-
Ohan Oda, Carmine Elvezio, Mengu Sukan, Steven Feiner, Barbara Tversky (2015). Virtual replicas for remote assistance in virtual and augmented reality. ACM Symposium on User Interface Software and Technology (UIST).
-
Sergio Orts-Escolano, Christoph Rhemann, Sean Fanello, Wayne Chang, Adarsh Kowdle, Yury Degtyarev, David Kim, Philip L. Davidson, Sameh Khamis, Mingsong Dou, Vladimir Tankovich, Charles Loop, Qin Cai, Philip A. Chou, Sarah Mennicken, Julien Valentin, Vivek Pradeep, Shenlong Wang, Sing Bing Kang, Pushmeet Kohli, Yuliya Lutchyn, Cem Keskin, Shahram Izadi (2016). Holoportation: virtual 3d teleportation in real-time. ACM Symposium on User Interface Software and Technology (UIST).
-
Pan, Z., Cheok, A. D., Yang, H., Zhu, J., & Shi, J. (2006). Virtual reality and mixed reality for virtual learning environments. Computers & Graphics.
-
T. Richter-Trummer, D. Kalkofen, J. Park and D. Schmalstieg, (2016). Instant Mixed Reality Lighting from Casual Scanning. IEEE International Symposium on Mixed and Augmented Reality (ISMAR).
-
Samuel B. Schorr and Allison M. Okamura (2017). Fingertip Tactile Devices for Virtual Object Manipulation and Exploration. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Alexa F. Siu, Mike Sinclair, Robert Kovacs, Eyal Ofek, Christian Holz, and Edward Cutrell (2020). Virtual Reality Without Vision: A Haptic and Auditory White Cane to Navigate Complex Virtual Worlds. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Eric Whitmire, Mohit Jain, Divye Jain, Greg Nelson, Ravi Karkar, Shwetak Patel, Mayank Goel (2017). Digitouch: Reconfigurable thumb-to-finger input and text entry on head-mounted displays. ACM Interactive Mobile Wearable Ubiquitous Technology.
-
Andre Zenner and Antonio Kruger (2017). Shifty: A weight-shifting dynamic passive haptic proxy to enhance object perception in virtual reality. IEEE Transactions on Visualization and Computer Graphics.
-
Zyda, M. (2005). From visual simulation to virtual reality to games. Computer, 38(9), 25-32.

Physical Output
Whereas the three-dimensional output we discussed in the previous chapter can create entirely new virtual worlds, or enhanced versions of our own world, it’s equally important that software be able to interface with the physical world. One of the first research papers to recognize this was the seminal work Tangible Bits: Towards Seamless Interfaces between People, Bits and Atoms . 8 In it, Ishii and Ullmer described a rift between the digital and physical world:
We live between two realms: our physical environment and cyberspace. Despite our dual citizenship, the absence of seamless couplings between these parallel existences leaves a great divide between the worlds of bits and atoms. At the present, we are torn between these parallel but disjoint spaces... Streams of bits leak out of cyberspace through a myriad of rectangular screens into the physical world as photon beams. However, the interactions between people and cyberspace are now largely confined to traditional GUI (Graphical User Interface)-based boxes sitting on desktops or laptops. The interactions with these GUIs are separated from the ordinary physical environment within which we live and interact. Although we have developed various skills and work practices for processing information through haptic interactions with physical objects (e.g., scribbling messages on Post-It notes and spatially manipulating them on a wall) as well as peripheral senses (e.g., being aware of a change in weather through ambient light), most of these practices are neglected in current HCI design because of the lack of diversity of input/output media, and too much bias towards graphical output at the expense of input from the real world.
This basic idea, that the massive rift between our physical and digital worlds should be bridged by a diversity of new physical input and output media, dovetailed Weiser’s vision of ubiquitous computing. 19 However, rather than envisioning a world of embedded computing, it focused on our embodied experiences with physical objects. Both of these themes are another example of how interfaces play a central role in mediating our interactions .
The impact of this vision was an explosion of research to create more physical input and output. In this chapter, we’ll discuss this research, and the history of physical computing that it build upon.
Printing
Most people who’ve interacted with computers have used a printer at some point in their life to turn bits into atoms. The basic principle is simple: take a digital document and create a copy with paper and some kind of marking substance, such as spraying ink (inkjets), burning the paper (laser printers), or one of a variety of other approaches.
Why was printing so important as computers first became ubiquitous?
For most of the 20th century, paper was the central medium for transmitting information. We used typewriters to create documents. We stored documents in file cabinets. We used photocopiers to duplicate documents. The very notion of a file and folder in graphical user interfaces mirrored the ubiquity of interacting with paper. Printers were a necessary interface between the nascent digital world and the dominant paper-based world of information.
One of the earliest forms of digital printing was the stock ticker machine, which printed text on a thin strip of paper on which messages are recorded:

While ticker tape was the most ubiquitous before the advent of digital computers, printing devices had long been in the imagination of early computer scientists. Charles Babbage was an English mathematician and philosopher who first imagined the concept of a programmable digital computer in 1822. He also imagined, however, a mechanical printing device that could print the results of his imagined differencing machine. Eventually, people began to engineer these printing devices. For example, consider the dot matrix printer shown in the video below, which printed a grid of ink. These printers were ubiquitous in the 1980’s, and a general extension of both ticker tape printers and a deeper integration with digital printing from general purpose computers. This was the beginning of a much greater diversity of printing mediums we use today, which use toner, liquid ink, solid ink, or dye-sublimation.
Most of these printing technologies have focused on 2-dimensional output because the documents we create on computers are primarily 2-dimensional. However, as the plastics industry evolved, and plastic extruders reshaped manufacturing, interest in democratizing access to 3D fabrication expanded. This led to the first 3D printer, described in a U.S. patent in 1984, which described a process for generating 3D objects by creating cross-sectional patterns of an object. 7 These early visions for personal 3D printing, combined with decades of research on the basic technologies required to manufacture printers at scale, eventually led to a new market for 3D printing, including companies like MakerBot . These printers also required the creation of new software to model printable 3D forms.
While the basic idea of 3D printing is now well established, and the market for 3D printers is expanding, researchers have gone well beyond the original premise. Much of this exploration has been in exploring materials other than plastic. One example of this is an approach to printing interactive electromechanical objects with wound in place coils . 17 These objects, made of copper wire, and structural plastic elements, allows for the printing of objects like actuated arms of toys, electric motors, and electronic displays:
Another project explored printing with wool and wool blend yarn to create soft felt objects rather than just rigid plastic objects. 6 Techniques like this and the one above simultaneously innovate in printing techniques, but also in exploring the possibilities of new media for bridging the digital and physical world.
These new forms of printing pose new challenges in authoring. One cannot print arbitrary 3D shapes with 3D printers, and so this requires authors to understand the limitations of printing methods. This lack of understanding can lead to failed prints, which can be frustrating and expensive. Some researchers have explored “patching” 3D objects, calculating additional parts that must be printed and mounted onto an existing failed print to create the desired shape. 18 Other research has investigated new software tools for extending, repairing, or modifying everyday objects by modeling those objects and streamlining the creation of attachment objects 4 :
These techniques, while not advancing how objects are printed, innovate in how we author objects to print, much like research innovations in word processing software from the 1980’s and 1990’s.
Of course, just as 2D printing imposes gulfs of execution and evaluation — trying to configure a printer to have the right printed margins, debugging why they don’t — 3D printing comes with its own sets of challenges. For example, Kim et al. 10 investigated the use of 3D printers to create 3D printed augmentations of physical objects found that the measurement error discrepancies between an abstract 3D model and its printed form were often a significant challenge for users of 3D printers. Improvements to measurement instruments, such as better precision, more interpretable measurements, and better instructions for measuring, were all essential skills in successful printing.
Morphing
Whereas printing is all about creating physical form to digital things, another critical bridge between the physical and digital world is adapting digital things to our physical world. Screens, for example, are one of the key ways that we present digital things, but their rigidity has a way of defining the physical form of objects, rather than objects defining the physical form of screens. The iPhone is a flat sheet of glass, defined by the screen; a laptop is shape of a screen. Researchers have long pondered whether screens must be flat, envisioning different forms of output that might have new unimagined benefits.
Some research has focused on making screens flexible and bendable. For example, one technique takes paper, plastics, and fabrics, and makes it easy to create programmable shape-changing behaviors with those materials. 16 As seen in the video below, this creates a new kind of digital display that can dynamically convey information and shape.
Other projects have created stretchable user interfaces with sensing capabilities and visual output, allowing for conventional experiences in unconventional places. 20 As seen in the video below, these screens adapt to objects’ physical forms, rather than requiring objects to adapt to a rectangular display:
Some research has even explored foldable interactive objects by using thin-film printed electronics. 15 The video below shows several examples of the types of new interactive physical forms that such materials might enable:
This line of research innovates in both the industrial forms that interfaces take, while offering new possibilities for how they are manipulated physically. It envisions a world in which digital information might be presented and interacted with in the shape most suitable to the data, rather than adapting the data to the shape of a screen. Most of these innovation efforts are not driven by problems with existing interfaces, but opportunities for new experiences that we have not yet envisioned. With many innovations from research such as foldable displays now make it to market, we can see how technology-driven innovation, versus problem-driven innovation, can struggle to demonstrate value in the marketplace.
Haptics
Whereas morphing interfaces change the structural properties of the interface forms, others have focused on offering physical, tangible feedback. Feedback is also critical to achieving the vision of tangible bits, as the more physical our devices become, the more they need to communicate back to us through physical rather than visual form. We call physical feedback haptic feedback, because it leverages people’s perception of touch and sense of where their body is in space (known as proprioception).
Kim et al. 11 laid out a rich framework for thinking about the design of haptics. They argue that the essential design parameters of haptics are about the timelineness , intensity , density , and timbre of feedback, which, respectively, concern the latency of when feedback arrives, the force applied, the amount of feedback that occurs over time, and the “tone, texture, color, or quality” of feedback patterns. The framework also argues that task-level concerns include the utility of the feedback, the degree to which the cause of the feedback is clear, the consistency of it’s delivery, and its saliency . These two lower levels of feedback characteristics can combine along several experiential dimensions, such as how harmonious it is with other sensory feedback, how expressive it is relative to other haptic feedback, how immersive it is, and how realistic it is. All of these factors, along with the ability to personalize all of these factors, create a rich design space.
Numerous works have explored this design space in depth. For instance, some haptic feedback operates at a low level of human performance, such as this idea, which recreates the physical sensation of writing on paper with a pencil, ballpoint pen or marker pen, but with a stylus 5 :
Other haptic feedback aims to provide feedback about user interface behavior using physical force. For example, one project used electrical muscle stimulation to steer the user’s wrist while plotting charts, filling in forms, and other tasks, to prevent errors. 13 Another used airflow to provide feedback without contact 12 :
Many projects have used haptics to communicate detailed shape information, helping to bring tactile information to visual virtual worlds. Some have used ultrasound to project specific points of feedback onto hands in midair. 3 Others used electrovibration, integrated with touch input, enabling the design interfaces that allow users to feel virtual elements. 2 Some projects have used physical forms to provide shape information, such as this gel-based surface imposed on a multi-touch sensor allowing for freely morphed arbitrary shapes 14 :
Some work leverages visuo-haptic illusions to successfully trick a user’s mind into feeling something virtual. For example, one work displayed a high resolution visual form with tactile feedback from a low-resolution grid of actuated pins that move up and down, giving a sense of high-resolution tactile feedback. 1 Some projects have created a sense of virtual motion by varying waves of actuator motion left or right. 9 In anticipation of virtual reality simulations of combat, some have even created perceptions of being physically hit by tapping the skin gently while thrusting a user’s arm backwards using electrical muscle stimulation 13 :
All of these approaches to haptic feedback bridge the digital and physical worlds by letting information from digital world to reach our tactile senses. In a sense, all haptic feedback is about bridging gulfs of evaluation in physical computing: in a physical device, how can the device communicate that it’s received input and clearly convey its response?
While this exploration of media for bridging bits and atoms has been quite broad, it is not yet deep. Many of these techniques are only just barely feasible, and we still know little about what we might do with these techniques, how useful or valued these applications might be, or what it would take to manufacture and maintain the hardware they require. There are also many potential unintended consequences by giving computers the ability to act in the world, from 3D printing guns to potential injuries.
Nevertheless, it’s clear that the tangible bits that Ishii and Ullmer envisioned are not only possible, but rich, under-explored, and potentially transformative. As the marketplace begins to build some of these innovations into products, we will begin to see just how valuable these innovations are in practice.
References
-
Parastoo Abtahi, Sean Follmer (2018). Visuo-haptic illusions for improving the perceived performance of shape displays. CHI.
-
Olivier Bau, Ivan Poupyrev, Ali Israr, Chris Harrison (2010). TeslaTouch: electrovibration for touch surfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Tom Carter, Sue Ann Seah, Benjamin Long, Bruce Drinkwater, Sriram Subramanian (2013). UltraHaptics: multi-point mid-air haptic feedback for touch surfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Xiang 'Anthony' Chen, Stelian Coros, Jennifer Mankoff, Scott E. Hudson (2015). Encore: 3D printed augmentation of everyday objects with printed-over, affixed and interlocked attachments. ACM Symposium on User Interface Software and Technology (UIST).
-
Cho, Y., Bianchi, A., Marquardt, N., & Bianchi-Berthouze, N. (2016). RealPen: Providing realism in handwriting tasks on touch surfaces using auditory-tactile feedback. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson (2014). Printing teddy bears: a technique for 3D printing of soft interactive objects. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Hull, C. (1984). Patent No. US4575330 A. United States of America.
-
Hiroshi Ishii and Brygg Ullmer. (1997). Tangible bits: Towards seamless interfaces between people, bit, atoms. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Joseph 'Jofish' Kaye (2012). Sawtooth planar waves for haptic feedback. ACM Symposium on User Interface Software and Technology (UIST).
-
Jeeeun Kim, Anhong Guo, Tom Yeh, Scott E. Hudson, and Jennifer Mankoff (2017). Understanding Uncertainty in Measurement and Accommodating its Impact in 3D Modeling and Printing. ACM Conference on Designing Interactive Systems (DIS).
-
Erin Kim, Oliver Schneider (2020). Defining Haptic Experience: Foundations for Understanding, Communicating, and Evaluating HX. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Jaeyeon Lee and Geehyuk Lee (2016). Designing a non-contact wearable tactile display using airflows. ACM Symposium on User Interface Software and Technology (UIST).
-
Pedro Lopes, Alexandra Ion, Patrick Baudisch (2015). Impacto: Simulating physical impact by combining tactile stimulation with electrical muscle stimulation. ACM Symposium on User Interface Software and Technology (UIST).
-
Viktor Miruchna, Robert Walter, David Lindlbauer, Maren Lehmann, Regine von Klitzing, Jörg Müller (2015). Geltouch: Localized tactile feedback through thin, programmable gel. ACM Symposium on User Interface Software and Technology (UIST).
-
Simon Olberding, Sergio Soto Ortega, Klaus Hildebrandt, Jürgen Steimle (2015). Foldio: digital fabrication of interactive and shape-changing objects with foldable printed electronics. ACM Symposium on User Interface Software and Technology (UIST).
-
Jifei Ou, Mélina Skouras, Nikolaos Vlavianos, Felix Heibeck, Chin-Yi Cheng, Jannik Peters, Hiroshi Ishii (2016). aeroMorph - Heat-sealing Inflatable Shape-change Materials for Interaction Design. ACM Symposium on User Interface Software and Technology (UIST).
-
Huaishu Peng, François Guimbretière, James McCann, Scott Hudson (2016). A 3D Printer for Interactive Electromagnetic Devices. ACM Symposium on User Interface Software and Technology (UIST).
-
Alexander Teibrich, Stefanie Mueller, François Guimbretière, Robert Kovacs, Stefan Neubert, Patrick Baudisch (2015). Patching Physical Objects. ACM Symposium on User Interface Software and Technology (UIST).
-
Mark Weiser (1991). The Computer for the 21st Century. Scientific American 265, 3 (September 1991), 94-104.
-
Michael Wessely, Theophanis Tsandilas, Wendy E. Mackay (2016). Stretchis: Fabricating Highly Stretchable User Interfaces. ACM Symposium on User Interface Software and Technology (UIST).

Help
In our discussion of theory at the beginning of this book, I made the case that a precondition of using an interface is learning the interface. One way to make this learning seamless is to minimize gulfs of execution and evaluation. A good designer minimizes gulfs by understanding what people want and need to do with interfaces, and making the mapping between those things and interface actions as tight as possible. Another way that designers achieve this is by simplifying designs, so there’s simply less to learn.
Sometimes, however—let’s be honest, most of the time—the mapping from goals to action in interfaces isn’t so tight. Interfaces introduce new concepts and users have to learn them. Sometimes things go wrong, and to recover from an error, people need to acquire a more nuanced model of how the interface works. And sometimes, interfaces are just irreducibly complex, offering great power that requires instruction and practice to fully harness. And interfaces are only getting more complex: 3D printing, tangible interfaces, sensor-based interactions, new techniques for pointing and text, and the countless other new media we’ve discussed all require some learning to use successfully.
One way to support this learning is to train people. Apple Stores offer classes on how to use Apple software. Purveyors of augmented and virtual reality devices offer demos that help people acclimate to gestures and heads up displays. Community colleges offer classes on ubiquitous software programs like Microsoft Office, helping people who aren’t comfortable tinkering with interfaces to get explicit guidance on their use. YouTube is now full of millions of tutorial videos demonstrating how to use popular interfaces.
The highest ambition of interface learning, however, is for interfaces to teach themselves to people. What kinds of help interfaces can be layered on to interfaces to facilitate rapid independent learning? From tooltips to tutorials, in this chapter we’ll discuss these approaches, and speculate about the future of help.
Theories of help
There are several basic concepts in software help that are...helpful...to know about when understanding the vast range of ideas that have been explored. For instance, applications need to help with many distinct things even to just bridge gulfs of execution 7 :
- Improving users’ understanding of task flow in an application
- Providing awareness of available functionality
- Helping users locate functionality
- Teaching users how to use functionality they have located
- Facilitating transitions from novice to expert user
Norman’s concept of a breakdownbreakdown: Mistakes and confusion that occur because a user’s mental model is inconsistent with an interface’s actual functionality. 12 is a useful shorthand for when any of the above five tasks fail to result in learning. Users might self-diagnose the problem, or they might ask for help in an interface or from someone else. This is either resolved or ultimately results the user abandoning the interface. All of these are failures to bridge gulfs of evaluation.
Breakdowns are usually followed by a question. There are many types of questions, each corresponding to the help above 14 , such as “ What kinds of things can I do with this application? ”, “ What is this? ”, “ How do I achieve this goal? ”, “ What does this output mean? ”, “ Where am I? ”.
Providing answers to these questions usually requires natural language. For example, labeling a button appropriately can help a user learn what a button does or adding a header might help a learner understand the flow of interaction in an application. Choosing good words and phrases is therefore key to learnability.
There’s just one problem: research shows that there is rarely a best word or phrase. For example, consider all of the words that essentially mean “ send my data to the cloud ”: save, send, submit, upload, sync, etc. Depending on the context and functionality, all of these might be reasonable descriptions. The diversity of words suitable for describing software functionality is called the vocabulary problem 6 . This is the empirical observation that there is extreme variability in the words that people choose to express a need, and so the single word that a designer chooses for a feature very rarely corresponds to the words that users choose. In fact, for the tasks that Furnas studied, to get 90% of users to recognize a phrase as related to a goal to be accomplished in a user interface, systems must use nearly 20 unique phrases to cover the range of expected descriptions of that goal. This means that most naive text-based help search mechanisms will either have extremely low recall, or if many aliases have been provided, very low precision. You can see the data here:
This trend of high variability of expected words suggests that any one word is rarely going to be sufficient for learning. Therefore interfaces will have to do a lot more than just label or index functionality with just one phrase. For example, they may need to index documentation with multiple different descriptions of the same content. They might also have to teach terminology to people so that they know how to find relevant functionality.
Tutorials
One of the most straightforward ways of offering help is to directly teach an interface to new users. This can include onboarding experiences that explain key features, explain how to navigate an interface, and show how to ask for futher help. In principle, this might seem like the most effective way to prevent future help needs. But in practice, most users are goal-oriented, and view onboarding tutorials as a distraction from whatever goal they are trying to complete. Rosson and Carroll 13 described this as the “paradox of the active user.” Put simply, users need to learn interfaces to succeed at their goal, but users often view learning as a distraction from their goal. This paradoxical behavior forces designers to consider ways of embedding that teaching throughout a user’s goal-driven behavior. For example, this might include waiting until a user reaches a dead end, but making help resources prominent at that dead end. Or, trying to detect if a user is stuck, then recommending relevant help. This paradoxical behavior necessitates the many alternative forms of help in the coming sections.
Searching for help
Perhaps the earliest form of interface help was to write documentation and provide an interface for browsing it. This approach involves titled articles, help topics, or question and answer pairs. In modern technical support platforms, you might find them called knowledge bases or technical support . These platforms vary in whether the designer authors the content or whether the content is crowdsourced from users of the software. For example, a typical support knowledge base might be entirely written by technical writers working for the company that created the software. In contrast, large companies might instead (or in addition to) create question and answer forums in which users ask and answer questions.
While the content that these media contain can often provide assistance for many of the breakdowns a user might have, they have many limitations:
- They require users to leave the interface they are learning and interact with a separate help interface.
- They require a user to express a query or browse, requiring them to know the right terminology to find help. This imposes the vocabulary problem described earlier.
- The answer may not have been written yet.
- With user-generated content, answers may be wrong or out of date.
Some research has tried to tackle these problems by providing more sophisticated representations of help content. For example, the Answer Garden system 1 , published in the late 1990’s, stored Q&A in a graph, allowing users to find Q&A by either playing a game of “diagnostic twenty questions” or viewing the entire graph of questions. Users could ask questions if they don’t find theirs, routing it to an expert, who can add it to the graph of Q&A. An evaluation of the system showed that users loved it when they got answers quickly; they didn’t care where the answer came from. They disliked having to browse every question only to find out the answer wasn’t present and they disliked expert’s long answers, which experts wrote to appear knowledgeable to superiors.

Other approaches focused on contextualizing help in the form of tooltips, providing documents where the user was having trouble rather than requiring them to navigate elsewhere to find an answer. Balloon help, for example, first appeared on Macintosh System 7 , and is now ubiquitous in the form of tooltips:
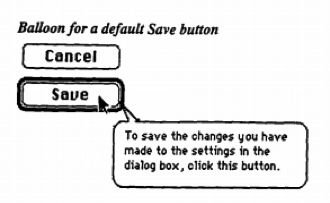
Tooltips can help with simple tasks, but failed to support long, complex procedures, and rely heavily on designers to anticipate help needs, since they are written at design time 5 .
My lab worked on a variation on contextual help that tried to address the problem of static tooltip content. Instead of attaching fixed content to an element, the Lemonaid system (seen below) allowed users to click on an arbitrary element in a user interface to identify the subject of help 4 . It then extracted features of the selection such as its labels, position, and current interface state as a query into a database of Q&A that was indexed by these features. This retrieval algorithm returned multiple possible Q&A related to the element, each with an answer authored by the designer. Over time, the system learned associations between which help content was relevant to which elements of a user interface based on what questions users viewed. It also allowed users to submit questions when they could not find a relevant want, crowdsourcing a mapping between user interface elements and questions. This crowdsourced model was quite effective at both identifying gaps in content, but also creating a tight mapping between where people expected to find help and where help appeared in an interface.

In a rare effort to directly commercialize a help system, my collaborators and I co-founded a company called AnswerDash based on this idea. As with any commercialization effort, our product evolved well beyond the initial idea, incorporating page-specific popular questions and other crowdsourced help features. AnswerDash joined a much broader ecosystem of services built on older ideas, such as knowledge bases, tooltip, and tutorials. You can see some of AnswerDash’s interactive features in this promotional video:
While many newer products have begun to explore the use of digital voice assistants to provide help, they are not essentially different from all of the help retrieval systems above. The only difference is that rather than a person typing a query to a system, they speak it. That query then gets evaluated using all of the same retrieval mechanisms that have existed over the past several decades, relying on content written by technical writers or other users with answers.
Recommending help
Whereas the systems in the previous section required the user to proactively seek help, there have been several attempts to automatically detect when a user needs help. For example, many rudimentary techniques in help chat clients on the web use simple rules, such as “if the user takes no action on a page for 1 minute, offer to chat”. Another basic example is simply providing explanations of how to use a feature in the interface itself, rather than waiting for a user to seek help.
More intelligent techniques monitor activity more systematically, trying to build a more precise model of what a user needs, so it only helps when necessary. For example, the Lumiere system attempted to infer user goals from a history of their actions 8 :

This research was the inspiration for the much-derided Microsoft Clippy , which tried to help in the same way, but did not use any of the sophisticated prediction techniques. This use of inferior rule-based predictions resulted in Clippy interrupting at unwanted times, offering unwanted help.
Another potentially useful signal of a need for help is when users undo or erase actions they have just performed. One project showed that these events can indicate confusion about how to use a feature, where 90% of the undo and erase episodes indicated severe breakdowns in users’ ability to progress on a task 2 .
Another approach is targeting proactive help was to classify users by their expertise. For example, one system tracked low-level mouse movements and menu navigation behaviors and found they are strong indicators of application expertise 9 . This system used a machine learned classifier to predict level of expertise during application use using features of these input streams with 91% accuracy.
Not all techniques for offering help proactively interrupt. For example, the CommunityCommands system embedded data about feature usage in the interface, passively suggesting to users what features they might find useful based on a user’s prior usage history 10 :
Generating answers
While all of the systems above are ultimately driven by content written by humans, some systems assist in streamlining help content generation or generating help content automatically. For example, the MixT system allowed a content author to simply demonstrate an interaction with an application to quickly generate an interactive step-by-step tutorial superior to a screen recording 3 :

The Crystal system, which I helped invent, created fully automated help content on demand 11 . It allowed users to click on anything in a word processor and ask “why” questions about it. The system would answer the why question by analyzing the entire history of interactions with the application, along with the application’s own independent actions (such as autocomplete or defaults) to generate answers. This example explains why a word was auto-corrected to a user surprised when “teh” was corrected to “the”:
While these attempts to generate help automatically can be quite powerful when they work, they are limited. It’s not yet possible to generate answers to any question, for example. And it’s not clear the answers generated are always comprehensible to people. There needs to be significantly more research on these before they are likely to reach widespread use.
Despite the diversity of help interfaces that try to enable interfaces to teach themselves, there’s still a lingering question about whether just how good a help interface can be. Will the gold standard always be having another person—a teacher, essentially—to explain how an interface works? Or is this moot, because there are never enough people with the right expertise at the right time? Or is it possible to just design interfaces that are so learnable, separate help interfaces won’t be necessary?
I suspect that interfaces will always require help systems. They are too artificial and change too much to ever eliminate the need for learning and that means that something or someone will have to do the teaching. If anything, it’s people that will adapt, becoming more accustomed to the constant learning necessary to use new interfaces.
And yet, help has never been more necessary. With the rapid expansion of new interface modalities, new types of sensor-based input, and new experiences being designed around these platforms, explicitly teaching how to use interfaces is becoming a central challenge. Industry has yet to place this teaching at the center of its design processes, instead still viewing as restricted to unboxing or later technical support.
Unfortunately, while research has produced many compelling ideas that advance beyond the basic documentation and tooltips of the 1990’s, there has been little uptake of these ideas in industry. Some of this is due to business models — if a customer pays upfront, or a user is forced to use software licensed by an IT department, there’s little incentive to polish the long term learning experience, as the company will get paid either way. The shift to direct-to-consumer subscription services may better align these incentives, leading companies to focus on improving usability and documentation in order to retain customers long term.
References
-
Mark S. Ackerman (1998). Augmenting organizational memory: a field study of Answer Garden. ACM Transactions on Information Systems.
-
David Akers, Matthew Simpson, Robin Jeffries, Terry Winograd (2009). Undo and erase events as indicators of usability problems. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Pei-Yu Chi, Sally Ahn, Amanda Ren, Mira Dontcheva, Wilmot Li, Björn Hartmann (2012). MixT: automatic generation of step-by-step mixed media tutorials. ACM Symposium on User Interface Software and Technology (UIST).
-
Parmit K. Chilana, Amy J. Ko, Jacob O. Wobbrock (2012). LemonAid: selection-based crowdsourced contextual help for web applications. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
David K. Farkas (1993). The role of balloon help. SIGDOC Asterisk J. Comput. Doc. 17, 2 (May 1993), 3-19.
-
G. W. Furnas, T. K. Landauer, L. M. Gomez, S. T. Dumais (1987). The vocabulary problem in human-system communication. Commun. ACM 30, 11 (November 1987), 964-971.
-
Grossman, T., Fitzmaurice, G., & Attar, R. (2009). A survey of software learnability: metrics, methodologies and guidelines. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Eric Horvitz, Jack Breese, David Heckerman, David Hovel, Koos Rommelse (1998). The Lumière project: Bayesian user modeling for inferring the goals and needs of software users. Conference on Uncertainty in Artificial Intelligence (UAI).
-
Amy Hurst, Scott E. Hudson, Jennifer Mankoff (2007). Dynamic detection of novice vs. skilled use without a task model. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Wei Li, Justin Matejka, Tovi Grossman, Joseph A. Konstan, George Fitzmaurice (2011). Design and evaluation of a command recommendation system for software applications. ACM Transactions on Computer-Human Interaction.
-
Brad A. Myers, David A. Weitzman, Amy J. Ko, Duen H. Chau (2006). Answering why and why not questions in user interfaces. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Don Norman (2013). The design of everyday things: Revised and expanded edition. Basic Books.
-
Rosson, M. B., & Carroll, J. M. (1987). Paradox of the active user. Interfacing thought: Cognitive aspects of human-computer interaction.
-
Sellen, A., & Nicol, A. (1995). Building User-centered on-line help. Human-Computer Interaction.

Intellectual Property
Throughout this book, we’ve discussed countless innovations in user interface software and technology. Our focus has been on the ideas themselves, refining our understanding of how these ideas work, and what opportunities they afford for interaction design. We’ve also talked about the many quality dimensions of these ideas: their utility for certain tasks, their expressiveness at supporting a range of tasks, their support for privacy and security , and the user efficiency they afford. These are all of central concern to the users of these technologies, and so they are necessarily of concern to designers.
There are stakeholders other than users, however. There are the inventors of technologies. There the organizations that subsidize the invention of technologies, such as for-profit companies, or non-profit entities like universities. There is also the general public, for whom the technologies are ultimately invented, and the government, which seeks to make these innovations available to the public. Because these different stakeholder groups want different things—the public wants innovation cheaply available, whereas inventors want credit and potentially compensation for their inventions— ownership of interface technology ideas is of central concern.
This concern of ownership raises broad questions about interface ideas:
- What are interface ideas?
- Should ideas be owned?
- Can ideas be owned?
- Can interface ideas be owned?
- What is the effect of ownership on innovation?
In this chapter, we’ll discuss these questions, and review some of the more notable precedent in copyright and patent law in the United States.
What are interface ideas?
In general, there really is no clear idea about what an interface idea is . There are many representations of ideas, however, that might be proxies for these ideas. For example, people write written descriptions of ideas in specifications, in research papers, and in marketing materials, all of which convey what makes an interface idea unique.
A designer’s sketch of an interface is another coarse representation of an idea. Of course, there’s also the interface implementation itself, which likely captures the essence of an idea, even if it doesn’t describe it explicitly. Each of these can indicate the essence of an idea, and may often explicitly distinguish one idea from others.
In academic research, ideas aren’t treated as discrete things. New ideas are combinations of old ideas, and the extent to which an idea is novel depends on how many ways it differs from prior inventions, and by how much. This is a multidimensional, subjective assessment often woven into peer review. “New” ideas are often attributed to specific researchers, but since research papers heavily cite the prior ideas upon which they were based, ideas are actually a composition of a complex interconnected web of prior ideas.
In industry, ideas are treated similarly when purely internal. Innovations emerge organically from interactions within a company, but also between a company and people outside of it, ultimately resulting in prototypes and employee knowledge of ideas. The biggest difference is that instead of publishing and sharing those ideas publicly, most companies share interface ideas through products, which only implicitly articulate ideas through experiences. Other companies might copy or refine those ideas, but it’s up to them to reverse engineer the essential elements of an idea in order to faithfully recreate it.
Should interface ideas be owned?
As I argued above, interface ideas are compositions of other ideas, and these compositions typically emerge from collaborative design processes. If this is true, how do we reconcile the need to reuse ideas to create new ones with the notion of ownership, which is about preventing reuse? To resolve this conflict, its necessary to reflect on why anyone would want to own an idea at all.
The first and most obvious reason to allow ownership is that ideas are hard to develop. They take time, effort, and money. If the result of all of that effort is that someone can just take your idea and get credit and profit from it, what incentive do you have to exert the effort? For example, why would a company want to task its employees with inventing new interface technologies if the company itself would not have the exclusive right to profit from its ideas? What incentive would an individual inventor have if they couldn’t personally profit from their idea?
The assumption in these questions, of course, is that inventors are only motivated by compensation. Some inventors are motivated by curiosity. For example, academic inventors, subsidized by their teaching efforts, follow their curiosity, invent things that may be of public value, and then often share them for free with the world. This can occur because their time is otherwise subsidized and they may not care about accruing wealth as much as they do having time to follow their curiosity. Other inventors might be motivated by the public good. For example, Elon Musk shared his idea for the hyperloop without expectation of credit or compensation because he wanted the world to investigate it, but he didn’t want to investigate it with his own resources. Therefore, while some inventors will be motivated by compensation, much innovation will happen even in the absence of the incentives that come with ownership.
Of course, these are pragmatic arguments for ownership that frame it as a legal instrument for preserving an incentive for innovation for the public good. One could also argue that people deserve an inherent right to ownership of ideas. After all, crafting and polishing an idea can be incredibly difficult, and the emotional effort behind it might demand ownership.
Whatever your argument for ownership, one cannot construct a notion of idea ownership without clarity about what an idea is . As we discussed above, that is not clear, so ownership is not clear either.
Can ideas be owned?
Thus far, we have discussed interface ideas and ownership in the abstract. How do ideas and ownership actually work in the world? Here we’ll discuss U.S. law, as that is the country I’m most familiar with, and many countries model their laws on U.S. law.
U.S. law currently recognizes two forms of ownership relevant to interface technology. Copyright law aa Copyrights are often confused with trademarks. The key difference is that copyrights protect the work itself, whereas trademarks are a narrower category of marks or symbols that are used to distinguish between the goods or services of different organizations. Trademarks, at least in the U.S., are also not granted automatically. We do not discuss them here since they are purely about branding and not interface design. , for example, automatically recognizes any concrete expression of an idea as intellectual property, giving rights to the person or people who expressed the material. Source code used to implement an interface idea is therefore copyrighted automatically, as are all other forms of ideas, such as documents describing the idea. None of this protects the idea itself, unless you believe that the implementation of an idea is the idea. A copyright holder of any of these materials reserves the exclusive right to use that material. No one else, without the permission of the copyright holder, may use that material.
In addition to copyrights, U.S. law also explicitly grants limited ownership of ideas themselves in the form of patents . In contrast to copyright, which protects specific expressions of ideas, patents copyright the ideas themselves. Because this conveys a much broader scope of protections and control, getting a patent requires writing a description of what constitutes the essence of the idea; this description must come in the form of “claims” about how the idea works, and those claims must differ “substantially” from the claims of prior patents. Once granted, a patent holder can control who can and cannot “use” the idea in products, services, and other copyrighted material. This protection currently lasts for 20 years, after which the idea enters the public domain , and can be used by anyone.
In addition to demonstrating novelty beyond prior patents, what categories of ideas can be patented is constantly in flux because of ambiguous language in patent law. At the time of this writing, for example, algorithms are still technically patentable, but there is a clear trend in the decisions of the U.S. Supreme Court of eroding protections for algorithms. This ambiguity emerges from the inherent ambiguity of what constitutes an idea.
There are also many rules about when something can be patented: if it has been in the public domain for more than a year in the U.S., it is considered public domain, and cannot be patented. Inventors in the U.S. are often encouraged to write provisional patents, which give a partial specification of an idea, giving the inventors a year to write the full patent, while also declaring to the world that they were the first to own the idea. If the provisional patent expires without a full patent application being submitted, then the idea enters the public domain. Otherwise, the application process proceeds (often for years), while the patent examiner’s office assesses the novelty relative to prior patents and other inventions.
Because copyrights and patents prevent use of ideas without the owner’s permission, U.S. law also has the notion of licenses , which allow owners to grant permission to others to use copyrighted or patented materials. For example, you don’t own the bits that represent the web browser that you’re reading this in: Microsoft, Google, Mozilla, or Apple still own that sequence of bits. They’ve just granted you a limited license to use those bits and they can take that right away at any time and for any reason.
Because most interface innovations occur in the context of organizations, it’s also important to understand how employment contracts interact with copyright and patent ownership. For example, as a condition of most for-profit employment, employees promise to transfer ownership of their copyrighted and patented materials to the organization they work for. That means any ideas you conceive of in a for-profit job are not your intellectual property, but the property of the company you work for. This can make it hard to protect ideas you believe are separate from your responsibilities at work. If you thought of something while at home reading work email, was it your idea or the company’s idea? Employment contracts vary. Most for-profit enterprises claim all intellectual property as theirs. Most universities allow academics to keep their property, but require the owners to transfer their “ right to license ” their intellectual property. Losing a right to license means that while inventors at universities still technically own the property, the university has all of the control in who uses the property, including the original inventor themselves. Because of the complexity of these decisions, most universities and large companies have resources to help with legal questions about intellectual property.
Can interface ideas be owned?
Our discussion thus far has been largely agnostic of interface ideas. Because copyright and patent law varies in its applicability for different media, where does U.S. law currently stand on ownership of interface ideas?
The first major legal precedent on interfaces ideas was set by Apple Computer, Inc. v. Microsoft Corp , filed in 1988, a few years after the release of Apple’s Mac OS. Apple had agreed to license parts of its GUI to Microsoft for Windows 1.0, but when Microsoft released Windows 2.0 with many of the interface features found in Mac OS, Apple decided to file a copyright infringement suit against Microsoft and Hewlett-Packard to prevent them from using the interface ideas. Their dispute was that ideas like buttons, scroll bars, text boxes, the rectangular look of windows, their resizability, their title bars, and their ability to overlap, were copyrighted material, and therefore Apple had the exclusive right to decide who could use those ideas. Apple also claimed that the entire “look and feel” taken as a whole was copyrighted material.
At the time, legal analysis of this case found the arguments weak. For example, in a prominent series of editorials, Pamela Samuelson pointed out that there really was no legal definition of “look and feel”, and so trying to claim that it was protected by copyright law would require defining it 3 . Samuelson noted that the phrase itself was invented by two lawyers named Jack Russo and Doug Derwin, who wrote an article in 1985 for a computer law magazine about aspects of software user interfaces that the authors thought might be protectable by copyright. Because there was no legal definition, and because the case did not try to define it, the legal arguments in the case never clarified what specifically was being stolen. Samuelson also noted that copyright law was a strange choice for the lawsuit, because most of look and feel would appear to be related to patent law, which protects the processes, systems, and procedures one might describe to define look and feel. She argued for several additional reasons to reject Apple’s claims:
- If look and feel is copyrighted, Apple’s claims to look and feel were not original, since Xerox PARC invented them (and they based them on other ideas from academia).
- Legal precedent suggested that layouts of content in graphic design were not copyrightable.
- Interfaces have functionality, and so patent law must be invoked, since U.S. law requires that if something is patentable, it is ineligible for copyright protection.
- There is a long history of protecting the products of human factors engineering ideas by patent law, but no history of protecting it through copyright.
In a CHI 1990 paper, Samuelson and a colleague reported the results of a 1989 survey of user interface designers about their opinions about the case and found several consistent beliefs 4 :
- Designers strongly believed that the look and feel of user interfaces should not be given protection by copyright or patent law.
- Many believed the phrase “look and feel” was too vague to become part of legal precedent.
- Many expressed concern that there was not yet a way to actually judge whether “look and feel” was comparable between two interfaces.
- Many pointed out that the actual functionality of software is part of the look and feel of an interface, and that they did not believe this functionality should be protected or owned.
These findings were particularly damning for the merits of copyright and patent law for interface designs, as these interface designers are the very people whom the copyright and patent laws were designed to protect.
The court followed a similar line of reasoning as Samuelson and the HCI community. The court insisted on an analysis of the GUI elements, with Apple listing 189 ideas for review. The court decided that 179 of those ideas had already been licensed to Microsoft in the Windows 1.0 agreement and that the other 10 were not copyrightable, either because Xerox PARC had invented them, or they were the only way of expressing an idea. The court defined a standard of “virtual identity” between Windows and the Macintosh in order to prove infringement, and Apple could not demonstrate it.
In her review of the rulings, Samuelson argued that while there may be something valuable about look and feel, copyright law was not the right way to protect it, particularly because the artistic and functional aspects could not be separated 5,6 . After all, copyright law tends to protect “look,” patent law tends to protect “feel,” and so unifying them as a single concept of look and feel is in conflict with two mutually exclusive forms of ownership.
Interestingly, after this suit, Apple and Microsoft resolved their conflict outside of court. Apple agreed to make Internet Explorer their default browser; Microsoft agreed to continue developing Office for Mac. Microsoft bought $150 million of non-voting Apple stock. They even decided to agree to a patent cross-licensing agreement in which certain innovations would be shared between the two companies. Both mutually agreed that rather than spending hundreds of millions of dollars on lawyers, they would spend hundreds of millions of dollars on partnership.
What is the effect of interface idea ownership on innovation?
While there have been many interface lawsuits since, few have had the scope and scale of Apple v Microsoft case. That was until 2016, when Apple sued Samsung for infringing upon three design patents that covered the black rounded-rectangle face of the iPhone and the grid of icons found in the iOS home screen. This time, using patent law, Apple succeeded in court, and a judge ordered Samsung to pay $399 million in lost profits due to infringement. These damages, however, and their scale, led to entirely different problem: what effect would Samsung paying these damages have on the industry and its ability to innovate?
Several companies, including Facebook, eBay, and Google, warned that actually forcing Samsung to pay these damages would lead to a flood of litigation between technology companies, since the companies had so liberally borrowed from each other in their designs. Their core argument was that complex, “multi-component” devices like smartphones and tablets simply cannot be litigated through the narrow and granular lens of patents. Samuelson, again providing commentary on this landmark case on patent law, summarized the legal arguments, and raised concerns about the cost of an industry-wide endless patent war, draining companies of innovation, and exhausting courts 1,2 . In May of 2018, a jury awarded Apple $539 million in damages. Rather than pursue an appeal, Samsung settled with Apple outside of court in June of 2018, but the terms of that settlement were not revealed.
This history of lawsuits and settlements might make one wonder how technology companies are able to so freely copy key features in other company’s products. For example, the original Macintosh user interface was directly inspired by work at Xerox PARC, and Windows was directly inspired by Mac OS. And hundreds of interface ideas on smartphones are regularly copied between Android, iOS, and other competiting platforms. These companies all have patents on a range of these ideas. And so the only thing stopping them from copying is a threat of lawsuit. But how likely is that threat when they might just countersue, leading to billions of dollars in legal fees and settlements? In essence, patent wars have cost large technology companies a lot of money and provided little benefit to them. And the smallest companies trying to defend their IP with patents and copyrights simply don’t have the resources to defend their IP in court.
Do these epic battles between tech giants around copyrights and patents on interface ideas actually incentivize innovation? Do they make you want to innovate? Do they make you want to help a company innovate? Ultimately, since copyright and patent law are ultimately designed to help inventors recover their investments and motivate them to reinvest them, the answers to these questions should probably shape the future of intellectual property law.
What does all of this intellectual property law mean for you? That depends on how much you care about compensation and credit for your ideas. If you don’t care at all about ownership, your approach to design can be quite pure, generating ideas, describing them, sharing liberally, furthering your vision of user interfaces independent of market concerns. But few of us have this luxury. Academics, who often have an obligation to disclose their inventions to universities so that universities can monetize them, and who may collaborate with students or people in industry who do care about credit and ownership, must often engage with intellectual property law to navigate how to care. And people in industry, whether they care about ownership or not, are contractually obligated to care about ownership by their employers. The only people free to share without concern for ownership are independent innovators with no organizational requirements to protect IP. This includes students in universities, who do not usually sign employment agreements that require them to give up licensing rights, but when students interact with faculty around ideas, this can still arise.
Since you probably have to care to some extent, here are the key things to know:
- When you begin a collaboration , be sure to have an explicit conversation about intellectual property. What kind of credit or compensation do you want? What kinds of intellectual property obligations are you each subject to? If your goals and constraints around ownership are in tension, find a way to resolve them before proceeding with the collaboration. This includes deciding how much each of you owns about an idea, which is a decision necessary for patenting an idea. (This can be disruptive to collaboration, and so many organizations create standard agreements to resolve these tensions. At the University of Washington, reach out to CoMotion , which has several experts on IP law and UW IP policy).
- Before you share an idea publicly , decide what you want to achieve through that sharing. Releasing an idea publicly will start a 1-year clock on patentability. Releasing copyrighted material to the public won’t give up your rights, but it will allow people to reuse it, and it’s up to you to file a copyright lawsuit if you want to stop someone from using it. If you’re sharing an idea that you conceived of while working at a company, recognize that you’re disclosing your company’s IP, and not yours, and that such disclosure could have implications for your current and future employment.
- After you share an idea , recognize that the only thing stopping someone from using it is a lawsuit or a threat of a lawsuit. Those are expensive and not always worth the time. The organization you work for might subsidize this enforcement, but they will likely do that in a way aligned with its interests, not yours.
- If you want to monetize a copyright or patent , recognize that companies don’t always see value in licensing IP. It may be cheaper for them to copy your IP and risk a lawsuit, or simply learn about your idea and invent their own slightly different idea that doesn’t infringe upon your rights, or your organization’s rights. In fact, in some cases, copyrights and patents can interfere with realizing your ideas. For example, because copyrights and patents are weak protection, and protecting them come with costs, venture capitalists who invest in ideas are much more interested in trade secrets, since they are not public.
If you think all of this IP law is a huge hassle and counterproductive to innovation, explore ways you might advocate for change in IP law. You can sign petitions, support new laws, and advocate for lobbying positions as part of the organization for which you work. If you take the opposite stance, find ways to strengthen intellectual property law in a way you protects you and others. My personal stance is IP law is ultimately an impediment to innovation. It starts from the premise that people can “own” ideas, which I think is a false premise. Ideas are always a combination of other ideas, so I feel that drawing ownership boundaries around them is false and counterproductive. Regardless of what you or I think, these laws do affect your work on user interface software technologies and so you should closely monitor changes in intellectual property law and legal precedent.
References
-
Pamela Samuelson (2016). Apple v. Samsung and the upcoming design patent wars?. Communications of the ACM.
-
Pamela Samuelson (2017). Supreme Court on design patent damages in Samsung v. Apple. Communications of the ACM.
-
P. Samuelson (1989). Why the look and feel of software user interfaces should not be protected by copyright law. Communications of the ACM.
-
Pamela Samuelson and Robert F. J. Glushko (1990). What the user interface field thinks of the software copyright "look and feel" lawsuits (and what the law ought to do about it). SIGCHI Bulletin.
-
Pamela Samuelson (1992). Updating the copyright look and feel lawsuits. Communications of the ACM.
-
Pamela Samuelson (1993). The ups and downs of look and feel. Communications of the ACM.

Translation
I love doing research on interfaces. There’s nothing like imagining an entirely new way of interacting with a computer, creating it, and then showing it to the world. But if the inventions that researchers like myself create never impact the interfaces we all use every day, what’s the point? The answer, of course, is more complex than just a binary notion of an invention’s impact.
First, much of what you’ve read about in this book has already impacted other researchers. This type of academic impact is critical: it shapes what other inventors think is possible, provides them with new ideas to pursue, and can sometimes catalyze entirely new genres. Think back, for example, to Vannevar Bush’s Memex . No one actually made a Memex as described, nor did they need to; instead, other inventors selected some of their favorite ideas from his vision, combined them with other ideas, and manifested them in entirely unexpected ways. The result was more than just more research ideas, but eventually products and entire networks of computers that have begun to reshape society.
How then, do research ideas indirectly lead to impact? Based on both the experience of HCI researchers and practitioners attempting to translate research into practice 2 and historical records of interface innovation, there are three essential milestones that must occur (at least in a capitalist economy), for innovations to diffuse throughout society: 4
- Researchers must demonstrate feasibility . Until we know that something works, that it works well, and that it works consistently, it just doesn’t matter how exciting the idea is. It took Xerox PARC years to make the GUI feel like something that could be a viable product. Had it not seemed (and actually been) feasible, its unlikely Steve Jobs would have taken the risk to have Apple’s talented team create the Macintosh.
- Someone must take an entrepreneurial risk . It doesn’t matter how confident researchers are about the feasibility and value of an interface idea. At some point, someone in an organization is going to have to see some opportunity in bringing that interface to the world at scale, and no amount of research will be able to predict what will happen at scale. These risk-taking organizations might be startups, established companies, government entities, non-profits, open source communities, or any other form of community that wants to make something.
- The interface must win in the marketplace . Even if an organization perfectly executes an interface at scale, and is fully committed to seeing it in the world, it only lives on if the timing is right for people to want it relative to other interfaces. Consider Google’s many poorly timed innnovations at scale: Google Glass , Google Wave , Google Buzz , Google Video ; all of these were compelling new interface innovations that had been demonstrated feasible, but none of them found a market relative to existing media and devices. And so they didn’t survive.
Let’s consider four examples of interface technologies where these three things either did or didn’t happen, and that determined whether the idea made it to market.

Feasibility
The first example we’ll consider is what’s typically known as strong AI . This is the idea of a machine that exhibits behavior that is at least, if not more skillful than human behavior. This is the kind of AI portrayed in many science fiction movies, usually where the AI either takes over humanity (e.g., The Terminator ), or plays a significant interpersonal role in human society (e.g., Rosie the robot maid in the Jetsons ). These kinds of robots, in a sense, are an interface: we portray interacting with them, giving them commands, and utilizing their output. The problem of course, is that strong AI isn’t (yet) feasible. No researchers have demonstrated any form of strong AI. All AI to date has been weak AI , capable of functioning in only narrow ways after significant human effort to gather data to train the AI. Because strong AI is not feasible in the lab, there aren’t likely to be any entrepreneurs willing to take the risk of bringing something to market at scale.
Strong AI, and other technologies with unresolved feasibility issues (e.g., seamless VR or AR, brain-computer interfaces), all have one fatal flaw: they pose immense uncertainty to any organization interested in bringing them to market. Some technology companies try anyway (e.g,. Meta investing billions in VR), but ultimately this risk mitigation plays out in academia, where researchers are incentived to take high risks and suffer few consequences if those risks do not translate into products. In fact, many “failures” to demonstrate produce knowledge that eventually ends up making other ideas feasiible. For example, the Apple Newton , inspired by ideas in research and science fiction, was one of the first commercially available handheld computers. It failed at market, but demonstrated the viability of making handheld computers, inspiring the Palm Pilot, Tablet PCs, and eventually smartphones. These histories of product evolution demonstrate the long-term cascade from research feasibility, industry research and development feasibility, early product feasibility, to maturity.

Risk
Obviously inveasible ideas like strong AI are of course fairly obviously not suitable for market: something that simply doesn’t clearly isn’t going to be a viable product. But what about something that is feasible based on research? Consider, for example, some brain-computer interfaces have a reasonable body of evidence behind them . We know that, for example, it’s feasible to detect muscular activity with non-invasive sensors and that we can classify a large range of behaviors based on this. The key point that many researchers overlook is that evidence of feasibility is necessary but insufficient to motivate a business risk.
To bring brain-computer interfaces to market, one needs a plan for who will pay for that technology and why. Will it be a popular game or gaming platform that causes people to buy? A context where hands-free, voice-free input is essential and valuable? Or perhaps someone will bet on creating a platform on which millions of application designers might experiment, searching for that killer app? Whatever happens, it will be a market opportunity that pulls research innovations from the archives of digital libraries and researcher’s heads into the product plans of an organization.
And risk changes as the world changes. For example, some of the current uncertainties of brain-computer interfaces stem from limitations of sensors. As biomedical advances improve sensor quality in healthcare applications, it may be that just barely feasible ideas proven in research suddenly become much more feasibile, and therefore lower risk, opening up new business opportunities to bring BCIs to market.

Acceptability
Of course, just because someone sees an opportunity doesn’t mean that there actually is one, or that it will still exist by the time a product is released. Consider, for example, Google Glass , which was based on decades of augmented reality HCI research, led by Georgia Tech researcher Thad Starner . Starner eventually joined Google, where he was put in charge of designing and deploying Google Glass. The vision was real, the product was real, and some people bought them in 2013 (for $1,500). However, the release was more of a beta in terms of functionality. And people weren’t ready to constantly say “OK, Glass” every time they wanted it to do something. And the public was definitely not ready for people wandering around with a recording device on their face. The nickname “Glasshole” was coined to describe early adopters, and suddenly, the cost of wearing the device wasn’t just financial, but social. Google left the market in 2015, largely because there wasn’t a market to sell to.
Of course, this changes. Prior to the COVID-19 pandemic, investing in video chat software and augmented reality might have seemed like a narrow enterprise business oppoprtunity. After the pandemic, however, there are likely permanent shifts in how not just business, but families and communities, will stay synchronously connected online. The market for creative, versatile video chat, and even AR and VR, expanded within weeks, rapidly increasing the acceptability of staying at home to visit with distant friends, or having a meeting with a headset strapped on.

Adoption
Some interface ideas become feasible and acceptable enough to be viable products. For example, after decades of speech recognition and speech synthesis research, DARPA, the U.S. Department of Defense’s Advanced Research Projects Agency, decided to invest in applied research to explore a vision of personal digital assistants. It funded one big project called CALO (“Cognitive Assistant that Learns and Organizes”), engaging researchers across universities and research labs in the United States in creating a range of digital assistants. The project led to many spinoff companies, including one called Siri, Inc., which was founded by three researchers at SRI, International, a research lab in Silicon Valley that was charged with being the lead integrator of the CALO project. The Siri company took many of the ideas that the CALO project demonstrated as feasible (speech recognition, high quality speech synthesis, mapping speech to commands), and attempted to build a service out them. After a few rounds of venture capital in 2007, and a few years of product development, Apple acquired Siri, kept its name, and integrated it into the iPhone. In this case, there was no market for standalone digital voice assistants, but Apple saw how Siri could give them a competitive advantage in the existing smartphone market: Google, Microsoft, and Amazon quickly followed by creating their own digital voice assistants in order to compete. Once digital voice assistants were widely adopted, this created other opportunities: Amazon, for example, saw the potential for a standalone device and created the smart speaker device category.
Once interface technologies reach mass adoption, problems of feasibilty, risk, and acceptability no longer factor into design decisions. Instead, concerns are more about market competition, feature differentiation, the services behind an interface, branding, and user experience. By this point, many of the concerns we have discussed throughout this book become part of the everyday detailed design work of designing seamless interface experiences, as opposed to questions about the viability of an idea.
Barriers to innovation
What are the implications of these stories for someone in innovating industry? The criteria are pretty clear, even if the strategies for success aren’t. First, if an interface idea hasn’t been rigorously tested in research, building a product (or even a company) out of the idea is very risky. That puts a product team or company in the position of essentially doing research, and as we know, research doesn’t always work out. Some companies (e.g., Waymo), decide to take on these high risks, but they often do so with the high expectation of failure. Few companies have the capital to do that, and so the responsibility for high-risk innovations falls to governments, academia, and the few industry research labs at big companies willing to invest big risks.
Even when an idea is great and we know it works, there’s a really critical phase in which someone has to learn about the idea, see an opportunity, and take a leap to invest in it. Who’s job is it to ensure that entrepreneurs and companies learn about research ideas? Should researchers be obligated to market their ideas to companies? If so, how should researchers get their attention? Should product designers be obligated to visit academic conferences, read academic journals, or read books like this? Why should they, when the return on investment is so low? In other disciplines such as medicine, there are people who practice what’s called translational medicine , in which researchers take basic medical discoveries and try to find product opportunities for them. These roles are often funded by governments, which view their role as investing in things markets cannot risk doing. Perhaps computing should have the same roles and government investment.
Finally, and perhaps most importantly, even when there are real opportunities for improving products through new interface ideas, the timing in the world has to be right. People may view the benefit of learning a new interface as too low relative to the cost of learning. There may be other products that have better marketing. Or, customers might be “locked in,” and face too many barriers to switch. These market factors have nothing to do with the intrinsic merits of an idea, but rather the particular structure of a marketplace at a particular time in history.
The result of these three factors is that the gap between research and practice is quite wide. We shouldn’t be surprised that innovations from academia can take decades to make it to market, if ever. If you’re reading this book, consider your personal role in mining research for innovations and bringing them to products. Are you in a position to take a risk on bringing a research innovation to the world? If not, who is?
Taking this leap is no small ask. When I went on leave to co-found AnswerDash in 2012 with my student Parmit Chilana and her co-advisor Jacob Wobbrock , it was a big decision with broad impacts not only on my professional life, but my personal life. We wrote about our experiences learning to sell and market a product 1 , identifying all of the gaps between our research and what it took to create a successful product. Later, just after I returned to UW, I reflected on the numerous challenges I personally faced growing a research idea into a successful product 3 . While these personal stories are far from representative of what it takes to bring interface ideas to market, they do illustrate a common challenge: turning any idea into a reality is a long, challenging, risky process, but a riveting and often rewarding one. Before defaulting to a large established stable company, ask yourself: what might you only learn at a startup that you couldn’t learn in an established business?
There are many ways to close these gaps. We need more contexts for learning about innovations from academia, which freely shares its ideas, but not in a way that industry often notices. We need more students excited to be translate, interpret, and appropriate ideas from research into industry. We need more literacy around entrepreneurship, so that people feel capable of taking bigger risks. And we need a society that enables people to take risks, by providing firmer promises about basic needs such as food, shelter, and health care. Without these, interface innovation will be limited to the narrow few who have the knowledge, the opportunity, and the resources to pursue a risky vision.
References
-
Chilana, P. K., Ko, A. J., & Wobbrock, J. (2015). From user-centered to adoption-centered design: a case study of an HCI research innovation becoming a product. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Colusso, L., Jones, R., Munson, S. A., & Hsieh, G. (2019). A translational science model for HCI. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Amy J. Ko (2017). A three-year participant observation of software startup software evolution. IEEE International Conference on Software Engineering, Software Engineering in Practice Track.
-
Kalle Lyytinen, Jan Damsgaard (2001). What's wrong with the diffusion of innovation theory?. Working conference on diffusing software product and process innovations.

Interface Ethics
The ethics of computing have never been more visible. CEOs of major tech companies are being invited to testify in front of governments about their use of data. Driverless cars are raising questions about whether machines should be deciding who does and doesn’t die . Judges are beginning to adopt machine learning to predict recidivism , rather than using their own judgement. Writers are beginning to ponder not only the ethics of computing and design, but their role in moral decisions 5 and social justice. 2
These and other applications of computing provoke numerous profound questions about design ethics.
- Who should we design for?
- How do we include the voices of all stakeholders in design?
- What responsibility do interaction designers have to create a sustainable, human future?
There are many methods that try to answer these questions, ranging from inclusive design 1 , universal design 9 , participatory design 8 , value-sensitive design 6 , and design justice . 2 And there are many practitioners grappling with how to use these methods. Many are wondering whether these methods are enough to resolve the deep questions about the role of computing in society.
But this book isn’t about interaction design broadly, it’s about interfaces, and the software and technology that make them possible. What specific role do interface technologies have in design ethics? And what role do interaction designers have in designing and leveraging interface technologies ethically? In this chapter, I argue that there are at least four ways that interfaces technologies are at the heart of interaction design ethics.
Interface technologies can erase diversity
One of the central roles of user interface software and technology is to standardize interaction. User interface toolkits lower the barrier to creating consistent interaction paradigms. User interface hardware, such as the sensor packages in phones, define what computers are capable of sensing. User interface conventions, built into software and hardware, regularize user experience, making new interfaces that follow convention easier to learn. These kinds of standardization aim for desirable ends of usability, learnability, and user efficiency.
Standardization is not ethically wrong in its own right. However, if not done carefully, the ubiquity of interface standards and conventions can exacerbate inequities in design choices. For example, the dominance of screen-based interaction with computers is fundamentally unjust toward people without sight or sufficient visual acuity to use screens. That standard is not a mere inconvenience to a population, but a blunt exclusion of people with disabilities from our computational worlds, because it embeds visual interaction as primary, rather than one of many channels of output. A screen reader, after all, is not a primary form of interaction, it is a technology that tries and only sometimes succeeds in making an inherently visual organization of information something accessible to people without sight. The defaults and templates built into user interface developer tools, intended to streamline the prototyping of conventional interfaces, build in subtle assumptions about left-to-right languages. This default makes it easier to create interfaces that function well for western languages, and harder to create interfaces for eastern languages. As with screens, these defaults are a categorical exclusion of cultures around the world, framing top-to-bottom, right-to-left languages as exceptional and secondary. Interface conventions and standards can also embed cultural assumptions in them. For example, taking a photograph is a social affront in some cultures, but we place multiple camera sensors with prominence in our phones. Interface standardization is, in a way, colonialist, embedding the language, ability, and cultural assumptions of one culture (primarily Silicon Valley) onto another. 7
One can question whether the colonialist mechanisms of interface standardization are unethical. But that is a debate that is more about the ethics of colonialism than interfaces. Do you believe it is the right of designers in Cupertino and Mountain View to embed their culture into interfaces reaching global ubiquity? And if not, are you willing to champion diversity in culture and ability at the expense of the learnability and interoperability that standards enable?
As a designer, what will you decide?
Interface technologies reconfigure human experience
When I was a child, I had no computer, no smartphone, and no internet. When I was bored, I had a few simple options for how to entertain myself: read a (print) book, walk to a friend’s house, sing a song, or play with toys with my brother. The nature of that experience was one of simplicity. When I didn’t want to do any of those things, I would often choose to just sit and observe the world. I watched squirrels chase each other. I pondered the movement of the clouds. I listened to the rain’s rhythms upon my roof. I looked to nature for stimulation, and it returned riches.
As I aged, and computing became embedded in my life, my choices changed. Interfaces were abundant. The computer in the den offered puzzles and games. My Super Nintendo offered social play with friends. My modem connected me to the nascent internet and its rapidly expanding content. My palette of entertainment expanded, but in some ways narrowed: interacting with computers, or with friends through computers, was much more visceral, immediate, and engaging. It promised instant gratification, unlike nature, which often made me wait and watch. It could not compete with the bright lights of the screen, and the immediacy of a key press. My world shifted from interacting with people and nature, to interacting with computers.
How much artificial is too much? Is there a right way to be a human? Is there a natural way to be a human? Does human-computer integration go too far? 4 Or is integration an inevitable embrace of our susceptibility to tight cycles of stimulus and response? Do we design for a world that centers human-computer interaction, or carefully situates it alongside the much broader and richer collection of other human experiences?
As a designer, what will you decide?
Interface technologies amplify social choices
There is emerging agreement that computing does not cause social change, but amplifies it, in whatever way that change intends. 10 For example, social media has not caused political division, but it has amplified division that was already there. The Ring doorbell, pictured at the beginning of this chapter, has not caused ubiquitous surveillance, but it has amplified our ability to surveil our homes. Games have not caused social isolation, but they have amplified isolation, giving depressed adolescents a short term yet isolating salve for unwanted seclusion. In these ways, computing can be weaponized: they are tools that can amplify violence, far beyond what we can do with our hands, but they do not alone cause violence.
If we accept the premise that human beings are ultimately responsible for both desirable and undesirable social change, and that interface technology are just the tools by which we achieve it, what implications does that have for interface design? If interfaces amplify, then that also amplifies the consequences of our choices of precisely what we amplify. For example, if we work on simplifying the control of drones, we must accept that we are helping hobbyists more easily surveil our neighborhoods and governments more easily drop bombs. If we work on simplifying the spread of information, we must accept that we are also simplifying the spread of misinformation and disinformation. If we design new interfaces for recreating or altering the appearance of actors in movies, we must accept that we are also enabling troubling deep fakes .
An amplification perspective ultimately forces us to question the ethics of what our interfaces enable. It forces us to think rigorously about both intended and unintended uses of our interfaces. It forces us to imagine not only the best case scenarios of use, but also the worst case scenarios. It forces us to take some responsibility as accomplices for the actions of others. But how much?
As a designer, what will you decide?
Interface technologies produce waste
Before graphical user interfaces, there weren’t that many computers. Large companies had some mainframes that they stored away in large rooms. Hobbyists built their own computers at a negligible scale. The computer hardware they created and discarded had negligible impact on waste and sustainability. Some computers, like the solar powered calculator I had in elementary school, were powered by sustainable energy.
All of this changed with the graphical user interface. Suddenly, the ease with which one could operate a computer to create and share information, led to ubiquity. This ease of sharing information has led to a massive global demand for data, is leading data consumption to account for 20% of global CO2 emissions , much of it in data centers controlled by just a few companies. Rather than using solar-powered calculators, many use Google search to compute 2 + 2, which Google estimated in 2009 emitted 0.2 grams of CO02.
But it’s not just carbon that interfaces emit. The promise of ever simpler and more useful interfaces leads to rapid upgrade cycles, leading e-waste to account for at least 44 million tons of waste. This makes computer hardware, and the interface accessories embedded in and attached to that hardware, the fastest growing source of garbage on the planet. Inside these millions of tons of garbage lie an increasing proportion of the world’s rare earth metals such as gold, platinum, cobalt, and copper, as well as numerous toxins.
Would we have reached this level of CO2 output and waste without an immense effort to make interfaces learnable, efficient, useful, and desirable? Likely not. In this sense, innovations interface software and technology is responsible for creating the demand, and therefore responsible for the pollution and waste.
Some companies are beginning to take responsibility for this. Apple started a recycling program to help reclaim rare earth metals and prevent toxins from entering our water. Amazon pledged to shift to sustainable energy sources for its warehouses and deliveries. Microsoft pledged to be not only carbon neutral, but carbon negative by 2035.
Are these efforts enough to offset the demand these companies generate for software, hardware, and data? Or, perhaps consumers are responsible for their purchasing decisions. Or, perhaps designers, who are the ones envisioning unsustainable, wasteful products and services are responsible for changing these companies? 3
As a designer, what will you decide?
How do you decide? The easiest way is, of course, to delegate. You can hope your manager, your VP, or your CEO has greater power, insight, and courage than you. Alternatively, you can advocate, demanding change from within as many have done at major technology companies. If you organize well, make your message clear, and use your power in numbers, you can change what organizations do. And if delegation and advocacy do not work, perhaps it is possible to innovate interfaces that are more inclusive, humane, sustainable, and just. And if that is not possible, ultimately, you can choose a different employer. Use the ample opportunity of the ever growing marketplace for interfaces to choose enterprises that care about justice, humanity, morality, and sustainability.
To make these choices, you will need to clarify your values. You will need to build confidence in your skills. You will need to find security. You may need to start your own company. And along the way, you will need to make decision decisions that intersect with all of the ethical challenges above. As you do, remember that the world is more diverse than you think, that communities know what they need more than you do, and that interfaces, as compelling as they are in harnessing the power computing, may not be the solution to the greatest problems facing humanity. In some cases, they may be the problem. Hold that critical skepticism and commitment to justice alongside a deep curiosity about the potential of interfaces and you’ll likely make the right choice.
References
-
Clarkson, P. J., Coleman, R., Keates, S., & Lebbon, C. (2013). Inclusive design: Design for the whole population. Springer Science & Business Media.
-
Sasha Costanza-Chock (2020). Design justice: Community-led practices to build the worlds we need. MIT Press.
-
Paul Dourish (2010). HCI and environmental sustainability: the politics of design and the design of politics. In Proceedings of the 8th ACM conference on designing interactive systems.
-
Umer Farooq, Jonathan Grudin (2016). Human-computer integration. ACM interactions.
-
Batya Friedman, David Hendry (2019). Value sensitive design: Shaping technology with moral imagination. MIT Press.
-
Batya Friedman (1996). Value-sensitive design. ACM interactions.
-
Irani, L., Vertesi, J., Dourish, P., Philip, K., & Grinter, R. E. (2010). Postcolonial computing: a lens on design and development. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Schuler, D., & Namioka, A. (2017). Participatory design: Principles and practices. CRC Press.
-
Molly Follette Story (1998). Maximizing Usability: The Principles of Universal Design. Assistive Technology, 10:1, 4-12.
-
Toyama, K. (2011). Technology as amplifier in international development. iConference.