
The power of information
My great grandfather was a saddle maker and farmer in Horslunde, on the poor island of Lolland, Denmark. In the 1850’s, his life was likely defined by silence. He quietly worked on saddles in a shed, working with his hands to shape and mold cowhide. He tended to his family’s one horse. Most of his social encounters were with his wife, children, and perhaps the small community church of a few dozen people each Sunday. I’m sure there was drama, and gossip, and some politics, but those likely happened on the scale of weeks and months, as communication traveled slowly, by mouth and paper. His children—my grandfather and his siblings—likely played in the quiet grassy flat fields in the summer, far from anyone. Life was busy and physically demanding, but it was quiet.
My life, in contrast, is noisy. As a professor, my research connects me with people across North and South America, all of Europe, and much of Asia and Australasia. I receive hundreds of emails each day, I see thousands of tweets, I might have a dozen friends and family message me on a dozen different platforms, causing my smart watch to gently vibrate every few minutes. My news aggregator pushes hundreds of stories to me, Facebook and LinkedIn share hundreds of updates from friends, family, and colleagues. The moment I’m bored, I have limitless games, television, movies, podcasts, magazines, comics, and books to choose from. I might spend just as much time using search engines and reading reviews to help decide what information to consume as I do actually consuming it. If my Danish grandparent’s lives were defined by quiet focus, mine is defined by clamorous distraction.
Despite these dramatic differences in the density and role of information in our two lives, information was very much present in both of them. My grandfather’s information was about livestock, weather, and the grain and quality of leather; my information is about knowledge, ideas, and politics. In either of our lives, has information been any more or less important or necessary? My grandfather needed it to sell saddles and I need it to educate and discover. I may have access to more of it, but it’s not obvious that this is better—just different.

What these two stories show is that information was, is, and always will be necessary to human thriving. In fact, some describe humanity as informavores , dependent on finding patterns, predictions, and order in an increasingly entropic, chaotic world 4 . Our species, more than any other, relies on information to find food, keep warm, and stay healthy. And as a social species, we rely on information from each other to do these things more effectively than we could alone. And while technology has changed the volume, pace, and sources of information in our daily lives, it has not changed its essential power to shape our knowledge and our behavior in the world.
Of course, some information is less necessary and powerful than other information. Much of the internet has little value; in fact, content on the web is increasingly generated by algorithms, which read and recombine existing writing to produce things that appear novel, but in essence are not. Most of the media produced does not change lives, but serves merely to resolve boredom. Our vibrant cities are noisier than ever, but most of that noise has no meaning or value to us. And the news, while more accessible than ever, is increasingly clickbait, with little meaningful journalistic or investigative content.
If it’s not the abundance of information that makes it powerful, what is it?
What is powerful about information?
The power of information comes from how it is situated in powerful contexts. Consider, for example, the SARS-CoV-2 Pfizer vaccine, which is one of many vaccines that will help build and sustain global immunity to the dangerous virus. This is a powerful, innovative vaccine that is fundamentally information: it encodes how to construct the “spike” of SARS-CoV-2 found on the surface of the coronavirus that causes COVID-19. When that information, stored as messenger RNA, is injected into our bodies, our cells read those mRNA instructions, assemble the spike protein, and our immune systems, rich databases of safe and dangerous proteins, detect the spike as a new foreign body, and add it to their database of substances to attack. The next time our immune systems see that spike, they are ready to act and destroy the virus before it replicates and causes COVID-19 symptoms. Information, therefore, keeps us healthy .
There is also power behind the origins of that DNA sequence. In February and March 2020, an international community of American and Chinese researchers worked together to model, describe, and share the structure of the SARS-CoV-2 spike. Their research depended on computers, on DNA sequencers, on the internet for distribution of knowledge, and on the free movement of information across national boundaries in academia. All of these information systems, and the centuries of research on vaccines, DNA, and computing, were necessary for making the vaccine possible in record time. The power of the vaccine, then, isn’t just about an mRNA sequence, but an entire history of discovery, innovation, and institutions that use information to understand nature. Information, therefore, fuels discovery .

Stories of the power of information abound in history 2 . For example, in 1202, Fibonacci, otherwise, known as Leonardo of Pisa, released a book called Liber Abaci, which described and taught the Hindu-Arabic number system that had long been used in the middle east and southeast Asia to compute. It replaced the clumsy, inefficient Roman numeral system, brought the number zero to western civilization, and transformed mathematics, commerce, science, and engineering. Information therefore teaches us.

Prior to 1592, there was no standard calendar in western civilization, and so it was hard to discuss time. The declaration of Pope Gregory XIII defined months, weeks, years, and days for Europe—and due to the rampant colonialism that followed—for most of the world 5 . It became the basis of time zones, international trade, and is now deeply encoded in computers, through application programming interfaces that facilitate time and date arithmetic. Information, therefore, organizes us.

As European colonialism waned and modern democracies emerged, information was a central force in shaping new systems of government. For example, the Declaration of Independence, released on July 4th, 1776, can be thought of simply as a one page letter to the Kingdom of Great Britain, declaring the British colonies as sovereign states. But it was far more than a letter: it led to the Revolutionary War, the decline of power in Great Britain, and the writing of the U.S. Constitution 1 . The Constitution, and its amendments, have led to great advances in freedom in the United States and beyond, while simultaneously encoding great injustices and inequities in human rights. Information, for better or worse, regulates us.

Some of these injustices in the United States led to information that changed the course of civil rights. For example, Martin Luther King, Jr’s 1963 speech, I have a dream , conveyed a vision of the United States without racism 7 . It pressured the U.S. Congress to advance civil rights legislation, and create a generation of activists to fight for racial justice, trying to overcome the racist beliefs and laws that had been at the foundation of U.S. history and its constitution. Information, therefore, inspires us.

Throughout this history of human and civil rights, a central challenge has been defining identity. Who is American? How does one prove they were born here? Documents like birth certificates, filled out and signed at the time and place of birth, become powerful media for laying claim to the rights of citizenship. Nowhere was this more apparent than in President Trump’s baseless conspiracy theories of President Obama’s citizenship 6 ; even the release of President Obama’s long form certificate did not quell skepticism. Information, therefore, identifies us.

In our 21st century, identity is just one part of the much larger way that we use information to communicate. When we express our views on social media, they are connected to our identities, and shape how people see us and interpret our motives and intents. For example, consider this moment in 2017, when long-time U.S. Senator John McCain stood in front of his senate colleagues, who awaited his up or down vote on whether to repeal the Affordable Care Act. His thumbs down, a simple non-verbal information signal, shocked the senate floor, reinforced his “maverick” reputation, and preserved the health care of millions of people. Information, therefore, binds us.

The illusory power of technology
Information, of course, is woven through all of our interactions with people and nature, and so it does much more than just the things above. It helps us diagnose and explain problems, it archives what humanity has discovered, it entertains us, it connects us, and it gives us meaning.
But the power of information, therefore, derives more from its meaning, its context, and how it is interpreted and used, and less from how it is transmitted. Moreover, it’s not information itself that is powerful, but the potential for action that information can create that is powerful: after all, having information does not necessarily mean understanding it, and understanding it does not necessarily mean acting upon it. It is easy to forget this, especially in our modern world, where information technology like Google, the internet, and smartphones clamor for our attention, and seem to be responsible for so much in society. It’s easy to confuse information technology for the cause of this power. Consider, for example, Google search, an inescapable fixture in how the modern world finds information. What is Google search without content? Merely an algorithm that finds and organizes nothing. Or, think about using your smartphone without an internet connection or without anyone to talk to. Of what value is its microprocessor, its memory, and its applications if there is no content to consume and no people to connect with? Information technology is, ultimately, just a vessel for information to be stored, retrieved, and presented—there is nothing intrinsically valuable about it. And information itself has a similar limit to its power: without people to understand and act upon it, it is inert.
This perspective challenges Marshall McLuhan’s famous phrase, “the medium is the message” 3 , which argued that the particular way that we transmit information—at the time, radio and television relative to newspapers—might be a transformative factor in what we make of information. As we shall see in the rest of this book, this is only partly true: how we find information, and how it is organized and presented, does matter, but it is not the only thing that matters, and it may matter less than the cultures, practices, values, and norms that shape what we do with it.
In the rest of this book, we will try to define information, demarcating its origins, explaining its impacts, deconstructing our efforts to create and share it, and problematizing our use of technology to store, retrieve, and present it. Throughout, we shall see that while information is powerful in its capacity to shape action, and information technology can make it even more powerful, information can also be perilous to capture and share without doing great harm and injustice.
Podcasts
The podcasts below all reveal the power of information in different ways.
- The Other Extinguishers (Act 2), Boulder v. Hill, This American Life. Shows how a long, collaborative history of science led to the DNA sequencing of the SARS-CoV-2 “spike” in just 10 minutes ( transcript )
- Electoral College Documents, 2020 , Documents that Changed the World. Discusses how the U.S. electoral college system actually determine transfer of power in United States elections.
- Statistical Significance, 1925 , Documents that Changed the World. Discusses the messy process by which scientific certainty is established.
References
-
Max Edling (2003). A Revolution in Favor of Government: Origin of the U.S. Constitution and the Making of the American State. OUP USA.
-
Joseph Janes (2017). Documents That Changed the Way We Live. Rowman & Littlefield.
-
Marshall McLuhan (1964). Understanding Media: The Extensions of Man. Routledge, London.
-
George A. Miller (1983). Informavores. The Study of Information: Interdisciplinary Messages.
-
Gordon Moyer (1982). The Gregorian Calendar. Scientific American.
-
Vincent N. Pham (2015). Our foreign president Barack Obama: The racial logics of birther discourses. Journal of International and Intercultural Communication.
-
Eric J. Sundquist (2009). King's Dream. Yale University Press.

The peril of information
When I was in high school, I was a relatively good student. All but one of my grades were A’s, I was deeply curious about mathematics and computer science, and I couldn’t wait to go to college to learn more. My divorced parents weren’t particularly wealthy, and so I worked many part-time jobs to save up for college applications and AP exam fees, bagging groceries, babysitting, and tutoring. It didn’t leave much time for extracurriculars. I was sure that colleges would understand my circumstances and see my promise. But when the decisions came back, I’d only been admitted to two places: my public state university, and the University of Washington, but the latter only offered a $500 loan, and I had no college savings. My dreams were shattered because the committee ignored the context of the information I gave them: that I had no time to stand out in any other way beyond grades because I was busy working, supporting my family.
Familiar stories like this show that not all information is good information or used in good ways. In fact, as powerful as information is, there is nothing about power that is inherently good either. In fact, power can be perilous. The admissions committees at my dream universities had great power to shape my fate through their decisions, and the information they asked me to share didn’t allow me to tell my whole story. And my lack of guidance from school counselors, teachers, and parents meant that I didn’t know what information to give to increase my chances. The committee’s decisions, while quite a powerful form of information, were therefore in no way neutral. In fact, behind their decisions were a particular set of values and notions of merit that shaped the information they requested, the information they provided, and the decision they sent me in thin envelopes in the mail.
With power comes peril

What is power? Within the context of society, powerpower: The capacity to influence and control others. is capacity to influence the emotions, behavior, and opportunities of other people. Power and information are intimately related in that information is itself a form of influence. When you listen to someone speak or read someone’s writing, the information they convey can shape our thoughts and ideas. When you take up physical space and give non-verbal cues of a reluctance to move, you are signaling information about what physical threats you might impose. When you share some information on social media, you are helping an idea find its way into other people’s minds. All of these forms of communication are therefore forms of power.
But power is not just communication. Power also resides in our knowledge and beliefs, shaped by information we received long ago. As children, for example, many of us learn ideas of racism, sexism, ableism, transphobia, xenophobia, and other forms of discrimination, fear, or social hierarchy. These ideas, beliefs, and assumptions form systems of power, in which those high in social hierarchies can influence who has rights, resources, and opportunity. Sociologist Patricia Collins called these forms of power, and their many interactions, the matrix of dominationmatrix of domination: The system of culture, norms, and laws designed to maintain particular social hierarchies of power. 1 , for how these many forms of social power interact across law, culture, disciplines, and interpersonal interactions. Information is at the heart of this matrix, as people with power use information to build and reinforce this matrix, preserving their influence over others’ behavior. Information, therefore, is far from neutral. Like any technology, it sits atop society, expressing particular values, requiring us to examine information for more than its content, but also its creator, their motivations, and their values.
D’Ignazio and Klein, in their book Data Feminism 2 , link the matrix of domination to data and information. In their book, they observe that what is done with data depends on who has power and what they use it for; that changing how power uses data requires challenging not just data itself, but how power is being used; that our tendency to classify, sort, and organize people using data can reinforce the matrix of domination; and that harm from data often comes not from intent, but simply lack of context about its meaning and origins. Data, and thus, information, is rife with peril without careful, mindful, and just use.
Consequences of information
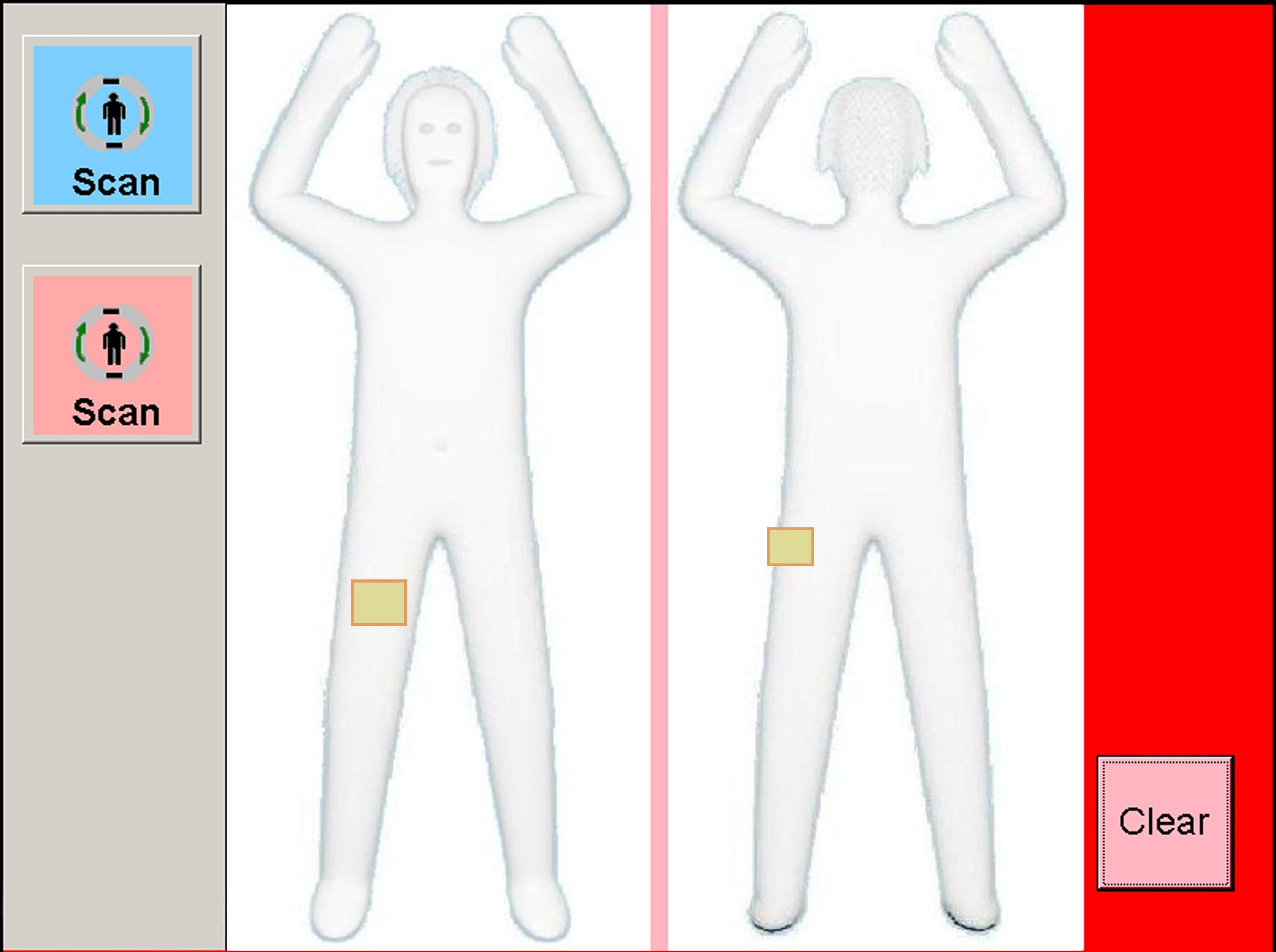
Let’s consider some of the many ways that information and its underlying values can be perilous. One seemingly innocuous problem with information is that it can misrepresent . For example, when I go to an airport in the United States, I often have to be scanned by a TSA body scanner. This scanner creates a three dimensional model of the surface of my body using x-ray backscatter. The TSA agent then selects male or female, and the algorithm inside the scanner compares the model of my body to a machine learned model of “normal” male and female bodies, based on a data set of undisclosed origin. If it finds discrepancies between the model of my body and its model of “normal,” I am flagged as anomalous, and then subjected to a public body search by an agent. For most people, the only time this will happen is if there is something that looks like a gun to the scanner. But many transgender people such as myself, as well as other people whose bodies do not conform to stereotypically gendered shapes such as those with disabilities, are frequently flagged and searched. This discrimination, in which “normal” bodies are protected by security, and “anomalous” bodies are invasively searched and sometimes humiliated, derives from how the TSA scanners and the TSA agents misrepresent the actual diversity of human bodies. They misrepresent this diversity because of the matrix of domination that excludes gender non-conforming and disabled people from consideration in design.
Information can also be false or misleading, misinforming its recipient. This was perhaps no more apparent during President Trump’s 2016-2020 term, in which he wrote countless tweets that were demonstrably false about many subjects, including COVID-19. For example, on October 5th, 2020, just after being released from the hospital a few days after testing positive for the virus, he tweeted:
I will be leaving the great Walter Reed Medical Center today at 6:30 P.M. Feeling really good! Don’t be afraid of Covid. Don’t let it dominate your life. We have developed, under the Trump Administration, some really great drugs & knowledge. I feel better than I did 20 years ago!
Whether or not the President was intentionally giving bad advice, or this was simply fueled by his steroid injection, its impact was clear, as the tweet was shortly followed by the Autumn 2020 wave of infections in the United States, fueled by conspiracy theories framing the virus as a hoax, and pressure on state and local officials to avoid stricter public health rules. Hundreds of thousands of people died in the U.S., likely due partly to the President’s persistent spreading of misleading information about the virus and many years of similar misinformation about vaccines, spread by parents who did not understand or believe the science of immunology.
Information can also disinform . Unlike misinformation, which is independent of intent, disinformation is information that people know to be false, and spread in order to influence behavior in particular ways. For example, many states in the United States require doctors who are administering abortions to lie to patients about the effects of abortion; the intent of these laws is framed as informed consent, but many legislators have admitted that their actual purpose is to disincentivize people from following through on abortions. Similarly, QAnon conspiracies , have created even larger collective delusions that lead to entirely alternate false realities. Disinformation, then, is a form of power and influence through deception.
Some information may be true, but may be created to manipulate , by misrepresenting its purpose. For example, in the video above, technologist Jaron Lanier discusses how social media platforms like Facebook and Instagram (also owned by Facebook) are fundamentally about selling ads. Facebook is not presented this way—in fact, it is rather innocuously presented as a way to stay connected with friends and family—but its true purpose is to ensure that when an advertisement is shown in a social media feed that we attend to it and possibly click on it, which makes Facebook money. Similarly, a “like” button is presented as a social signal of support or affirmation, but its primary purpose is to help generate a detailed model of our individual interests, so that ads may be better targeted towards us. Independent of whether you think this is a fair trade, it is fundamentally manipulation, as Facebook misrepresents the motives of its features and services.

Information can also overload 4 . In a context where there are too many options—too many search results, too many products, too many tweets, too many emails—it is possible for too much information to lead to people being less happy with their choices or making no choice at all. These effects are not consistent—sometimes information overload occurs and strongly influences decision outcomes, and other times it actually helps. This research suggests that the whether information about choices is good depends on what the information is and what the decision is.

Sometimes, information can be addictive 3 . Some of the most obvious examples are things like games and stories, which are often explicitly designed to entice us to play the next level or read the next chapter. When we practice self-regulation, moderating our consumption of information, such media can be a source of joy, connection, and entertainment . But when left unmoderated, they may pose addiction risks, especially to youth, where there is a strong association between smartphone addiction, stress, and reduced academic performance 3 . But games and stories are the most obvious sources of information addiction; less obvious ones are notifications on smartphones, which may also be addictive.

Some recent research has even shown that ease of accessing information can lead to isolation 5 . Because the internet has essentially infinite information, and connecting with people in superficial ways through social media is so much easier than connecting in deeper ways, there appears to be evidence that youth are less likely to have intimate relationships, less robust interpersonal communication skills, and more isolation. This same pattern can also contribute to bullying, as the ease of superficial communication makes it easier for peers to communicate with and bully victims with minimal visibility of parents, teachers, or even peers. Of course, information addiction in smartphones alone are likely not the sole explanation behind mental health challenges; they may just be one of many factors. (Moreover, for some youth, they may be protective factors, preventing isolation).

Information can also kill . Consider, for example, the case of the Uber autonomous driving sensor system . In March of 2018, it was driving down a highway with a human driver monitoring it. Elaine Herzberg, a pedestrian, was crossing the road with her bike at 10 p.m. The driver was not impaired, but also was not monitoring the system. The system noticed an obstacle, but could not classify it; then, it classified it as a vehicle; then as a bicycle. And finally, 1.3 seconds before impact, the system determined that an emergency braking maneuver was required to avoid a collision. However, this mode was disabled during automated driving mode, and the driver was not notified, so the car struck and killed Elaine. This critical bit of information—danger!—was never sent to the driver, and since the driver was not paying attention, someone died. Beyond automation, errors in information can kill in any safety-critical context, including flight, health care, and social safety nets that provide food, shelter, and security.
These, of course, are not the only potential problems with information. The world has an ongoing struggle with the tensions of free speech, censorship, and the many ways we have discussed above that information can do harm. With the ability of the internet to archive much of our past, there are also many open questions about what rights we have to erase information stored on other people’s computers that might tie us to a past life, a past action, or a past name or identity. These and the numerous many other questions, reinforce that information has values, and those values are intrinsically tied to the ways that we exercise control over each other.
Podcasts
The podcasts below all reveal the peril of information in different ways.
- Family Stories, Family Lies , Code Switch. Shares one story of how the origins of a family name are far more complicated than one can ever imagine, capturing a multi-generation history of love and oppression.
- A Conspiracy Theory Proved Wrong, The Daily, The New York Times . Discusses the history of the QAnon conspiracy and its aftermath after its predictions did not come true.
- No Silver Bullets, On the Media, WNCY Studios . Discusses how information and propaganda has led to far-right extremism, and how information is also used to deradicalize.
- Facebook’s CTO on Misinformation, In Machines We Trust . Facebook’s CTO describes Facebook’s struggling efforts to detect misinformation and prevent harm.
- Undercover and Over-Exposed, On the Media . Discusses the risks of freely sharing information with journalists.
References
-
Patricia Collins (1990). Black feminist thought: Knowledge, consciousness, and the politics of empowerment. Routeledge.
-
Catherine D'Ignazio, Lauren F. Klein (2020). Data Feminism. MIT Press.
-
Samaha, M., & Hawi, N. S. (2016). Relationships among smartphone addiction, stress, academic performance, and satisfaction with life. Computers in Human Behavior.
-
Benjamin Scheibehenne, Rainer Greifender, Peter M. Todd (2010). Can There Ever Be Too Many Options? A Meta‐Analytic Review of Choice Overload. Journal of Consumer Research.
-
Sherry Turkle (2011). Alone together: Why we expect more from technology and less from ourselves. MIT Press.

Data, information, knowledge
When I was a child in the 1980’s, there was no internet, there were no mobile devices, and computers were only just beginning to reach the wealthiest of homes. My experience with information was therefore decidedly analog. I remember my three primary sources of information fondly. First, a few times a month, my mother would take my brother and I to our local public library, and we would browse, find a pile of books that captured our attention, and then simply sit, in silence, and read together for hours. Eventually, we would get hungry, and we would check out a dozen books, and then devour them at home together for the next few weeks, repeating the cycle again. My second source was the newspaper. Every morning, my father would leave early in the morning to get a donut and coffee, and go to the local newspaper rack on the street to buy a copy of The Oregonian for a nickel, a dime, or a quarter. Sometimes I would join him and get a donut myself, and then we would come home, eating donuts together while he read the news and I read the comics. My third source was magazines. In particular, I subscribed to 3-2-1 Contact , a science, technology, and math education magazine that accompanied the 1980 broadcast television show. The monthly magazine came with fiction, non-fiction, math puzzles, and even reader submissions of computer programs written in the BASIC programming language—type them in and see what happens! I would run out to our mailbox every morning near the beginning of the month to see if the latest issue had come. And when it did, it consumed the next week of my free time.
Of course, this analog world was quickly replaced with digital. Forty years later, the embodied joy of reading books, news, and magazines with my family, and the wonderful anticipation that came with having to wait for information, was replaced with speed. I still read books, but I click a button to get them on my tablet instantaneously. I still read the news, but I scroll through a personalized news feed at breakfast, with little sense of shared experience with family. And I still read magazines, but on a tiny smartphone screen, whenever I want, which is rarely. Instead, I fall mindlessly into the infinite YouTube rabbit hole, with no real sense of continuity, anticipation, or wonder. Computer science imagined a world in which we could get whatever information we want, whenever we want, and then realized it over the past forty years. And while the words I can find in these new media are the same kind as those forty years ago, somehow, the experience of this information just isn’t the same.
This change in media begs an important question: what is information? We can certainly name many things that seem to contain it: news, books, and magazines, like above, but also movies, speeches, music, data, talking, writing, and perhaps even non-verbal things like sign language, dancing, facial expressions, and posture. Or are these just containers for information and the information itself is things like words, images, symbols, and bits? And what about things in nature, like DNA? Information seems to be everywhere—in nature, in our brains, in our language, and in our technology—but can something that seems to be in everything be a useful idea?

What is information?
This is a question that Michael Buckland grappled with in 1991 2 . In his article, he notes the long struggle to define what information is, discovering many competing ideas.
- One idea was as information as a process , in which a person becomes informed and their knowledge changes. This would suggest that information is not some object in the world, but rather some event that occurs in the world, in the interaction between things. The challenge with this notion of information is that process is situational and contextual: the door in my office, to me, might not be informational at all, it might just play the role of keeping heat inside. But to someone else, the door being closed might be informational, signaling my availability. From a process perspective, the door itself is not information, but particular people in particular situations may glean different information from the door and its relation to other social context about its meaning. If information is process, then anything can be information, and that doesn’t really help us define what information is.
- Another idea that Buckland explored was information as knowledge . This notion of information makes it intangible, as knowledge, belief, opinion, and ideas are personal, subjective, and stored in the mind. The only way to access them is for that knowledge to be communicated in some way, through speech, writing, or other signal. For example, I know what it feels like to be bored, but communicating that feeling requires some kind of translation of that feeling into some media (e.g., me posting on Twitter, “I’m bored.”).
- The last idea that Buckland explored was information as thing . Here, the idea was that information is different from knowledge and process in that it is tangible, observable, and physical. It can be stored and retrieved. The implication of this view is that we can only interact with information through things, and so information might as well just be the things themselves: the books, the magazines, the websites, the spreadsheet, and so on.
Buckland was not the only one to examine what information might be. Another notable perspective came from Gregory Bateson in his work Form, Substance, and Difference 1 , in which he wrote in reference to physical energy:
What we mean by information - the elementary unit of information - is a difference which makes a difference, and it is able to make a difference because the neural pathways along which it travels and is continuously transformed are themselves provided with energy... But what is a difference? A difference is a very peculiar and obscure concept. It is certainly not a thing or an event. This piece of paper is different from the wood of this lectern. There are many differences between them-of color, texture, shape, etc. But if we start to ask about the localization of those differences, we get into trouble. Obviously the difference between the paper and the wood is not in the paper; it is obviously not in the wood; it is obviously not in the space between them, and it is obviously not in the time between them.
Bateson’s somewhat obtuse thought experiment is a slightly different idea than Buckland’s process , knowledge , and thing notions of information: it imagines the world as full of noticeable differences , and that those differences are not in the things themselves, but in their relationships to each other. For example, in DNA, it is not the cytosine, guanine, adenine, or thymine themselves that encode proteins, but the ability of cells to distinguish between them. Or, to return to the earlier example of my office door, it is not the door itself that conveys information, but the the fact that the door maybe open, closed, slightly ajar—those differences, and knowledge of them, are what allow for the door to convey information. Whether the “difference” encoded in the sequence of letters is conveyed by in a print magazine or a digital one, the differences are conveyed nonetheless, suggesting that information is less about medium than it is the ability of a “perceiver” to notice differences in that medium.
In 1948, well before Buckland and Bateson were theorizing about information conceptually, Claude Shannon was trying to understand information from an engineering perspective. Working in signal processing at Bell Labs, he was trying to find ways of transmitting telephone calls more reliably. In his seminal work, 8 he linked information to the concept of entropy from thermodynamics. Entropy is a measurable physical property of a state of disorder, randomness, or uncertainty. For example, if you tossed a coins four times and every toss came up heads this situation would have low entropy, conceptually, as there’s not any disorder in the results. In contrast, if the tosses came up half heads and half tails this would have high entropy, with no apparent pattern and maximum disorder. Shannon’s view of information was thus as an amount of information, measured by the disorder of the results.
Another way to think about Shannon’s entropic idea of information is through probability: in the first example there’s only one way toss four heads so the probability is low. In contrast, in the second sequence, you have a high probability of getting half heads and half tails and could get those flips in many different ways: two heads then two tails, or one head followed by two tails followed by one head, and so on. The implication of these ideas is that the more rare “events” or “observations” in some phenomenon, the more information there is.
A third way to think about Shannon’s idea was that the the amount of information in anything is inversely related to is compressability . For example, is there a shorter way to say “1111111111”? We might say “ten 1’s”. But is there a shorter way to say “1856296289”? As a prime number, no. Shannon took this notion of compressibility to the extreme, observed that a fundamental unit of difference might be called a bit : either something is or isn’t, 1 or 0, true or false. He postulated that all information might be encoded as bit sequences and that the more compressible a bit sequence was, the less information content it has. This idea, of course, went on to shape not only telecommunications, but mathematics, statistics, computing, and biology, and enabled the modern digital world we have today.

Data, Information, and Knowledge
The nuance, variety, and inconsistency of all of these ideas bothered some scholars, who struggled to reconcile these definitions. Charles Meadow and Weijing Yuan tried to create some order on these concepts in their 1997 paper, Measuring the impact of information: defining the concepts 5 . Building upon dozens of prior attempts to define information and related concepts, including those described above, they proposed the following:
- Datadata: Analog or digital symbols that someone might perceive in the world and ascribe meaning. are a set of “symbols”, broadly construed to include any form of perceptible difference in the world. In this definition, the individual symbols have potential for meaning, but that they may or may not be meaningful or parsable to a recipient. For example, the binary sequence 00000001 is indeed a set of symbols, but you as the reader do not know if they encode the decimal number 1, or some message about cats, encoded by youth inventing their own secret code. A hand gesture with five fingers stretched out in a plane might mean someone is stretching their fingers or a non-verbal signal meant to get someone’s attention. In the same way, this entire chapter is data, in that it is a sequence of symbols that likely has much meaning to those fluent in English, but very little meaning to those not. Data, as envisioned by Shannon, is an abstract message, which may or may not have informational content.
- Informationinformation: The process of receiving, perceiving, and interpreting data into knowledge. , in Meadow and Yuan’s definition, is realization of the informational potential of data: it is the process of receiving, perceiving, and translating data into knowledge. The distinction from data, therefore, is a subtle one. Consider this bullet point, for example. The data is the sequence of Roman characters, stored on a web server, delivered to your computer, and rendered by your web browser. Thus far, all of this is data, being transmitted by a computer, and translated into different data representations. The process of you reading this English-encoded data, and comprehending the meaning of the words and sentences that it encodes, is information. Someone else might read it and experience different information.
- Knowledgeknowledge: An interconnected system of information in a mind. , in contrast to information, is what comes after the process of perceiving and interpreting data. It is the accumulation of information received by a particular entity. The authors do not get into whether that entity must be human—can cats have knowledge, or even single-cell organisms, or even non-living artifacts?—but this idea is enough to distinguish information from knowledge.
Some scholars have extended this framework to also include wisdom 7 , suggesting that wisdom is somehow constructed out of knowledge, and concerns at underlying questions of “why is” and “why do” 9 . Others have argued that this extension is unnecessary, as those are just other forms of knowledge. With or without wisdom, most scholars have settled on these three concepts broadly, with continued debate about their nuances.
One challenge with all of these conception of data, information, and knowledge, is the broader field of epistemologyepistemology: The study of how we know we know things. , which is a branch of philosophy concerned with how we know that know things. For example, one epistemological position called logical positivism is that we know things through logic, such as formal reasoning or mathematical proofs. Another stance called positivism , otherwise broadly known as empiricism, and widely used in the sciences, argues that we know things through a combination of observation and logic. Postpositivism takes the same position as positivism, but argues that there is inherent subjectivity and bias in sensory experience and reasoning, and only by recognizing our biases can we maintain objectivity. Interpretivism largely abandons claims of objectivity, arguing that all knowledge involves human subjectivity, and instead frames knowledge as subjective meaning. These and the many other perspectives on what knowledge is complicate simple classifications of data, information, and knowledge, because they question what it means to even know something.

Emotion and Context
These many works that attempt to define information largely stem from mathematical, statistical, and organizational traditions, and have sought formal, abstract definitions amenable for science, technology, and engineering. However, other perspectives on information challenge these ideas, or at least complicate simplistic notions of “messages”, “recipients”, and “encoding”. For example, consider the work of behavioral economists 4 , which has found that people do not simply receive and interpret information and translate it into knowledge. Instead, emotions interact with and mediate our interpretation of data, influencing the information we receive, strongly shaping our knowledge, and therefore decisions. This suggests that information, far from being an objective process of receiving and interpreting data, is partly a subjective emotional process, shaped by the many emotional and cognitive biases that humans find hard to overcome.
An example of such bias is confirmation bias 6 , which is the tendency for people to look for, interpret, and remember information in a way that supports their prior beliefs and their values. This bias is often unconscious, and leads people to ignore or discount information that might change their beliefs, and interpret ambiguous information in ways that supports their beliefs. Especially for matters that are emotionally charged, confirmation bias can be amplified in social media, where it is not simply the person curating what information they attend to and how they interpret it, but also algorithms. If information is indeed a process of interpreting data through an emotional lens, then it is an inherently biased one.
A second aspect of information often overlooked by mathematical, symbolic definitions of information is contextcontext: Social, situational information that shapes the meaning of information being received. . This idea of context is implied in Bateson’s notion of difference, Buckland’s notion of information being a thing in a context, and implicit in Meadow and Yuan’s formulation in the recipient’s perception of information. But in all of these definitions, and in the work on the role of emotions in decisions, context appears to play a powerful role in shaping what information means, perhaps even more powerful than whatever data is encoded, or what emotions are at play in interpreting data. For example, in 1945, novelist and cultural critical Michael Ventura, said:
Without context, a piece of information is just a dot. It floats in your brain with a lot of other dots and doesn’t mean a damn thing. Knowledge is information-in-context … connecting the dots.
To illustrate his point, consider, for example, this sequence of statements, which reveals progressively more context about the information presented in the first statement.
- I have been to war.
- In that war, I have killed many people.
- Sometimes, killing in that war brought me joy and laughter.
- The war was a game called Call of Duty Black Ops: Cold War .
- The game was designed by Treyarch and Raven Software.
- I play it with my friends.
The first statement is still true in a way, but each of the other pieces of information fundamentally changed your perception of the meaning of the prior statements. Even simple examples like this demonstrate that while we may be able to objectively encode messages with symbols, and transmit them reliably, these mathematical notions of information fail to account for the meaning of information, and how it can change in the presence of our emotions and other information that arrives later. Defining information simply as data perceived and understood is therefore overly reductive, hiding the complexity of human perception, cognition, identity, and culture.
It also hides the complexity of context. Consider, for example, the many kinds of context that can shape the meaning of information:
- How was the information created? What process was followed? Was it verified by someone credible? Is it true? These questions fundamentally shape the meaning of information, and yet are rarely visible in information itself (with the exception of academic research, which has a practice of thoroughly describing the methods by which information was produced), and journalism, which often follows ethical standards for acquiring information, and sometimes reveals sources.
- When was the information created? A news story that was released 5 years ago does not have the same meaning that it does now; our knowledge of the future that occurred after it was published changes how we see its events, and how we interpret their meaning. And yet, we often do not pay attention to when news was reported, when a Wikipedia page was written, when a scientific study was published, or when someone wrote a tweet. Information is created in a temporal context that shapes its meaning.
- For whom was the information created? Messages have intended recipients and audiences, with whom an author has shared knowledge. This chapter was written for students learning about information; tweets are written for followers; love letters are meant for lovers; cyberbullying text messages are meant for victims. Without knowing for whom the message was created, it is not possible to know the full meaning of information, because one cannot know the shared knowledge of the two parties.
- Who created the information? The identity of the person creating the information shapes its meaning as well. For example, when I write “Being transgender can be hard.”, it matters that I am a transgender person saying it. It conveys a certain credibility through lived experience, while also establishing some authority. It also shapes how the message is interpreted, because it conveys personal experience. But if a cisgender person says it, their position in relation to transgender people shapes its meaning: are they an ally expressing solidarity, a mental health expert stating an objective fact, or an uninformed bystander with no particular knowledge of trans people?
- Why was the information created? The intent behind information can shape its meaning as well. Consider, for example, when someone posts some form of hate speech on social media. Did they post it to get attention? To convey an opinion? To connect with like-minded people? To cause harm? As a joke? These different motives shape how others might interpret the message. That this context is often missing from social media posts is why short messages so often lead to confusion, misinterpretation, and outrage.
These many forms of context, and the many others not listed here, show that while some aspects of information may be able to be represented with data, the social, emotional, cultural, and political context of how that data is received can shape information as well. Therefore, as D’Ignazio and Klein argued in Data Feminism , “the numbers don’t speak for themselves” 3 : no information is neutral; all information reflects the social processes that created them, including their values, beliefs, and biases. Context is how we identify those values, beliefs, and biases.
Returning to my experiences as a child, the diverse notions of information above reveal a few things. First, while the data contained in the books, news, and magazines of my youth might not be different kind from that in my adulthood, the information is different. The social context in which I experience it changes what I take from it, my motivation to seek it has changed, and my ability to understand how it was created, by whom, for what, and when has been transformed by computing. Thus, while the “data” behind information has changed little over time, information itself has changed considerably as media, and the contexts in which we create and consume it, have changed in form and function. And if we are to believe the formulations above that relate information to knowledge, then the knowledge I gain from books, news, and magazines has almost certainly changed too. What implications this has on our individual and collective worlds is something we have yet to fully understand.
Podcasts
Want to learn more about the importance of context in information? Consider these podcasts:
- Can AI Fix Your Credit?, In Machines We Trust, MIT Technology Review . Discusses credit reports and the context they miss that leads to inequities in access to loans such as credit cards, car purchases, and homes.
- How Radio Makes Female Voices Sound Shrill, On the Media . Discusses how voice information is not simply data, but a complex set of hardware decisions about how voice is translated into data.
References
-
Gregory Bateson (1970). Form, substance and difference. Essential Readings in Biosemiotics.
-
Michael K. Buckland (1991). Information as thing. Journal of the American Society for information Science.
-
Catherine D'Ignazio, Lauren F. Klein (2020). Data Feminism. MIT Press.
-
Jennifer Lerner (2015). Emotion and decision making. Annual Review of Psychology.
-
Charles Meadow, Weijing Yuan (1997). Measuring the impact of information: defining the concepts. Information Processing & Management.
-
Raymond Nickerson (1998). Confirmation bias: A ubiquitous phenomenon in many guises. Review of General Psychology.
-
Jennifer Rowley (2007). The wisdom hierarchy: representations of the DIKW hierarchy. Journal of Information and Communication.
-
Claude E. Shannon (1948). A mathematical theory of communication. The Bell System Technical Journal.
-
Milan Zeleny (2005). Human Systems Management: Integrating Knowledge, Management and Systems. World Scientific.

Data, encoding, and metadata
Every ten years, the United States government completes a census of everyone that lives within its borders. This census, mandated by the U.S. Constitution, is a necessary part of determining many functions of government, including how seats in the U.S. House of Representatives are allocated to each state, based on population, as well as how federal support is allocated for safety net programs. Demographic information, such as age, gender, race, and disability, also informs federal funding of research and other social services. Therefore, this national survey is about distributing both power and resources.
When I filled out the census for the first time in the year 2000 at the age of 20, I wasn’t really fully aware of why I was filling out the survey, or how the data would be used. What struck me about it were these two questions:
- What is your sex? ☐ Male ☐ Female
- What is your race? ☐ White ☐ Black, African Am., or Negro, ☐ American Indian or Alaska Native, ☐ Asian Indian, ☐ Chinese, ☐ Filipino, ☐ Japanese, ☐ Korean, ☐ Vietnamese, ☐ Native Hawaiian, ☐ Guamanian or Chamorro, ☐ Samoan, ☐ Other Pacific Islander, ☐ Some other race
I struggled with both. At the time, I wasn’t definitely uncomfortable with thinking about myself as male, and it was too scary to think about myself as female. What I wanted to write in that in that first box was “Confused, get back to me.” Today, I would confidently choose female , or woman , or transgender , or even do you really need to know ? But the Census, with its authority to shape myriad policies and services based on gender for the next twenty years of my life, forced me into a binary.
The race question was challenging for a different reason. I was proudly biracial, with Chinese and Danish parents, and I was excited that for the first time in U.S. history, I would be able to select more than one race to faithfully represent my family’s ethic and cultural background. Chinese was an explicit option, so that was relatively easy (though my grandparents had long abandoned their ties to China, happily American citizens, with a grandfather who was a veteran, serving in World War I). But White ? Why was there only one category of White? I was Danish, not White. Once again, the Census, with its authority to use racial data to monitor compliance with equal protection laws and shape funding for schools and medical services, forced me into a category in which I did not fit.
These stories are problems of data, encoding, and metadata. In this chapter, we will discuss how these ideas relate, connecting them to the notions of information in the previous chapter, and complicating their increasingly dominant role in informing the public and public policy.

Data comes in many forms
As we discussed in the previous chapter, datadata: Analog or digital symbols that someone might perceive in the world and ascribe meaning. can be thought of as any form of symbols, analog or discrete , that someone might perceive in the world. Data, therefore, can come in many forms, including those that might enter through our analog senses of touch, sight, hearing, smell, taste, and even other less known senses, including pain, balance, and proprioception (the sense of where our bodies are in space relative to other objects). These human-perceptible, physical forms of data might therefore be in the form of physical force (touch), light (sight), sound waves (hearing), molecules (smell, taste), and the position of matter in relation to our bodies (balance, proprioception). It might be strange to imagine, but when we look out into the world to see the beauty of nature, when we smell and eat a tasty meal, and when we listen to our favorite songs, we are perceiving data in its many analog forms, which becomes information in our minds, and potentially knowledge.
But data can also come in forms that cannot be directly perceived. The most modern example is bitsbit: A binary value, often represented as either 1 or 0 or true or false. , as Claude Shannon described them 11 , building upon George Boole’s idea of truth values 5 , true , and false , or 1 , and 0 . Shannon and Boole imagined these as abstract ideas, but for bits to be data, they must be concretely embodied in some physical form. Early technologies for encoding bits included vacuum tubes, which passed an electric current between two electrodes to represent true , whereas no current represented false . These were soon replaced with the transistor 9 , which used high or low voltage to represent true and false , but in a much smaller package. The history of the transistor since has largely been to shrink them, to the point where we can now fit billions of transistors on a chip that’s just a few centimeters square. Whatever the form, the data storage capability is the same: either true , or false .
Of course, binary, bits, and transistors were not the first forms of discrete data. Deoxyribonucleic acid (DNA) came much earlier. A molecule composed of two polynucleotide chains that wrap around each other to form a helix shape, these chains are composed of sequences of one of four nucleobases, cytosine, guanine, adenine, and thymine. DNA, just like transistors, encodes data, but unlike a computer, which uses bits to make arithmetic calculations, life uses DNA to assemble proteins, which are the complex molecules that enable most of the functions in living organisms and viruses. And just like the transistors in a microprocessor and computer memory are housed inside the center of a computer, DNA is fragile, and therefore carefully protected, housed inside cells and the capsid shell walls of viruses. Of course, because DNA is data, we can translate it to bits 10 , and use them to advance any science concerned with life, from genomics and immunology to health and wellness.
Because computers are our most dominant and recent form of information technology, it is tempting to think of all data as bits. But this diversity of ways of storing data shows that binary is just the most recent form, and not even our most powerful: bits cannot heal our wounds the way that DNA can, nor can bits convey the wonderful aroma of fresh baked bread. This is because we do not know how to encode those things as bits.

Data requires encoding
The forms of data, while fascinating and diverse, are insufficient for giving data the potential to become information in our minds. Some data is just random noise with no meaning, such as the haphazard scrawls of a toddler trying to mimic written language, or the static of a radio receiving no signal. That is data, in the sense that it conveys some difference, entropy, or surprise, but it has little potential to convey information. To achieve this potential, data can be encodedencoding: Rules that define the structure and syntax of data, enabling unambiguous interpretation and reliable storage and transmission. , giving some structure and syntax to the entropy in data that allows it to be transmitted, parsed, and understood by a recipient. There are many kinds of encodings, some natural (such as DNA), some invented, some analog, some digital, but they all have one thing in common: they have rules that govern the meaning of data and how it must be structured.
To start, let’s consider spoken, written, or signed natural language, like English, Spanish, Chinese, or American Sign Language. All of these languages have syntax, including grammatical rules that suggest how words and sentences should and should not be structured to convey meaning. For example, English often uses the ending -ed to indicate an action occurred in the past ( waited , yawned , learned ). Most American Sign Language conversations follow Subject-Verb-Object order, as in CAT LICKED WALL . When we break these grammatical rules, the data we convey becomes harder to parse, and we risk our message being misunderstood. Sometimes those words and sentences are encoded into sound waves projected through our voices; sometimes they are encoded through written symbols like the alphabet or the tens of thousands of Chinese characters and sometimes they are encoded through gestures, as in sign languages that use the orientation, position, and motion of our hands, arms, faces, and other body parts. Language, therefore, is an encoding of thoughts into words and sentences that follow particular rules 2 .
While most communication with language throughout human history was embodied (using only our bodies to generate data), we eventually invented some analog encodings to leverage other media. For example, the telegraph was invented as a way of sending electrical signals over wire long distances between adjacent towns, much like a text messages 4 . Someone would bring a message to a telegraph operator, and then they would translate the message into a series of telegraph codes that encoded the message as periods of positive and negative voltage along a wire. On the other end, another telegraph operator would listen to a sonification of the voltage bursts, writing them down as a written pattern, then translate that pattern back into natural language. There were dozens of encodings one could use: the Chappe code, Edelcrantz code, Wig-wag, Cooke, and the more popular and standardized Morse code, all mirroring our other systems of symbolic communication, such as the Roman and Greek alphabets that inspire many western languages today.
This history of analog encodings directly informed the digital encodings that followed Shannon’s work on information theory. The immediate problem posed by the idea of using bits was how to encode the many kinds of data in human civilization into bits. Consider, for example, numbers. Many of us learn to work in base 10, learning basic arithmetic such as 1+1=2. But mathematicians have long known that there are an infinite number of bases for encoding numbers. Bits, or binary values, simply use base two. There, encoding the integers 1 to 10 in base two is simply:
| Binary | Decimal |
|---|---|
| 1 | 1 |
| 10 | 2 |
| 11 | 3 |
| 100 | 4 |
| 101 | 5 |
| 110 | 6 |
| 111 | 7 |
| 1000 | 8 |
| 1001 | 9 |
| 1010 | 10 |
That was simple enough. But in storing numbers, the early inventors of the computer quickly realized that there would be limits on storage 12 . If a computer had 8 transistors, each storing one bit, how many possible numbers could one store? The long way to find out is to simply keep counting in binary as above until one reaches 8 digits. The short way is to remember from mathematics that the number of possible permutations of a sequence of 8 binary choices can be computed as 2 to power 8, or 256. When you see references to 32-bit processors or 64-bit processes , this is what those numbers refer to: the number of bits used to store chunks of data, such as numbers.
Storing positive integers was easy enough. But what about negative numbers? Early solutions reserved the first bit in a sequence to indicate the sign, where 1 represented a negative number, and 0 a positive number. That would make the bit sequence 10001010 the number -10 in base 10. It turned out that this representation made it harder and slower for computers to do arithmetic on numbers, and so other encodings - which allow arithmetic to be computed the same way, whether numbers are positive or negative - are now used (predominantly the 2’s complement encoding ). However, reserving a bit to store a number’s sign also means that one can’t count as high: 1 bit for the sign means only 7 bits for the number, which means 2 to the power 7, or 128 possible positive or negative values, including zero.
Real numbers (or “decimal” numbers) posed an entirely different challenge. What happens when one wants to encode a large number, like 10 to the power 78, the latest estimate of the minimum number of atoms in the universe? For this, new encoding had to be invented, that would leverage the scientific notation in mathematics. The latest version of this encoding is IEEE 754 , which defines an encoding called floating-point numbers, which reserves some number of bits for the “significand” (the number before the exponent), and other bits for the exponent value. This encoding scheme is not perfect. For example, it is not possible to accurately represent all possible numbers with a fixed number of bits, nor is it possible to represent irrational numbers such as 1/7 accurately. This means that simple real number arithmetic like 0.1 + 0.2 doesn’t produce the expected 0.3 , but rather 0.30000000000000004 . This level of precision is good enough for applications that only need approximate values, but scientific applicants requiring more precision, such as experiments with particle accelerators which often need hundreds of digits of precision, have required entirely different encodings.
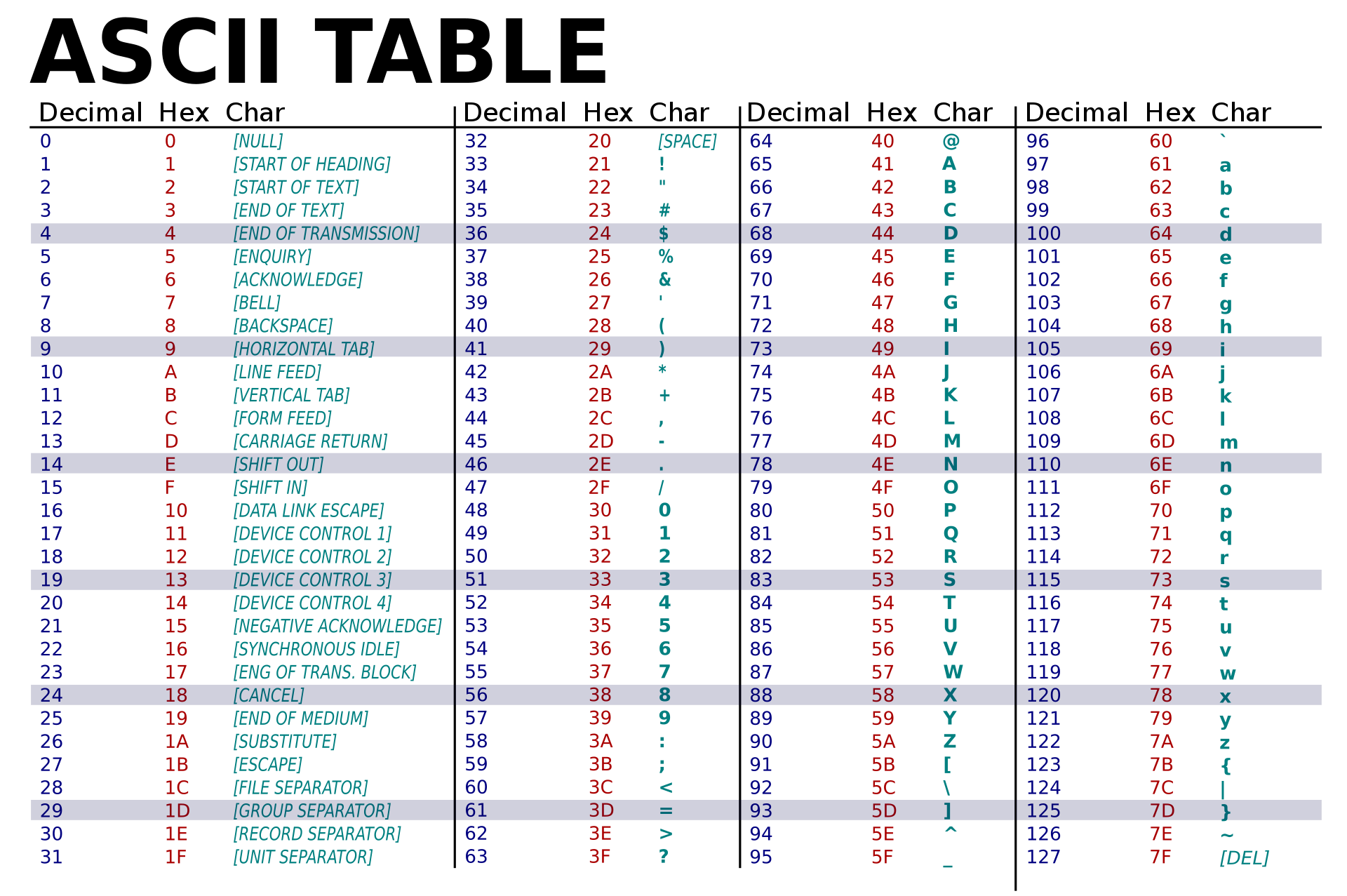
While numbers are important, so are other symbols. In fact, most of the Internet is text, and not numbers. So encoding text was an entirely different challenge. The basic idea that early inventors of computers devised was to encode each character in the alphabet as a specific number. This first encoding, called ASCII (which stood for American Standard Code for Information Interchange), used specific values in an 8-bit sequence to denote specific characters 8 : the decimal number 65 stood for A , 66 for B , 67 for C , and so on, with lower case letters starting at 97 for a . Therefore, to encode the word kitty , one would use the sequence of numbers 107 105 116 116 121 , or in unsigned binary, 01101011 01101001 01110100 01110100 01111001 . Five letters, five 8-bit numbers.
Of course, as is clear in the name for this encoding — American Standard — it was highly exclusionary: only western languages could be encoded, excluding all other languages in the world. For that, Unicode was invented, allowing the encoding of all of the world’s languages 7 . But it went beyond just established language, also including things like emoji, defining a community-based process by which individuals can propose new emoji for inclusion into the standard. Because everyone in the software industry has agreed on Unicode as the global encoding, and everyone agrees to accept revisions to the encoding, it has become the basis for all textual data exchanged through computers.
Numbers and text of course do not cover all of the kinds of data in the world. Images have their own analog and digital encodings (film photograph negatives, JPEG, PNG, HEIC, WebP), as do sounds (analog records, WAV, MP3, AAC, FLAC, WMA). And of course, software of all kinds defines encodings for all other imaginable kinds of data. Each of these, of course, are designed, and use these basic primitive data encodings as their foundation. For example, when the U.S. Census was designing the 2000 survey, the two questions I struggled with were stored as a data structure , with several fields, each with a data type:
| Data type | Description |
|---|---|
| boolean | true if checked male |
| boolean | true if checked White |
| boolean | true if checked Black |
| boolean | true if checked American Indian/Native Alaskan |
| boolean | true if checked Asian Indian |
| boolean | true if checked Chinese |
| boolean | true if checked Filipino |
| boolean | true if checked Japanese |
| boolean | true if checked Korean |
| boolean | true if checked Vietnamese |
| boolean | true if checked Hawaiian |
| boolean | true if checked Guamanian/Chamorro |
| boolean | true if checked Pacific Islander |
| text | encoding of handwritten text describing another race |
Each response to that survey was encoded using that data structure, encoding binary as one of two values, and encoding race is a yes or no value to one of twelve descriptors, plus an optional text value in which someone could write their own racial label. Data structures, like the one above, are defined by software designers and developers using programming languages; database designers create similar encodings by defining database schema , specifying the data and data types of data to be stored in a database .

Encoding is lossy
The power of encoding is that it allows us to communicate in common languages. Encoding in bits is even more powerful, because it is much easier to record, store, copy, transmit, analyze, and retrieve data with digital computers. But as should be clear from the history of encoding above, encodings are not particularly neutral. Natural languages are constantly evolving to reflect new cultures, values, and beliefs, and so the rules of spelling and grammar are constantly contested and changed. Digital encodings for text designed by Americans in the 1960’s excluded the rest of the world. Data structures like the one created for the 2000 U.S. Census excluded my gender and racial identity. Even the numerical encodings have bias, making it easier to represent integers centered around 0, and giving more precision to rational numbers than irrational numbers. These biases demonstrate that an inescapable fact of all analog and digital encodings of data: they are lossy, failing to perfectly, accurately, and faithfully represent the phenomenon they encode 1 . No matter how much additional precision we give to encodings, they will always be missing detail, emphasizing some details over others.
Nowhere is this more clear than when we compare analog to digital encodings of the same phenomena to the phenomena they attempt to encode as data:
- Analog music , such as that stored on records and tapes, is hard to record, copy, and share, but it captures a richness and fidelity. Digital music , in contrast, is easy to copy, share, and distribute, but is usually of lower quality. Both, however, cannot compare to the embodied experience of live performance, which is hard to capture, but far richer than recordings.
- Analog video , such as that stored on film, has superior depth of field but is hard to edit and expensive. Digital video , in contrast, is easier to copy and edit, but it is prone to compression errors that are far more disruptive than the blemishes of film. Both, however, cannot compare to the embodied experience of seeing and hearing the real world, even though that embodied experience is impossible to replicate.
Obviously, each encoding has tradeoffs; there is not best way to capture data of each kind, just different ways, reflecting different values and priorities.
Metadata captures context
One way to overcome the lossy nature of encoding is by also encoding the context of information. Context, as we described in the previous chapter, represents all of the details surrounding some information, such as who delivered it, how it was captured, when it was captured, and even why it was captured. As we noted, context is critical for capturing the meaning of information, and so encoding context is a critical part of capturing the meaning of data. When we encode the context of data as data, we call that metadatametadata: Data about data, capturing its meaning and context. , as it is data about data 13 .
To encode metadata, we can use the same basic ideas of encoding. But deciding what metadata to capture, just as with deciding how to encode data, is a value-driven design choice. Consider, for example metadata about images we have captured. The EXIF metadata standard captures context about images such as captions that may narrate and describe the image as text, geolocation data that specifies where on Earth it was taken, the name of the photographer who took the photo, copyright information about rights to reuse the photo, and the date the photo was taken. This metadata can help image data be better interpreted as information, by modeling the context it was taken. (We say “model”, because just as with data, metadata does not perfectly capture context: a caption may overlook important image contents, the name of the photographer may have changed, and the geolocation information may have been imprecise or altogether wrong).
But metadata is useful for more than just interpreting information. It is also useful for organizing it. For example, Netflix does more than encode television and movies as data for streaming. It also stores and even creates metadata about movies and television, such as who directed it, who produced it, who acted in it, what languages it can be heard in, whether it is captioned, and so on. This metadata facilitates searching and browsing, as we shall discuss in our later chapter on information seeking. But Netflix also creates metadata, synthetically generating tens of thousands of “micro-genres” to describe very precise categories of movies, such as Binge-Worthy Suspenseful TV dramas or Critically Acclaimed Irreverent TV Comedies . This metadata helped Netflix make browsing both more granular and informative, creating a sense of curiosity and surprise through its sometimes odd and surprising categorizations. This is an example of what knowledge organization scholars called a controlled vocabularycontrolled vocabulary: A fixed collection of terminology used to restrict word choice to ensure consistency and support browsing and searching. , a carefully designed selection of words and phrases that serve as metadata for use in browsing and searching. Tagging systems like controlled vocabularies are in contrast to hierarchical systems of organization, like taxonomies, which strictly place data or documents within a single category.
While some metadata is carefully designed and curated by the creators of data, sometimes metadata is created by the consumers of data. Most systems call these taggingtagging: A system for enabling users of an information system to create descriptive metatdata for data. systems, and work by having consumers of data apply public tags to items, resulting in an emergent classification system; scholars have also called them folksonomies , collaborative tagging , or social classification , or social tagging systems 6 , distinguishing them from tagging systems that are controlled by some authoritative body such as a designer or a standard body. These have the benefit of having the classification scheme reflect users’ vocabulary and offer great flexibility to change tag metadata over time. However, they can also result in metadata that is too ambiguous, personal, or inconsistent to be useful to a wider audience.
Classification, in general, is fraught with social consequences. 3 We use them throughout society to categorize, label, and organize our environments, identities, and systems, but too often, the people who make these classification systems do not design them to include everyone, and so many of us end up not fitting the rigid categories prescribed by classification schemes. For example, we encode data using racial categories to prioritize resources; we use gender categories to inform sexist assumptions about lived experience and knowledge; we use categories about histories of incarcertation to deny people work. Classification, metadata, and data itself, is therefore not simply about bits and information, but morality, politics, and identity.

Thus far, we have established that information is powerful when it is situated in systems of power, that this power can lead to problems, and that information is likely a process of interpreting data, and integrating it into our knowledge. This is apparent in the story that began this chapter, in which the information gathered by U.S. Census has great power to distribute political power and federal resources. What this chapter has shown us is that the data itself has its own powers and perils, manifested in how it and its metadata is encoded. This is illustrated by how the U.S. Census encodes gender and race, excluding my identity and millions of others’ identities. This illustrates that the choices about how to encode data and metadata reflect the values, beliefs, and priorities of the systems of power in which they are situated. Designers of data, therefore, must recognize the systems of power in which they sit, carefully reflecting on how their choices might exclude.
Podcasts
Learn more about data and encoding:
- Emojiconomics, Planet Money, NPR . Discusses the fraught role of business and money in the Unicode emoji proposal process.
- Our Year: Emergency Mode Can’t Last Forever, What Next, Slate . Discusses the processes by which COVID-19 data have been produced in the United States, and the messy and complex metadata that makes analysis and decision making more difficult.
- Inventing Hispanic, The Experiment, The Atlantic . Discusses the history behind the invention of the category “Hispanic” and “Latino”, and how racial categories are used to encode race as a social construct.
- Organizing Chaos, On the Media . Reports on the debates about the Dewey Decimal System and it’s inherent social biases.
References
-
Ruha Benjamin (2019). Race after technology: Abolitionist tools for the new jim code. Social Forces.
-
Kathryn Bock, Willem Levelt (1994). Language production: Grammatical encoding. Academic Press.
-
Geoffrey Bowker, Susan Leigh (2000). Sorting things out: Classification and its consequences. MIT Press.
-
Lewis Coe (2003). The telegraph: A history of Morse's invention and its predecessors in the United States. McFarland.
-
James Gasser (2000). A Boole anthology: recent and classical studies in the logic of George Boole. Springer Science & Business Media.
-
Andreas Hotho, Robert Jäschke, Christoph Schmitz, Gerd Stumme (2006). Information retrieval in folksonomies: Search and ranking. European Semantic Web Conference.
-
Jukka K. Korpela (2006). Unicode explained. O'Reilly Media, Inc..
-
C.E. Mackenzie (1980). Coded-Character Sets: History and Development. Addison-Wesley Longman Publishing.
-
M. Riordan (2004). The lost history of the transistor. IEEE spectrum.
-
Michael C. Schatz, Ben Langmead, Steven L. Salzberg (2010). Cloud computing and the DNA data race. Nature Biotechnology.
-
Claude E. Shannon (1948). A mathematical theory of communication. The Bell System Technical Journal.
-
Jon Stokes (2007). Inside the Machine: An Illustrated Introduction to Microprocessors and Computer Architecture. No Starch Press.
-
Marcia Lei Zeng (2008). Metadata. Neal-Schuman Publishers.

Information technology
My family’s first computer was an Apple IIe computer. We bought it in 1988 when I was 8. My mother had ordered it after $3,000 saving for two years, hearing that it could be useful for word processing, but also education. It arrived one day in a massive cardboard box and had to be assembled. Before my parents got home, I had opened the box and found the assembly instructions. I was so curious about the strange machine, I struggled my way through the instructions for two hours, I had plugged in the right cables, learned about the boot loader floppy disk, inserted into the floppy disc reader, and flipped the power switch. The screen slowly brightened, revealing its piercing green monochrome and a mysterious command line prompt.
After a year of playing with the machine, my life had transformed. My play time had shifted from running outside with my brother and friends with squirt guns to playing cryptic math puzzle games, listening to a homebody mow his lawn in a Sims-like simulation game, and drawing pictures with typography in the word processor, and waiting patiently for them to print in the dot matrix printer. This was a device that seemed to be able to do anything, and yet it could do so little. Meanwhile, the many other interests I had life faded, and my parents’ job shifted from trying to get us to come inside for dinner to trying to get us to go outside to play.
For many people since the 1980’s, life with computers has felt much the same, and it rapidly led us to equate computers with technology, and technology with computers. But as I learned later, technology has meant many things in history, and quite often, it has meant information technology.

What is technology?
The word technology comes from ancient Greece, combining tekhne , which means art or craft , with logia , which means a “subject of interest” to make the word tecknologia . Since ancient Greece, the word technology has generally referred to any application of knowledge, scientific or otherwise, for practical purposes, with its use evolving to refer to whatever recent inventions had captivated humanity 5 . And it generally has that broader meaning today, referring to any practical application of science, typically stemming from engineering disciplines. Consider, for example, this history of what was considered “technology” in different eras of human history:
| 15000 BC | stone tools |
|---|---|
| 2700 BC | abacus |
| 900’s | gunpowder |
| 1100’s | rockets |
| 1400’s | printing press |
| 1730’s | yarn spinners |
| 1820’s | motors |
| 1910’s | flight |
| 1920’s | television |
| 1930’s | flying |
| 1950’s | space travel |
| 1960’s | lasers |
| 1970’s | computers |
| 1980’s | cell phones |
| 1990’s | internet |
| 2000’s | smartphones |
While many technologies are not explicitly for the purpose of transmitting information, you can see from the ones in bold in the table above that most technology innovations in the last five hundred years have been information technologies 4 . Information technologies, of course, are any technology that serves to capture, store, process, or transmit information—or, more precisely, data , as we’ve discussed in the previous chapters.
A second thing that is clear from the history above is that most technologies, and even most information technologies, have been analog, not digital, from the abacus for calculating quantities with wooden beads almost 3,000 years ago to the smartphones that dominate our lives today. Only since the invention of the digital computer in the 1950’s, and their broad adoption in the 1990’s and 2000’s, did the public start using the word “technology” to refer to computing technology.

Early information technologies
The history of information technologies, unsurprisingly, follows the evolution of humanity’s desire to communicate. For example, some of the first information technologies were materials used to create art , such as paint, ink, graphite, lead, wax, crayon, and other pigmentation technologies, as well as technologies for sculpting and carving. Art was one of humanity’s first ways of communicating and archiving stories 6 , and a skill of privileged, as it required many skills to be able to produce color and shape materials, as well as leisure time, away from hunting and gathering.
Spoken language came next 9 . It might be hard to think of talking as a technology, but there appears to be a time when our species did not use language to convey information. Many anthropologists believe that we began with non-verbal communication, such as gestures, and that one of many possible practices, such as tool creation, ritual, and even grooming might have led to some regularity in how we eventually used sounds and gestures to come to agreement on the meaning of specific sounds. Even today, spoken language evolves, with new accent, new words, and new meanings to reflect shifting cultures.
Writing came later. Many scholars dispute the exact origins of writing, but our best evidence suggests that the Egyptians and Mesopotamian’s, possibly independently, created the early systems of abstract pictograms to represent particular nouns, as well as early Chinese civilizations, where symbols have been found on tortoise shells. These early pictographic scripts evolved into alphabets and character sets, and exploited any number of media, including walls of caves, stone tablets, wooden tablets, and eventually paper. Paints, inks, and other technologies emerged, eventually being refined to the point where we take immaculate paper and writing instruments such as pencil and pens for granted. Some found writing dangerous; Socrates, the Greek philosopher, for example, believed that the written word would prevent people from harnessing their minds:
For this invention will produce forgetfulness in the minds of those who learn to use it, because they will not practice their memory. Their trust in writing, produced by external characters which are no part of themselves, will discourage the use of their own memory within them. You have invented an elixir not of memory, but of reminding; and you offer your pupils the appearance of wisdom, not true wisdom, for they will read many things without instruction and will therefore seem to know many things, when they are for the most part ignorant and hard to get along with, since they are not wise, but only appear wise.
Writing, of course, was slow. Even once humanity had created books, there was no way to copy them other than painstakingly transcribing every word onto new paper. This limited books to the wealthiest and most elite people in society, and ensured that news was only accessible via word of mouth, reinforcing systems of power undergirded by access to information.

The printing press , invented by goldsmith Johannes Gutenberg around 1440 in Germany, solved this problem. It brought together a box full of letter blocks on which ink could be applied, another box in which letters were placed, and a machine, which would lay ink upon the lead blocks, and then paper would be rolled to apply the ink. With this mechanism, copying a text went from taking months to minutes, introducing the era of mass communication, permanently transforming society through the advent of reading literacy. Suddenly, the ability to access books and newspapers , and learn to read them, lead to a rising cultural self-awareness through the circulation of ideas that prior had only been accessible to those with access to education and books. To an extent, the printing press democratized knowledge—but only if one had access to literacy, likely through school.
While print transformed the world, in the late 18th century, the telegraph began connecting it. Based on earlier ideas of flag semaphores in China, the electrical telegraphs of the 19th century connected towns by wires, encoding what were essentially text messages via electrical pulses. Because electricity could travel at the speed of light, it was no longer necessary to ride a horse to the next town over, or send a letter via train. The telegraph made it possible to send a message without ever leaving your town.
Around the same time, French inventor Nicéphore Niépce invented the photograph , using chemical processes to expose a film to light over the course of several days, allowing for the replication of images of the world. This early process led to more advanced ones, and eventually black and white film photography in the late 19th century, and color in the 1930’s. It was much longer after the first photographs that the first motion pictures were invented. Photography and movies became, and continues to be, the dominant way that people capture moments in history, their own, and the world’s.

While photography was being refined, in 1876 Alexander Graham Bell was granted a patent for the telephone , a device much like the telegraph, but rather than encoding text through electrical pulses, it encoded voice. The first phones were connected directly to each other, but later phones were connected via switchboards, which were eventually automated by computers, creating a worldwide public telephone network.
During nearly the same year in 1887, Thomas Edison and his crew of innovators invented the phonograph , a device for recording and reproducing sound. For the first time, it was possible to capture live music or conversation, store it on a circular disk, and then spin that disk to generate sound. It became an increasingly popular invention, and lead to the recorded music industry.
Shortly after, at the turn of the century, broadcast radio emerged from the innovations in recording sound, and both homes and workplaces began to use radios to receive information across AM and then FM bands. Shortly after that, combining radio with motion picture technology, the first live transmission of television occurred in Paris in 1909, and just a decade later, televisions began entering the homes of millions of people.
While this brief history of information technology overlooks so many fascinating stories about science, engineering, and innovation, it also overlooks the fascinating interplay between culture and information technology. Imagine, for example, living in the era prior to books and literacy, and then suddenly having access to these mythical objects that contained all of the ideas of the world. Books must have created centuries of wonder on the part of people who may have never left their small agricultural community. Or, imagine living at the beginning of the 20th century, where books were taken for granted, but photographs, movies, telephones, radio, and television connected the world in ways never before possible, centering broadcast information technology for the next 80 years as the dominant form of communication. Thus, much as we are fascinated by computers and the internet now, people were fascinated by television, books, and the telegraph before it.

Computing emerges
It took tens of thousands of years for humanity to invent writing, millennia to invent the printing press, a few hundred years to invent recorded and broadcast media, and just fifty years to invent the computer. Of course, this is a simplification: Charles Babbage , a mathematician and inventor who lived in 19th century England first imagined the computer, describing a mechanical device he called the difference engine that could take the numbers as inputs, and automatically compute arithmetic operations on them. His dream was to replace the human computers of the time, who slowly and painstakingly and sometimes incorrectly calculated mathematical formulas for pay. His dream mirrored the broader trends of industrialization and automation at the time, when people’s role in industry shifted from making with their hands to maintaining and supporting machinery that would do the making. This vision capitivated his protogé, Ada Lovelace , the daughter of a wealthy poet Lord Byron. She wrote extensively about the concept of algorithms and how they might be used to compute with Babbage’s difference engine.
In the 1940’s, Alan Turing was examining the theoretical limits of computing, John Von Neumann was laying the foundations of digital computer architecture, and Claude Shannon was framing the theoretical properties of information. All of these men were building upon the original visions of Babbage, but thinking about computing and and information in strictly mathematical and computational terms. However, at the same time, Vannevar Bush , the director of the Office of Scientific Research and Development in the United States, had an entirely different vision for what computing might be. In his landmark article, As We May Think 1 , he imagined a fictional computer called the Memex , which contained a digital computer, digital memory, displays, keyboards, mice, touchscreens, and more importantly, access to an interconnected network of documents, photographs, and letters on any subject to its user. Bush’s vision was essentially one of a personal library, in which one could not only access any knowledge, but also create and store new knowledge. Here is how he described it:
Consider a future device for individual use, which is a sort of mechanized private file and library. It needs a name, and, to coin one at random, “memex” will do. A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory... Wholly new forms of encyclopedias will appear, ready made with a mesh of associative trails running through them, ready to be dropped into the memex and there amplified. The lawyer has at his touch the associated opinions and decisions of his whole experience, and of the experience of friends and authorities. The patent attorney has on call the millions of issued patents, with familiar trails to every point of his client’s interest. The physician, puzzled by a patient’s reactions, strikes the trail established in studying an earlier similar case, and runs rapidly through analogous case histories, with side references to the classics for the pertinent anatomy and histology. The chemist, struggling with the synthesis of an organic compound, has all the chemical literature before him in his laboratory, with trails following the analogies of compounds, and side trails to their physical and chemical behavior.
If this sounds familiar, it’s no coincidence: this vision inspired many later inventors to realize this vision, including Douglas Engelbart , who gave a demonstration of the NLS , a system resembling Bush’s vision, which inspired Xerox Parc to explore user interfaces with the Alto , which inspired Steve Jobs to create the Apple Macintosh , which set the foundation for the future of personal computing we have today.
(If you’re wondering why all of these inventors were White men, look no further than the 20th century universities in the United States and United Kingdom, which systematically excluded women and people of color until the 1960’s. Universities are where most of this invention occurred, and where all of the world’s computers were, as computers took up entire rooms rooms in which women, Black, Asian, Hispanic, and Native people simply weren’t allowed).
The underlying ideas of computing followed a very simple architecture, as depicted in the video above:
- Computers encode programs as a series of numbered instructions.
- Instructions include things like add , multiply , compare , and jump to instruction
- Instructions can read data from memory, and store data in memory
- Computers execute programs by following each instruction until the program halts.
- Computers can take inputs from users and give outputs to users.
In essence, computing is nothing more than the ideas above. The magic of computing, therefore, emerges not from these simple set of rules that govern computer behavior, but how the instructions in computer programs are assembled to do magical things. In fact, part of Turing’s theoretical contribution was observing that the ideas above have limits: it is not possible to write a program to calculate anything we want, or do anything we want. In fact, some programs will never finish computing, and we will not be able to know if they ever will. Those limits are fundamental and inescapable, as certain as any mathematical proof.
Yet, as an information technology, if we program them to, computers can do a lot. They can take in data, store it, analyze it, manipulate it, even capture it, and then retrieve and display it. This is far more any of the information technologies in the history we discussed earlier, and it could do it far faster and more reliably than any prior technology. It is not surprising then that since the 1950’s, computers have transformed all of the prior technologies, replacing the telephone with Voice Over IP, the film photograph with digital photographs, analog music with digital, and print documents with digital documents. The computer has not really contributed new ideas about what information technology can be, but rather digitized old ideas about information technology, helping us to make them easier to capture, process, and retrieve.

Is computing the superior information technology?
There are many things that make computers an amazing form of information technology. They can store, process, and retrieve data faster than anything we have ever invented. Through the internet, they can give us more data than we could ever consume, and connect us with more people than we could possibly ever know. They have quickly exceeded our needs and wants, and as we continue to invest in enabling them to do more powerful things, we will likely continue to.
But are computers really the best information technology? Just because they are the most recent, doesn’t necessarily mean they are superior. Let us consider a few of their downsides relative to older information technologies.
- Amplification . Because computers are so fast and spread data so easily, they have a tendency to amplify social trends far more than any prior information technology 10 , for better or worse. In the case of spreading information about a cure to a deadly virus, this amplification can be a wonderful thing, saving lives. But amplification can also be negative, helping disinformation spread more rapidly than ever before. Is this a worthwhile tradeoff? For the victims of amplification, such as those oppressed by hate speech, harassment, or even hate crimes spurred by division in online communication, the answer is a clear no.
- Automation . In prior forms of information technology, there are many different people involved in making information move. For example, prior to automated telephone switching, it was possible to talk to human telephone operators if you had a wrong number; they might know who you were trying to reach, and connect you. With code, however, there is no person in the loop, no person to question the logic of code. Is it better to have slowly executed instructions that you can interrogate, question, and change, or quickly executed instructions that you cannot challenge? If you are marginalized in some way in society, with no way to question the automation and its decisions 2 , then the answer is once again no.
- Centralization . At the height of news journalism, there were tens of thousands of news organizations, each with their own values, focus, and ethics. This diversity built a powerful resilience to misinformation, leading to competition for investigation and truth. With computers and the internet, however, there are fewer distributors of information than ever: Google is the front door to most of of the data we access, Amazon the front door of the products we buy, and Facebook (and its other social media properties) is the front door of the people we connect with. If we don’t find the information we need there, we’re not likely to find it elsewhere, and if we don’t like how those services work, we have fewer alternatives than ever. Is the benefit that comes from centralization worth lost choice and agency? If the services above have effectively erased your business from the internet, eliminated your sales, or led to the spread of misinformation that harms you and your community 7 , once again, no.
The dominant narrative that positions computing as superior rests upon the belief that all of the trends above are ultimately better for society. But the reality is that computing is not magic, computing is not infinitely powerful, computing is highly dependent on human labor to write code and create data, and most of the reason that people want computers is because they want information. As we have seen throughout history, fascination with the latest form of information technologies often grants far too much power to the technology itself, overlooking the people behind it and how it is used.
Of course, computing is far more powerful than any information technology we have invented. Many argue that it is leading to a fundamental shift in human reality, forcing us to accept that both natural and virtual realities are real and posing new questions about ethics, values, and society 3 . Computing is faster, more versatile, and more disruptive than anything that has come before it. While we have long assumed that the power of computing is inherently good, history has also taught us that no information technology is inherently good or bad, nor is it neutral: it is what we do with it that matters, just like information itself.
Podcasts
Learn more about information technology:
- The AI of the Beholder, In Machines We Trust, MIT Technology Review . Discusses recent advances in applying machine learning to beauty, and the shift from altering our physical appearance with makeup and surgery to altering the pixels that represent it. Discusses racism, ageism, and other biases encoded into beautification algorithms.
- A Vast Web of Vengeance, Part 2, The Daily, NY Times . Discusses the maintainers of websites who spread information that harms reputations, how Section 230 protects them, and the extortion that some companies use to have defamatory information removed.
- The Most Thorough case Against Crypto I’ve Heard, The Ezra Klein Show, NY Times . Discusses the numerous risks of decentralized currency, intersecting with issues of privacy, property, and individualism.
References
-
Vannevar Bush (1945). As we may think. The atlantic monthly.
-
Virginia Eubanks (2018). Automating inequality: How high-tech tools profile, police, and punish the poor. St. Martin's Press.
-
Luciano Floridi (2014). The Fourth Revolution: How the Infosphere is Reshaping Human Reality. OUP Oxford.
-
James Gleick (2011). The information: A history, a theory, a flood. Vintage Books.
-
Stephen J. Kline (1985). What is technology?. Bulletin of Science, Technology & Society.
-
Shigeru Miyagawa, Cora Lesure, Vitor A. Nóbrega (2018). Cross-modality information transfer: a hypothesis about the relationship among prehistoric cave paintings, symbolic thinking, and the emergence of language. Frontiers in Psychology.
-
Safiya Noble (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
-
Plato (-370). Phaesrus. Cambridge University Press.
-
Jean-Jacques Rousseau, John H. Moran, Johann Gottfried Herder, Alexander Gode (2012). On the Origin of Language. University of Chicago Press.
-
Kentaro Toyama (2015). Geek heresy: Rescuing social change from the cult of technology. PublicAffairs.
Information systems
When I started middle school at the age of 12, I had the great fortune of being the first class in a brand new building. The architecture was a beautiful half circle, and large attached box on the side. The box housed a large gym and our cafeteria. The two levels of the half circle contained several dozen classrooms and lockers. And in the center of the half circle, below a radiant glass ceiling in a fully open atrium, was our library, rich with short stacks of books, desks of computers, and several rows of seating. This library was clearly meant to be the heart of the school, representing knowledge and discovery, and the hub connecting the classrooms, the gym, the cafeteria, and the outside world. Every week, throughout middle school, we had a library class, where we learned how to use a card catalog, how to read carefully, how to write a bibliography, and about the wonderful diversity of the genres, from young adult pulp fiction to historical non-fiction. Our librarian loved books and loved teaching us to love them.
At home, I encountered a different world of knowledge. My family had a new PC, and inside it was something called a modem, which we plugged into our phone line, and used to connect to the internet via a service called America Online (AOL). When we wanted to connect, we made sure no one needed to use the phone, then initiated a connection to AOL. The modem’s speaker would make a phone call to AOL, but instead of voice, it made a piercing screech. After a minute, we would hear the affirming sound of a connection, when we knew we were online. Once there, I had a similar sense as I did at my school library, that I was connecting with the world. But this world, rather than being full of carefully written, carefully curated texts, was a mess. AOL had a chaotic list of links to different portals, with stories that seemed to be written by journalists. There were encyclopedia entries describing seemingly random topics. There were chat rooms, where I could be connected with random, anonymous people around the world. And there were collections of files; one favorite of mine was sound clips from famous movies. My brother and I would wait an hour for one WAV file to download, then spend several more hours using the sound editor application in Windows 95 to reverse it, speed it up, making Arnold Schwarzenegger as the Terminator say “I’ll be back”, backwards, and like a chipmunk.
These two different experiences emerged from two very different information systemsinformation system: A process for coordinating people, data, and information technology in order to faciliate information creation, storage, and access. 1 : that of a school library and that of AOL. And as the stories show, each had their own unique qualities, connecting me with different information, different ideas, and different people. In this chapter, we discuss what information systems are, how they differ, and compare them to our most recent modern information system: the internet.
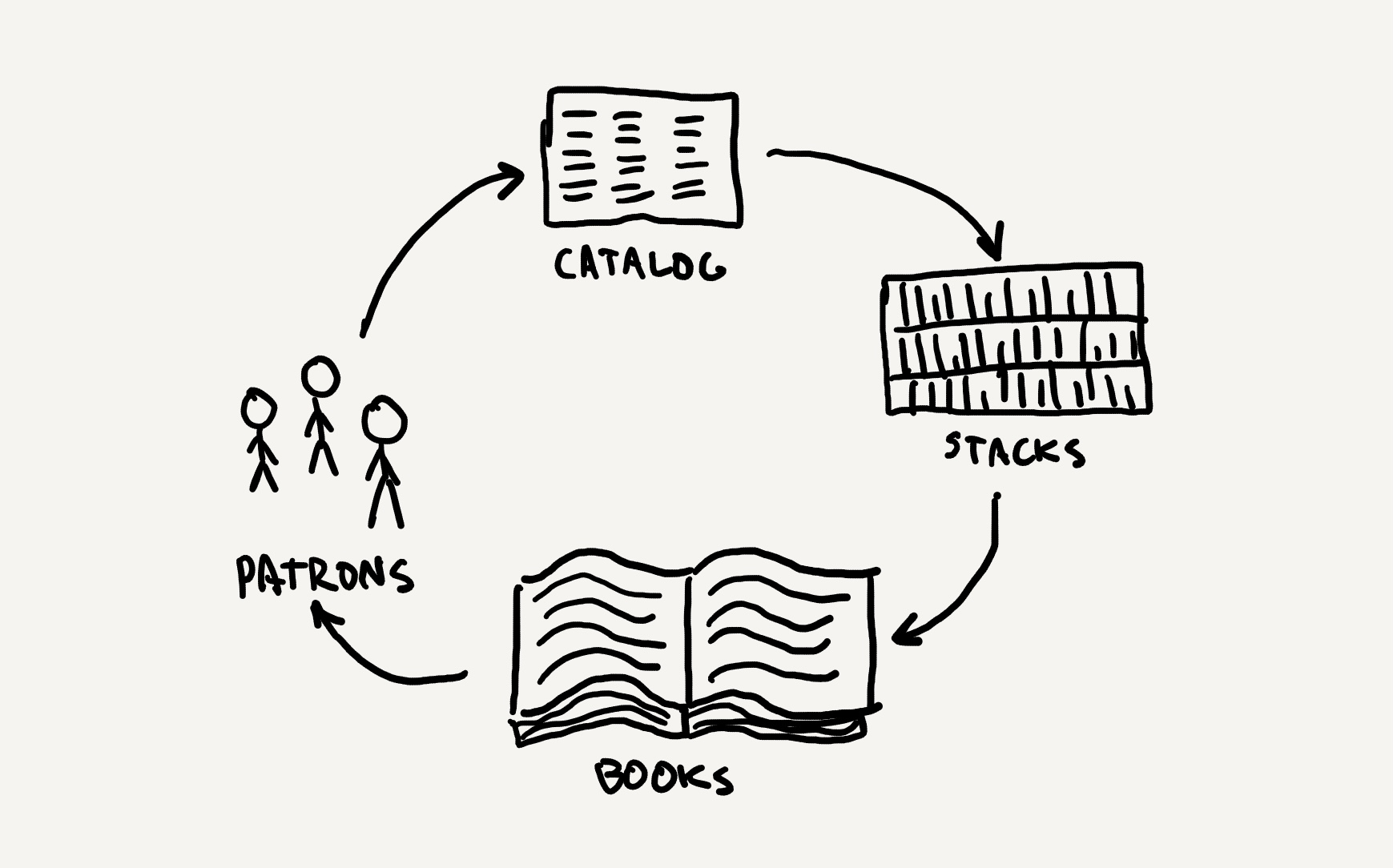
What are information systems?
In contrast to information technology, which is some form of engineered device like the telephone or computer, information systemsinformation system: A process for coordinating people, data, and information technology in order to faciliate information creation, storage, and access. 1 are processes that organize people, technology, and data to allow people to create, store, manipulate, distribute, and access information . For example, a book is an information technology, but a library is an information system that makes books—among other things—accessible. A library’s process, as depicted above, might involve patrons using a catalog to find the location of the book, going to the stack that contains that book, using the organization of the stack to locate the book, then reading the book. Each of these parts of the process uses a different information technology (e.g., an index, a sorting scheme, a book), but together they make a system. In contrast, a computer is an information technology, but its system includes an operating system, software ecosystem, technical support and repair services, and online communities. Information systems can even be highly informal and low-tech; for example, in your family, you might have someone who plays the role of organizing family gatherings, determining when people are available, finding locations to meet, and planning activities. Their work, their communication with you, and their use of communication technologies, is an information system. Whether a library, a computer, or a family, all of these are processes that move data between people and technology in specific, ordered ways, each optimized for particular goals.

Information systems, like information technologies, have come in many forms in history. Consider, for example, the Great Library of Alexandria 3 , one of the largest information systems in modern history. It was built in Alexandria, Egypt, and part of a larger research institution called the Mouseion. The idea behind the library was to be a universal collection of knowledge. Ptolemy II Philadelpus, who ruled the region, was known for aggressively procuring papyrus scrolls of writing by either buying them or copying texts found on boats entering the Alexandrian ports (much like Google copies websites it finds online so that it may index them). Because it was such a great collection, Alexandria and its library became the capital of knowledge, with many influential philosophers working at the library in the 2nd and 3rd centuries BC, including Euclid (founder of geometry), Homer (author of epic Greek poems), Plato (founder of the first Western university), and Socrates (founder of Western moral philosophy). Many of these philosophers would study at the library, and make pilgrimages to seek more scrolls to bring back to the library. Keeping the library functioning required much more than just the technology of papyrus scrolls and ink: it required building maintenance; staff to acquire and copy texts; security, as it was not public. And like any information system, it had tradeoffs: there were no backups and it was hard to access geographically. Also, it burned: Julius Caesar set the harbor aflame in a battle in 48 BC, destroying much of the collection.

Whereas libraries are systems that are optimized for archiving and retrieving documents from a collection, newspapers are a very different kind of system. In its modern form, newspapers were invented in Europe 7 , which were handwritten news sheets circulated in the 16th century. These sheets contained information about wars and politics in Italy. Weekly newsletters like these flourished across Europe, especially after the invention of the printing press, which enabled thousands of copies to be printed cheaply each week or day. Newspapers, of course, followed a very different system architecture than libraries: journalists worked hard to gather and write news; photographers tried to capture these stories visually; these stories and images were then typeset in printing presses, then printed at scale. The copies of the newspaper were then sold on the street by “newsies” 2 (often young boys in poverty, but also women), distributed by a circulation manager who designed the delivery routes throughout a city. All of this occurred in a weekly, and then daily cycle, broadcasting the latest news to the public. Keeping this system functioning required well-maintained printing machines, paid journalists, paid photographers, paid circulation managers, paid newsies, and a lot of paper and ink. And the system of newspapers had different tradeoffs than a library: rather than going to the information, it came to you, and rather than being archival, it was ephemeral, with a new update each day or week. The biggest tradeoff with the news, even today, is that there is little time to verify information before it is shared, leading some in the 20th century to describe it as the “first rough draft of history” .

Systems, of course, evolve. Whereas the Great Library of Alexandria relied on papyrus scrolls and handwritten copying, today’s modern libraries are far different. Consider, for example, the U.S. Library of Congress , widely considered to be the world’s most comprehensive record of human creativity and knowledge. It contains millions of books, printed materials, maps, manuscripts, photographs, films, audio and video recordings, prints and drawings—even every tweet on Twitter from 2006-2017, and selective tweets since. It acquires all of these through exchanges with libraries around the world, through gifts, and through purchase, adding thousands of new items each day, with a full staff curating and selecting items for inclusion in its permanent collection. It stores the books in dozens of buildings in Washington, D.C. and elsewhere; none of them are publicly accessible. However, because the library is a research library, any member of the public can search the online catalog of more than 18 million records, request an item, and read it at the library. Maintaining this library is far more involved than the Library of Alexandria 6 : it requires maintaining dozens of buildings, building web scale cataloging and search software, staffing 3,000+ employees, archiving petabytes of data, managing a $600 million budget, and constantly refining policies and procedures to ensure the archive is kept intact and accessible to the world. Because of the library’s focus on archiving, it does not contain the most recent information in the world, but it does contain its most ancient, making it far better than Google at retrieving primary sources documenting human civilization and its history.
As should be clear from each of these examples, information systems are far more than a particular technology: they are processes that combine skilled people, systems of organization, and information technologies to provide access to information, each optimizing for particular kinds of information and information experiences.

The internet
No discussion of information systems would be complete without discussing the internet , perhaps the largest and most elaborate information system that humanity has ever created. And as with any system, it is a history of more than just technical innovation. It started in the 1950’s 4 , after the invention of the modern digital computer. Various engineers and policy makers had discussed ways of connecting computers to make a global network, and in 1969, the U.S. Department of Defense Advanced Research Projects Agency (DARPA, originally ARPA) funded the ARPANET, a government project to network computers. Project lead Bob Taylor and science policy lead J.C. Licklider published The Computer as a Communication Device 5 , describing a future in which computers would be used to share information much more broadly and rapidly than telegraphs, telephones, or television had ever done before. They made bold predictions about the impact of this imagined global network
When people do their informational work “at the console” and “through the network,” telecommunication will be as natural an extension of individual work as face-to-face communication is now... life will be happier for the on-line individual because the people with whom one interacts most strongly will be selected more by commonality of interests and goals than by accidents of proximity. ... communication will be more effective and productive, and therefore more enjoyable... there will be plenty of opportunity for everyone (who can afford a console) to find his calling, for the whole world of information, with all its fields and disciplines, will be open to him—with programs ready to guide him or to help him explore... Unemployment would disappear from the face of the earth forever, for consider the magnitude of the task of adapting the network’s software to all the new generations of computer, coming closer and closer upon the heels of their predecessors until the entire population of the world is caught up in an infinite crescendo of on-line interactive debugging.
The vision, while not perfect in its clairvoyance, laid out several hard problems that needed to be solved to realize the networked future: how to format and send messages reliably; where to store data; and most importantly, how to ensure everyone could have access to a computer to participate. This led to the U.S. APRANET project, which sought to solve many of these problems through government-funded research and innovation. This history is told by Robert Kahn, discussing the motivations behind the beginnings of the internet:
The first foundation was that the internet is a graph : a collection of nodes, each a computer, connected by edges, each some hardware allowing messages to be transmitted between computers. Getting information from one node to another requires finding a path from one node in the network to another. Therefore, when you access the internet on a phone, tablet, laptop, or desktop, your computer has to send a request to another computer for that information, and that request itself has to find a path to that computer, before that computer can respond with the data, sending it back along a path.

All of these back and forth messages between computers requires a protocol to organize communication. For example, when we send physical letters in the U.S. mail, there is a protocol: put a message in an envelope, write an address for where you want to send it, write a return address in case it cannot be delivered, put a stamp on it, then submit it to a post office or post office pickup location. The internet required something similar; Vint Cerf invented the protocol we use today in 1973, naming it TCP/IP . The TCP stands for Transmission Control Protocol , and defines how computers start a conversation with each other. In a simplified form, TCP defines two roles for computers on the internet: clients , which request information, and servers , which deliver it. TCP works in three phases:
- The server starts listening for connections.
- The client asks for a connection.
- The server acknowledges the request.
After this, data is sent in chunks called packets , which are a sequence of bytes defining where the information is coming from, where it is going, and various other information for checking whether the information has arrived intact, along with the data itself. After the data is received, the server indicates that it is done sending information, the client acknowledges that it was received intact and requests the connection be closed, and then the server closes the connection.
TCP, of course, is just one part of transmitting information. The other part in the acronym TCP/IP is IP , which stands for Internet Protocol . This defines how computers on the internet are identified. An IP address is a unique number representing a computer; all computers connected to the internet have one, though they may change and be shared. IP addresses are four 8-bit numbers and look something like this:
152.002.081.001 The first two chunks are a unique number assigned to the network your computer is connected to; the last two parts are a unique number on your network. More modern versions of IP addresses (IPv6) contain 128 bits, allowing for more uniquely identifiable addresses. These addresses ultimately end up encoded in TCP packets to indicate the source and destination of data.

If the internet was just a bunch of computers connected to each other via TCP/IP, it wouldn’t work very well. Every computer would need to know the IP address of every computer that it wanted to communicate with. And clearly, when we use computers today, we don’t have to know any IP addresses. The solution to this problem is two fold. First, we have routers , which are specialized computers that break up the internet into smaller networks, and are responsible for keeping records of IP addresses and finding paths for a packet to get to its destination. You probably have a router at home to connect to your internet service provider (ISP), which is essentially one big router that processes TCP requests from millions of customers. Second, we have domain name services , which are specialized computers that remember mappings between IP addresses and unique names ( www.seattle.gov ), which are organized into top level domains ( .gov ), domains ( seattle ), and subdomains ( www ). Your internet service provider also maintains DNS lookups, so you don’t have to memorize IP addresses. Combined, TCP, IP, DNS, and routers are what allow us to enter a simple domain like www.seattle.gov into a web browser, establish a connection to the UW web servers, request the front page of the Seattle city government website, receive that front page, close the connection, and then render the front page on our computer.
There is one more important detail: TCP/IP alone, plus some network hardware to connect computers to routers via ethernet cables or wireless protocols, is sufficient to create the internet. But it is not sufficient to create the web , which is actually an application built on top of the internet using yet more protocols. The most important of these, HTTP (hypertext transfer protocol) (or the encrypted version, HTTPS ), is how computers use TCP/IP to send and request entire documents between computers. It wasn’t invented until the early 1990’s. The basis of HTTP is simple: clients send a request for a particular document via a URL (uniform resource locator), which consists of a domain ( www.seattle.gov ) plus a pathway to the desired document ( /visiting-seattle ). When we combine the transfer protocol, the domain, and the path, we get https://www.seattle.gov/visiting-seattle , which specifies how the request will be formatted, which computer we want to send the request to (by name, which will be used to lookup an IP address on a DNS server), and which document on that computer we want ( /visiting-seattle ). If the computer has a web server running that knows how to handle HTTPS requests, it will use the path to retrieve the document, then send it back to the client.
Together, TCP, IP, routers, DNS, and HTTP, and their many versions and supporting hardware, make up the modern internet and web, and allow it to be as simple as typing in a URL and seeing a web page. Every computer on the internet must follow these protocols for any of this to work. And if anything goes wrong in the process, the internet will “break”:
- If your computer loses its wired or wireless connection to a router, it won’t be able to connect to other computers.
- If your router loses its connection to the rest of the internet (e.g., your ISP loses its connection), it won’t be able to send packets.
- If your router can’t find a path from your computer to the computer from which you’re requesting information, your request will “time out”, and result in an error.
- If the computer processing your request can’t find the document you’re requesting (e.g.,
https://www.seattle.gov/not-a-real-page), it will send an error. - If the web browser on the computer processing your request hangs or terminates, it won’t process requests.
- If the computer processing your request experiences a power outage, it won’t process requests.

Much of what industry calls the cloud is meant to deal with these reliability problems. The cloud is essentially a collection of large data centers distributed globally that contain large numbers of powerful computers that redundantly store large amounts of data. Computers then request that data for display, and send requests to modify that data, rather than storing the data locally. For example, when you edit a Google Doc, the document itself is not stored on your computer, but redundantly stored on many servers across the globe. If one of those data centers has a power outage, another data center will be there to respond, ensuring that you’ll rarely lose access. (Of course, when you go offline, you won’t have a copy of your data at all).

Is the internet the best information system?
Humanity has invented many forms of information systems in history, all with different strengths and weaknesses. But it is tempting to imagine that the internet, being the newest, is the best of them all. It is fast, it is relatively reliable, it connects us to nearly anyone, anywhere, and we can access nearly anything—data, information, even goods and services—by using search engines. When we compare this to older types of systems—word of mouth, libraries, newspapers—it is hard to argue that they are in any way superior, especially since we have replicated most of those systems on the internet in seemingly superior forms. News is faster, books are easier to get, and even informal systems like chatting with friends and sharing gossip, has never been more seamless and efficient.
But if we think about information systems in terms of qualities , it becomes clear that the internet is not always superior:
- Accuracy . Much of the data on the web is misleading or even false, which is far less true for information from carefully curated, edited, and fact-checked sources like books and leading newspapers, or from experts directly.
- Reliability . A print book doesn’t depend on electricity or a network of computers to operate. As long as the book is the only information you need, it’s much more reliable that a computer connected to the internet.
- Learnability . Learning to talk, whether verbally or non-verbally, is still easier for people to learn than the many skills required to operate a computer (mice, touch screens, keyboards, operating systems, applications, web browsers, URLs, buttons, links, routers, wifi, etc.).
Of course, the internet is superior in somethings: it wins in speed , as well as currency , which refers to how current information is. To the extent that humanity is only concerned with getting recent information quickly, then it is superior. But when one wants expert information, information from history, or private information that might only be stored in people’s memories or private archives, the internet is inferior. And more importantly, if you want to live life slowly, take in information in a measured, careful way, and have time to process its meaning, the speed and currency of the internet will be a distraction and nuisance. Thus, as with all designed things, the internet is optimized for some things, and fails at others.
Information systems, therefore, aren’t better or worse in the absolute sense, but better or worse for particular tasks. Choosing the best system for a particular task then isn’t just about choosing the latest technology, but carefully understanding the task at hand, and what types of systems might best support. And as society is slowly discovering, the internet might be fast, but it isn’t so good at tasks like helping people find credible information, learn online, or sustain local communities. In fact, it seems to be worse at those things, when compared to systems that rely on authoritiative, credible information, systems that center physically proximal teachers for learning, and physical spaces that bring communities together to connect.
Podcasts
These podcasts explore some of the strengths and weaknesses of modern information systems.
- Rabbit Hole, Episode 1, NY Times . Discusses YouTube as an information system, and the kinds of information experiences it excels at creating.
- Why the Vaccine Websites Suck, What Next TBD . Discusses the many policies, practices, and market dynamics that result in U.S. government websites being so poor in quality.
- Seduced by Substack, What Next TBD, Slate . Discusses why some journalists are shifting from traditional journalism to a paid newsletter model on Substack, and the tradeoffs of the new model for editorial oversight, labor, and chasing audience.
- Brown Box, Radiolab, WNYC Studios . Discusses the information systems used to rapidly provision online orders and some of inhumane work they cause. Also discusses the complexities of name changes for those with records of archived, credited work. (The reporter is transgender.)
- The Internet is a Luxury, Recode Daily, Vox . Discusses the digital divide and why most people in the world still don’t have access to the internet.
- 404: Podcast Not Found, Recode Daily, Vox . Discusses the exceptional difficulties of archiving content on the internet relative to other information systems.
References
-
Michael K. Buckland (1991). Information and information systems. ABC-CLIO.
-
Maria DiCenzo (2003). Gutter politics: Women newsies and the suffrage press. Women's History Review.
-
Andrew Erskine (1995). Culture and power in ptolemaic Egypt: The Museum and Library of Alexandria. Greece & Rome.
-
Barry M. Leiner, Vinton G. Cerf, David D. Clark, Robert E. Kahn, Leonard Kleinrock, Daniel C. Lynch, Jon Postel, Larry G. Roberts, Stephen Wolff (2009). A brief history of the internet. ACM SIGCOMM Computer Communication Review.
-
Joseph C.R. Licklider, Robert W. Taylor (1968). The computer as a communication device. Science and technology.
-
Gary Marchionini, Catherine Plaisant, and Anita Komlodi (1998). Interfaces and tools for the Library of Congress national digital library program. Information Processing & Management.
-
Michael Schudson (1981). Discovering the news: A social history of American newspapers. Basic Books.
Seeking information
I had a lot of questions when I was a child. Driving around Portland, Oregon, I would point to signs and objects and pose endless queries: “what is that?”, “who is that?”, “ why is that?” Nothing was mundane enough—I wanted to know it all. And when I started to read, I wanted to know the meaning of every word. I remember one particular night when I’d brought home a book from my 1st grade class about rabbits. I read it late at night in my bed, sounding out each word under my breath. I got to a sentence that had the word “laughing” and got stuck. I walked up to my parents’ bedroom, tip toed to their bed, and tapped my sleeping mother’s shoulder, and whispered, “ what is log...hing? ”, trying to pronounce this tricky English word.
My queries, of course, became more sophisticated. In high school, I remember encountering some of the web’s first commercial search engines, including Infoseek , Yahoo , WebCrawler , Lycos , Excite , AltaVista , AskJeeves , and eventually Google , mesmerized how, just like my parents, they would answer any question. Just like my parents, sometimes the answer was “I don’t know”, and quite frequently, the answers I got seemed like they were wrong, or just someone’s inexpert opinion. But unlike my parents, and unlike the library and its encyclopedias, these search engines could connect me with content about anything, and do it privately. Unfortunately, too few transgender people were out on the web for me to find many answers about my gender. It would take another decade before the communities and content I needed to make sense of my gender were online, discoverable, and something I felt safe querying.
Whether it’s a child’s simple questions of parents or life changing query about identity, our human desire for information means we are constantly seeking it. This activity, which we often describe as information behaviorinformation behavior: How people go about creating, finding, and interpreting information. 3 , involves people seeking, managing, sharing, and using information across all possible contexts. And, of course, our desire for information is everything we have discussed in this book so far: it’s why we create information systems, why we create technology to support those systems, why we encode data and metadata, why we create information, and why information has any power and peril. In this chapter, we’ll discuss how we seek it, and the narrow role of modern web search engines in answering our questions.

The many facets of information seeking
At a superficial level, it might seem like information seeking is as simple as questions and answers. And that’s a reasonable simplification of something all people do: we often first become aware that we want to know something when we have a question, and it often seems like the need is met once we have the answer. However, information seeking is a complex process, full of subtle, sometimes subconscious processes, all of which influence what we seek and what we do with what we seek.
Consider first the many things that come before a question. There is the contextcontext: Social, situational information that shapes the meaning of information being received. that we have for some information need, which includes our prior knowledge, the people around us, the factors governing our motivation, and our values and beliefs. For example, you might never seek to know the origin of the Czech pastry trdelnik until you visit Prague and see everyone eating them. And I didn’t want to know how to pronounce the word “laughing” until I encountered it in the middle of a very cute story about a bunny. Nobel Laureate Herb Simon described the importance of context in shaping our behavior with a parable of an ant on a beach:
We watch an ant make his laborious way across a wind- and wave-molded beach. He moves ahead, angles to the right to ease his club up a steep dunelet, detours around a pebble, stops for a moment to exchange information with a compatriot... Viewed as a geometric figure, the ant’s path is irregular, complex, hard to describe. But its complexity is really a complexity in the surface of the beach, not a complexity in the ant... An ant, viewed as a behaving system, is quite simple. The apparent complexity of its behaviour over time is largely a reflection of the complexity of the environment in which it finds itself.
Simon would therefore argue that information seeking, as with context in any behavior, is at least partly shaped by our environment.
Of course, context alone isn’t the only factor that shapes someones information needs. There are other factors, such as one’s psychological , sociocultural , motivational , and cognitive factors, which shape how much someone wants some information and what they might be willing to do to find it 13 . For example, imagine becoming curious about your family history. Some people, after reflecting on the work it might take to uncover that history by talking to family and consulting official records, might decide that they aren’t interested enough, or aren’t confident enough in their ability to unearth the truth. Others with a great curiosity, a confidence in their research skills, and some free time, might happily begin their search. Therefore, matters of perceived risk and reward, self-efficacy of information seeking skills, and motivation might all interact to shape whether one searches.

Another factor is how one conceives of a question. For example, I know now that if I want information about gender affirming health care, I can use concepts and phrases like “gender”, “transgender”, and “gender identity”, and I will be likely to find information of high relevance with web search. But back in the 1990’s, I had no idea what words to use; the closest concept I knew was “gay”, because many people had used it against me as an insult, and so I searched the web with the query “ am I gay? ” That didn’t answer my question about gender because I was asking the wrong question. This is an example of prior knowledge shaping the questions we ask: when we lack it, we may not know what to ask, leading to ineffective queries and unhelpful answers. It often takes someone else with expertise, such as a teacher or librarian, to help us find well-formed questions that are consistent with the information resources in a system, not only in terminology, but also in concept.
Of course, only once we have a question do we begin to engage in an iterative process information seeking. This process is usually called sensemakingsensemaking: The human process of gathering, interpreting, and synthesizing information into knowledge. 9 , because it involves not only gathering information, but making sense of it, integrating it into our understanding, and using that new understanding to shape further information seeking. Consider, for example, a scenario in which a college student registering for classes identifies needs to know what to take to help them maximize their chances of graduating on time. They might message a friend in the same major for advice, and get an unhelpful answer, and then just pick some things that seem interesting. But in that brief interaction, there was actually a lot going on:
- They identified a need (determine what to register for to minimize time to graduation).
- They chose an information source (their friend, likely because they were the easiest to reach and most likely to help quickly).
- They expressed that need (“What should I take next?”, which doesn’t perfectly express their need).
- The information system—their friend and the messaging system— retrieved an answer (“Not sure, ask the advisors.”, indicating that either the source didn’t want to help or didn’t have the answer.)
- Evaluate the answer received (“That wasn’t helpful, I don’t have time to meet with them”)
- Sensemake (“I don’t really know what to take and it seems hard to find out.”)
Throughout this process, information seeking is influenced by all of the other factors: needs might change, the costs and risks of accessing various sources might change, expressions of needs can be imprecise or use ineffective terminology, the information system used might not have the answer, or might have an unhelpful or incorrect answer, the student might evaluate the answer wrong, or they might struggle to make sense of the answers they are finding.
Herb Simon, once again, provides a helpful explanation for these challenges: satisficingsatisficing: Human tendency to seek as little information as is necessary to decide, bounding rationality. 11,12 . This is our tendency to only consider so much information, and only consider it so carefully, when trying to make decisions. Simon viewed human beings as information processors, taking in information from the world and using it to problem solve and decide. Simon observed that because there is so much information to consider, we need some strategy to filter, to prevent us from getting paralyzed. Satisficing is how we do that, considering what we have learned until we meet some subjectively acceptable threshold of confidence or understanding. It’s why when we do a Google search, we might only look at the first few results, rather than considering all of them, before deciding that one of the sources is “good enough” to answer our question.

Another idea that explains this seemingly lazy behavior in information seeking is information foraginginformation foraging: The observation that humans rely on metadata cues in information environments to drive searching and browsing. theory 8 . In this theory, people are imagined to forage for information like we do for food: we use information to learn where food (information) might be found; we use information to determine the best way to find food (information); we consider how much energy it might take to get that food (information); and we consider how much energy that food (information) might provide. This theory has been used to explain how we browse websites to find the information we want, using labels on links and headers to help us estimate the likelihood of finding what we need. When those words are accurate predictors of where information is, we might learn to trust a source more.
What these various ideas about information seeking reveal is that finding and making sense of information is about far more than just questions and answers: it is about who we are, what we want, what we know, the information systems we have in our worlds, how our brains conserve our attention, and how these many factors end up shaping the information that we seek and obtain.
Search engines
How do search enginessearch engine: Software that translates queries into a collection of documents related to a query. like Google fit in to all of this? In essence, search engines are software that take, as input, some query, and return as output some ranked list of resources. Within the context of information seeking, they feel like they play a prominent role in our lives, when in actuality, they only play a small role: the retrieval part of the sensemaking steps above. To reinforce that, here is the list again, and how search engines fail to help:
- Search engines don’t help us identify what we need—that’s up to us; search engines don’t question what we ask for, though they do recommend queries that use similar words.
- Search engines don’t help us choose a source—though they are themselves a source, and a heavily marketed one, so we are certainly compelled to choose search engines over other sources, even when other sources might have better information.
- Search engines don’t help us express our query accurately or precisely—though they will help with minor spelling corrections.
- Search engines do help retrieve information—this is the primary part that they automate.
- Search engines don’t help us evaluate the answers we retrieve—it’s up to us to decide whether the results are relevant, credible, true; Google doesn’t view those as their responsibility.
- Search engines don’t help us sensemake—we have to use our minds to integrate what we’ve found into our knowledge.
While search engines are quite poor at helping with these many critical aspects of information seeking, they are really quite good at retrieving information. Let’s consider how they work, considering web search engines in particular.
The first aspect of web search to understand is that the contents of the web are constantly changing. Therefore, the first and most critical part of a search engine is its web crawlercrawler: Software that navigates interlinked data collections to discover and index new documents. 4 . This component attempts to read the contents of every public web page on the internet as frequently as possible, so that it can keep an up to date record of its contents to support retrieval. Early web crawlers did this quite slowly because they only used one or two computers to do it; modern web crawlers maintained by Google use orders of magnitude more computers to crawl billions of pages. Crawlers also have to discover new pages, and they do this by following links in HTML, building a model of all of the pages on the web and how they link to each other. All of this is similar to what a human does when they browse the internet, starting from one page, and following links—computers just do it fast, do it systematically, and record immense amounts of information about what they find.
For each page that a web crawler finds, it must parseparse: Algorithms for translating encoded data into representations suitable for analysis. the page, reading its HTML, finding all of the words and links in the document, and in the case of modern search engines, likely parsing the natural language text of a page to obtain its syntactic structure 1 . This parsing allows the web crawler to segment the text into words, parts of speech, and other linguistic features, which can be used to predict what the page is about. At this stage, the crawler might also identify images, videos, and other embedded content.
From this parsing, the search engine creates an indexindex: A data structure that organizes documents by one or more facets of their contents or metadata. 2 . Much like an index at the end of a print book, which shows all of the significant words in the book and which pages they occur on, a web search index does the same, mapping key words and phrases from web pages to the specific URLs of web pages on which they occur. The index is the key part of mapping a user query on to a document, as it is the central mapping between ideas on a page to the page themselves.
After building an index, there must be some way of mapping a user’s query onto the subset of documents that match that query. The simplest approach is of course to search for the pages in the index that contain those words. For example, if a user searched for cat videos , it could use the index to retrieve all of the documents containing cat and, separately, all of the documents containing videos , then find the intersection of these two document sets, and return them in a list. This, of course wouldn’t be a very helpful list, because it would probably contain hundreds of millions of web pages, and it’s very unlikely that anyone would read them all. Therefore, search engines have to do something more helpful; that’s where rankingranking: Ordering documents in a collection by relevance. comes in.
Early ways of ranking computed the “importance” of different words and phrases in a document. For example, one measure called TFIDF , which stands for term frequency, inverse document frequency . Term frequency refers to how frequently a word occurs in a document; document frequency refers to the prevalence of the word in a set of documents. The inverse refers to the ratio between the two: the more frequent a word is in a document and the more rare it is across all documents, the more meaningful it might be. For example, if cat appeared a lot on a page, but didn’t occur on many pages overall, it might be an “important” word, and therefore should receive a higher TFIDF score. In contrast, the word the , even if it appears on a page many times, occurs on likely every English page, and so its score would likely be near zero. Finally, comparing the importance of the words in a query to the importance of the words in the documents using a cosign similarity of two vectors of all of the words in the query and pages produced a measure of importance and similarity, providing a helpful way to sort search results.
Another way to rank pages—and the one that made Google Search succeed over its dozens of competitors in the late 1990’s—was PageRank (a pun, cutely named after Larry Page, while also referring to web pages ). This algorithm, inspired by bibliometrics used by information scientists to identify impactful research publications and scientists, computed a measure of relevance based on the number of pages that link to a page. Conceptually, this was a measure of a page’s popularity. Using this measure to rank pages produced more popular results than TFIDF, which many users perceived as more relevant. Because Google Search is proprietary, we do not know if it still uses PageRank, but we do know that search ranking has advanced considerably with natural language processing 5 , knowledge graphs for question answering 6 .
Of course, all of the ideas above only work if this process is really fast. Modern web search relies on massive numbers of computers, constantly crawling, parsing, indexing, and pre-computing the answers to queries, and storing those answers redundantly across dozens of data centers worldwide. Without all of this optimization, a Google search would take minutes, if not days, instead of the less than 100 milliseconds that most searches take. What makes all of this possible is scale: most queries have been asked before, and so with enough users, it’s possible to know, in advance, most of the queries that one might encounter, and answer them in advance. Therefore, when you type a query into Google, it’s not answering your question in real time, it’s merely retrieving a ranked list of results already computed.
Of course, knowing all of the above, one thing should become obvious: search engines don’t really know anything. All they are really doing is retrieving content from the web that matches the words in a query. They do not know if content is biased, correct, harmful, or illegal. And in fact, because search engine ranking algorithms themselves have their own biased ideas about what “relevant” means, they can introduce bias of their own, surfacing results that perpetuate harmful stereotypes or erase the existence of important resources 7 . For example, it is “popular” to only hire older white cis men as CEOs, and so searching for images of CEOs returns results of white cis men. Popular, in this example, is simply a proxy for sexist.
It’s easy to be impressed by the scientific and engineering feats that have produced web search engines. They are, unquestionably, one of the most impactful and disruptive information technologies of our time. However, it’s critical to remember their many limitations: they do not help help us know what we want to know; they do not help us choose the right words to find it; they do not help us know if what we’ve found is relevant or true; and they do not help us make sense of it. All they do is quickly retrieve what other people on the internet have shared. While this is a great feat, all of the content on the internet is far from everything we know, and quite often a poor substitute for expertise. But we are satisficers, and so this often seems good enough. But our desire for speed and ambience to truth has consequences, as we have seen.
Podcast
Learn more about information seeking and search:
- Who We Are At 2 a.m., Hidden Brain, NPR . Discusses the role of search engines in creating private spaces for learning.
- Bias and Perception, TED Radio Hour, NPR . Discusses bias, perception, and how search engines can perpetuate them.
- The Force of Google, Seriously, BBC . Discusses Google as a monopoly and the secrecy of the Google Search algorithm.
- Meet the Man Who Wants You to Give Up Google, Sway . Discusses how ad-supported search engines bias search results and the various tradeoffs of subscription-based alternatives.
References
-
Steven Bird, Ewan Klein, Edward Loper (2009). Natural Language Processing with Python. O'Reilly Media.
-
Sergey Brin, Lawrence Page (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems.
-
Karen E. Fisher, Sanda Erdelez, and Lynne E.F. McKechnie, Sanda Erdelez (2005). Theories of information behavior. ASIST.
-
Allan Heydon, Marc Najork (1999). Mercator: A scalable, extensible web crawler. World Wide Web.
-
Julia Hirschberg, Christopher Manning (2015). Advances in natural language processing. Science.
-
Maximilian Nickel, Kevin Murphy, Volker Tresp, Evgeniy Gabrilovich (2016). A Review of Relational Machine Learning for Knowledge Graphs. Proceedings of the IEEE.
-
Safiya Noble (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
-
Peter Pirolli (2007). Information foraging theory: Adaptive interaction with information. Oxford University Press.
-
Daniel Russell, Mark J. Stefik, Peter Pirolli, Stuard K. Card (1993). The cost structure of sensemaking. ACM Conference on Human Factors in Computing Systems.
-
Herbert A. Simon (1963). The Sciences of the Artificial. MIT Press.
-
Herbert A. Simon (1972). Theories of bounded rationality. Decision and Organization.
-
Herb A. Simon (1978). Information-processing theory of human problem solving. Handbook of learning and cognitive processes.
-
Tom D. Wilson (1997). Information behaviour: an interdisciplinary perspective. Information Processing & Management.

Hiding information
For most of my adulthood, I used two personal Google accounts. One was my social account, which I used to communicate with friends and family, track my search history, track my calendar, and interact with commerce. I didn’t worry about much about data privacy on this account, as it was very much my “public” personal account, out and visible in the world. Consequently, my digital ads reflected my “public” personal life, as seen through my searching and browsing: parenting goods, gadgets, and generic man stuff, like trucks and deodorant.
My other personal account, however, was very much private. It was the account I used to search for information about gender. I used it to log in to forums were I lurked to learn about other transgender people’s experiences. I used it to ask questions I wouldn’t ask anyone one else, and didn’t want anyone else to know I was asking. I always browsed in Chrome’s incognito mode, to make sure there was no search history on my laptop. I kept my computer password locked at all times. Every time I finished a search, I closed my browser tabs, cleared my browser history, and erased my Google and YouTube histories, and cleared the autocomplete cache. Google still had my search logs of course, but I took the risk that someone might gain access to my account, or worse, that some friend or colleague who worked at Google might access my account and associate it with me. And these weren’t easy risks to take: being outed as transgender, for most of my adulthood, felt like it would be the end of my marriage, my family, my career, and my life. Privacy was the only tool I had to safely explore my identity, and yet, as much control as I was exerting over my privacy, the real control lie with Google, as I had no way of opting out of its pervasive tracking of my life online.
These two lives, one semi-private, and one aggressively private, are one example of why privacyprivacy: Control over information about one’s body and self. and securitysecurity: Efforts to ensure agreements about privacy. matter: they are how we protect ourselves from the release of information that might harm us and how we ensure that this protection can be trusted. In the rest of this chapter, we will define these two ideas and discuss the many ways in which they shape information systems and technology.

Privacy
One powerful conception of privacyprivacy: Control over information about one’s body and self. is as a form of control over others’ access to bodies, objects, places, and information 8 . Control is closely related to power, as we discussed it in Chapter 2 , in that control is a way of influencing the behavior and opportunities of others. For example, putting up a fence around one’s house or putting up window coverings are some ways to exert control over what information people have about what is happening in your home. This control is closely tied to autonomy, in that it leaves the person erecting the fence or closing the blinds in charge of when that power over others’ information is harnessed. This might mean, for example, that a person at home with blinds, even when the blinds are open, still has privacy, in the sense that they can control when to close them.
Of course, precisely what degree or kinds of control one has over their privacy, is often determined by culture 6 . Physical spaces, for example, come with very culturally determined notions of privacy. In our homes, for example, some might expect utmost control over who has access to our home, who can see inside of our home, and what information they can gain about the activities in our home, whereas others who live in more communal settings, might have no such expectations of privacy. In fact, there are even places in our home that are even more private in many cultures, such as a bathroom or bedroom, but those expectations may change when one has young children, who may not respect or even be aware of those expectations.

The culturally-determined nature of privacy is even more visible in public spaces. For example, when you’re walking through a public park, you might expect to be seen. But do you expect to be recognized? Do you expect the contents of your smartphone screen to be private? How much personal space do you expect between you and others in public spaces? Some scholars argue that the distinction between public and private is both a false dichotomy, but also more fundamentally culturally and individually determined than we often recognize 10 . Moreover, there are many ways in which being in “public” spaces is not a choice—one must often enter public spaces in order to secure basic needs, such as food, shelter, and social connection. If we accept privacy as a form of control, then, the very notion of public spaces is a challenge to that control.
While privacy in physical contexts is endlessly complex, privacy in digital spaces is even more complicated. What counts as private and who has control? Consider Facebook, for example, which aggressively gathers data on its users and surveils their activities online. Is Facebook a “public” place? What expectations does anyone have of privacy while using Facebook, or while browsing the web? And who is in control of one’s information, if it is indeed private? Facebook might argue that every user has consented to the terms of service, which in its latest versions, disclose the data gathered about your activities online. But one might counter that claim, arguing that consent at the time of account creation is insufficient for the ever evolving landscape of digital surveillance. For example, Facebook used to just track how I interacted with Facebook. Now it tracks where I am, how long I’m there, what products I browse on Amazon, whether I buy them, and then often sells that information to advertisers. I never consented to those forms of surveillance.

Much of the complexity of digital privacy can be seen by simply analyzing the scope of surveillance online. Returning to Facebook, for example, let us consider its Data Policy . At the time of this writing, here is the data that Facebook claims to collect:
- Everything we post on Facebook, including text, photos, and video
- Everything we view on Facebook and how long we view it
- People with whom we communicate in our contact books and email clients
- What device we’re using and how it’s connected to the internet
- Our mouse and touchscreen inputs
- Our location
- Our faces
- Any information stored by other websites in cookies, which could be anything
It then shares that information with others on Facebook, with advertisers, with researchers, with vendors, and with law enforcement. This shows that, unlike in most physical contexts, your digital privacy is largely under the control of web sites like Facebook, and the thousands of others you likely visit. Under the definition of privacy presented above, that is not privacy at all, since you have little control or autonomy in what is gathered or how it is used.
Many people have little desire for this control online, at least relative to what they gain, and relative to the trust they place in particular companies to keep their data private 5 . In fact, studies show that people across the world, regardless of culture, people note that privacy online is an important issue, but most users rarely make an effort to protect their privacy. This “privacy paradox” is largely explained that most people value what they gain from services for compromising their privacy, they trust companies to keep their information private, and they are not aware of concrete risks.
But for some, the risks are quite concrete. For example, some people suffer identity theft , in which someone maliciously steal one’s online identity to access bank accounts, take money, or commit crimes using one’s identity. In fact, this happens to an estimated 4% of people in the United States each year, suggesting that most people in their lifetimes will suffer identity theft 1 . Of course, the consequences can be worse than a loss of money and time. One modern form of privacy invasion online is doxxing , a complex form of online harassment that involves seeking private or personally identifying information about someone and widely distributing it through mass media without consent, typically with subtle or sometimes explicit calls to harm to a person 3 . One of the most notable was in 2014 during the GamerGate controversy, where several women game developers in the video game industry had personal information and nude photos exposed online without consent, accompanied with rape and death threats. Another complex form of privacy invasion is outing , when someone’s sexual or gender identity is disclosed without a victim’s consent, sometimes causing great harm to their physical safety and professional security 2 . And, even more consequential, U.S. police have aggressively begun using data surveillance to track the locations of crimes, using it to prioritize their future policing, reinforcing decades of racist policing against Black neighborhoods 7 . Therefore, while people in dominant groups may not feel at great risk to a loss of digital privacy, marginalized groups—for which power is often harnessed to oppress—may face greater risks from disclosure of their private information.
As we’ve noted, one critical difference between physical and online privacy is who is in control: online, it is typically private organizations, and not individuals, who decide what information is gathered, how it is used, and how it is shared. This is ultimately due to centralizationcentralization: Concentrating control over information or information systems to a small group of people. . In our homes, we have substantial control over what forms of privacy we can achieve. But we have little control over Facebook’s policies and platform, and even more importantly, there is only one Facebook, whose policies apply to everyone uniformly—all 2.7 billion of them. Therefore, even if a majority of users aren’t concerned with Facebook’s practices, the minority who are must live with whatever majority-serving design choices that Facebook makes.
At the heart of many issues around privacy, especially in digital contexts, is the notion of contextual integrityconextual integrity: The degree to which the context of information is preserved in its presentation, distribution, and interpretation. . Recall from Chapter 3 that the context of information is not just a separate description of the situations in which data was captured, but also details that intricately determine the meaning of data. For example, imagine someone posts a single sad face emoji in a tweet after election day in the United States. What that data means depends on the fact that the tweet occurred on that day and on the particular politics of the author. In fact, it might not have to do with the election at all. Context, therefore, is central in determining meaning. Contextual integrity, therefore, is about preserving the context in which data is gathered, and ensuring that the use of data is bound to the norms of that context 9 . With this concept, we can then discuss context collapse , in which data is used outside the bounds of its original context 11 . In these situations, data that was never intended for particular audiences or particular contexts is shared, violating norms, and causing miscommunication and misinterpretation. That sad face emoji, when viewed immediately after it was posted by people who know the author meant one thing, but several years later, after the author may have gained status and public visibility, might be interpreted to mean something else.
One of the most notable examples of context collapse was the Cambridge Analytica scandal, in which a British consulting firm used Facebook services to gather the likes and posts data of 50 million Facebook users, then used it to predict the users’ Big 5 personality type to target political ads during the 2016 U.S. election. This type of data had been used similarly before, most notably by the Obama campaign, but in that case, user consent was given. Cambridge Analytica never sought such consent. Surely, none of these 50 million Facebook users expected their data to be used to sway the outcome of the 2016 election, especially to shape what political advertisements they saw on the platform.
Cambridge Analytica is one example of a much broader economic phenomenon of surveillance capitalism 12 . This is an economic system that commodifies personal data for the purpose of profit making. The means to profit may be using that personal data to better target advertisements, as is the case for Google, Facebook, Amazon, and other large companies that accumulate user data for the purposes of profit. It may also be sold to others for unknown uses, as was the case for Cambridge Analytical. It may even be used by governments, as was the case with the Edward Snowden leaks , which revealed that the U.S. government used digital surveillance to track millions of American’s daily phone records, recording phone calls, harvesting email and instant messaging contact lists, email text, accessing Yahoo and Google data centers, and even collecting data by tapping undersea internet backbone network cables. “Capitalism” in this case, does not refer narrowly to private industry, but four trends: the drive to gather more data, the development of new forms of surveillance, the goal of personalizing services using this data, and the use of information technology infrastructure to conduct experiments on consumers and citizens.
Therefore, while privacy may seem simple, it is clearly not, especially in digital media. And yet the way that modern information technologies make it possible to capture data about our identities and activities at scale, without consent, and without recourse for when there is harm, demonstrates that privacy is only becoming more complex.

Security
In one sense, the only reason security matters is because privacy matters: we need security to restrict access to private information, to prevent the many harms that occur when private information is improperly disclosed. This is equally true for individuals who are trying to keep part of their identity or activities private, as well as for large corporations, in that they may have secrets about innovations or sales to keep private, while also having data about their customers that they might want to keep private. Access controlaccesscontrol: A system for making and enforcing promises about privacy. is a security concept essential to keeping promises about privacy.
There are two central concepts in access control. The first is authorizationauthorization: Granting permission to access private data. , which is about granting permission to gain access to some information. We grant authorization in many ways. We might physically provide some private information to someone we trust, such as form with our social security number, to a health care provider at a doctor’s office. Or, in a digital context, we might give permissions for specific individuals to view a document we’re storing in the cloud. Authorization is the fundamental mechanism of ensuring privacy, as it is how individuals and organizations control who gets information.

The second half of access control is authentication , which are ways of proving that some individual has authorization to access some information. In the example of the doctor’s office above, authentication might be subjective and fluid, grounded in a trust assessment about the legitimacy of the doctor and their staff and their commitments to use the private information only for certain purposes, such as filing health insurance reimbursements. Online, authentication may be much more objective and discrete, involving passwords or other secrets used to prove that a user is indeed the person associated with a particular user account.
While physical spaces are usually secured with physical means (e.g., proving your identity by showing a government issued ID), and digital spaces are usually secured through digital means (e.g., accessing data by providing data about your identity), digital security also requires physical security. For example, a password might be sufficient for accessing a document in the cloud. But one might also be able to break into a Google data center, find the hard drive that stores the document, and copy it. Therefore, security is necessarily a multilayered endeavor.

The first layer of security is data . Securing data typically involves encryptionencryption: Encoding data with a secret so that it can only be read by those who possess the secret. , which is the process of translating data from a known encoding to some unknown encoding. Encryption requires key (also known as a secret), and an algorithm (also known as a cipher) that transforms the data in a way that can only be undone with the key. Critically, it is always possible to decrypt data without the key by guessing the key, but if the key is large enough, it may take substantial computing power—and many years, decades, or longer—making some levels of encryption effectively impossible to crack. Some encryption is symmetric in that it uses the same key to encrypt and decrypt the data, meaning that all parties who want to read the data need the same key. This has the downside of requiring all parties to be trusted to safely store the key, keeping it private. One remedy to this is asymmetric encryption, where a public key was used to encrypt messages, but a separate private key was used to decrypt them. This is like a post office box: where it’s easy to put things in, but only person with the private key can take stuff out. Given these approaches, breaching data security simply means accessing and decrypting data, usually through “brute force” guessing of the key.
Encrypting data is not enough to secure data. The next layer of security required is in the operating systems of computers. This is the software that interfaces between hardware and applications, reading things from storage and displaying them to screen. Securing them requires operating systems that place strict controls over what data can and cannot be read from storage. For example, Apple and Google are well known for their iOS and Android sandboxing approaches, which disallow one application to read data from another without a user’s permission. This is what leads to so many request for permission dialogs. Breaching operating system security, therefore requires finding some way of overcoming these authorization restrictions by finding a vulnerability that the operating system developers have overlooked.
The applications running in an operating system also need to be secured. For example, it doesn’t matter if data is encrypted and an operating system sandboxes apps if the app is able to decrypt your data, read it, and then send it to a malicious entity, decrypted. Securing software, much like securing operating system, requires ensuring that private data is only ever accessed by those with authorization. This is where iOS and Android often differ: because there is only one iOS app store, and Apple controls it, Apple is able to review the implementation of all apps, verifying that they comply with Apple’s privacy policy and testing for security vulnerabilities. In contrast, there are many ways to obtain Android apps, only some of which provide these privacy and security guarantees. Breaching software simply requires finding a vulnerability that developers overlooked, and using it to access private data.
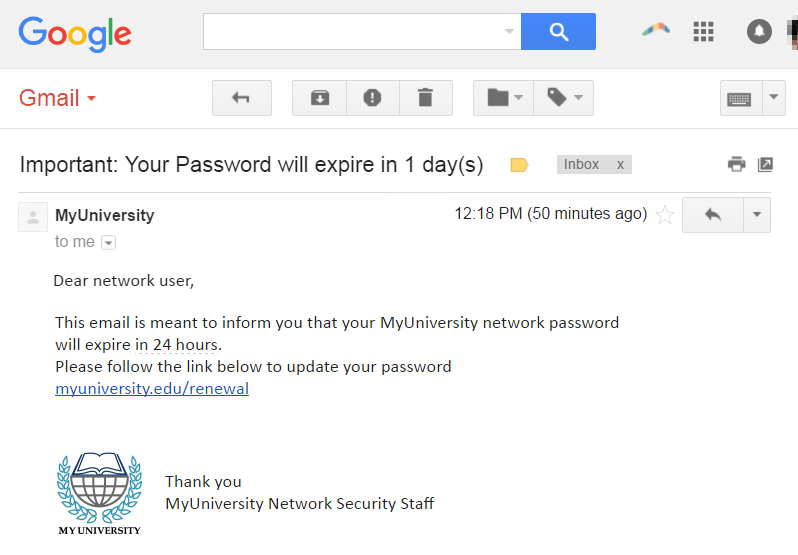
Securing data and software alone is not sufficient; people must follow security best practices. This means not sharing passwords and keeping encryption keys private. If users disclose these things, no amount of security in data or code will protect the data. One of the most common ways to breach people’s security practices is to trick them into disclosing authorization secrets. Known as phishing , this typically involves sending an email or message to a user that appears trustworthy and official, asking someone to log in to the website to view a message. However, the links in these phishing emails instead go to a malicious site and record the password you enter, giving the identity thief access to your account. Practices like two-factor authentication—using a password and a confirmation on your mobile device—can reduce the feasibility of phishing. Other approaches to “breaching” people can be more aggressive, including blackmail, to compel someone to disclose secrets by threat.
Even if all of the other layers are secure, organizational policy can have vulnerabilities too. For example, if certain staff have access to encryption keys, and become disgruntled, they may disclose the keys. Or, staff who hold secrets might inadvertently disclose them, accidentally copying them to a networked home backup of their computer, which may not be as secure as the networks at work.
All of these layers of security, and the many ways that they can be breached, may make security feel hopeless. Moreover, security can impose tradeoffs on convenience, forcing us to remember passwords, locking us out of accounts when we forget them. And all of these challenges and disruptions, at best, mean that data isn’t breached, and privacy is preserved. This can seem especially inconvenient if one isn’t concerned about preserving privacy, especially when breaches are infrequent and seem inconsequential.
Of course, it may be that the true magnitude of potential consequence of data breaches is only beginning to come clear. In 2020, for example, the U.S. Government, in cooperation with private industry, discovered that the Russian government had exploited the software update mechanism of a widely used IT Management solution called SolarWinds . Using this exploit, the Russian government gained access to the private data and activities of tens of thousands of government and private organizations worldwide, including the U.S. Department of Commerce, U.S. Department of Energy, and the U.S. Treasury. In fact, the breach was so covert, it’s not yet clear what the consequences were: the Russian government may have identified the identity of U.S. spies, it may have interfered with elections, it may have gained access to the operations of the U.S. electrical grid, and more. There are good reasons why this data was private; Russia might, at any point, exploit that data for power, or worse, to cause physical harm.
Other emerging trends such as ransomware 4 have concrete consequences. This is a class of software that exploits vulnerabilities one or more of the layers above to gain access to private data. Most ransomware restricts its owner’s access to data, or even moves the data to a different location, and threatens to delete the data if the organization does not pay a ransom fee. For many organizations, it is often easier to simply pay the attackers and recover their data than to recreate it.
Privacy may not matter to everyone, but it does matter to some. And in our increasingly centralized digital age, what control you demand over your privacy shapes what control other people have. Therefore, secure your data by following these best practices:
- Use a unique password for every account
- Use two-factor authentication wherever possible
- Use a password manager to store and encrypt your passwords
- Assume every email requesting a login is a phishing attack, verifying URL credibility before clicking them
- Always install software updates promptly to ensure vulnerabilities are patched
- Ensure that websites you visit use the HTTPS protocol, encrypting data you send and receive
- Read the privacy policies of applications you use, and if you can imagine a way that the the data gathered might harm you or someone else. Demand that it not be gathered or refuse to use the product.
Is all of this is inconvenient? Yes. But ensuring your digital privacy not only protects you, but also others, especially those vulnerable to exploitation, harassment, violence, and other forms of harm.
Podcasts
Want to learn more about privacy and security? Consider these podcasts, which engage some of the many new challenges that digital privacy and security pose on society:
- Right to be Forgotten, Radiolab . This podcast discusses the many challenges of archiving private data, and how the context of that data can shift over time, causing new harm.
- What Happens in Vegas... is Captured on Camera, In Machines We Trust . Discusses the increasing use of facial recognition in police surveillance and the lack of transparency, oversight, and policy that has led to its abuse.
- What Cops Are Doing With Your DNA, What Next: TBD, Slate . Discusses the increasing use of open-source DNA platforms to solve crimes, and the problematic ways in which people who never share their DNA still might be implicated in crimes.
- Who is Hacking the U.S. Economy?, The Daily . Discusses cyberattacks, ransomware, and the adversarial thinking required to prevent and respond to them.
- Why Apple is About to Search Your Files, The Daily . Discusses the complex tensions between privacy, safety, and law in Apple’s child sexual abuse survellance.
References
-
Keith B. Anderson, Erik Durbin, and Michael A. Salinger (2008). Identity Theft. Journal of Economic Perspectives.
-
Gorden A. Babst (2018). Privacy and Outing. Core Concepts and Contemporary Issues in Privacy.
-
Stine Eckert, Jade Metzger-Riftkin (2020). Doxxing. The International Encyclopedia of Gender, Media, and Communication.
-
Alexandre Gazet (2010). Comparative analysis of various ransomware virii. Journal in Computer Virology.
-
Nina Gerber, Paul Gerber, Melanie Volkamer (2018). Explaining the privacy paradox: A systematic review of literature investigating privacy attitude and behavior. Computers & Security.
-
Helena Leino-Kilpi, Maritta Välimäki, Theo Dassen, Maria Gasull, Chryssoula Lemonidou, Anne Scott, and Marianne Arndt (2001). Privacy: a review of the literature. International Journal of Nursing Studies.
-
Charleton D. McIlwain (2019). Black Software: The Internet and Racial Justice, from the AfroNet to Black Lives Matter. Oxford University Press.
-
Adam D. Moore (2008). Defining privacy. Journal of Social Philosophy.
-
Helen Nissenbaum (2004). Privacy as contextual integrity. Washington Law Review.
-
Helen Nissenbaum (1998). Protecting Privacy in an Information Age: The Problem of Privacy in Public. Law and Philosphy.
-
Jessica Vitak (2012). The impact of context collapse and privacy on social network site disclosures. Journal of Broadcasting & Electronic Media.
-
Shoshana Zuboff (2019). The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power. Public Affairs.

Managing information
By high school, most of my hobbies were on a computer. I liked creating art in Microsoft Paint; I liked editing sounds. And my emerging hobby of making simple games in the BASIC programming language, aided by my stack of 3-2-1 Contact magazines and their print tutorials, meant that I always had a few source files I was working on. All of my data fit onto a single 1.44 MB 3.5“ floppy disk, which I carried around in my backpack and inserted into the home and school computers whenever I had some time to play. Inspired by my mother’s love of paper planners, I kept it neatly organized, with folders for each project, and text file with a list of to do’s. With no email and no internet, the entirety of my data archive was less than a megabyte. Managing my projects meant making sure I didn’t drop my floppy disk in a puddle or crush it in my backpack.
Much later, when I was Chief Technology Officer (CTO) of a startup I had co-founded, my information management problems were much more complex. I had a team of six developers and one designer to supervise; the rest of the company had a half dozen sales, marketing, and business development people, in addition to our CEO. We had hundreds of critical internal documents to support engineering, marketing, and sales, and with a growing team, we had a desperate need for for onboarding materials. We had a web scale service automatically answering the questions of hundreds of thousands of customer questions on our customer’s websites, and our customers had endless questions about the patterns in that data. Our sales team needed to manage data about customer interactions, our marketing team needed to manage data about ad campaigns, and our engineering team needed to manage data about the availability and reliability of our 24/7 web services, especially after the half dozen releases each day. And atop all of this, our CEO needed to create elaborate quarterly board meeting presentations that drew upon all of this data, summarizing our sales, marketing, and engineering progress. Our critical data spanned Salesforce, Marketo, GitHub, New Relic, and a dozen Google services. Our success as a business depended on our ability to organize, manage, and learn from that data to make strategic decisions. (And I won’t pretend we succeeded).
Both of these stories are information managementinformation management: The systematic and strategic collection, storage, retrieval, and analysis of information for some purpose. stories, one personal, and one organizational. And they both stem from the observation we’ve made throughout this book that information has value. The critical difference between the two, however, was a matter of scale. When information in scarce, there’s little need for organization or management. But when it is abundant—especially when it is too abundant to fully comprehend—we need to manage it to get value out of it. In the rest of this chapter, we’ll discuss some of these problems of information management, both personal, and organizational, and connect these ideas to the many challenges we’ve raised in prior chapters.

The economics of attention
What determines when information management becomes necessary? The answer to this question goes back to some formative work from Herb Simon, who said in his book Designing Organizations for an Information-rich World 8 :
In an information-rich world, the wealth of information means a dearth of something else: a scarcity of whatever it is that information consumes. What information consumes is rather obvious: it consumes the attention of its recipients. Hence a wealth of information creates a poverty of attention and a need to allocate that attention efficiently among the overabundance of information sources that might consume it.
Simon went on to frame the problem of attention allocation as an economic and management one, noting that many at the time had incorrectly framed organizational problems as one of a scarcity of information, rather than one of a scarcity of attention. Instead, he argued that in contexts of information abundance, the key problem is figuring what information exists, who needs to know it and when, and archiving it in ways that it can be accessed by those people when necessary.
These ideas of identifying and managing information, described in Simon’s book Administrative Behavior 6 , laid the foundation for problems of information management for the coming decades. They shaped perspectives on management in business. They explained problems of advertising, in which consumer attention was the scarce resource. And they became the foundation of even personal information management problems, such as e-mail spam and growing archives of personal photos.

Personal information management
While most of Simon’s ideas were applied to organizations such for-profit businesses and government institutions, they also shaped a body of work on personal information management problems 9 . The scope of problems mirrors that of organizations: how do individuals acquire, organize, maintain, retrieve, and use personal data, such as documents, web pages, emails, to do lists, calendars, photos, and more? The story at the beginning of this chapter illustrated one practice for managing personal information, but management practices are as varied as people’s lives are diverse.
There are many kinds of information that can be considered “personal”:
- Information that people keep, whether stored on paper or in digital form. This includes critical document such as licenses, birth certificates, and passports, but also personally meaningful documents like mementos, letters, and other information-carrying documents.
- Information about a person but kept by others. This includes things like health or student records and histories of tax or bill payments.
- Information directed towards a person, such as emails, social media messages, and advertisements.
For all of the information above, importance may vary. For example, most of us have some critical information (e.g., a birth certificate proving citizenship, or some memento that reminds us of a lost loved one). Other information might be useless to us (e.g., Google’s records of which ads they have shown us, or spam we received long ago that still sits in our email archive). This variation in importance, and the shifting degree to which information is important, is what creates problems of personal information management.
Some of these are problems of maintenance and organization . For example, some people might store their personal data in haphazard, disordered ways, with no particular scheme, no habits of decluttering 4 . Maybe this describes you. If most of that information is unimportant, it really doesn’t matter if someone never engages in these activities. But the moment some of that information becomes important, other activities such as retrieval become more challenging: for example, if there’s no consistent place to store your passport, you might spend all day looking for it before a flight. Others may go to the opposite extreme of organization, but with little benefit relative to the effort 12 . For example, my mother rents her basement on Airbnb, and has an elaborate print guide for her guests that lists all of the restaurants in her neighborhood with her opinions and recommendations. I’m sure some guests review the guide, but most probably rely on restaurant review sites online.
Some problems are of managing privacy , security , and sharing . For example, in the United States, most citizens have Social Security cards. This is sensitive information, since it is often used to access financial resources or government services. Every individual has the problem of how to secure that private information, and whom to share it with. But not every person has practices that actually secure it 13 . The lack of personal practices for privacy and security can have great consequences, such as identity theft when people unknowingly disclose their private information, or even being deported, if someone is legally in a country but does not have the documentation to prove it.
Most problems, of course, are of retrieving and using personal information. Where is that photo of my grandmother when I was a child? Where is that bill I was supposed to pay? Where is my birth certificate? These problems of personal information retrieval are exacerbated by the problems above: if personal information is not maintained, organized, archived, and secured, finding information will be more difficult, and using it may be harder as there may be no metadata to help remind someone of the context in which it was gathered. This can create entirely new problems of re-finding information 10 , where some information that was deemed important was once found, but because of a lack of maintenance and organization, it remains difficult to recover, and potentially lost forever.
All of these challenges are the same ones that archivists in libraries and museums face 1 , except that most individuals do not have training in archiving. This leads to many diverse, emergent practices. Some people are “packrats”, saving everything; others ruthlessly cull kept information from their lives. Some create elaborate organization schemes with rich metadata, often going beyond the level of order actually needed; others spend no effort organizing, trusting that the need to retrieve will be rare, or that they can rely on automated tools such as search. These practices evolve over time as people experience information needs that their current practices do not support. None of these practices are necessarily better or worse, but each has tradeoffs within the context of an individuals’ personal information needs over time.

Organizational information management
While problems of information management are universal at some level, they can feel quite different at different scales. Managing personal information might feel like a chore, but managing organizational information might be the difference between an organization’s success or failure. For a for-profit business, the right information can be the difference between a profit and loss; for a not-for profit organization, such as the American Cancer Society , it might be the difference between life and death for cancer patients worldwide, slowing research and advocacy.
It is important to distinguish here between “organization” as it is used on the context of management, and “organization” as we are using it here. The first usage concerns the ways in which we create order around data and metadata to facilitate searching and browsing. The second usage concerns groups of people, and the patterns and processes of communication in which they engage to achieve shared goals. Confusingly, then, organizations create value from information by organizing it.
What value might organizations get from organizing information? In Administrative Behavior 6 , Simon argued that information is for decisions . In the book, he examined management decisions by invoking the ideas in his prior work of bounded rationality and satisficing 7 , demonstrating that decision makers in organizations have limits on the amount of information they can and will examine and use to make choices. He further argued that these limits are shaped not only by inherent limits of human cognition, but also social factors such as training, authority, loyalty. Therefore, Simon viewed the problem of information management as helping decision makers get the right information and the right time, while accounting for the many social and political factors that encourage or limit decisions.
After Simon’s book, and the role of computers in expanding the amount of information available to organizations, the field of information management began to emerge to try to solve the problems that Simon framed. Several further challenges emerged 2 :
- Where does data come from? This includes all of the challenges of creating explicit systems to capture data and metadata. Consider Amazon, for example, which aggressively tracks browsing and use of its retail services; it has elaborate teams responsible for instrumenting web pages and mobile apps to monitor every click, tap, and scroll on every product. Managing that data collection is its own complex enterprise, intersecting with methods in software engineering, data science, and human-computer interaction.
- Where is data stored? This includes all of the problems of data warehousing 5 , including data schemas to capture metadata, databases to implement those schema, backups, real-time data delivery, and likely data centers that can scale to archive that data. At Amazon, this means creating web-scale, high performance data storage to track the activity of hundreds of millions of shoppers in real-time.
- Who is responsible for data? Someone in an organization needs to be in charge of ensuring data quality, reliability, availability, and legal compliance. Because data is valuable, they also need to be responsible for data continuity, in the case of disasters like earthquakes, fires, floods, power outages, or network outages. At Amazon, there are not only people at Amazon Web Services who take on some of these responsibilities, but also people in the Amazon retail division who ensure that the data being stored at AWS is the data Amazon retail needs.
Managing information in an organization means answering these questions.
As information management emerged, so did the role of Chief Information Officer 3 , as the executive in an organization ultimately responsible for creating information systems that serve the strategic goals of the organization. They play critical role in interfacing between more technical roles with expertise in technology and the rest of the company, typically facing inward to ensure that the organization’s use of data is aligned with the operations of the organization. This might mean making choices about which technology to use (e.g., Google G Suite or Sharepoint), which hardware to buy (e.g., PC or Mac), how to comply with legal requirements (e.g., FERPA, HIPPA, GDPR), and what custom information systems to create in order to achieve the organization’s goals, now more broadly known as business intelligence 11 . This latter task might involve creating data-driven dashboards and reports that help the organization monitor its progress toward goals.
As digital information technology makes it easier than ever to gather data, our personal and professional lives will pose ever greater challenges of managing information, and our attention on it. Of course, underlying all of these issues of management are also the same moral and ethical questions we have discussed in prior chapters. What responsibility do individuals and organizations have as they gather and analyze data? What responsibilities do individuals and organizations have to prevent harm from data? How do we ensure that how we encode and archive data is respectful of the rich diversity of human identity and experience? In what moral circumstances should we delete data or change archives? These many challenges are at the heart of our decisions about what to do with the data we gather, and decisions about whether to gather it at all.
References
-
Peter Buneman, Sanjeev Khanna, Keishi Tajima, and Wang-Chiew Tan (2004). Archiving scientific data. ACM Transactions on Database Systems.
-
Chun Wei Choo (2002). Information Management for the Intelligent Organization. Information Today.
-
Varun Grover, Seung-Ryul Jeong, William J. Kettinger, and Choong C. Lee (1993). The chief information officer: A study of managerial roles. Journal of Management Information Systems.
-
Thomas W. Malone (1983). How do people organize their desks? Implications for the design of office information systems. ACM Transactions on Information Systems.
-
Paulraj Ponniah (2011). Data warehousing fundamentals for IT professionals. John Wiley & Sons.
-
Herbert A. Simon (1966). Administrative Behavior. Free Press.
-
Herbert A. Simon (1963). The Sciences of the Artificial. MIT Press.
-
Herbert A. Simon (1971). Designing Organizations for an Information-rich World. Johns Hopkins University Press.
-
Jaime Teevan, William P. Jones (2011). Personal Information Management. University of Washington Press.
-
Sarah K. Tyler, Jaime Teevan (2010). Large scale query log analysis of re-finding. ACM International Conference on Web Search and Data Mining.
-
Hugh J. Watson, Barbara H. Wixom (2007). The current state of business intelligence. IEEE Computer.
-
Steve Whittaker, Tara Matthews, Julian Cerruti, Hernan Badenes, and John Tang (2011). Am I wasting my time organizing email? A study of email refinding. ACM Conference on Human Factors in Computing Systems.
-
Gizem Öğütçü, Özlem Müge Testik, and Oumout Chouseinoglou (2016). Analysis of personal information security behavior and awareness. Computers & Security.

Regulating information
Gender is a strange, fickle kind of information. Those unfamiliar with the science equate it with “biological sex,” and yet we have long known that gender and sex are two different things, and sex is not binary, but richly diverse along numerous genetic, developmental, and hormonal dimensions 3 . Others accept that gender is largely a social construction 6 . In my case, for example, all it took was a year of hormones and some change in my hair and clothing for most people to see and treat me as the woman that I am. All of these bits of information—my genes, how they were expressed, how my brain developed, the identity I developed, and how people see me in public based on what I wear and how much fat is under my skin—add up to one aggregate piece of information: my perceived gender. And that information, because of the social institutions of gender, determines much of my experience in the world: how I am treated, whether I am believed, where I can safely pee.
And yet, as much as I want the right to define my gender not by my “biology” and not by how am I seen, but who I am , the public regularly engages in debate about whether I deserve that right. For example, in June 2020, Health and Human Services (HHS) decided to change Section 1557 of its anti-discrimination policy, removing gender from the list of protected aspects of identity, and defining gender as “biological sex.” The implication is that the government would decide, not me, whether I was a man or a woman, and it would decide that based on “biology”. Of course, the government has no intent of subjecting me to blood draws and chromosomal analysis in order for me to have rights to bring anti-discrimination lawsuits against healthcare providers (and it wouldn’t help anyway, since there are no tests that definitively establish binary sex, because binary indicators do not exist.) Instead, HHS proposed to judge biological sex by other information: a person’s height, the shape of their forehead, or their lack of a bust. Defining gender in these ways, of course, subjects all people, not just transgender women or women in general, to discrimination on the basis of how their bodies are perceived.
Who, then, gets to decide what information is used to define gender, and how that information is used to determine someone’s rights? This is just one of many questions about information that concern ethics, policy, law, and power, all of which are ways different ways of reasoning about how we regulate information in society. In the rest of this chapter, we will define some of these ideas about policy and regulation, and then discuss many of the modern ethical questions that arise around information.

What are ethics, policy, law, and regulation?
While this book cannot do justice to ideas that have spanned centuries of philosophy and scholarship 9 , it is important to provide some basic foundations about these concepts, and where they appear in society.
To begin, ethicsethics: Systems of moral and questions and principles about human behavior. concerns moral questions and principles about people’s behavior in society. Of the four words were are addressing here, this is the broadest, as ethics are at the foundation of many kinds of decisions. Individuals engage information ethics when they make choices to share or not share information (e.g., should I report that this student cheated? ). Groups make decisions about how to act together (e.g., should we harass this person on Twitter for their beliefs? ). Organizations such as private for and not-for profit businesses make ethical decisions about how employees professional and personal lives interact (e.g., Should employees be allowed to use their own personal devices? ). And governments made decisions about information and power (e.g., Who owns tweets? ). Information ethics is concerned with the subset of moral questions that concern information, though it is hard to fully divorce information from ethical considerations, and so that scope is quite broad. For example, consider questions seemingly separate from information, such as capital punishment: part of an argument that justifies its morality is one that relies on certainty of guilt and confidence in predictions about a convicted person’s future behavior. Those are inherently informational concerns, and so capital punishment is an information ethics issue.
Policypolicy: Rules that restrict human behavior to some end. is broadly concerned with defining rules that enact a particular ethical position. For example, for the parenthetical questions above, one might define policies that say 1) yes, report all cheating, 2) no, never harass people for their beliefs, unless they are threatening physical harm, 3) yes, allow employees to use their own devices, but require them to follow security procedures, and 4) Twitter owns tweets because they said they did in the terms of service that customers agreed to. Policies are, in essence, just ideas about how to practically implement ethical positions. They may or may not be enforced, they may or may not be morally sound, and you may or may not agree with them. They are just a tool for operationalizing moral positions.
Some policies become lawlaw: Policies enforced by governments. , when they are written into legal language and passed by elected officials in governed society. In a society defined by law, laws are essentially policies that are enforced with the full weight of law enforcement. Decisions about what policy ideas become law are inherently political, in that they are shaped by tensions between different ethical positions and tensions, which are resolved through systems of political power. For example, one could imagine a more ruthless society passing a law that required mandatory reporting of cheating in educational contexts. What might have been an unenforced policy guideline in a school would then shift to becoming a requirement with consequences.
Regulationsregulations: Interpretations of law that enable enforcement. are rules that interpret law, usually created by those charged with implementing and enforcing laws. For example, suppose the law requiring mandatory reporting about cheating did not say how to monitor for failures to reporting. It might be up to a ministry or department of education to define how that monitoring might occur, such as defining a quarterly survey that all students have to fill out anonymously reporting any observed cheating and the names of the offenders. Regulations flow from laws, laws from policies, and policies from ethics.

Privacy
One of the most active areas of policy and lawmaking has been privacy. Privacy, at least in U.S. constitutional law, as muddled origins. For example, the 4th amendment alludes to it, stating:
The right of the people to be secure in their persons, houses, papers, and effects, against unreasonable searches and seizures, shall not be violated, and no Warrants shall issue, but upon probable cause, supported by Oath or affirmation, and particularly describing the place to be searched, and the persons or things to be seized.
This amendment is often interpreted as a right to privacy, though there is considerable debate about the meaning of the words “unreasonable” and “probable”; later decisions by the U.S. Supreme Court found that the Constitution grants a right to privacy against governmental intrusion, but not necessarily intrusion by other parties.
Many governments, lacking explicit privacy rights, have passed laws granting them more explicitly. For example, in 1974, the U.S. government passed the Family Educational Rights and Privacy Act (FERPA), which gives parents access to their children’s educational records up to the age of 18, but also protects all people’s educational records, regardless of age, from disclosure without consent. This policy, of course, had unintended consequences: for example, it implicitly disallows things like peer grading, and only vaguely defines who can have access to educational records within an educational institution. FERPA strongly shapes the information systems of schools, colleges, and universities, as it requires sophisticated mechanisms for securing educational records and tracking disclosure consents to prevent lawsuits.
More than two decades later in 1996, the U.S. government passed a similar privacy law, the Health Insurance Portability and Accountability Act (HIPPA), which includes a privacy rule that disallows the disclosure of “protected health information” without patient consent. Just as with FERPA, HIPPA reshaped the information systems used in U.S. health 2 . For example, medical records, which were largely paper prior to the law, were typically stored in unlocked file cabinets in offices and regularly faxed between providers. HIPPA required much more strict control over exactly which providers had access to records, incentivizing the adoption of electronic medical records.
Just a few years later in 2000, the U.S. government passed COPPA, which requires parent or guardian consent to gather personal information about children under 13 years of age. Many organizations had been gathering such information without such consent, and did not know how to seek and document consent, and violated the law for years. Eventually, after several regulatory clarifications by the Federal Trade Commission, companies had clear guidelines: they were required to post privacy policies, provide notice to parents of data collection, obtain verifiable parental consent, provide ways for parents to review data collected, secure the data, and delete the data once it is no longer necessary. Because getting “verifiable” consent was so difficult, most websites responded to these rules by asking for a user’s birthdate, and disabling their account if they were under 13 7 , leading many youth to lie about their age in order to get access to web services.

Perhaps the most sweeping privacy law has been the European Union’s General Data Protection Regulation (GDPR), passed in 2016. It requires that:
- Data collection about individuals must be lawful, fair, and transparent;
- The purpose of data collection must be declared and only used for that purpose;
- The minimum data necessary should be gathered for the purpose;
- Data about individual must be kept accurate;
- Data may only be stored while it is needed for the purpose;
- Data must be secured and confidential; and
- Organizations must obtain unambiguous, freely given, specific, informed, documented and revokable consent for the data collection.
This law sent strong waves through the software industry, requiring it to spend years re-engineering its software to be compliant 1 . Because GDPR only applied to EU citizens, some U.S. states have sought to replicate the law. California was the first, passing the California Consumer Privacy ACT (CCPA) in 2018, mirroring many of the rights in GDPR.
Privacy law, of course, has still been narrow in scope, neglecting to address many of the most challenging ethical questions about digital data collection. For example, if a company gathers information about you through legal means, and that information is doing you harm, is it responsible for that harm? Many have begun to imagine “right to be forgotten” laws 5,8 , that would give people rights to demand that particular information about them be deleted, or at least kept private. Or, if an organization suffers a data breach, disclosing private information that does harm, are they responsible for the harm? Currently, the only consequence that most companies in most countries face is a loss of customer trust.

Property
While information privacy laws have received much attention, information property laws have long been encoded into law. Consider, for example, U.S. copyright law, which was first established in 1790. It deems that any creator or inventor of any writing, work, or discovery, gets exclusive rights to their creations, whether literary, musical, dramatic, pictorial, graphic, auditory, or more. This means that, without stating otherwise, anything that you write down, including a sentence on a piece of paper, is automatically copyrighted, and that no one else can use it without your permission. Of course, if they did, you probably would not sue them, but you could—especially if it was a song lyric, an icon, or solution to a hard programming problem, all of which might have some value worth protecting. This law effectively makes information, in particular embodiments, property. This law, of course, has had many unintended consequences, especially as computers have made it easier to copy data. For example, is sampling music in a song a copyright violation? Is reusing some source code for a commonly known algorithm a copyright violation? Does editing a copyrighted image create a new image? Most of these matters have yet to be settled in U.S. or globally.
Trademarks are a closely related law, which allow organizations to claim words, phrases, and logos as exclusive property. The goal of the law is to prevent confusion about the producers of goods and services, but it includes provisions to prevent trademarks for names that are offensive in nature. This law leads to many fascinating questions about names, and who gets rights to them. For example, Simon Tam, a Chinese-American man started a band, and decided to call it The Slants , to reclaim the racial slur. When he applied for a trademark, however, the trademark office declined his application because it was deemed offensive, as it was disparaging to people of Asian decent. The case went to the Supreme Court, which eventually decided that the first amendment promise of free speech overrode the trademark law.

Speech
As we have noted throughout this book, information has great potential for harm. Information can shame, humiliate, intimidate, and scare; it can also lead people to be harassed, attacked, and even killed. When such information is shared, especially on social media platforms, who is responsible for that harm, if anyone?
In the United States, some of these situations have long been covered by libel, slander, and defamation laws, which carve out exceptions to free speech to account for harm. Defamation in this case, is the general term covering anything that harms someone’s reputation; it is libel when it is written and published, and slander when it is spoken. Generally, defamation cases must demonstrate that someone made a statement, that the statement was published, that the statement caused harm to reputation, that the statement was false, and that the type of statement made was not protected in some other way (e.g., it is legal to slander in courts of law).
Prior to the internet, it was hard for acts of defamation to reach scale. Mass media such as newspapers were the closest, where early newspapers might write libelous stories, and be sued by the subject of the news article. But with the internet, there are many new kinds of defamation possible, as well as many things that go beyond defamation to harassment. For example, cyberbullying 4 extends bullying by bringing into virtual domains, allowing bullying to occur at all times, even outside of school. Dogpiling extents interpersonal harassment to scale, leading a large number of people to quickly fill comment threads and private messaging with criticisms and insults toward a person. Doxxing , as we discussed in Chapter 8 , extends interpersonal threats to scale, disclosing private information with the intent to psychologically harm or threaten someone. (As a trans person on Twitter, I suffer all of these forms of speech-based harassment when I write about trans rights online). Defamation laws have little to say about these new phenomena, since those laws narrowly concern reputation, and not mental wellbeing.
Defamation laws also have little to say about what responsibility social media platforms have in amplifying these forms of harassment. There are, however, laws that explicitly state that such platforms are not responsible. Section 230 of the Communications Decency Act (CDA), for example, says:
No provider or user of an interactive computer service shall be treated as the publisher or speaker of any information provided by another information content provider.
This protects social media platforms from any culpability in any of the harm that occurs on their platforms, defamation or otherwise. Because of the numerous concerns about online harassment by consumers, many companies have begun to attempt to self-regulate. For example, the Global Alliance for Responsible Media framework defines several categories of harmful content, and attempts to develop actions, processes, and protocols for protecting brands (yes, brands, not consumers). Similarly, in 2020, Facebook launched a Supreme Court to resolve free speech disputes about content posted on its platform.
All of these concerns about defamation, harassment, and harm, are fundamentally about how free speech should be, how responsible people should be for what they say and write, and how responsible platforms should be when they amplify that speech.

Identity
We began this chapter by discussing the contested nature of gender identity as information, and how policy, law, and regulation are being used to define on what basis individual rights are protected. That was just one example of a much broader set of questions about information about our identities. For example, when do we have a right to change our names? Do we have a right to change the sex and gender markers on our government identification, such as birth certificates, driver’s licenses, and passports? When can our identity be used to decide which sports teams we can play on, which restrooms we can use, and whether we can serve in the military, and who we can marry?
Gender, of course, is not the only contested aspect of our identities, and it intersects with other aspects of identity 10 . Similar issues surround race, especially Native American, American Indian, and Indigenous identities, which often intersect in complex ways with tribal sovereignty. This is closely related to citizenship, which has an ever evolving set of rules, norms, and policies that shape who is allowed into countries, who is granted citizenship, and what rights come with that citizenship. All of these issues of identity are fundamentally information policy issues, in that names, gender markers, racial categories, and proof of citizenship are all conveyed through documents that encode this information.
In many countries, the ethics, policy, law, and regulation around gender, race, citizenship have been less focused on granting rights and more about taking them away. The U.S. Constitution itself only counted 3/5ths of each enslaved Black person in determining representation in the House. Women did not have the right to vote until 1920, long after the end to U.S. slavery. Most transgender people in the world, including most in the U.S., still do not have rights to change their legal name and gender without proof of surgery that many trans people do not want or need. What progress has been made came after years of activism, violence, and eventually law: the Emancipation Proclamation ended slavery after civil war; the 19th Amendment granted women the right to vote after one hundred years of activism; the Civil Rights Act of 1964 outlawed discrimination on the basis of race, color, religion, sex, national origin, and sexual orientation only after years of anti-Black violence; and the Obergefell (2014) and Bostock (2020) cases granted LGBTQ people rights to marriage and rights to sue for employment discrimination. All of these hard won rights were fundamentally about information and power, ensuring everyone has the same rights, regardless of the information conveyed by their skin, voice, dress, or other aspects of their appearance or behavior.
These four areas of information ethics are of course just some of many information ethics issues society. The diversity of policy, legal, and regulatory progress in each demonstrates that the importance of moral questions about information does not always correspond to the attention that society gives to encoding policy ideas about morality into law. This all but guarantees that as information technology industries continue to reshape society according to capitalist priorities, we will continue to to engage in moral debates about whether those values are the values we want to shape society, and what laws we might need to reprioritize those values.
Podcasts
Interested in learning more about information ethics, policy, and regulation? Consider these podcasts, which investigate current events:
- Who Owns the Future? On the Media . Discusses the U.S. Justice departments’ anti-trust case against Facebook.
- Unspeakable Trademark, Planet Money . Discusses what rights people have to trademark names and how these rights intersect with culture and identity.
- The High Court of Facebook, The Gist . Discusses Facebook’s long-demanded formation of an independent body for making censorship decisions.
- A Vast Web of Vengence, The Daily, NY Times . Discusses a specific case of online harassment and defamation, the harm that came from it, and how the law shielded companies from responsibility for taking the defamatory content down.
- The Facebook Whistle-Blower Testifies, The Daily, NY Times . Explores the impact of the testimony on possible regulation.
References
-
Jan Philipp Albrecht (2016). How the GDPR will change the world. European Data Portection Law Review.
-
David Baumer, Julia Brande Earp, and Fay Cobb Payton (2000). Privacy of medical records: IT implications of HIPAA. ACM SIGCAS Computers and Society.
-
Anne Fausto-Sterling (2000). Sexing the Body: Gender Politics and the Construction of Sexuality. Basic Books.
-
Dorothy Wunmi Grigg (2010). Cyber-aggression: Definition and concept of cyberbullying. Australian Journal of Guidance and Counselling.
-
Paulan Korenhof, Bert-Jaap Koops (2014). Identity construction and the right to be forgotten: the case of gender identity. The Ethics of Memory in a Digital Age.
-
Patricia Yancey Martin (2004). Gender as social institution. Social Forces.
-
Irwin Reyes, Primal Wijesekera, Joel Reardon, Amit Elazari Bar On, Abbas Razaghpanah, Narseo Vallina-Rodriguez, and Serge Egelman (2018). "Won’t somebody think of the children?" Examining COPPA compliance at scale. Privacy Enhancing Technologies.
-
Jeffrey Rosen (2011). The right to be forgotten. Stanford Law Review.
-
Michael J. Sandel (2010). Justice: What's the right thing to do?. Macmillan.
-
Riley C. Snorton (2017). Black on both sides: A racial history of trans identity. University of Minnesota Press.

Designing information
I have what most transgender people call a deadname : the name I was given at birth that I have since replaced with a chosen name. Some trans people, including myself, find deadnames to be a painful piece of information, reminding us a past life and identity associated with fear and shame. And so changing it can bring the opposite of those things: confidence, affirmation, and pride.
Unfortunately, accessing and modifying records of one’s name is rarely easily. To change my legal name, I needed to pay the city of Seattle $201.50, fill out an elaborate form, and participate in a hearing in front of a judge before a received a certified court order. To change my Social Security information, I had to wait in a Social Security office for four hours for a five minute appointment, and bring every piece of documented evidence of my citizenship, along with the court order, and then wait six weeks for confirmation that it had been changed. My driver’s license took multiple trips, each time to address some missing piece of information in a poorly explained process. And then, because I have relatively organized password manager, I spent about 100 hours visiting the websites of 700 companies that had my name, or encoded my name in my email address. Some refused to change it (e.g., Google, Best Buy, academic publishers); some refused to change it without me mailing an original court order (e.g., government institutions); some refused to change it without a faxed copy of the court order and my new ID (e.g., financial institutions); some required hour long phone calls with customer support with many people asking to speak to my husband for approval; some made it nearly impossible to find where on the website to change it. And some, thankfully, had a clear profile page where I could easily update my name. It was an exhausting, expensive, slow, and sometimes humiliating process that required me to come out as transgender to hundreds of skeptical strangers.
All of these experiences were about accessing information stored in a database and modifying it. And what my experience illustrate is that the interfacesinterfaces: A technology used to faciliate information creation, retrieval, searching, browsing, and/or analysis. we design to provide access to information—the paper forms, the websites, the policies, the procedures, and the media we use—determine so much about our experience with information: whether we can access it at all, whether we can find it, whether we trust the source, and what harm it causes in the process. In this chapter, we will discuss the many challenges in designing interfaces like these for information, and briefly discuss methods for overcoming these challenges.

Design
Throughout this book, we have alluded to the design of many things: data and data encodings, information technologies, information systems, the many policies that shape what information is gathered, stored, secured, and retrieved. All of these designed things emerge from an activity broadly known as designdesign: The human activity of envisioning how to change the status quo into a more preferred one. .
Design, to put it simply, is about envisioning future experiences. Or, as (once again) Herb Simon put it:
To design is to devise courses of action aimed at changing existing situations into preferred ones.
Design, therefore, comes with two central challenges: 1) understanding existing situations, and 2) figuring out what future situations we prefer. For the many things to design to make information accessible, this means different things:
- Designing data . This might mean understanding what data already exists, what its limitations are, and envisioning new kinds of data that address those limitations. Returning to the name change example above, this might mean designing database schemas that avoid using someone’s name, or other data like an email address that might contain their name, as a primary key, so that the name may be easily changed.
- Designing information technologies . This might include examining the problems and limitations of websites, mobile apps, search engines, and forms, and designing better ones. For example, I use wireless Bluetooth headphones between multiple devices, which are exceptionally annoying to unpair, and then repair between devices. Design might involve envisioning different device networking protocols that avoid these problems.
- Designing information systems . This might involve examining how existing information systems are failing to meet an information need, and then envisioning a change to the system, or even a complete redesign, to meet that need. For example, one of the common struggles of college students is registering for the classes they need to graduate: so many aspects of this system fail to meet student needs, with information released too late to plan schedules, confusing registration priority systems, inability to predict and meet demand for courses, and so on. Redesigning systems requires more than just building a new registration website; it requires reimagining how courses are scheduled, how student demand is expressed, and how limited resources are allocated.
- Designing information policies . This might involve examining the unintended consequences of a policy and imagining new policies that preserve the benefits of a policy while avoiding those unintended consequences. For example, web search engines are prone to embedding racist stereotypes in search results 12 ; design might entail defining new retrieval policies for algorithms to follow, accounting for and preventing harmful stereotyping.

Throughout all of these kinds of design, a central question is for whom one is designing 3 (or in Simon’s language, whose preferences are considered). This question is fundamentally about who is considered a stakeholderstakeholder: Someone who might be directly or indirectly impacted by the creation of a new information technology. of a design. Stakeholders are anyone who is a direct user of some information system, as well as anyone indirectly affected by in some information system, even if they do not use it directly. For example, consider the most ubiquitous information system, Google: billions of people use it and they are clearly stakeholders, but there are also billions who do not. These non-users are also stakeholders; imagine, for example, someone who travels to a country and uses Google to find a local restaurant. Even if a restaurant owner doesn’t use Google, the fact that Google may not show them on Google Maps, or may have incorrect information about their address, means that the restaurant owner will not get the tourist’s business, simply because others are relying on it.
There are many design paradigms that approach the problem of understanding stakeholder needs differently:
- Human-centered design uses interviews, observations, and other empirical methods to study how people use existing designs to identify alternative designs that might better serve their needs. This approach may produce design that meet direct stakeholder needs, but they often overlook indirect stakeholders.
- Value-sensitive design 5 considers both direct and indirect stakeholders but from the perspective of values rather than tasks. Values include things like autonomy, community, cooperation, democratization, sustainability, fairness, dignity, justice, and privacy. This approach may help ensure that designs meet the particular values of a community of stakeholders, but still requires a designer to decide whose values take priority.
- Design justice 3 considers all stakeholders, but from the perspective of justice, rather than values, focusing on marginalized groups first, and using community-based methods to envision designs with a community, rather than for a community. This approach stems from the premise that 1) marginalized groups are too often overlooked in design because they aren’t considered “average”, and 2) designing for the benefit of marginalized groups frequently ends up benefiting everyone by accounting for a greater diversity of human experiences.
- Posthumanist design 4 broadens design to consider not only human values and justice, but non-humans, including not only other species on earth and the broader ecosystems in which all life lives. This approach “decenters” humanity in the design process, looking at the broader systems on which humanity depends (which may or may not depend on humanity).
In all of these paradigms, there are a set of key design activities:
- Research . Not to be confused with academic research, design research (or sometimes “user research”) involves understanding the status quo 8 . There are countless methods for doing this, including interviewing or surveying people, observing their work and play, participating in their activities, or gathering data or academic discoveries about a problem. Design justice tends to approach these in partnership with communities, whereas other paradigms position researchers as “outside” a community, but designing on its behalf.
- Ideation . This is the most imaginative part of design, generating possible futures that might make current situations in a community into more preferred situations 10 . Ideation can involve brainstorming, sketching, storytelling, and more, all in service of creating visions for the future. For data, this might mean brainstorming data to collect; for information technologies, this might mean imagining new types of data analyses or interactive experiences. For information systems, it might mean imagining new processes that orchestrate people, technology, and data together.
- Prototyping . With a particular idea in mind, prototyping involves creating concrete experiences that reflect a possible future 2 . The goal of prototyping is to approximate that future so that it can be evaluated, but without having to actually create that future. Prototyping data might mean drafting a data structure or data schema. Prototyping information technologies might mean making website or mobile app mockups or algorithmic pseudocode for how a retrieval algorithm might work. Prototyping information systems might mean creating storyboards that narrate the different experiences and roles of people and information technology in a particular use case.
- Evaluating . With a prototype, designers can evaluate whether it might be a preferred future 7 . These methods are similar to research, but focus on stakeholders’ judgments about a particular future; what makes them difficult is deciding how much to trust people’s reactions to hypothetical, approximate depictions of what the future might be.
While the list of activities above is sequential, design activities are often anything but linear: they are more frequently iterative, returning to all four of these activities. Evaluations can reveal problems that require new prototypes or new questions for research; ideation can result in new questions for research. Prototypes can trigger new ideation. Design is therefore less a procedure and more like a collection of interrelated activities, each requiring a different mindset and skills.
There are many interrelated terms in design that can make the practice confusing. One is Human-Computer Interaction , which is an academic research area concerned with how people interact with and through computing and information technology. Interaction Design and User Experience Design are commonly phrases in industry that refer to the design of interactive, information experiences. Information Architecture often refers to the design of data, metadata, and interfaces to facilitate browsing, searching, and sensemaking. We will return to these in the last chapter of the book in information careers.

Interfaces
While there are many things to design in order to make information systems that meet stakeholder needs, interfaces are of particular importance, as they are the prime mediator—aside from other people—between people and information systems. Interfaces to information can take many forms, including paper (e.g., forms, newspapers), film (e.g., photographs, movies, library archives), audio (e.g., podcasts), computers (e.g., keyboards, mice, touch screens, smart speakers), and more. Designing each of these interfaces is hard in its own way, with print posing typographic challenges, film posing lighting challenges, and audio and video posing editing challenges.
Computer interfaces, more broadly known as user interfaces, may be some of the most challenging interfaces to design. One of the central reasons is that unlike most forms of information media, they are interactive : when we provide input, they react based on our input. This creates an illusion of intelligence. In fact, some work has found that people treat computers as social actors 11 , expecting them to have intelligence, follow social norms, and behave like other people, even when we are fully aware that they will not. This work found that we gender computers just like we gender people; we are polite to them when they are strangers; we ascribe a self to them, and that when we treat them as human, we like them better.

Interfaces can be good on many different dimensions, including:
- Usefulness . Interfaces that meet stakeholders’ information needs might be deemed useful, but knowing whether they do can be difficult. Moreover, useful interfaces are not necessarily good in other ways: they may be hard to learn, frustrating to use, unreliable, and even harmful, much like the name change interfaces I described at the beginning of the chapter, which were useful but hard and slow to use.
- Usability . Interfaces that are efficient to use without error are usable, but they are not necessarily useful. For example, many users of WeChat find it incredibly useful, supporting calls, messaging, search, payments, news, taxies, hotels, and much more, but many users, especially new ones, find it overwhelmingly complex to use.
- Accessibility . Interfaces that can be used by anyone, independent of their physical or cognitive abilities, are accessible. Unfortunately, few interfaces achieve such universal accessibility, with many excluding people who are blind, low vision, deaf, or have motor disabilities that make them unable to use a mouse, keyboard, or touchscreen. Interfaces that are usable to some might be unusable to others because of accessibility issues.
Accessibility is particularly important for information interfaces: if someone cannot physically operate an interface that mediates information, then they cannot access that information. This is a critical concern, as 1 in 7 people worldwide have some form of disability that might interfere with their ability to use an interface. Moreover, all people, independent of their abilities now, will eventually be disabled in some way as we age or become injured. It is unfortunate then that designers often take what is called a “medical” or “rehabilitation” lens on disability, imagining that the problem lies with the disabled person, focusing on fixing them rather than fixing interfaces. A disability justice lens, much like a design justice lens, recognizes that accessibility problems are in the interface designs themselves, and that it is the responsibility of designers to center people with disabilities in design to ensure that they work for everyone 1 .
In fact, disability has been the catalyst for many of the information technologies in history: telephones were invented in the 1880’s while trying to visualize sounds optically for teaching people who are deaf; texting was invented in the 1960’s as a way of transmitting text over phone lines to support people who are deaf; machine vision was invented in 1974 to help people who are blind access books; video captioning was invented in 1972 to enable deaf viewers to read audio; and the synthesized speech found in virtual assistants and smart speakers was invented in 1976 for people who are blind to hear text. Much of our modern information interfaces, then, emerged from design processes that centered people with disabilities.
Information Architecture
If one thinks of interfaces as the “containers” for information, one can think of information architecture as the labels on those containers that help us understand the structure of an interface and its contents. More generally, it is the organization and structure of information interfaces, ideally optimized to help people use the interface to meet an information need 14 .
Ultimately, the primary tool for guiding people to the information they need are symbols. For example, a button label like “search” might indicate some key search functionality, or the word “contact” on a restaurant website might indicate where a visitor can find a restaurant’s phone number. Words, phrases, iconography, and other symbols are a central kind of metadata for communicating the location of functionality or content in an interface. For example, in the site map in the figure above, words, icons, and symbols found on links, buttons, and images are the key way that users will know how to navigate the site, finding the information they need. Or, if they search instead, they will likely use words to describe the content they want.

Given the necessity of words, one central challenge in information architecture is the vocabulary problem 6 . First described in 1987 at the advent of graphical user interfaces, this series of studies observed that when asked to choose words for some given content or functionality, people would choose a diversity of labels that often did not overlap. For example, when the experiments non-verbally demonstrated copying some text in a word processor, participants might use the words “ copy ”, “ duplicate ”, “ repeat ”, “ replicate ”, or even “ clone ”. Of course, this problem is inherent to natural language: we often have many synonyms to describe the same phenomena. The problem was that it was quite rare for there to be any single word that covered the majority of participants’ expectations. These results suggest that there is no “best” word or phrase to describe some content or functionality in an interface.
The vocabulary problem has implications for both ways that people seek information in interfaces. When searchingsearching: Attempting to retrieve particular information from an information system. for information, it means that people’s queries for the same information are likely to use different words 9 . This means that any content being searched likely needs to have multiple descriptions to cover the diversity of vocabulary that people might use, or that users will have to learn the “official” vocabulary for some concept in order to find it. For example, imagine being new to English and trying to get a driver’s license. A reasonable search in simple English might be Seattle allow drive , but that returns results about driving laws and vehicle requirements. Someone has to learn the official vocabulary of U.S. driving regulations, which includes words like “license” and “permit.” Query recommendation can help when someone’s vocabulary is close, or mirror’s other’s confusion 17 , but it can’t make up for al lack of knowledge.
The vocabulary problem is equally problematic when browsingbrowsing: Exploring what information exists in an information system. for information, except rather than having to describe the information, users have to recognize descriptions of what they want. The challenge in designing the architecture of a website or app is that designers typically only get one label to describe that information, and the vocabulary problem means that the label will probably only be recognized as relevant for a fraction of visitors. Worse yet, that label will be amidst a sea of other labels, icons, and symbols competing for attention, many of which might be false positives , signaling relevance, but actually being irrelevant 13 . For example, suppose I was looking for a Seattle city permit to hold a street party in my neighborhood. The top navigation menu on the city website has the options “ Services & Information ”, “ Departments ”, “ Elected Officials ”, “ Boards & Commissions ”, “ Media Contacts ”, “ Staff Directory ”, “ News ”, “ Events ”, and “ Visiting Seattle .” It might be reasonable to choose “ Events ”, except that turns out to be about events the city itself is holding, not about events a resident wants to hold. “ Departments ” is also a good guess, since there is probably a department for permits, but that turns out to be a list of several dozen phone numbers. The answer is buried in “Services & Information”, then “Parking”, then “Permits”, and then “Apply for a Street Use Permit” in a list of 52 types of permits. These are the kinds of search and browsing problems that information architecture solves.
One clever combination of interface design and information architecture is faceted browsing 16 , seen above. This interface leverages the metadata of content on a site to generate a filtering interface that allows visitors to browse the metadata, select metadata that describes properties of what they are seeking, and then see matching results. Interfaces like these are only possible by carefully identifying what kinds of metadata will be most recognizable and relevant for users to describe what they want—and then painstakingly building that metadata database for all of the content on the site. Faceted browsing is an excellent example of how interfaces and information architecture must be designed together to optimize retrieval.
One short chapter on the intersection between information, design, and interfaces is not nearly enough to convey the rich practices that surround the design of information, information technology, and information systems. However, fundamentally, these practices ultimately stem from the desire to connect people to information by making accessible, usable, and useful interfaces. The key challenge is designing interfaces that don’t just serve the common cases, but also the diversity of cases at the margins of human experience and needs. Only then will information be truly accessible to everyone.
Podcasts
- Listen now! Offer ends soon, Recode Daily, Vox . Discusses the dark patterns used throughout design to manipulate people into interacting and generating ad revenue, including new policies that are beginning to regulate these design patterns.
- The Next Billion Users, 99% Invisible . A Google sponsored podcast about how Google conducts research using ethnographic methods from anthropology to understand users who don’t yet have access to the internet.
- The Worst Video Game Ever, 99% Invisible . Discusses the E.T. game for Atari, one of the worst video games ever, which nearly caused the collapse of the fledgling video game industry int he early 1980’s.
- All Rings Considered, 99% Invisible . Discusses the history of the design of mobile phone ringtones.
References
-
Cynthia L. Bennett and Daniela K. Rosner (2019). The Promise of Empathy: Design, Disability, and Knowing the "Other". ACM Conference on Human Factors in Computing Systems.
-
Bill Buxton (2010). Sketching user experiences: getting the design right and the right design. Morgan Kaufmann.
-
Sasha Costanza-Chock (2020). Design justice: Community-led practices to build the worlds we need. MIT Press.
-
Laura Forlano (2017). Posthumanism and Design. She Ji: The Journal of Design, Economics, and Innovation.
-
Batya Friedman, David G. Hendry (2019). Value Sensitive Design: Shaping Technology with Moral Imagination. MIT Press.
-
George W. Furnas, Thomas K. Landauer, Louis M. Gomez, and Susan T. Dumais (1987). The vocabulary problem in human-system communication. Communications of the ACM.
-
Morten Hertzum (2020). Usability Testing: A Practitioner's Guide to Evaluating the User Experience. Morgan & Claypool.
-
Julie A. Jacko (2012). Human computer interaction handbook: Fundamentals, evolving technologies, and emerging applications. CRC press.
-
Bernard J. Jansen, Danielle L. Booth, and Amanda Spink (2009). Patterns of query reformulation during Web searching. Journal of the American Society for Information Science and Technology.
-
Ben Jonson (2005). Design ideation: the conceptual sketch in the digital age. Design Studies.
-
Clifford Nass, Jonathan Steuer, and Ellen R. Tauber (1994). Computers are social actors. ACM Conference on Human Factors in Computing Systems.
-
Safiya Noble (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
-
Peter Pirolli (2007). Information foraging theory: Adaptive interaction with information. Oxford University Press.
-
Louis Rosenfeld, Peter Morville (2002). Information architecture for the world wide web. O'Reilly Media, Inc..
-
Herbert A. Simon (1963). The Sciences of the Artificial. MIT Press.
-
Ka-Ping Yee, Kirsten Swearingen, Kevin Li, and Marti Hearst (2003). Faceted metadata for image search and browsing. ACM Conference on Human Factors in Computing Systems.
-
Zhiyong Zhang, Olfa Nasraoui (2006). Mining search engine query logs for query recommendation. ACM International Conference on World Wide Web.
Information + social
When I was in middle school, there were no smartphones and there was no internet. Friendship, therefore, was about proximity: I eagerly woke up and rushed to the bus stop each morning not to get to school, but to see my friends, all of whom lived within a mile of my house. Lunch was always the highlight of the day, where we could share our favorite moments of the latest Pinky and the Brain skit on Animaniacs , gossip about our teachers, and make plans for after school. On the bus ride home, we would chart out our homework plans, so we could reunite at 4 or 5 pm to play Super Nintendo together, play basketball at the local primary school playground, or ride our bikes to the corner store for candy. If we were feeling lonely, we might head to our kitchens to our wired landline phone, call each other’s houses, politely ask whoever answered to give to the phone to our friend, and covertly coordinate our next moves. But our conversations were always in code, knowing full well that our parents or siblings might be listening on another phone, since they all shared the same line.
To be social in the early 1990’s in the United States meant to be together, in the same space, or on the phone, likely with no inherent privacy. This time, of course, was unlike the world before the phone, in that nearly all communication was face to face; and it is unlike today, where almost all communication is remote and often asynchronous. The constant in all of these eras is that to be social is to exchange information, and that we use information and communications technologies (ICTs) to facilitate this exchange. In this chapter, we’ll discuss the various ways that information intersects with the social nature of humanity, reflect on how technology has (and hasn’t) changed communication, and raise questions about how new information technologies might change communication further.

Information and Communication
Information, in the most abstract sense, is a social phenomenon. All human communication is social in that it involves interactions between people. Writing, data, and other forms of archived information are social, in that they capture information that might have otherwise been communicated in forms separate from another person. Even biological information like DNA is social, in that we have elaborate and diverse social norms about how we share our DNA with each other through reproduction. Information is constructed socially, in that we create it with other people, shaped by our shared values, beliefs, practices, and knowledge; and we create it for the purpose shaping the values, beliefs, and practices, and knowledge of other people.
Similarly, information systems, including all of those intended for communication, are sociotechnical , in that they involve both social phenomena such as communication, as well as technology to facilitate or automate that communication. Libraries are social in that they are shared physical spaces for exchanging and sharing knowledge. The internet is social in that it is a shared virtual space for exchanging and sharing knowledge. Even highly informal information systems, like a group of friends chatting around a table, are sociotechnical, in that they rely on elaborate systems of verbal and non-verbal communication to facilitate exchange 2 .
Our social interactions around information can vary along some key dimensions, broadly shaping what is known as social presence 27 . For example, one dimension is the intimacy of communication, which is the degree to which the many social cues in communication such as physical distance, eye contact, smiling, posture, and conversation topic establish feelings of emotional closeness. Another dimension is immediacy , which is the degree to which information has urgency in an exchange. Another dimension is efficiency , which is the degree to which a medium facilitates a message being delivered.

Each information technology has unique properties along these dimensions. For example, consider two popular forms:
- Face-to-face communication has high potential for intimacy, immediacy, and efficiency, as it affords multiple parallel channels for exchange, including speech, non-verbal cues, eye contact, facial expressions, and posture. It is also synchronous, in that the delay between sending a message and receiving it is effectively instantaneous because of the high speed of light and sound. And by using other information technology—paper, pens, whiteboards, smartphones, tablets—there is even richer potential to communicate efficiently and intimately through multiple media.
- Texting strips away most of the features of face-to-face communication, leaving an asynchronous stream of words, symbols (e.g., emoji), and more recently, images and video. It can achieve a different kind of intimacy because of its privacy, though it has many fewer channels in which to do this, and often results in miscommunication, especially of emotional information 31 . Because it is often asynchronous and usually at a distance, there is more time between exchanges, and therefore reduced immediacy. Moreover, because of the reduced channels, may be less efficient for particular kinds of information that are more easily conveyed with speech, gestures, or drawings.
These basic ideas in information and communication are just a fraction of the insights in numerous fields of research. Communication 5 studies verbal, written, and non-verbal social interactions, detailing the strategies that we have for effectively conveying information to others in different media. Social Psychology 18 studies the social nature of human beings and how our many social biases (e.g., in-grouping, which is the tendency to create artificial tribal boundaries around social interaction), influence what information we share and with whom and who we trust. Organizational Behavior 26 studies how social psychology and communication affect the shared goals we pursue through work. And Social Computing 23 is a part of computing and information sciences that is concerned with all of these phenomena as they relate to computing, including computer-supported collaborative work, computer-mediated communication, and online communities.

Communities
One place that these foundational aspects of communication play out is in communities , which may be anything from groups of people with strong ties to much larger groups that share some affinity, such as an interest, identity, practice, or belief system 29 . A group of friends is a community, a church is a community, a university is a community, a hospital is a community, workplaces are communities, and even much broader affinity groups, such as LGTBQ+ people are community. None of these imply a particular strength of relational ties or homogeneity in experience—the LGBTQ+ community, for example, can be exceptionally heterogenous, with great rifts between different groups in experience, priorities, and beliefs. It is therefore not similarity that brings people together, but simply relationships around shared identities.
Communities relate to information in that much of what communities do is exchange information. Communities curate information with each other to promote learning and awareness, like active Wikipedia contributors create shared identity and practices around curating knowledge about special interests 24 . Communities provide expertise, as when software developer with particular technical expertise provide answers on Stack Overflow to common questions 16 . And communities shape beliefs, as when conspiracy communities leverage identity affirmation strategies to create tightly bound in-groups 22 . Therefore, when we consider the role of communities in information, it becomes clear that much of what information means is determined by the shared identities in our communities in which we create it.

The internet has led to a rapid exploration of information technologies to support community, revealing two major types of community supports. One support is broadcasting . Much like newspapers, radio, and television, online social media is often used to broadcast to community, where one person or a group of people broadly disseminate information to a broader community. It includes Usenet, which were the threaded discussion forums that shaped the internet and inspired later websites like Slashdot, Digg, and Reddit 10 . They include blogging and micro-blogging such as the posting features of Instagram and Facebook, in which people broadcast personal experiences to seek affirmation, feedback, and connection 20 . And it includes the darker parts of the web, such as 4chan and /b/, which spawn humor, but also conspiracy theories and hate speech 3 , as well as platforms like Gab, which amplify both free speech and hate speech resisting moderation 17 .
Other communities are more focused on discourse , where communication is not primarily about broadcasting from one to many, but more mutually interactive communication and conversation. Most notably, since its launch, Facebook has been seen as a place to maintain close relationships, talking about shared interests, celebrating life milestones, or providing support in trying times 14 . This also includes mailing lists, such as those used by cancer survivors to provide mutual support and aid 19 . General purpose social media websites often fail to protect marginalized communities from hate speech and harassment that emerges in discourse, and so some sites have emerged with specific supports for preventing these phenomena; for example, trans communities have created sites that ensure safety, privacy, content warnings, and strict moderation to safe spaces for support and encouragement 9 .
It is rare that communities last forever. Some of the key reasons communities fade include 4 :
- Its members’ needs and interests change, and so they leave one community for another.
- A platform’s underlying information technology of a platforms decays, reducing trust in the archiving of information and the availability of the platform, resulting in migration to new platforms that are better maintained.
- Platform maintainers make design changes that are disruptive to community norms, such as the infamous 2018 Snapchat redesign that condensed stories and snapchats into a single “Friends” page.
- Platform policies evolve to become hostile to a community’s values, or a community’s values evolve and policies do not. For example, many experience harassment on Twitter, struggling to maintain block lists, and therefore leave 11 .
These demonstrate that while a community’s communication is key, so are the underlying information systems designed and maintained to support them.
One key design choice in online communities is how to handle content moderation. All communities moderate somehow; at a minimum, platforms may only allow people with accounts to post, or may disallow content that is illegal where the community or platform operates. Most social media companies have a set of rules that govern what content is allowed, and they enforce those rules to varying degrees. For example, Twitter does not currently allow violent threats, promotions of terrorism, encouragement of suicide, doxxing, or harassment. However, it does allow other content, such as gaslighting , which is a form of abuse that makes victims seem or feel “crazy” 28 . Because of the challenges of centralizing moderation, many researchers are investigating new forms of decentralized moderation, such as online harassment moderation systems that use friends instead of platform maintainers or moderators 15 .

Collaboration, Coordination, and Crowds
Whereas communities often bring people together to share information about interests and identities, work is an entirely different form of social interaction, bringing people together to accomplished shared goals. As with communities, information and information technologies are central to work.
One way that information is central is that information facilitates collaboration , in which a group of people together to achieve a shared goal. Collaboration includes activities like pair programming , in which software developers write code together, making joint decisions, helping each other notice problems, and combining their knowledge to improve the quality of code 30 . Another example is using collaborative editing tools like Google Docs to create shared documents 12 . Collaboration benefits from information by helping establish what communications researchers call grounding (a shared understanding of what is being talked about), and awareness (knowledge of what a collaborator is working on) 7 . These two distinct kinds of information are independently important for helping collaborators work toward shared goals, and information technologies must provide them to facilitate collaboration. For example, in group projects, it is equally important to develop agreement about what is being worked on (grounding), as well as sending regular updates about progress on that work (awareness). However, collaboration technologies can offer features that combine both of these information needs into a single feature. For example, the fact that Google Docs provides real-time awareness of where a collaborator’s cursor is provides both awareness (because it indicates what a collaborator is working on) and grounding (because it is a proxy for what they might be talking about).

Whereas collaboration is about people in tandem toward a shared goal, coordination is about people working separately, and often asynchronously toward a shared goal, separated by time and space. For example, coordination includes large teams of software developers independently working on an application, but eventually integrating their work into a coherent whole 25 . It also includes teams of doctors, nurses, and medical assistants coordinating care for patients 6 . Coordination does not require grounding, in the sense that communication may be less synchronous, but it still requires—even more so—awareness of others’ work, as well as awareness of dependencies between different aspects of work. Without these two forms of awareness, teammates might do redundant work that has to be merged, conflicting work that has to be redone, or incoherent work that can’t be integrated. Information technologies are key to providing this awareness of dependencies, sharing updates about teammates’ contributions, warnings about conflicting work.
In general, information technologies struggle to support collaboration and coordination, especially in conditions like remote work where the baseline capacity for communication is low. Distance work, for example, really only succeeds when groups have high common ground, loosely coupled work with few dependencies, and a strong commitment to collaboration technologies, reducing the need for synchronous communication 21 . One active area of research on ensuring these conditions is crowd work, in which groups of strangers come together to complete tasks (Wikipedia, Mechanical Turk, Uber, 99designs, TopCoder); all of these succeed because there is almost no requirement for coordination, collaboration, or communication, and tasks are well-specified 13 . In contrast, groups that have poor common ground and/or highly coupled work with significant dependencies experience much higher demand for communication, straining relationships and complicating work.
Information technology has struggled to prevent these strains for many reasons. First and foremost, research is clear on what aspects of face-to-face communication are necessary and why they are necessary, but even after decades of research, technology simply cannot support them 1 . For example, we know that for video chat to have the same fidelity as face to face chat that it needs no latency, clear visibility of non-verbal gestures, natural eye contact, and a sense of shared space, but none of these are yet viable.
Organizations are also often ineffective at deploying collaboration tools 8 :
- There are disparities between who does the work and who benefits. For example, using meeting scheduling software that allows the scheduler to easily see busy status helps the scheduler, but requires everyone else to carefully maintain their busy status.
- Collaboration tools require critical mass. For example, if only some people on your team adopts Slack, Slack is less useful, because you don’t get the information you need from the entire team.
- Collaboration tools don’t handle exceptions well. For example, sharing a Google Doc with someone without a Google account either requires exporting it, opening up permissions, or not sharing it with them at all.
Thus, despite many decades of innovation and adoption in industry, working together still works best face-to-face in the same physical space.
Clearly, information technology has changed how we communicate, and in some ways, it has even changed what we communicate, allowing us to share more than words. And yet, as we have seen throughout this chapter, it hasn’t really changed the fundamental challenges of communication, nor has it supplanted the richness of face-to-face communication. What it has done is expanded the ways we communicate, and deepened our understanding of what makes communication work, challenging us to adapt to an ever more complex array of ways of being social.
Podcasts
- Ghost in the Machine, On the Media . Discusses the possible necessary limits of free speech, ideas from planning that could shape future social media platforms, and the often problematic role of science fiction in shaping online platforms.
- Can Big Tech Make Sure That 2020 Is Not 2016?, Sway . Discusses how social media platforms are amending policies around political advertising and disinformation.
- You Missed a Spot, On the Media . Discusses content moderation, deplatforming, free speech, and the future of social media.
- I Love Section 230. Got a Problem With That?, The Argument, NY Times . A debate on Section 230, the left’s desire for more aggressive moderation, the right’s desire for less, and the surprising ways that the policy has created a marketplace for online speech.
- Restoring Justice Online, On the Media . Discusses conflict and harassment online and how methods of restorative justice hold promise to rehabilitate online communities suffering from interpersonal conflict.
- The Substack Bros & Teen Vogue, Cancel Me Daddy, Katelyn Burns and Oliver-Ash Kleine . Discusses the resignation of Teen Vogue’s new editor due to her anti-Asian racist adolescent tweets and the controversy at Substack in which ant-trans writers are being recruited with large writing grants using the revenue generated partly by trans Substack writers.
References
-
Mark S. Ackerman (2000). The intellectual challenge of CSCW: the gap between social requirements and technical feasibility. Human-Computer Interaction.
-
Michael Argyle (1972). Non-verbal communication in human social interaction. Cambridge University Press.
-
Michael Bernstein, Andrés Monroy-Hernández, Drew Harry, Paul André, Katrina Panovich, and Greg Vargas (2011). 4chan and/b: An Analysis of Anonymity and Ephemerality in a Large Online Community. AAAI Conference on Web and Social Media.
-
Casey Fiesler, Brianna Dym (2020). Moving Across Lands: Online Platform Migration in Fandom Communities. ACM Proceedings of Human-Computer Interaction.
-
John Fiske (2010). Introduction to Communication Studies. Routledge.
-
Geraldine Fitzpatrick, Gunnar Ellingsen (2013). A review of 25 years of CSCW research in healthcare: contributions, challenges and future agendas. Computer Supported Cooperative Work.
-
Darren Gergle, Robert E. Kraut, and Susan R. Fussell (2013). Using visual information for grounding and awareness in collaborative tasks. Human–Computer Interaction.
-
Jonathan Grudin (1988). Why CSCW applications fail: problems in the design and evaluation of organizational interfaces. ACM Conference on Computer Supported Cooperative Work and Social Computing.
-
Oliver L. Haimson, Justin Buss, Zu Weinger, Denny L. Starks, Dykee Gorrell, and Briar Sweetbriar Baron (2020). Trans Time: Safety, Privacy, and Content Warnings on a Transgender-Specific Social Media Site. ACM Proceedings on Human-Computer Interaction.
-
Michael Hauben, Ronda Hauben, Thomas Truscott (1997). Netizens: On the History and Impact of Usenet and the Internet. Wiley.
-
Shagun Jhaver, Sucheta Ghoshal, Amy Bruckman, and Eric Gilbert (2018). Online harassment and content moderation: The case of blocklists. ACM Transactions on Computer-Human Interaction.
-
Young-Wook Jung, Youn-kyung Lim, and Myung-suk Kim (2017). Possibilities and limitations of online document tools for design collaboration: The case of Google Docs. ACM Conference on Computer Supported Cooperative Work and Social Computing.
-
Aniket Kittur, Jeffrey V. Nickerson, Michael Bernstein, Elizabeth Gerber, Aaron Shaw, John Zimmerman, Matt Lease, and John Horton (2013). The future of crowd work. ACM Conference on Computer Supported Cooperative Work and Social Computing.
-
Cliff Lampe, Nicole B. Ellison, and Charles Steinfield (2008). Changes in use and perception of Facebook. ACM Conference on Computer Supported Cooperative Work and Social Computing.
-
Kaitlin Mahar, Amy X. Zhang, David Karger (2018). Squadbox: A Tool to Combat Email Harassment Using Friendsourced Moderation. ACM Conference on Human Factors in Computing Systems.
-
Lena Mamykina, Bella Manoim, Manas Mittal, George Hripcsak, and Björn Hartmann (2011). Design lessons from the fastest Q&A site in the west. ACM Conference on Human Factors in Computing Systems.
-
Binny Mathew, Anurag Illendula, Punyajoy Saha, Soumya Sarkar, Pawan Goyal, and Animesh Mukherjee (2020). Hate begets Hate: A Temporal Study of Hate Speech. ACM Proceedings of Human-Computer Itneraction.
-
William McDougall (2015). An Introduction to Social Psychology. Psychology Press.
-
Andrea Meier, Elizabeth Lyons, Gilles Frydman, Michael Forlenza, and Barbara Rimer (2007). How cancer survivors provide support on cancer-related Internet mailing lists. Journal of Medical Internet Research.
-
Bonnie A. Nardi, Diane J. Schiano, and Michelle Gumbrecht (2004). Blogging as social activity, or, would you let 900 million people read your diary?. ACM Conference on Computer Supported Cooperative Work and Social Computing.
-
Gary M. Olson, Judith S. Olson (2009). Distance matters. Human-Computer Interaction.
-
Shruti Phadke, Mattia Samory, and Tanushree Mitra (2020). What Makes People Join Conspiracy Communities? Role of Social Factors in Conspiracy Engagement. ACM Conference on Computer Supported Cooperative Work and Social Computing.
-
Manoj Parameswaran, Andrew B. Whinston (2007). Social computing: An overview. Communications of the Association for Information Systems.
-
Christian Pentzold (2010). Imagining the Wikipedia community: What do Wikipedia authors mean when they write about their ‘community’?. New Media & Society.
-
Rachel Potvin, Josh Levenberg (2016). Why Google stores billions of lines of code in a single repository. Communications of the ACM.
-
John R. Schermerhorn, Jr., Richard N. Osborn, Mary Uhl-Bien, James G. Hunt (2011). Organizational Behavior. Wiley.
-
John Short, Ederyn Williams, Bruce Christie (1976). The Social Psychology of Telecommunications. John Wiley & Sons.
-
Paige L. Sweet (2019). The sociology of gaslighting. American Sociological Review.
-
Etienne Wenger (1999). Communities of Practice: Learning, Meaning, and Identity. Cambridge University Press.
-
Laurie A. Williams, Robert R. Kessler (2000). All I really need to know about pair programming I learned in kindergarten. Communications of the ACM.
-
Sarah Wiseman, Sandy JJ Gould (2018). Repurposing emoji for personalised communication: Why🍕 means “I love you”. ACM Conference on Human Factors in Computing Systems.
Information + science
When I was Chief Technology Officer of AnswerDash, the startup I co-founded to help answer people’s questions on websites, one of my primary jobs was to help our sales team sell. One of our company’s biggest opportunities was to sell to a large telecommunications company that fielded hundreds of thousands of phone calls each month about billing. Each one of those phone calls cost anywhere from $5-50 each, because they took at least one customer support staff time to answer. The company was enticed by our product, because it might help their customers get answers to billing questions on the website itself, potentially saving them millions in support costs (by laying off customer support staff). They agreed to a pilot launch, we passed their security audit, and we helped them write content for our service to ensure people could find helpful answers. They agreed to run a one month A/B test, comparing calls in the month during the pilot to the months before and after our service was added.
After the pilot month, we had the results: we had reduced their call volume by about 5%, saving them tens of thousands of calls each month. We were overjoyed! But when we talked to their internal data scientist, he didn’t believe the results. He wanted to know more about how we had gathered our data, how we had cleaned it, and how we had analyzed it. We shared our methods with him, and they agreed to run another pilot, this time using their own A/B testing infrastructure. Again, they received the same results: a 5% reduction. We met again and make the hard sell that our product was the cause of the two reductions, but he was still skeptical of the results, and recommended the company pass on our service. We learned later that this data scientist had been wrong a few times before, and needed to not be wrong again, and so despite our successful results, his need to maintain his reputation internally as a trusted source of truth trumped our seemingly positive results.
This story is an example of applied data sciencedata science: Using data and code to answer questions. in industry, and it’s reflective of the broader challenges of data science in both academia, industry, and government. How do we use data to answer questions and to make decisions? How do we address issues of bias and trust? And how do we communicate what we learn in a way that not only persuades, but acknowledges the many limitations of data in modeling the world?

Science
Long before there was data science, there was science, emerging in the 16th century in Europe. And at the core of science was the central question: how can we answer questions ? Questions such as “ Why do things fall after we throw them up in the air? ”, “ What is at the bottom of the ocean? ”, or “ Where do species come from? ” Prior to science, questions like these were most often answered either through the kinds of logical argumentation of philosophers and mathematicians, the kinds of interpretative and humanist traditions in the humanities, and, of course, religion. What science brought was method: strategies for observation and measurement of the natural and social world, techniques for analyzing data, and practices for interpreting and synthesizing data into ever better theories that explain how the world works. The result of this new epistemology of knowledge was a revolution in how humanity stumbles its way toward truth through evidence and paradigm shifts 7 .
Science and its methods evolved over centuries, shaping not only our knowledge, but our practical application of knowledge, driving innovations in engineering and industry 12 . But in 1962, John W. Tukey, an American mathematician and statistician, wrote The Future of Data Analysis 15 , where he imagined in a future in which computers might enable a speed and scale of data analysis that might transform how data is analyzed and who analyzes it:
Most data analysis is going to be done by people who are not sophisticated data analysts and who have very limited time; if you do not provide them tools the data will be even less studied. Properly automated tools are the easiest to use for a man with a computer.
He imagined algorithms that would automate statistical computations and even algorithms that would render data visualizations, freeing analysts from having to calculate them manually. At the same time, he warned that such automation would create even greater need for theory, to help guide analysts, less they mindlessly and recklessly search for patterns in data, only to find spurious associations with no meaning.
Only a few decades later, his predictions came to pass in science, as computing transformed science 8 . Scientists began using sensors to automatically gather large scale data about the climate. In partnership with computer scientists, they began inventing database systems capable of storing hundreds of millions of data points. The scale of data required new methods of automated analysis, facilitated by both advances in statistical methods such as machine learning, as well as advances in computer hardware and algorithms, enabling the first supercomputers to process large scale data in real time. Programming languages like R , created by and for statisticians to analyze data automatically, began to replace manual calculation on data, facilitating analysis at scale. And new automated forms of data visualization emerged to enable scientists to explore their data to generate hypotheses, but also to summarize it in scientific journals. By the late 1990’s, science had changed, becoming inherently computational, though at its core, its endeavor remained the same: gather data, test hypothesis, develop theories, but do so with more data and speed than ever before. But it was also more sociotechnical than ever, balancing the inherently human aspects of science with increasingly technical infrastructure 11 .

The result of this multi-decade transformation was a general understanding of analysis as a pipeline :
- Pose a question that can be answered with data. For example, an immunologists might want to know “ How effective are SARS-CoV-2 vaccines for children? ” This has remained relatively unchanged by computation and statistics, as data and algorithms alone cannot tell us what questions are novel, important, and feasible to answer.
- Define measurements of the phenomena in the question. While this is still largely something that data and algorithms cannot change, they did change what kinds of measurements are possible. For example, computing was central to enabling DNA sequencing, which has been critical in precise measurement of viral antibodies 14 .
- Gather data . Computing transformed this by automating measurement and storage in many domains, allowing sensors of many kinds to gather and record data at scale without human labor. For example, oceanographers can now deploy extensive cables and sensors on the coastal ocean floor to monitor submarine volcanic activity, methane plumes, salinity, and the effects of climate change from their offices 13 .
- Explore the data . Computing transformed this step by allowing it to be quickly queried, summarized, and visualized, helping scientists see patterns, form hypothesis, and plan analyses. For example, R packages like ggplot2 enabled scientists to quickly visualize sampled data, build upon some of the earliest data visualizations in the 18th and 19th century, which helped diagnose cholera outbreaks in London.
- Analyze the data . Computing transformed this step by allowing programs to automatically clean, restructure, query, and statistically analyze data at scale, rather than calculating statistics by hand or by entering data tables into statistics packages. Libraries like Pandas for Python emerged making it easier to write short but powerful programs for processing data; libraries like mlr3 emerged to simplify the application of machine learning to problems of prediction, classification, and clustering.
- Report results . As with exploration, computing made it possible to automatically generate summaries, visualizations, and reports for scientists, whether for a research paper, presentation, or internal discussion. Tools like Tableau emerged to help streamline the creation of visualizations and reports.
- Interpret results . As with posing questions and defining measurements, interpretation remained untouched by computing and statistics, as scientists still needed to make sense of results and integrate them into broader theories and bodies of evidence.
Underlying this pipeline were two long-standing challenges. The first, how to ask good questions and interpret the answers , have always been at the heart of not only science, but scholarship in general. Computing has left those challenges unchanged. But the second had always been there, but was never seriously engaged: when is it ethical to gather and analyze data ? Computing had a strong impact on this question, as it was enabling observation in ways never before possible, at scales never before possible. By amplifying and automating how data was used to answer questions, it raised new ethical concerns about data and its inherent biases. Some of the critical concerns include 3 :
- Whoever gathers the data decides what knowledge we discover; what if most of the data gathered is by industry, with no public control over what is gathered?
- Will the scale of data lead people to falsely believe in its objectivity? Data has bias and scale cannot correct its inaccuracies or biases.
- Will the quantity of data become more important than its quality? In science, sometimes small data sets with high quality data are more valuable than large data sets with poor quality.
- What meaning is lost when big data is taken out of context? Especially when that context might not be gathered as metadata?
- When is it unethical to gather data at scale? Issues of consent, sampling bias, and harm still matter, even when data collection is automated.
- Who gets access to data, especially if it is gathered privately? Science is practiced in public, and private data risks creating digital divides.
Scholars have further worried that all of the phases of data science above, when done without awareness of the deep, structural, and historical inequities in society, might only reinforce those inequities 4 . They might pose questions only of importance to dominant groups, they might gather data in ways that exclude marginalized groups, they might analyze data in ways that ignore the margins society, and they might visualize, report, and interpret data in ways that are ignorant of marginalized experiences. Computing and statistics might then become another tool for oppression.
Industry
It wasn’t until the early 2000’s that industry, with its emerging realization of the power of information for informing decisions, that the phrase data sciencedata science: Using data and code to answer questions. emerged. DJ Patil, an executive at LinkedIn who was doing a lot of data analysis of user engagement, was talking a lot with Jeff Hammerbacher , who was on Facebook’s data team doing the same thing. They didn’t want to call themselves “analysts,” because that was a word too often associated with finance; they didn’t like the term “research scientist” or “statistician”, since those were associated with academia. And so after brainstorming some job titles, they came up with “data scientist.” It stuck, and was just provocative and vague enough that industry executives started realizing that the applied science that Silicon Valley was doing to understand user activity on their websites was something that all companies could be doing with their own data.
Of course, in essence, “data science” was not substantially different from science. There were still questions, but they concerned questions of capitalism, such as “ Who is visiting our site? ”, “ Why are people leaving our site? ”, and “ What is driving sales? ” Conceptually, measurement was no different, but measurements tended to be about web server logs, sales transactions, and advertising campaigns. Data storage was often more demanding, since commerce tends to operate at a greater scale then science, but database technologies worked equally well in both domains. The techniques for data analysis were no different, drawing upon the same statistical and computational methods of science. And the tools were the same, drawing upon R, Python, machine learning libraries, and data visualization toolkits.

There were three differences, however:
- Industry typically has far less time than science. Where scientists might take decades to identify a high certainty answer to a big unanswered question, data scientists in industry might need a (necessarily low certainty) answer in a day, a week, or a month.
- Unlike science, which answers questions for the sake of understanding, industry answers questions to inform decisions . This introduces risks of bias and persuasion, as data might be more likely to be abused in industry to secure a promotion or increase sales.
- Unlike science, where the people using data to do science might have at least 5-6 years of training in a Ph.D., and communicate primarily with people with similar levels of training, data scientists in industry might lack similar expertise , and be communicating with people with little scientific literacy.
The result of these three differences was industry, as well as government, began to push for more training of data scientists. In essence, these efforts distilled the core expertise that scientists had developed in combining computing and statistics into knowledge that undergraduate or masters students have. While that educational infrastructure has grown, many of the data scientists hired in industry have been people with Ph.D.s that did not find or did not want a job in academia.
As data science has expanded in industry, the roles that data scientists take have been woven through business and government. Some data scientists inform managers’ strategic decisions with new insights; some specializing in modeling for real-time prediction to inform prioritization of tasks; some build robust platforms for data collection; and some manage teams of data scientists to do these things 6 . Others specialize in the unique challenges of leveraging machine learning, including managing and versioning data and calibrating and tuning machine learned models 1 . Data scientists in industry, unlike scientists, often find that they have to model data in ways that balance precision with simplicity, in order to communicate insights in ways that are relevant and comprehensible to people in their organization that lack data science expertise 5 .

Industry, like academia, is also beginning to grapple with the risks of bias and oppression in large scale data gathering and analysis. An increasing number of both scholars and industry experts have raised concerns about how data is being used to reinforce and amplify oppression of marginalized groups 2,4,9,10 . Data scientists, often having never received education about issues of justice, bias, and ethics, resist these calls, arguing that data is neutral. And controversies, like the firing of AI Ethics expert Timnit Gebru at Google, demonstrate that the role of ethics in data and data science in industry is far from a settled one.
Ultimately, the transformation of science and industry, first through statistics, and then through computation, are transformations about information: where it comes from, how we create it, what it means, and whether we trust it. The disruptive nature of computation is changing the answers to these questions, but it is not changing the questions themselves. Universities, as a nexus of both data-driven science, as well as data science education, are at the heart of shaping whether the answers to these questions are purely technical in nature, or sociotechnical and sociopolitical.
Podcasts
Interested in learning more about science and data science? Consider these podcasts:
- Florence Nightingale: Data Viz Pioneer, 99% Invisible|https://99percentinvisible.org/episode/florence-nightingale-data-viz-pioneer/]. Discusses the founder of modern nursing, Florence Nightingale, who also happened to be a pioneer in data visualization of public health data.
- Scientists Are Hunting For Alien Worlds Outside Our Solar System, Are We There Yet?, NPR . Discusses efforts to detect life in other solar systems using data.
- CRISPR, Radiolab, WYNC . Discusses technology for editing DNA, and the many complex implications of treating DNA as data.
References
-
Saleema Amershi, Andrew Begel, Christian Bird, Robert DeLine, Harald Gall, Ece Kamar, Nachiappan Nagappan, Besmira Nushi, and Thomas Zimmermann (2019). Software engineering for machine learning: A case study. International Conference on Software Engineering: Software Engineering in Practice.
-
Ruha Benjamin (2019). Race after technology: Abolitionist tools for the new jim code. Social Forces.
-
danah boyd, Kate Crawford (2012). Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon. Information, Communication & Society.
-
Catherine D'Ignazio, Lauren F. Klein (2020). Data Feminism. MIT Press.
-
Fred Hohman, Andrew Head, Rich Caruana, Robert DeLine, and Steven M. Drucker (2019). Gamut: A Design Probe to Understand How Data Scientists Understand Machine Learning Models. ACM Conference on Human Factors in Computing Systems.
-
Miryung Kim, Thomas Zimmermann, Robert DeLine, and Andrew Begel (2016). The emerging role of data scientists on software development teams. IEEE/ACM International Conference on Software Engineering.
-
Thomas S. Kuhn (2012). The structure of scientific revolutions. University of Chicago Press.
-
Charlotte P. Lee, Paul Dourish, and Gloria Mark (2006). The human infrastructure of cyberinfrastructure. ACM Conference on Computer Supported Cooperative .
-
Safiya Noble (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
-
Cathy O'Neil (2016). Weapons of math destruction: How big data increases inequality and threatens democracy. Broadway Books.
-
David Ribes, Charlotte P. Lee (2010). Sociotechnical Studies of Cyberinfrastructure and e-Research: Current Themes and Future Trajectories. Computer Supported Cooperative Work.
-
Bertrand Russell (1953). The impact of science on society. Routledge.
-
John Trowbridge, Robert Weller, Deborah Kelley, Edward Dever, Albert Plueddemann, John A. Barth, and Orest Kawka (2019). The Ocean Observatories Initiative. Frontiers in Marine Science.
-
Cheng-ting Tsai, Peter V. Robinson, Carole A. Spencer, and Carolyn R. Bertozzi (2016). Ultrasensitive Antibody Detection by Agglutination-PCR (ADAP). ACS Central Science.
-
John W. Tukey (1962). The future of data analysis. The annals of mathematical statistics.

Information + automation
The first time I saw a computer program was magical. It was 4rd grade and I was nine years old. There was a temporary installation of about fifteen Commodore 64 computers lined up in the hallway outside of our classroom. One class a time was invited out into the hallway to sit in pairs in plastic chairs. When my class was invited out, we walked single file to our seats and then our teacher, a very short and very cranky man, grumpily handed out a single piece of paper in front of each computer. He told us to follow the instructions on the sheet of paper, entering exactly what it said until we reached the end of the worksheet. The instructions were a cryptic list of pairs of numbers. We entered them, one by one, correcting our errors as we typed them in. When we reached the bottom of the list, we pressed the “Run” button on the keyboard.
To our surprise, a pixelated duck appeared! The numbers suddenly made sense: each one represented the position of one of square, and together, all of the position made up a picture of a duck. My partner and I immediately wanted to edit the points, seeing if I could make the duck’s eyes bigger, or give it bigger wings, or better yet, change it into a monster or a cat. For some reason, the idea of telling a computer how to draw robotic, rectangular, black and white animals was far more interesting than just drawing animals myself, even though my hands could do far more with paper, pens, and paint.
We use code, now more than ever, automate how we create, retrieve, and analyze information. And yet, as in the story above, we often happily exchange the labor that we can do ourselves with the wonder of our minds and bodies with the speed, scale, logic, and versatility of code. In this chapter, we reflect on this trade, what we gain and lose when we make it, and the diverse consequences of shifting control over information and decisions to machines.
When to automate?
Automation, of course, does not just include computing. As we noted in Chapter 5 in our discussion of information technology, we used mechanical devices to automate printing, phonographs to automate musical recordings, and electricity to automate the transmission of messages via telegraphs, phones, and television. And our discussion of what is gained and lost began with Socrates and his fears that writing itself was a form of “automation”, in that it externalizes our memories, risking atrophy to our intelligence, memory, and wit. Code, therefore, is just the latest information technology to make us wonder about the tradeoffs of delegating our information labor to machines.

When, then, is automation worth it? Let’s examine this question by considering the many applications of code to problems of information. We’ll begin with one of the first things that code automated: calculation . As you may recall, the first computers were people, in that humanity has performed the labor of arithmetic manually since arithmetic was invented. This was true even up through the Space Race in the mid-1950’s, when the United States and the Soviet Union rushed to be the first to space. The calculations here were ballistic, involving algebra, geometry, and calculus, all in service of trying to aim and steer rockets in a manner that would allow them to escape orbit and safely return to Earth. Women, including many Black women mathematicians, performed the calculations that got the U.S into orbit 13 . When computers arrived shortly after, the need for human computers rapidly declined, leaving most out of work. They were replaced with a much smaller generation of computer programmers, who wrote programs to calculate trajectories instead of calculating them manually.
What was gained? A new speed and complexity in space flight, requiring careful programming and planning. In fact, without code, little of the remaining missions to space would have been possible, as they all relied on onboard computers to track trajectories. What was lost was a career path for mathematicians, and their agility in responding to urgent needs for calculation in unexpected circumstances. And what remains is a public education system that still teaches the arithmetic used to get us to space.

Later, in the 1990’s, there were fewer than 100 websites, and researchers pondered what the web might be. At the time, most of the valuable information in the world was in libraries, which archived books, newspapers, magazines, and other media. The people that made that information accessible were librarians 7 . Throughout history, the job of librarian have been diverse and ever changing: some librarians select books and other media for inclusion in archives, carefully reflecting on their credibility and significance; some librarians catalog and index, creating organizational schemes that help people browse and search collections; some librarians are experts in domains, helping people not only find answers to their questions, but find the right questions; some librarians teach literacy in schools, helping youth learn to read. It was in this context that the National Science Foundation, the primary research funding agency in the U.S., began investing in research on digital libraries. One project at Stanford funded a project that imagined how library collections might be digitized and search; one of the Ph.D. students on the project, Larry Page, imagined a future where all of the content in libraries was digitized, and developed a recursive algorithm to estimate page relevance, improving the relevance of rankings 11 . With this algorithm, and the many algorithms for crawling, indexing, and retrieval that came before it, Page and his collaborator Sergey Brin co-founded Google, automating much of what librarians had been doing for centuries.
What was gained? Obviously, a transformation in our ability to find and retrieve documents stored on other people’s computers. And when those documents have valuable content, this replicates the benefits of libraries, but does so at far greater speed, scale, and access than libraries had ever achieved. But what was lost was profound: libraries are institutions that celebrate equity, literacy, archiving, and truth. While accessing the information they have may be slower, Google has done little to adopt these values in supporting information archiving and retrieval. Half of the world lacks access to the internet, but most countries have public library systems open to all. Google has done little to address literacy, largely relying on schools and libraries to ensure literacy. Google largely ignores archiving, with the exception of Google Books, mostly documenting what is on the web now, and ignoring what used to be. And perhaps more importantly, Google has largely ignored truth, ignoring the critical role of libraries in archiving and curating credible information, and instead retrieving whatever is popular and current. What remains are two relatively independent institutions: a for-profit one that meets are immediate needs for popular information that has questionable truth, but offers little to address information literacy or inequity, and a not-for-profit one that continues to uphold these values, but struggles to retain public support because of its less than immediate response.

Before the social web, social was personal. To hear about what our friends were doing, people had conversations with their friends. To get recommendations for books or movies, people might go to their local bookstore or library to get recommendations from avid readers, or read a review from a newspaper movie critic. To make food recommendations, people might spend months getting to know the owners of local restaurants, cafes, and diners, building an awareness of industry. Word of mouth, gossip, and sharing was relational and direct. As the social web emerged, algorithms began to mediate these relationships. We were more likely to learn about what our friends were doing because of a post that Facebook’s news feed algorithm decided to recommend to us. Rather than relying on experts and enthusiasts to help us select media, we trusted collaborative filtering algorithms 12 to model our collective interests, and give us more things that people “like” us seem to like. To decide where to eat, we began to rely on averages of star ratings from people we’d never met, of restaurants who decided to pay the Yelp tax 9 . Information about friends and where to shop no longer came from our friends and communities, but ranked, aggregated, models of our social networks and interests.
What was gained? It is certainly less work to keep up with our friends, and less work to decide what to read, watch, eat, and buy—especially social labor, as our interactions no longer need to involve people at all. What was lost were relationships, community, loyalty, and trust. The algorithms built to create digital recommendations are optimized to reduce our decision time, but not to connect us. And we do not yet know the implications of these lost connections on society: will our increased convenience and weakened community ties make us happier by making us more productive and satisfied, or was there something essential to community that we are losing?

While the web began to mediate our connections, the policing in the United States was pondering code as well. Throughout U.S. history, a primary function of policing had been to restrict Black lives 3 . Policing emerged in the 1700’s in South Carolina as slave patrols, which were groups of white men allowed to forcefully enter anyone’s home if they were believed to be harboring people who had escaped bondage. As police departments emerged, they were overwhelmingly White and male, and charged with controlling the “dangerous underclass” of Black Americans, immigrants, and the poor. After the civil war, Jim Crow laws meant that police were charged with restricting Black American’s voting rights, travel, and use of public spaces, while overlooking lynchings and mob murders. And after the Civil Right act, police have focused their patrols on Black neighborhoods for minor drug arrests, while largely ignoring the same violations happening on largely white college campuses. For policing, code was a way to optimize these efforts, prioritizing limited resources to predict crime. For example, the LA Police Department, in 2011, launched Operation LASER , to take data from past offenders in a two-year period, using it to prioritize where they patrol and who they surveil. Such practices increase arrests in those areas 2 . And when the accused are tried, and convicted, course are increasingly using racially-biased algorithms to predict the likelihood at the convicted person will commit future crimes 14 . Police departments are now adopting face recognition software racially biased against dark skin, leading to false arrests like that of New Jersey man Nijeer Parks , who was held in jail for 10 days and had to spend $5,000 in legal fees to prove his innocence.
What is gained? For police departments, they may feel like they are better allocating their time, “optimizing” the number of arrests to reduce crime. What is lost a sense of freedom: Black people have always been surveilled in the United States 3 , but that surveillance was always by other (albeit sometimes racist) people. With data and cameras now constantly monitoring, and doing so in ways that are inaccurate and biased against their skin color, they have to live with being watched by both people and technology, and with the fear that they might be unjustly arrested at any time because a training set in a machine vision algorithm didn’t have enough Black faces to be accurate.

How to automate?
In all of the stories above, there is a similar pattern: people had evolved practices over time to perform some information task, code was used to automate their work, and in the process, the humanity in the task was lost. But there is a pattern underneath these histories that goes deeper: it is the decision to delegate control over our gathering, analysis, and interpretation of information from human, subjective, emotional, and relational human processes to procedural, objective, rational, impersonal computational processes. In that decision is a choice about precisely what aspects of human experience we delegate to processing information, and what new kinds of partnerships we form between people and information technology to help us.
The dawn of computing set up a continuum for these choices. On one end was automationautomation: The delegation of human action to technology, often for the purpose of efficiency or reliability. . This vision—championed by researchers like Marvin Minsky, who is often called the “father of artificial intelligence”—imagined a world in which computers would replicate key aspects of human intelligence such as search, pattern recognition, learning, and planning 8 . In this future, computers would replace people, and even achieve a degree of autonomy. It is this same vision that has led to dreams of driverless cars that transport us to our destinations and autonomous robots that serve and care for us. While these visions are still quite far from being a reality 5 , they continue to capture our imaginations in science fiction, and drive massive public and private investments. They are also the foundation of much of the disruption in the stories above.

The counter narrative to automation was one of augmentationaugmentation: The use of technology to improve or enhance human abilities. . This vision—championed by people like Vannevar Bush 4 and Douglas Englebart, and carried forward through fields like Human-Computer Interaction—imagined a world in which computers did not replace people, but enhance their abilities. In this future, computing is designed not to do our work for us, or make our decisions, but to augment our ability to do these things. Unlike AI, which has struggled to realize its strongest visions of autonomy, augmentation is the reality we live with today: computers have enhanced our ability to access information, to create, and to connect in so many ways. As the capability of computing has expanded, this has led to refinements of augmentation narratives, such as human-computer integration 6 , which imagines computers as more than just enhancing our abilities, but becoming proactive, symbiotic partners in our lives.
Of course, the dichotomy between automation and augmentation is a false one. Computers will likely never be completely independent of humanity, as they will always require us to shape their behavior and intelligence. And as much as we enhance ourselves with computing, we will at some biological level likely always be human, with both our rational minds, and our emotional ones. And in both visions of automation, there is little attention to the inequities and injustices in society that underlie how we create information technology 1 , and how we deploy it into the world 9,10 . The truth is that we have always had to make challenging moral, ethical, and sociopolitical choices about what power we give people and what power we give technology. Sometimes those the consequences of those choices are not clear, and some of us end up with enriched lives, and others end up abused or oppressed. The challenge is trying to know these consequences upfront, before we decide whether and how to automate, and then having the will to do what we think is right.
Podcasts
- What happens when an algorithm gets it wrong, In Machines We Trust, MIT Technology Review . Discusses a false arrest based in racially biased facial recognition software.
- AI in the Driver’s Seat, In Machines We Trust, MIT Technology Review . Discusses the many complexities in human-machine communication that have been largely ignored in the design and engineering of current driverless car technology.
- She’s Taking Jeff Bezos to Task, Sway, NY Times . An interview with Joy Buolamwini, an activist who leads the Algorithmic Justice League, about facial recognition, algorithmic bias, corporate resistance, and opportunities for AI legislation.
- What’s Causing the Tesla Crashes, What Next:TBD, Slate . An interview with Missy Cummings, a safety critical systems researcher at Duke, about driverless cars.
- Biased Algorithms, Biased World, On the Media . Discusses the illusion of algorithmic objectivity and how they end up reflecting the biases in our world.
- An Engineer Tries to Build His Way Out of Tragedy, The Experiment . Discusses the limits of solutionism when facing lived experiences.
References
-
Ruha Benjamin (2019). Race after technology: Abolitionist tools for the new jim code. Social Forces.
-
Jeffrey Brantingham, P., Matthew Valasik, and George O. Mohler (2018). Does predictive policing lead to biased arrests? Results from a randomized controlled trial. Statistics and Public Policy.
-
Simone Browne (2015). Dark matters: On the surveillance of blackness. Duke University Press.
-
Vannevar Bush (1945). As we may think. The atlantic monthly.
-
Thomas G. Dietterich (2017). Steps Toward Robust Artificial Intelligence. AI Magazine.
-
Umer Farooq, Jonathan Grudin (2016). Human-computer integration. interactions.
-
Michael H. Harris (1999). History of Libraries in the Western World. Scarecrow Press.
-
Marvin Minsky (1961). Steps toward artificial intelligence. Proceedings of the IRE.
-
Safiya Noble (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
-
Cathy O'Neil (2016). Weapons of math destruction: How big data increases inequality and threatens democracy. Broadway Books.
-
Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd (1999). The PageRank citation ranking: Bringing order to the web. Stanford InfoLab.
-
Paul Resnick, Neophytos Iacovou, Mitesh Suchak, Peter Bergstrom, and John Riedl (1994). GroupLens: an open architecture for collaborative filtering of netnews. ACM Conference on Computer Supported Cooperative Work and Social Computing.
-
Margot Lee Shetterly (2016). Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space Race. HarperCollins.
-
Sonja B. Starr (2014). Evidence-based sentencing and the scientific rationalization of discrimination. Stanford Law Review.
Information + health
I was born in 1980 at a hospital in rural Oregon. As is still current practice, the staff overseeing my birth peeked at my anatomy, and checked “male” on my birth certificate. For the next 38 years, this one bit of binary health data was the basis for a profound number of experiences in my life. It was entered on forms registering me for public school. My pediatricians used this bit, without ever actually inspecting my body, to shape their preventative health care decisions about my weight, mental health, and risks of eating disorders. And when I turned 18, the government used this bit in its decision to send me U.S. military draft card. This single bit of binary data, far more than my body, shaped the course of my childhood and adolescence, both in health care and beyond. And, of course, I wasn’t a boy, or a man; as a transgender person, that bit was wrong, and it ended up defining more than how people treated me: it ended up defining how I saw myself in devastating ways.
Racing forward to my late thirties, I finally fixed that bit, correcting my birth certificate, health records, my government identification. And because in health care, it more often data that drives decisions, the health care system now treats me as the woman that I am. There’s just one problem: because health information technology is still binary about gender, it leaves no room for the sexual and gender diversity. I have a prostate gland, but I no longer get reminders about prostate exams, and my doctors no longer ask. I do not have a cervix, but I regularly get urgent reminders about overdue pap smears. Physicians unfamiliar with my trans body ask my why I don’t have a gynecologist and I get confused stares in the lobbies of urologists. And when I ask providers about gender-influenced health concerns about heart disease, kidney stones, osteoporosis, and strokes, they either shrug, and say, “There’s no science on your trans body” or they just assume the binary science on gender difference applies, treating me like every other woman.
These experiences, far from being about transgender health alone, reveal the complex interactions between health and information. Data about health is often used as a proxy for our anatomy and physiology, and when that data is biased, it biases care for our health and wellness. Data about our bodies, whether it’s carefully measured or simply assumed by someone looking at our bodies, is used to inform decisions outside health care, in education, work, and government. And science about health, which is our primary guide in shaping health care, is only as good as the data we collect. In the rest of this chapter, we will survey these complexities, mapping their interactions across different scales of our bodies, our selves, our health care systems, and our communities.
DNA as Information
In one sense, all life on Earth is partially influenced by information stored in DNA. First discovered in 1869 by Swiss chemist Friedrich Miescher, it was first called “nuclein”, as it was found in the nuclei of human white blood cells 14 . As its chemical structure was studied further, it was renamed “nucleic acid”. Only after hundreds of research papers later did scientists discover the three major components of a single nucleotide (a phosphate, a sugar, a base), and the carbohydrate components of RNA and DNA (ribose and deoxyribose). No one yet knew how these components were arranged spatially; it wasn’t until Erwin Chargaff, inspired by a major discovery that genes are composed of DNA, launched a research project to understand the structure of DNA, finding that no matter what DNA his team sampled, there was a consistent volume of adenine and thymine, and consistent volumes of guanine and cytosine. This realization eventually led to James Watson and Francis Crick’s use of 3D modeling, first advanced by biochemist Linus Pauling, which led to the famous discovery of the double-helical structure of DNA. This nearly 100 year history of science culminated into a single profound fact of nature: all life that we have observed thus far, is encoded as long sequences of AT, GC pairs, stored in nuclei, used in cell replication. This information, repeatedly replicated more than 30 trillion times in our bodies over our lifetimes, is the basis of our reproduction, of evolution, and often our deaths 15 .
The discovery of DNA has had profound effects on the science of life. For example, biology shifted a discipline of subjective description and classification to one of data analysis. This practice, now called bioinformatics , entails using machines to sequence DNA, algorithms and statistics to analyze DNA sequences, and the broader science of genomics to understand the particular sequences of DNA that contribute to disease 1 . For example, one branch of bioinformatics investigates the parts of DNA that, when mutated through our bodies’ imperfect process of DNA replication, tend to lead to cancerous cells, which tend to ignore critical signals that stop cell division, while also being able to evade our immune systems, and consume resources from blood vessels that other normal healthy cells need. This work is beginning to shape medical practices, helping us detect biomarkers that correlate highly with cancer risk 19 .
Understanding DNA as data also led to the record fast production of the SARS-CoV-2 vaccines in 2020. The virus, first detected by Chinese scientists, was known to have a distinctive “spike”; they quickly sequenced the 29,903 bases of its RNA and shared it globally on January 10th, 2020, just one month after the first identified case. Hundreds of scientists, using methods of bioinformatics, quickly determined that its RNA sequences were very similar to a previously known virus, SARS, another coronavirus. This led to the name SARS-CoV-2. German virologist Christian Drosten, who had long studied coronaviruses , developed the first test for this virus a few weeks later, by detecting particular bases in the virus’s genome. And then, using technology from the 1990’s to create mRNA vaccines that would inject instructions for human cells to producing the innocuous coronavirus spike, Pfizer and BioNTech partnered to construct the first vaccine in just a few weeks. The vaccine, essentially a sequence of RNA wrapped in a fatty acid, teaches our cells how to build the spike, which triggers an immune response that teaches our body to recognize and attack the full virus. The next 6 months involved clinical trials to verify the efficacy of the vaccines. None of this would have been possible, especially so fast, without understanding that DNA and RNA are essentially data. (Nor would it have been possible without decades of public investment in basic research by governments around the world, especially the United States and China.)
Health research as information
How do we know that a vaccine works? Or that any health care practice works? This knowledge, and the processes by which we produce it, are the foundation of modern medical practice. But for most of human history, we lacked this foundation 2 . Physicians had practices that were grounded in faith or superstition. For example, bloodletting was a practice of intentionally removing blood from patients to cure illness and disease, under the theory that blood and other fluids were “humours” that, when in proper balance, would maintain health; removing blood, therefore, was one way to restore “balance”.
These superstitious practices began to shift in the 18th century. In 1747, physician James Lind was trying to address scurvy amongst sailors; amidst the backdrop of the broader scientific revolution of the 18th century, he decided to compare 12 similar patients, dividing them into each given different groups, and giving each different treatments. The ones who were given oranges and lemons were the only ones that recovered quickly led to the first evidence of scurvy as a vitamin-C deficiency. This was one of the first examples of a controlled experiment , or what health sciences usually calls a clinical trial .
The practice of clinical trials advanced from there. In 1811, the first documented use of placebos occurred, using deception to give a treatment that is known to be ineffective, but present it as the treatment being tested. In 1943, the first double-blind trial occurred, ensuring that both the patients and the providers giving treatments, were not told whether the treatment was a placebo. In 1946, the first randomized controlled trial occurred, in which the assignment of patients to the placebo or treatment group was random rather than self-selected or provider selected. All of these improvements, and the countless others that have followed since, have greatly increased the confidence and certainty of the methods by which scientists deem interventions to be effective. And this entire history of producing knowledge was brought to bear in evaluating the SARS-CoV-2 vaccines, to the point where universities and companies have well-established procedures and infrastructure, government units like the U.S. Food and Drug Administration have well-established regulations for evaluating clinical trial results, and medical journals, read widely by medical providers, have well-established norms for objectively reviewing and publishing the results of trials.
While clinical trials are the highest standard in producing knowledge about health interventions, there are countless other research methods used to build knowledge about health and medicine. Descriptive studies can identify new phenomena and theories about health. Correlational studies,—like the kind often reported in journalism indicating that eating some food increases or decreases the risk of some disease—can help generate hypotheses to be later tested in randomized controlled experiments. And qualitative methods, such as interviews, field observations, and ethnographies, can help identify social, cultural, and organizational factors that shape the efficacy of interventions. For example, it doesn’t matter if a drug is effective if someone doesn’t take it correctly, forgets to take it because of a complex dosing schedule, or did not keep the instructions on how to take it because they are homeless. Qualitative methods shape our understanding of why a medication does or doesn’t work, as the reasons are often sociocultural, not physiological.
Regardless of method, the same values, biases, and systems of oppression that affect all data, information, and knowledge, affect health knowledge, resulting in science that supports and highlights the experiences of dominant groups, while often disregarding or erasing the experiences of marginalized groups, or even doing direct harm. For example, a study conducted between 1932 and 1972 of syphilis recruited Black men, telling them that they were receiving free health care from the federal government. The reality, however, was that the government study was observing the natural course of syphilis, and administered no care when it was detected, did not notify the men that they had detected it, and even offered placebos that were known to be ineffective. As a result, hundreds of men died of syphilis, forty partners contracted the disease, and 19 children were born with congenital syphilis. The focus on Black men was explicitly racist 3 , and the lasting generational impact has been a pervasive distrust of medical science amongst Black Americans 6 , further introducing racial bias into the scientific foundations of health care knowledge. This recent history—recent because there are many Black Americans who were participants in this racist exploitation, or whose parents were—has undergirded reasonable skepticism in some Black communities about the safety of COVID-19 vaccines.
Information in health care
From both a patient, modern health care is rife with information problems. When we experience symptoms in our health, we rely on information from friends, family, and increasingly the internet to even decide whether to utilize health care services 17 . When we visit health care providers, we often first interact with medical assistants, who take vital information from our bodies such as our weight, blood pressure, and heart rate. Conversations with physicians are often centered on gathering information about our experiences, including pain or other symptoms, the duration of symptoms, and if they are mindful of social determinants of health 10 , the context of our lives that may be causing or aggravating these systems. If conversation is not enough, providers may order more systematic tests, measuring properties of our blood, stool, urine, bones, skin, and more. All of the information that providers gather goes in medical records, now mostly electronic like the one above, as a central database for data about our anatomy, physiology, and its change over time. And if provider and their team can make a judgement from this information, whether a diagnosis, or some next step for gathering more information, they communicate that to us as information, often giving us printed materials to read, medications to take, or other home remedies to follow, all with instructions that attempt to translate a medical judgement into something we can comprehend and follow.
Of course, the information-driven processes above are rarely so seamless. Patients and clinicians often lack a shared understanding of a patient’s goals 13 . Patients struggle to get the information they need to transition home from hospitals, understand care instructions, and get information about post-care symptoms and complications 7 . People with chronic illnesses struggle to monitor information about their illness and share it with providers 18 . The problem of coordinating care across multiple providers, a patient, and their community is fundamentally an information systems problem, and one poorly supported by technology, health care communication practices, and the varying complexity of health care funding in different countries. The result is that many patients take care into their own hands, using self-tracking technology such as consumer devices like fitness trackers 5 , and even hacking their own monitors. The result is often an even more complex challenge of integrating the data that people have gathered about themselves with the existing information systems of their health care providers 12 .
The provider side of health care from inside these information systems is similarly complex. Providers and hospitals often have few ways to overcome the poor design and usability of electronic medical records other than simply hiring more staff to workaround these problems 16 . Medical records often fail to capture emotional information in facial expressions and voice, crucial to critical care and emergency room practice 11 . And at the heart of many of these challenges are the new and underlying information technology challenges that store, retrieve, and secure medical data, creating issues of poor data interoperabilityinteroperability: The ability to move and translate data structures between different systems without losing data or changing its meaning. between health care silos, complexities of regulatory compliance with privacy policy like HIPPA, and the regular disruptions of IT in general, such as confusing software updates, internet outages, and hardware failures 8 . Many of these problems emerge from the fragmentation of decentralized health systems; countries that invested in universal health care systems post World War II benefit from much more uniform, centralized systems, simplifying improvements and eliminating many interoperability problems.
Atop all of these challenges with individual patients are population health challenges 9 , which consider entire communities of people and their health. Population health includes disciplines like epidemiology, which gathers, analyzes, and reports data about both determinants of health, as well as diseases, through populations. This includes people charged with detecting and preventing the spread of deadly bacteria and viruses, as well as people monitoring the use of substances like nicotine and other controlled substances. Complementing epidemiology is public health , which is more concerned with proactively preventing disease and promoting wellness. This discipline focuses on disseminating information, including providing health education to prevent deterioration of health. For example, public health practitioners lead efforts on safe sex campaigns, needle-exchange programs to prevent the spread of communicable diseases through reused needles, and advocating for smoking cessation. At the heart of both of these disciplines are questions of health equity, which recognize that in many societies, only some people have the resources they need to stay healthy and well. This increasingly includes information and technology resources, such as access to the internet and health information technologies, like blood sugar monitors for patients with diabetes.

At the foundation of all of these intersections between information and health are issues of diversity, equity, and inclusion. Biology is inherently diverse, human experiences are inevitably diverse, and yet so much of our understanding of DNA, effective medicine, and population health stems from studies that often systematically exclude significant parts of that diversity, or erase it through aggregate statistics. These practices of supporting health through a lens of dominant groups results in systemic inequality in who is treated, who is treated effectively, and therefore who lives long, healthy lives. Challenges in information and health, therefore, are fundamentally health equity challenges 4 , and how we gather, store, and use information about our health is at the center of how we ensure equity.
Podcasts
For more about the intersection of health and information, consider these podcasts:
- The Ashes on the Lawn, Radiolab . Describes the history of HIV/AIDS advocacy, and the response of the U.S. federal government to this advocacy.
- The Great Vaccinator, Radiolab . Describes the contributions of Maurice Hilleman, inventor of more than 40 vaccines, many routinely given to children.
- The Science Behind The Historic mRNA Vaccine, Short Wave . Describes the science behind the mRNA technology used in the Pfizer-BioNTech COVID-19 vaccine.
- Down and Dirty with Covid Genes, In Machines We Trust, MIT Technology Review . Describes the many ways that DNA scrubbing and machine learning is being used to detect and treat disease.
- The Rise of Therapy Apps, What Next TBD, Slate . Discusses a new genre of therapy apps intended to scale access to mental health, as well as their limitations, and the risks of lowering the bar on care.
- How AI is giving a woman back her voice, In Machines We Trust . Discusses applications of voice recognition in health care.
- What Does It Mean to Give Away Our DNA?, The Experiment . Discusses the tensions between genetic testing and Indigenous communities.
- The Downfall of One of the World’s Biggest Brains, What Next TBD . Discusses IBM Watson’s failulre to transform health care.
References
-
Andreas D. Baxevanis, Gary D. Bader, David S. Wishart (2020). Bioinformatics. John Wiley & Sons.
-
Arun Bhatt (2010). Evolution of clinical research: a history before and beyond James Lind. Perspectives in Clinical Research.
-
Allan M. Brandt (1978). Racism and research: the case of the Tuskegee Syphilis Study. Hastings Center Report.
-
Paula Braveman (2006). Health disparities and health equity: concepts and measurement. Annual Review of Public Health.
-
Daniel A. Epstein, Monica Caraway, Chuck Johnston, An Ping, James Fogarty, and Sean A. Munson (2016). Beyond abandonment to next steps: understanding and designing for life after personal informatics tool use. ACM Conference on Human Factors in Computing Systems.
-
Vicki S. Freimuth, Sandra Crouse Quinn, Stephen B. Thomas, Galen Cole, Eric Zook, and Ted Duncan (2001). African Americans’ views on research and the Tuskegee Syphilis Study. Social Science & Medicine.
-
Shefali Haldar, Sonali R. Mishra, Maher Khelifi, Ari H. Pollack, and Wanda Pratt (2019). Beyond the Patient Portal: Supporting Needs of Hospitalized Patients. ACM Conference on Human Factors in Computing Systems.
-
William Hersh (2004). Health care information technology: progress and barriers. Journal of the American Medical Association.
-
David Kindig and Greg Stoddart (2011). What is population health?. American Journal of Public Health.
-
Michael Marmot, Richard Wilkinson (2005). Social determinants of health. OUP Oxford.
-
Helena M. Mentis, Madhu Reddy, and Mary Beth Rosson (2010). Invisible emotion: information and interaction in an emergency room. ACM Conference on Computer Supported Cooperative Work and Social Computing.
-
Helena M. Mentis, Anita Komlodi, Katrina Schrader, Michael Phipps, Ann Gruber-Baldini, Karen Yarbrough, and Lisa Shulman (2017). Crafting a View of Self-Tracking Data in the Clinical Visit. ACM Conference on Human Factors in Computing Systems.
-
Ari H. Pollack, Sonali R. Mishra, Calvin Apodaca, Maher Khelifi, Shefali Haldar, and Wanda Pratt (2020). Different roles with different goals: Designing to support shared situational awareness between patients and clinicians in the hospital. Journal of the American Medical Informatics Association.
-
Leslie A. Pray (2008). Discovery of DNA structure and function: Watson and Crick. Nature Education.
-
Wynand P. Roos, and Bernd Kaina (2006). DNA damage-induced cell death by apoptosis. Trends in molecular medicine.
-
Gordon D. Schiff, and Laura Zucker (2016). Medical scribes: salvation for primary care or workaround for poor EMR usability?. Journal of General Internal Medicine.
-
Kendra L. Schwartz, Thomas Roe, Justin Northrup, James Meza, Raouf Seifeldin, and Anne Victoria Neale (2006). Family medicine patients’ use of the Internet for health information: a MetroNet study. The Journal of the American Board of Family Medicine.
-
Lisa M. Vizer, Jordan Eschler, Bon Mi Koo, James Ralston, Wanda Pratt, and Sean Munson (2019). “It’s Not Just Technology, It’s People”: Constructing a Conceptual Model of Shared Health Informatics for Tracking in Chronic Illness Management. Journal of Medical Internet Research.
-
Duojiao Wu, Catherine M. Rice, and Xiangdong Wang (2012). Cancer bioinformatics: A new approach to systems clinical medicine. BMC Bioinformatics.
Information + democracy
The first time I was eligible to vote was in the 2000 U.S. elections. I was a sophomore in college. As an Oregonian, voting was a relatively simple and social affair. I was automatically registered to vote. About one month before the election, I received a printed voter’s pamphlet that gave the biographies and positions of all of the candidates, as well as extensive arguments for and against various ballot measures (a form of direct democracy that bypassed the state legislature). Two weeks before the election, I received my ballot. My roommates and I organized a dinner party, gathering friends to step through each decision on the ballot together, making the case for and against each candidate and issue. At the end of the night, we had completed our ballots, shared our positions on the issues, and went outside to place them in the secure mailbox on our street.
Two years later, when I moved to Pittsburgh, Pennsylvania, my voting experience in the mid-term elections was quite different. I wasn’t automatically registered; doing that required submitting a registration form and proving my residence. There didn’t seem to be a mail-in ballot process or information online, so I went to the local library to ask about voting. They told me to go to my local polling place on election day, but they had no information about where my polling place was. I asked my neighbors and they said it was at the local elementary school a mile away. There was no voter’s guide, and so I had to read the news to keep track of who was running and what their positions were, and watch television to see their advertisements. And on election day, I memorized who and what I was voting for, walked with my daughter to the school, and then waited in a line for 45 minutes. Inside, I had to show my ID, then enter a voting booth, then punch holes in a large, confusing paper ballot machine with a mechanical arm, while I tried to recall my position on various candidates and issues. My daughter and I left with some civic pride at having expressed our preferences, but I longed for the sense of community I had in Oregon, where voting was on my schedule, in my home, with my friends, family, and community.
Both of these stories are at the heart of democracy, where individuals, with their communities, gather information about people and issues, use that information to develop preferences around how society should work, and then express those preferences through voting, where their preferences are either directly implemented, or implemented by elected representatives. This entire process is, in essence, one large information system, designed to ensure that the laws by which we govern ourselves reflect our wishes. In the rest of this chapter, we will discuss the various parts of this information system, surfacing the critical roles that information plays in ensuring a functioning democracy. Throughout, we will focus on the United States, not because it is the only or best democracy, but because it is the longest active democracy. But throughout, we will remember that there are democracies all over the world, as well as countries with different systems of government, each influencing each other through politics, culture, and trade.

Information and political systems
There are many forms of political systems that humanity has used in history. One of the first might simply be called anarchyanarchy: The absense of any form of government. , in which there are no governing authorities or laws that regulate people’s interactions. In these societies, the primary force driving social interactions is whatever physical power or intellectual advantage a person have bring to protect themselves, their property, and their community. In an anarchy, information may play a role in securing individual advantage, but otherwise has no organized role in society, since there is no society. Such a system maximizes individual choice, but at the expense of safety, order, and human rights.
Authoritarianauthoritarianism: A system of government that centralizes power. systems centralize power in one or more elite leaders, who handle all economic, military, foreign relations, leaving everyone else with no power or representation, and usually a strict expectation of obedience to those leaders. These include military dictatorships in which the military controls government functions, single-party dictatorships like that in China or North Korea, or monarchic dictatorships, in which power is centralized in kings, queens, and people of other royal descent inherent power. In authoritarian systems, leaders tend to tightly control information, as well as spread disinformation, in order to keep the public uninformed and retain power. For example, authoritarian governments rely heavily on public education and public ownership of the media to indoctrinate youth with particular values 9 . Countries like China also greatly regulate the internet, blocking access to foreign tools and censoring information that is inconsistent with the ideas of the Chinese Communist Party. From the perspective of an authoritarian leader, this is key to retaining power: the more accurate information citizens can get about an authoritarian regime’s ability to resist an uprising, the more likely a regime is to be overthrown 3 . Such efforts, however, are only one factor in shaping what political information people do and do not receive 19 .
Democracydemocracy: A system of government that distributes power. , in contrast to anarchy and authoritarianism, is fundamentally an information-centered political system 2 . Rather than giving power to particular people, it attempts to gives power to all people to shape society, and relies on each individual to gain enough knowledge to make informed decisions about how society should function and who should lead it 10 . Unlike anarchy, where information is scarce, and authoritarianism, where information is controlled, democracies rely on an abundance of information, broadly shared to all citizens, to inform the public. Democracies also rely on carefully designed information gathering processes, to solicit preferences in voting. Democracies rely on information aggregation processes, to decide what magnitude of majority is required for someone to be given power, or for a new law to be passed. And democracies rely on transparency of laws and decisions to maintain trust in those granted power. Without functional information systems for these key processes, democracies fail: a lack of information about candidates can influence voting strategies 20 ; fraudulent voting processes and opacity in leader’s decisions reduce faith in the system itself 14 .
Systems of government, of course, do not operate in isolation. Our modern world is global and interconnected; people move across the world, sharing ideas, culture, practices, and information. What happens in one country like the United States or China affects what happens in other countries, whether this is a law that is passed or a shift in culture.
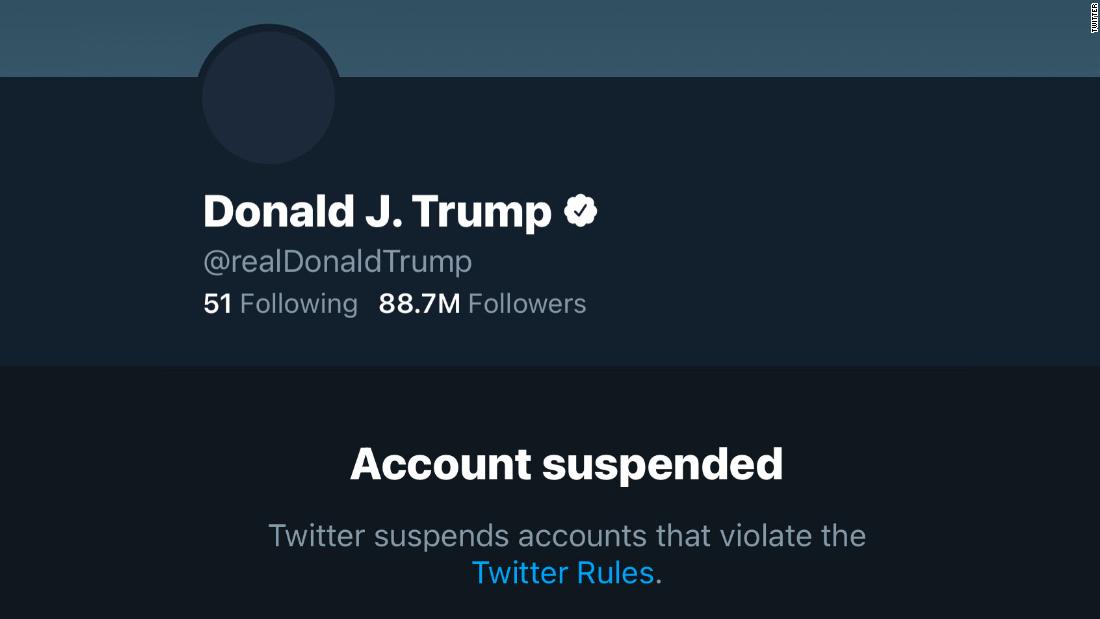
Political speech as information
In the United States’ democracy, one of the central principles underlying an informed public is a notion of free speech . Its first amendment, for example, reads:
Congress shall make no law respecting an establishment of religion, or prohibiting the free exercise thereof; or abridging the freedom of speech, or of the press; or the right of the people peaceably to assemble, and to petition the Government for a redress of grievances.
Underlying this law is the idea that people should be free—in the sense that the government shall not constrain—what people believe or say and who they organize with to say it, especially when they are saying something about the government itself. However, also implicit in this statement is that it only limits the government from abridging or limiting someone’s speech: it says nothing about a business limiting someone’s speech by removing them from a platform, or firing them as an employee; it says nothing about a community banning someone from a forum in which they are speaking; and it certainly says nothing about enforcement of limits on speech in homes, places of worship, or other private settings. The limit, at least in the U.S., is primarily on the government. In fact, part of the protection the government is offering is the freedom for individuals and private enterprises to censor as they see fit, without government intervention.
Of course, in the U.S., and in many other countries, there are some forms of speech that the government can limit, often concerning speech that does harm. In the U.S., libel is an illegal form of defamation in print, writing, pictures, or signs that harms someone’s reputation, exposes someone to public hatred. Slander is a similar form of defamation made orally. Both tend to require proof of damage. Other laws in the U.S. also limit fraud, child pornography, speech that is integral to illegal conduct or incites illegal actions. Therefore, even in the U.S., which is regarded as having some of the strongest speech protections, speech has limits, and political speech is included in these limits.
Political speech, of course, is the foundation of information systems that ensure an informed public to support democratic decisions. It ensures that communities can form around issues to advocate for particular laws or representatives 21 . It’s what allows people running for public office to purchase advertisements in print, television, and online to share information about their beliefs and priorities. It’s what allows the press and it’s journalists to report on political activity. It’s what allows lobbyists to organize as businesses, advocating for particular laws, and even drafting example laws for lawmakers to consider in their legislative work. In principle, these various kinds of organizing rely fundamentally on free speech protections, and are all oriented toward informing the public.
Many debates about politics concern limits on speech. For example, should politicians be able to take limitless money from any source to support their campaigns? This campaign financing question is fundamentally about whether giving money is a form speech. If it is, then the 1st amendment would say yes: the government has no role in limiting that speech. But if it is not speech, then the government may decide to pass laws to place limits on campaign donations, as it has in the past. Of course, what counts as speech is closely tied to what counts as information: giving money is clearly one way to send a signal, but it also entails granting economic power at the same time. Perhaps the difficulty of separating the information and resources conveyed in donations is why it is so tricky to resolve as a speech issue 7 .

Other questions concern the role of private business in politics in limiting political speech. For example, newspapers have long had reporters that attend U.S. presidential press briefings, and editorial boards that decide what content from those briefings might be published. These editorial judgments about political speech have rarely led to controversy, because there are multiple papers that make different editorial judgments. But social media platforms, as a different kind of publisher, are in the same position, protected by the 1st amendment by the right to decide what speech is allowed on their platforms, with the option of limiting speech. For example, on January 8th, 2021, Twitter permanently suspended the account of former President Trump after he incited mob violence on the U.S. capital. And then, shortly after, Amazon decided to withdraw web hosting support to Parler , a popular Twitter clone often used by right-leaning politicians and individuals, notable for its strict free speech commitments. Both of these cases are examples of private enterprise limiting political speech, firmly protected by the 1st amendment, by engaging in content moderation 22 . Should they have that protection?
Notably, there are no speech protections in the U.S. or other countries that outlaw lies, disinformation, or misinformation in politics. Politicians can misrepresent their positions, spread false information, lie about their actions and intents, and intentionally deceive and manipulate the public with information. As long as it does not incite illegal activity or provably cause damage, lying and deception are generally legal (although not without social consequence). Because the U.S. government currently has no policy that speaks to how to handle lies and deception in political contexts, it is left to the public and private organizations to manage it. Some social media sites flag it, and link to fact checks; others limit its amplification; others simply let it be. Individuals are then left to make their own judgments about the speech when forming their political preferences. Some argue that social media has accelerated and amplified radicalization and conspiracy theories, fragmenting political information landscapes 11 . Some argue that this is the price to pay for supporting civil society 17 ; others argue that even in the presence of free speech, there must be efforts to detect and dismantle strategic information campaigns that spread disinformation and online manipulation 18 .
Because the political information systems in democracies are so free, diverse, and varied in their purpose, synthesizing information into informed political preferences is challenging. Newspapers publish opposing viewpoints; advertisements might lie, misrepresent, and deceive; politicians themselves in public debates might focus more on rhetoric than policy; and social media, written by people with myriad motives, and amplified by platforms and a public that spends little time evaluating the credibility of what they are sharing, create noisy feeds of opinion. If democracies rely on an informed public to make sensible votes, modern information systems only seem to have made making sense of this information more challenging.
Voting information systems
However a person forms their political preferences in a democracy, preferences ultimately become votes (if someone decides to vote). Votes are data that convey a preference for or against a law or for or against a representative. Because votes in a democracy are the fundamental mechanism behind shaping policy and power, voting systems, as information systems, have strict requirements:
- They must reliably capture someone’s intent. In the 2000 U.S. elections, for example, this became a problem, as some of the paper balloting systems in the state of Florida led to ambiguous votes (known as “ hanging chads ”), and debates about individual voter’s intents.
- They must be secure 23 . It is critical that each individual only votes once and that votes are not changed. This requires tracking voter identity and having an auditing trail to verify that the vote, as captured, was not modified, and was tallied correctly.
- They must be accessible 12 . If someone cannot find how to vote, cannot find where to vote, cannot transport themselves to record a vote, cannot read the language in which a ballot is printed or displayed, or cannot physically record their vote because of a disability, they cannot vote.
All of these are fundamentally information system problems, and without faith that all of these properties are maintained, the public may lose faith in the power of voting as a way to express their preferences. This happened in Florida when ballots with hanging chads were tossed out. This happened in the 2020 U.S. elections with (unfounded) fear of mail-in ballot security. And it has happened throughout U.S. history as the country and it’s states have made voting harder for Black people, disabled people, and immigrants not fluent in English to vote (and only after centuries of not allowing Black people and women to vote at all). And it continues to happen in many states through strict voter ID laws, voter purging that effectively unregisters individuals from voting rolls, and reductions in the hours and availability of polling places 1 . Such efforts appear to ultimately reduce voting access equally across all racial groups 15 , and for no actual gains in election security.
But voting alone is only part of voting information systems. Laws also shape how votes are tallied, aggregated, and used to distribute power. For example, in the United States, state legislatures and the U.S. Congress are composed of elected representatives from different regions of the country. These regions, usually called districts , are geographical boundaries. These boundaries are drawn by politicians, and for some time, have been drawn in a way that clusters voters with similar preferences together, to limit their influence on elections. For example, a common strategy is drawing boundaries around Black neighborhoods, so all of the Black vote is concentrated toward electing one representative, limiting their impact on the election of other representatives. This practice, called gerrymandering 13 , intentionally reduces the power of particular votes to shape election outcomes. A similar example is the U.S. electoral college 4 , which is a system by which votes are tallied to select electors, who then elect the U.S. President. The system was originally designed to limit the power of the public to shape election outcomes, concentrating power amongst “men of virtue”, out of fears that the public did not have the information needed to make informed voting decisions. In this system, electoral college votes were distributed on the basis of the U.S. census, which counted the number of people living in each state; the system, however, shaped by White supremacists, only counted enslaved Black Americans as 3/5ths of a person in the allocation of electoral college votes.

Laws as information
Whatever the outcome of voting, and however votes are tallied, the result is a temporary granting of power to make, enforce, or interpret laws. Like speech and voting, lawmaking is requires information systems as well.
Consider, for example, the problem of knowing the laws: one cannot follow the laws if one does not know them, and yet actually seeing the law can be challenging. One source of information about laws is public signage: speed limit signs, for example, efficiently communicate driving laws, and parking signs attempt to explain parking laws. Law enforcement, such as police, might be a source of information about laws: if you violate a law and they see it, or are notified of it, they may communicate the law to you; they may arrest you, and communicate the charge against you only after you are in jail. At one point, the state of Georgia actually had its laws behind a paywall , preventing residents from even accessing the law without money. In contrast, the Washington state legislature’s Revised Code of Washington website , makes all of the state’s laws freely searchable, browsable, and accessible to anyone with access to a web browser. Even such websites, however, do not make it easy to know which laws apply to our behavior, as they may use language or ideas we do not know, or may need to be legally interpreted.
Another kind of information system is the process by which elected representatives make laws. Representatives might have committee meetings, they might draft legislation for comment by other legislators, they may hold public meetings to solicit feedback about laws, and they may hold votes to attempt to pass laws. Democracies vary in how transparent such processes are. For example, in some U.S. states, only some of these processes are public and there is no information about other legislative activities. In contrast, in Washington state where I live, there is a public website that makes visible all of the committee schedules, agendas, documents, and recordings , including features for tracking bills, tracking representative activity, and even joining a list of citizens who want to give testimony at meetings. These varying degrees of transparency provide different degrees of power to individuals to monitor and shape their representative’s activities.
Lobbyists, who advocate to lawmakers around particular issues 5 , also vary in their visibility. U.S. states vary on what lobbyists are required to make public about their activities. Some states require them to document meetings they have with representatives, others require records of money given by lobbyists to particular politicians. In Washington state, there is a public website showing all of the campaigns for state offices and courts , all of the financial gifts given to those campaigns, as well as records of lobbying activities. Any citizen concerned about who is influencing their elected representative can gather data about this influence, and advocate against it.
Law enforcement, including everything from parking enforcement, to police, to federal fraud investors and internal ethics committees, also relies on and interfaces with information systems. Internally, they may gather data about crimes committed, keeping records of crimes, gathering information evidence. Some law enforcement agencies in the U.S. have even gone as far as using crime data to make predictions about where future crimes might occur, to help them prioritize their policing activities. Because these data sets encode racist histories of policing, the predictions are racist as well 6 , resulting in policing that prioritizes Black neighborhoods, and de-prioritizes crimes by other racial groups, including those that might be “white collar” (banking fraud, illegal trade, insider trading). When this crime data is made public (e.g., the Seattle Police data maps ), it can increase transparency about police activity and support advocacy against police bias and violence.
Lastly, the interpretation of law is central to democracy, but is also fundamentally an information system, as with law making. In the United States, judges and lawyers primarily interpret the law. Their job is essentially one of reading the text of laws and prior decisions and trying to test the specific details of a case against the meaning of the law and prior decisions about it. This process is inherently one concerned with information 16 : What law is relevant to a case? What decisions are relevant to a case? What do the words in those cases and decisions mean? What did they historically mean? Not only is legal work itself fundamentally about information, but because interpretations about laws shape their enforcement, the public in a democracy also needs to access judicial interpretation of law. For example, as a transgender person, I was particularly eager to learn the decision of Bostock v. Clayton county, which the U.S. Supreme Court heard in 2020 to decide whether the Civil Rights Act of 1964 granted the same anti-discrimination protections to transgender people. Because the federal website supremecourt.gov makes public all of the filings, opinions, oral arguments, and case documents released by the court, I was able to read the decisions at the same time as journalists.

While all information systems are important to someone for some reason, few information systems affect everyone in a democracy. Democratic information systems, however are an exception: the means by which we get political information, the systems we use to vote and to access and understand laws are fundamental to our basic rights and safety, and essential to preventing democracies from resisting authoritarianism or anarchy 8 . And the activities and decisions of one democracy—especially one like the United States, with its immense economic and cultural power—have great consequences on our interconnected global community. Finding ways to secure, improve, and strengthen these systems through careful analysis and design is therefore central to not only building trust in the systems, but building faith in the stability and merit of democracy, and achieving justice globally.
Podcasts
For more about information and democracy, consider these podcasts:
- If You Were on Parler, You Saw the Mob Coming, Sway, NY Times . Host Kara Swisher interviews Parler CEO John Matze, who defended the platform’s lack of content moderation as a neutral town square, even after the violent insurrection at the U.S. capitol on January 6th. His positions in this interview led Amazon to stop providing web hosting on January 11th, 2020.
- Deplatforming the President, What Next, Slate . Host Lizzie O’Leary discuss the history behind content moderation and Twitter’s decision to suspend the president’s account.
- Shame, Safety and Moving Beyond Cancel Culture, The Ezra Klein Show, NY Times . Host Ezra Klein faciliates a discussion with YouTuber Natalie Wynn (ContraPoints) and writer Will Wilkinson about the culture of shame that underlies social media cancellation mobs, and the surprising ways this culture might be eroding democracy.
- The People Online Justice Leaves Behind, What Next: TBD . Discusses how those at the margins in the U.S. justice system were even less well-served online.
- How Minnesota Spied On Protesters, What Next: TBD . Discusses police surveillance of protestors.
References
-
Carol Anderson, Dick Durbin (2018). One Person, No Vote: How Voter Suppression Is Destroying Our Democracy. Bloomsbury.
-
Bruce Bimber (2003). Information and American democracy: Technology in the evolution of political power. Cambridge University Press.
-
Chris Edmond (2013). Information manipulation, coordination, and regime change. Review of Economic Studies.
-
George C. Edwards III (2019). Why the Electoral College is bad for America. Yale University Press.
-
Richard L. Hall, and Alan V. Deardorff (2006). Lobbying as legislative subsidy. American Political Science Review.
-
Bernard E. Harcourt (2008). Against prediction: Profiling, policing, and punishing in an actuarial age. University of Chicago Press.
-
Deborah Hellman (2010). Money Talks but It Isn't Speech. Minnesota Law Review.
-
Steven Levitsky, Daniel Ziblatt (2018). How Democracies Die. Crown.
-
John R. Lott, Jr. (1999). Public schooling, indoctrination, and totalitarianism. Journal of Political Economy.
-
Arthur Lupia (1994). Shortcuts versus encyclopedias: Information and voting behavior in California insurance reform elections. American Political Science Review.
-
Andrew Marantz (2020). Antisocial: Online extremists, techno-utopians, and the hijacking of the American conversation. Penguin Books.
-
Tetsuya Matsubayashi, and Michiko Ueda (2014). Disability and voting. Disability and Health Journal.
-
Nolan McCarty, Keith T. Poole, and Howard Rosenthal (2009). Does gerrymandering cause polarization?. American Journal of Political Science.
-
Brian Randell, Peter YA Ryan (2006). Voting technologies and trust. IEEE Security & Privacy.
-
Rene R. Rocha, Tetsuya Matsubayashi (2013). The politics of race and voter ID laws in the states: The return of Jim Crow?. Political Research Quarterly.
-
Manavalan Saravanan, Balaraman Ravindran, and Shivani Raman (2009). Improving legal information retrieval using an ontological framework. Artificial Intelligence and Law.
-
Clay Shirky (2011). The political power of social media: Technology, the public sphere, and political change. Foreign Affairs.
-
Kate Starbird, Ahmer Arif, Tom Wilson (2019). Disinformation as collaborative work: Surfacing the participatory nature of strategic information operations. Proceedings of the ACM on Human-Computer Interaction.
-
Harsh Taneja, Angela Xiao Wu (2014). Does the Great Firewall really isolate the Chinese? Integrating access blockage with cultural factors to explain Web user behavior. The Information Society.
-
Michal Tóth, Roman Chytilek (2018). Fast, frugal and correct? An experimental study on the influence of time scarcity and quantity of information on the voter decision making process. Public Choice.
-
Emily Van Duyn (2020). Mainstream Marginalization: Secret Political Organizing Through Social Media. Social Media+ Society.
-
Sarah Myers West (2018). Censored, suspended, shadowbanned: User interpretations of content moderation on social media platforms. New Media & Society.
-
Scott Wolchok, Eric Wustrow, J. Alex Halderman, Hari K. Prasad, Arun Kankipati, Sai Krishna Sakhamuri, Vasavya Yagati, and Rop Gonggrijp (2010). Security analysis of India's electronic voting machines. ACM Conference on Computer and Communications Security.

Information + sustainability
I grew up near Portland, Oregon in the 1980’s and 1990’s. At the time, and even more so now, it was a place where the environment was front and center in daily life. Recycling was mandatory, with steep fines for not properly sorting cans and bottles, or placing something recyclable in the garbage. Community gardens were everywhere, with prominent public composting and vibrant collections of neighborhood greens. My public primary school taught us Native perspectives on relationships to nature, detailed histories of overfishing of northwest salmon, and depicted our fragile human existence as protected by a thin layer of ozone, protecting us from the sun’s radiant ultraviolet light. Bicycles were everywhere, I regularly saw cars that ran on biofuel, and most school field trips involved hiking into the woods to literally hug trees, thanking them for absorbing the dangerous carbon dioxide we emitted with every breath.
And yet, as I entered graduate school, and begin to attend academic conferences, I did not think twice about my trips around the world. In just six years of study, I flew from Pittsburgh to Florida, Rhode Island, San Francisco, Austria, New Zealand, Italy, China, the United Kingdom, Alberta, British Columbia, California, Missouri, Germany, Nebraska, Colorado, India, Massachusetts, Georgia, Switzerland, and back home to Portland at least twelve times. Despite all of the cans, bottles and paper I recycled, all of the lights I diligently kept off, all of the trees I planted, all of the buses I rode, and all of the donations I’d made to saving fish and rain forests, in those six or so flights per year, my family’s carbon output went from an already very high 15 tons of CO2 per year (mostly from our use of inefficient natural gas radiators and driving), to 40 tons of CO2. There simply was no information or feedback about my behavior on carbon output, or its broader impact on climate change.
These two stories show how entangled climate change is with information: the journalism and education shape our understanding of long term consequences of our behavior on the planet; feedback about our energy use shapes our future behavior; and as we inevitably face the increase in frequency and severity of global warming crises, information will be ever more central in helping humanity respond to crisis and survive. What kinds of information systems about sustainability do we need to survive?

The information system of climate science
While there are many sustainability issues that humanity faces—from issues of biodiversity, air pollution, energy sources, waste management, and water scarcity—climate change interacts with all of these, threatening to overheat us, eliminate our access to food and water, flood our coastal towns and cities, and fill our air with toxic smoke from wildfires. At the heart of understanding these climate phenomena has been information, carefully gathered over a century of diligent scientific work. And at the heart of our reluctance to change our behavior has been the challenge of communicating this information to the public, as well as the active sharing of misinformation and disinformation by fossil fuel companies and politicians.
The information story of climate science begins in the 18th century, when scientists were just beginning to build rigorous foundations of physics, chemistry, biology, and human behavior. One of the first major discoveries about climate came from geologists, who had just begun to notice in their examination of the many diverse layers of materials in rocks and Earth that there had been a succession of geological ages, and that the Earth might have a hot volcanic core that explained these various layers. While geologists studied the Earth’s crust, national weather agencies began measuring temperature, rainfall, and other weather phenomena in the Earth’s atmosphere. Most of this data was regional, most of the scientific modeling was primitive, with statistics still in its infancy, and there were not yet theories about how such local effects can have global consequences. There were, however, many conflicts between these emerging sciences and religion, which had conflicting accounts of the age of Earth 16 .

At the turn of the 19th century, scientists began to take the regional information about Earth and its atmosphere and integrate it into more global theories about Earth’s history 15 . Most notably, in 1815, Jean-Pierre Perraudin noticed giant granite rocks normally found on glaciers scattered around the valley known as Val de Bagnes, and tried to imagine ways that these giant boulders might have moved. He also observed that glaciers had left visible stripes on land. He theorized that the glaciers had moved across land over time, depositing the boulders across the land. Though many scientists were skeptical of this movement, they were intrigued enough to test his hypothesis. Evidence of similar glacial movement in many other regions led geologist Louis Agassiz to develop a theory of the “Ice Age”, a time at which glaciers covered Europe and much of North America 5 . The new implication of the ice age theory was that the temperature of Earth must change over time, raising questions about how and why it does.
Meanwhile, physicists were trying to explain how the Earth remained so warm when space was so cold. In 1824, Joseph Fourier hypothesized that Earth had an “atmosphere” that caused light from the sun to be absorbed and emit infrared radiation in response, increasing surface temperatures of Earth, like a greenhouse captures the heat from light. This led to the emergence of atmospheric science, leading to several laboratory discoveries that tested Fourier’s theory of atmosphere, eventually discovering that water vapor, and hydrocarbons like methane and carbon dioxide strongly block radiation, suggesting that increases in carbon dioxide might result in less heat escaping from the atmosphere, warming the planet. Notably, inventor, scientist, and women’s rights activist Eunice Newton Foote demonstrated in 1856 that carbon dioxide trapped more solar heat than other gases, theorizing that the more the atmosphere was composed of it, the warmer the Earth might get. At the time, she wasn’t given credit and her paper wasn’t included in the proceedings, since the AAAS professional society didn’t allow women members. Her work was read by a man and his reading was published under his name, eventually leading scientists to build upon her observations. These later experiments in the 19th century confirmed Foote’s observed association between carbon dioxide in the atmosphere and the Earth’s temperature 1 , and geologists begin seeing the same effects in the sedimentary layers associated with the ice age. These early studies began to explain why and how the planet’s temperature changes.
Thus began a race at the beginning of the 20th century to try to understand the causes behind the correlations between carbon dioxide and temperature. Early experiments did not show strong relationships between significant sources of carbon output, such as the burning of coal, and infrared absorption. But it turned out that these early experiments were just not accurate enough; later experiments with more precise instruments confirmed the effects. Geologists tested theories of natural variation in climate over history by examining tree rings, but early efforts struggled to rigorously distinguish tree ring patterns from noise. It wasn’t until the 1950’s, with improved spectrography (methods of measuring light composition), that scientists observed that there was little water vapor in the atmosphere, and so most variation was explained by carbon dioxide released from fossil fuels, which was not absorbed by the ocean. In the 1960’s, the advent of computers led to even more sophisticated versions of Arrhenius’s models from sixty years earlier, precisely modeling and predicting the Earth’s slow rise in temperature using from many factors, including carbon output 8 . After two hundred years of data gathering, hypothesizing, modeling, and theory refinement and rejection, there was only one explanation remaining that was consistent with the data: more carbon, less radiation absorption, a hotter planet, and increases in carbon were coming from exponential increases in human burning of fossil fuels.

In a landmark report, U.S. President Lyndon B. Johnson’s science advisory committee brought this emerging consensus into public policy, warning of the potential negative effects of fossil fuel emission:
The part that remains in the atmosphere may have a significant effect on climate; carbon dioxide is nearly transparent to visible light, but it is a strong absorber and back radiator of infrared radiation, particularly in the wave lengths from 12 to 18 microns; consequently, an increase of atmospheric carbon dioxide could act, much like the glass in a greenhouse, to raise the temperature of the lower air.
As these warnings entered politics, the strength of the scientific evidence increased. By the 1980’s scientific consensus emerged through multiple sources of evidence from decreased aerosol pollution, increased fossil fuel use, and increase chlorofluorocarbons (CFCs), were all consistent with theories of carbon’s effect on infrared radiation deflection. Building on this consensus, research on climate change expanded, linking atmospheric sciences, computer models, geology, and even economics and behavioral sciences, expanding the natural science consensus to a consensus spanning all of academia. Climate scientist James Hansen, gave landmark testimony in 1988 to the U.S. Congress, sharing the consensus view of 200 years of data collection and modeling:

Global warming has reached a level such that we can ascribe with a high degree of confidence a cause and effect relationship between the greenhouse effect and observed warming...It is already happening now... NASA is 99% confident that the warming is caused by the accumulation of greenhouse gases in the atmosphere and not a random fluctuation.
While this consensus emerged, journalists and politicians struggled to report and act on the scientific warnings. Some news outlets exaggerated the reports, predicted imminent doom, then creating skepticism after the dire effects predicted by journalists did not materialize. Fossil fuel companies, protecting their interests, spread disinformation about climate change for decades. And public education in the U.S., mostly omitting education on climate science, and often providing arguments contrary to scientific consensus, created generations of youth confused and skeptical about its effects. Climate change activists, including former U.S. Vice President Al Gore emerged, engaging in public education on the climate science evidence in 2006, providing the most distilled versions of the science for to develop climate literacy.
And that distilled version is as follows. The sun’s radiation travels to our planet in the form of light. That heats up the earth, as it always has. Some of the radiation from that light is absorbed by the planet’s surface and some bounces off the Earth back into space in the form of infrared radiation. But some of that outgoing radiation is trapped by the Earth’s atmosphere surrounding our planet, trapping it inside. This is ultimately good for humanity’s survival: it keeps our planet warm enough to sustain life. But as humanity has burned fossil fuels, we have thickened the atmosphere, trapping more of the outgoing radiation, warming our planet further. Life on Earth thrives within a narrow band of temperatures, and so increases threaten to destabilize the many interdependent global ecosystems that allow us to survive.
This basic explanation of our planet’s relationship to the sun, and our impact on that relationship, is a fact that emerged from two centuries of data gathering, data modeling, data interpretation, scientific exchange, and eventually, science communication and education.

Designing for sustainability
Unfortunately, communicating scientific facts about climate change is not sufficient to change human behavior. Many do not believe the science above; many conservative politicians in the United States actively dismiss it, or dismiss the role of human behavior, or deprioritize policy change about the climate, ignoring the scientific consensus. Having clear data about the science, while necessary for knowing the truth, has not led to changes in behavior sufficient for lowering carbon dioxide output to levels to prevent catastrophe. However, many researchers believe that information can play a role in changing behavior, leading to more sustainable behaviors that preserve our ability to live on this planet.
The information problems underlying sustainability are numerous 3 . One set of challenges, for example, frames the problem as one of persuasion , examining ways to know where our energy comes from, how sustainable that energy is, and how much carbon output our activities produce. The theory underlying these questions is that if only people had concrete information about the consequences of their choices, they might change their behavior. For example, one study examined numerous “eco-feedback” technologies 7 , finding many strategies such as presenting people with the benefits of more sustainable behavior, or providing messages, prompts, reminders, and notifications about electricity use and transportation. Some technologies go further, trying to use goal-setting as a way to motivate people to change their behavior, or comparisons to peer groups, commitments and pledges, or systems of opt-in rewards and punishments. This survey of technologies revealed a wide range of potential applications of software, hardware, sensors, and information to change behavior; other studies showed that many emerging efforts by energy companies can reduce electricity consumption by modest amounts, ranging from 7 to 14% depending on how utilities charge for electricity 6 . Other surveys of information, feedback, and incentives of recycling behavior suggest that personalizing feedback to particular audience segments are most effective, though it is not clear whether these interventions result in long-term behavior change 13 .

While information, tied with incentives, appears to be a promising approach to short term behavior change of individuals, there are reasons to be skeptical about their impacts on long term behavior. Some argue, for example, that focusing sustainability efforts on the individual ignores the much larger systemic factors such as policy, energy, and transportation infrastructure that shape carbon output; that the focus on technology over behavior change overlooks the dominant influence of habit, social norms, civic and cultural life; and that focusing on the power of designers, as opposed to civic leaders and policy makers, overlooks the necessary role of politics in making large scale, long term change 2 . Others argue that it isn’t just the focus on individuals and technology that impedes progress in addressing climate change, but neoliberal commitments to businesses and markets as “natural” institutions, rather than socially constructed ones, that results in framings of sustainability efforts as “informed choice” in individualist capitalist marketplaces, rather than collective decisions about how to sustain human civilization. These critics of technology and information-centric solutions to sustainability argue that the way forward is to deemphasize technology-only solutions, expanding our framings of persuasion to include politics and policy, to expand the range of stakeholders we include in design, to design for systems and communities rather than individuals, and to envision design methods for information systems that address these larger scales.

Managing crisis information
While researchers have made great strides in climate science and some progress on sustainability interventions, these efforts have been far too slow to prevent an increase in disasters likely partially caused by climate change. Cyclones, wildfires, droughts, and floods are killing more people than ever, making the hottest regions of our planets inhospitable, and costing governments hundreds of billions of dollars annually in crisis management and reconstruction. And most of these impacts affect the poorest countries of the world near the equator, which have the fewest resources to manage extreme weather events or migrate to safer regions of the planet. While efforts to reduce carbon output have never been more urgent, it is already too late to prevent an increase in such crises. While humanity works on finding more sustainable sources of energy, researchers are therefore also working on better ways of using information to manage crises.
Such work began in 2007 under the phrase crisis informatics , which includes empirical study as well as information system design to better support crisis situations 10 . Such work considers the way that information technology can be interwoven through the many well-documented stages of crisis 4 , including:
- Pre-disaster , a stable social system prior to impact
- Warning , which includes sharing of imminent threat in a social system
- Threat , which prompts individual “survival” action in a social system
- Impact , which prompts shifts from individual to community action
- Inventory , which prompts a collective account of impact
- Rescue , which prompts disorganized localized action on impact
- Remedy , which prompts organized and professional action on impact
- Recovery , which involves individual rehabilitation, community restoration, and organizational efforts to prevent recurrence.

Crisis informatics recognizes that each of these distinct stages of a crisis requires information, information technologies, and information systems to minimize fear and harm in both the short and long term and to prevent further crisis. Consider, for example, a case study of two climate-related events in 2009, the Oklahama grassfires and the Red River floods 14 . This study considered how Twitter was used to maintain situational awareness during the many stages of these crises. Tweets that contained geo-location information were the most utilized helping both individuals and authorities quickly identify the locations of threats. Tweets contained situational updates, which included threat-specific details about flood levels, fire line status, advice, evaluation details, volunteer information, and damage and injury reports. Throughout such events, particular individuals on Twitter played an outsized role in reporting information, and were often not in positions of disaster response authority. Later work on the January 12, 2010 Haiti earthquake showed how specific features of Twitter as a medium, such as the hashtag, facilitated ad-hoc communication structures that led to emergent volunteering efforts and eventually collective action 12 .
While many such studies reveal the powerful role of open social media platforms in broadcasting information, other studies show that social media, unlike journalism, is particularly prone to rumor and misinformation. One study of the 2010 Chilean earthquake demonstrated how false rumors and confirmed news propagated throughout Twitter during the crisis 9 . The social network “topology”, or whom was following who, did not change substantially, though the topology did determine the spread of misinformation about the crisis. On the other hand, evidence in the study suggested that false rumors tended to be questioned more than confirmed truths, even though both spread equally far through Twitter’s retweet mechanism.
Twitter, of course, and social media in general, are not the only information systems important in preventing, managing, and recovering from crises. As climate crises become more common, communities will need more robust early warning systems about the climate (typically government funded scientific endeavors), more organized and trained professional response teams, more redundant information and communication technologies that do not assume the a functioning internet or internet connection, and more intentional platforms for collective organizing to respond to novel crises. And most importantly, information systems will be required to motivate individuals, communities, and governments to motivate the funding of this work, and the development of trust. Without these efforts, the inevitable rise in climate and other crises will be more damaging and disruptive than ever.

Fundamentally, information about the climate has the greatest potential to impact our lives, saving us from disaster and helping us find sustainable ways to preserve the fragile balance of our planet and its ecosystem. And yet, because this information is often so indirectly related to our behavior, so distant in our futures, many of the problems that we hope to prevent through information eventually translate into crises, in which information directly impacts our immediate well-being. Is it possible to stop this cycle of short-term focus, and long-term disaster? If the history of information and sustainability proves anything, it’s that information and information technology are necessary but insufficient to make change.
Podcasts
- Innovation, Not Trees. how Bill Gates Plans to Save the Planet, Sway, NY Times . An interview with Bill Gates, covering the many energy and information technology innovations required to reach net zero.
- The Birth of Climate Change Denial, Only Human, WYNC . Discusses the political origins of climate change denial and the use of misinformation to create doubt.
- What You Need to Know About Climate Change, Making Sense, Sam Harris . A conversation between Sam Harris and Joseph Romm, a leading climate science communicator.
- It’s Hot. It’s Flooding. Is This the New Normal?, What Next: TBD . Discusses the latest advances in causal analysis of climate change impacts.
References
-
Svante Arrhenius (1896). On the influence of carbonic acid in the air upon the temperature of the ground. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science.
-
Hronn Brynjarsdottir, Maria Håkansson, James Pierce, Eric Baumer, Carl DiSalvo, and Phoebe Sengers (2012). Sustainably unpersuaded: how persuasion narrows our vision of sustainability. ACM Conference on Human Factors in Computing Systems.
-
Carl DiSalvo, Phoebe Sengers, and Hrönn Brynjarsdóttir (2010). Mapping the landscape of sustainable HCI. ACM Conference on Human Factors in Computing Systems.
-
R. R. Dynes (1970). Organized Behavior in Disaster. Lexington Books.
-
Edward Paysome Evans (1887). The authorship of the glacial theory. The North American Review.
-
Ahmad Faruqui, Sanem Sergici, and Ahmed Sharif (2010). The impact of informational feedback on energy consumption—A survey of the experimental evidence. Energy.
-
Jon Froehlich, Leah Findlater, and James Landay (2010). The design of eco-feedback technology. ACM Conference on Human Factors in Computing Systems.
-
Syukuro Manabe, Richard T. Wetherald (1967). Thermal equilibrium of the atmosphere with a given distribution of relative humidity. Journal of the Atmospheric Sciences.
-
Marcelo Mendoza, Barbara Poblete, and Carlos Castillo (2010). Twitter under crisis: can we trust what we RT?. First Workshop on Social Media Analytics.
-
Leysia Palen, Sarah Vieweg, Jeannette Sutton, Sophia B. Liu, and Amanda Hughes (2007). Crisis informatics: Studying crisis in a networked world. Proceedings of the Third International Conference on E-Social Science.
-
Katie Patrick (2019). How to save the world. BLURB Incorporated.
-
Kate Starbird, Leysia Palen (2011). "Voluntweeters": self-organizing by digital volunteers in times of crisis. ACM Conference on Human Factors in Computing Systems.
-
Alessandra Varotto, and Anna Spagnolli (2017). Psychological strategies to promote household recycling. A systematic review with meta-analysis of validated field interventions. Journal of Environmental Psychology.
-
Sarah Vieweg, Amanda L. Hughes, Kate Starbird, and Leysia Palen (2010). Microblogging during two natural hazards events: what twitter may contribute to situational awareness. ACM Conference on Human Factors in Computing Systems.
-
S. Weart (2003). The Discovery of Global Warming. Harvard University Press.
-
Davis A. Young (1995). The Biblical Flood: A Case Study of the Church's Response to Extrabiblical Evidence. University of Michigan.

Information + careers
I did not grow up wanting to be a professor, a researcher, or a teacher. In fact, like most youth, I didn’t even really think about careers until college. When I was ten, all I knew was that I liked jump ropes, cats, origami, Super Mario Bros., and math puzzles. When I was fifteen, I knew that I liked making simple games on my graphing calculator and reading historical fiction. And when I was twenty, even though I was a computer science major, I knew I didn’t want to be a software engineer. I thought that it involved programming alone in smelly basements (it doesn’t). My dream was to have a job where I had no boss, I could follow my curiosity and dream up new ideas with friends, and then tell people about what we’d made. As I soon learned from one of my CS professors that a tenure-track professor at a research university does roughly that, I was hooked: I wanted to be a professor.
Of course, I soon learned careers were far more complicated that I imagined. Software engineers don’t sit in smelly basements alone and don’t just code. And they don’t just work with other software engineers. They work with interaction designers, who envision what information systems should do. They work with product managers who ensure that what designers envision and engineers build meets a market or stakeholder need. They work with graphic designers who make visual assets. They work with database administrators who ensure that data can be quickly stored and retrieved. They work with information architects to decide how to structure data and it’s metadata. And managers work with all of these roles to ensure everyone has the resources, skills, and psychological safety to thrive in their work. And all of this work, while it centers around software, inevitably interacts with other kinds of expertise, since computing and information touch every discipline, practice, and domain in human experience. I just couldn’t see of this from the confines of school. When I co-founded a software startup, it became even more apparent, as I helped build the interdisciplinary teams that would envision and create our services.
Learning about this diversity of roles, and taking on those various roles as a founder, didn’t make me want those roles more than I wanted to be a professor. I still wanted the ultimately freedom to explore and share that only academia can provide. But it helped me understand that designing, creating, and maintaining information systems is never solitary work, and requires far more skills than any one person can possess. And because information systems are used in every aspect of society—government, science, and industry of all kinds—understanding how organizations come together to do this work is a crucial part of understanding information. In this final chapter of this book, we will define and discuss these various modern careers in information, how they leverage the ideas we’ve discussed in this book, and how they are a crucial aspect of getting people the information they need.

Information careers
Throughout this book, we’ve shown how information systems are fundamentally about people making and moving information with the help of technology. And because systems are largely composed of people, their decisions, assumptions, beliefs, and values are the foundation of how those systems work and for whom they work. But information systems are also fundamentally created and maintained by people: people build and repair the technology that runs them, people create the information that runs through them, and quite often, people are critical parts of operating information systems, translating, transmitting, interpreting, and combining information for other people to use. Whether it is writing, printing, and distributing books, creating and maintaining web scale websites, or organizing online communities, all information systems intricately combine human effort with technology and process to make information work. And if you take away any one of these things—people, information, technology, or the processes that coordinate them—the information system stops functioning.
Industry, then, is ultimately about organizing people to keep information systems working. There are many distinct kinds of work involved in this effort, and each kind of work requires distinct skills and knowledge to be successful. For example, the most central work in envisioning information systems is designdesign: The human activity of envisioning how to change the status quo into a more preferred one. , which, as we discussed in the Designing Information chapter, involves deciding what an information system will do, why, and for whom. What information will it have? Who will it serve? Where will the information come from? How should the information be structured? Which values will the system uphold? These questions are central in design.
Because this design work is so critical, there are many different roles in organizations that do it. While one might expect design work to be done by designers, in most organizations, there is actually a role with more powerful oversight over design called product managementproduct management: Synthesizing design, engineering, marketing, and sales concerns into strategic choices about product behavior. that ultimately answers the questions above. Product managers are in charge of finding the intersection between design opportunities and business opportunities, identifying groups of people who have some information need and envisioning some way of meeting that need through an information system. For example, consider the video above, which showcases a Yelp product manager, who talks about her work with multiple teams to make product decisions. Another example would be a Vice President of Product at a company like Netflix, who might be ultimately in charge of ensuring that people find so many movies and television shows that they want to watch so that they would never think of canceling their subscription, and that finding and watching them is so easy that they never cancel out of frustration. Netflix, of course, has many lower-level product managers, some for content, some for mobile apps, some of integrations on other platforms, all working toward the shared goals of getting great content to subscribers and keeping them subscribed. Product managers, as the ultimate decision makers about what information systems do and who they serve, have immense power, and thus are perhaps more responsible than anyone else at ensuring that products do not further reinforce systems of oppression (e.g., deprioritizing accessibility, amplifying harassment of marginalized groups). Product management has its closest affinities to academic disciplines of business.
Product managers, as the deciders, are usually not implementors. Instead, that work typically gets delegated to a range of different roles. One increasingly common design role is user experience (UX) researchuser experience research: Investigating how technology is currently used to reveal opportunities for how technology might better serve needs. . UX researchers gather insights about the information problems that users face and how they currently solve them, helping a product manager find opportunities for products. For example, in the video above, a UX researcher at Google talks about her career path into UX research, and her work on Google Maps, which largely involves understanding how people use maps to navigate their lives, and how Google Maps might help them do that better. UX researchers at Netflix might do similar work, interviewing a broad sample of families about how they use Netflix, or conduct surveys with families that don’t yet have Netflix, to understand why they haven’t yet subscribed. UX research has its closest affinities to academic social science that involve studying culture and human behavior, including anthropology, sociology, communication, and more applied research areas like human-computer interaction.
In contrast to UX research, user experience (UX) designuser experience design: Using design methods to envisioning products that meet needs. is about envisioning how an information system might meet an information need. For example, in the video above, a UX designer at the bra company True & Co talks about her work to understand where customers are getting stuck in the fitting and purchasing process, and envisioning features that might solve those problems by providing information. Her work involves analyzing insights about user experience possibly from UX researchers, and envisioning design changes to improve those experiences. Similarly, a UX designer at Netflix might lead a project to redesign the watch screen interface and it’s various controls to make it more accessible to people who are blind or low vision. Therefore, whereas product managers set the high level strategy for what system to make, and UX researchers inform that strategy by studying people’s needs, UX designers figure out how to actually meet those needs. UX design has its closest affinities to academic disciplines such as interaction design and human-computer interaction.
Whereas UX designers typically focus on features and experience, information architectureinformation architecture: Organzing data and metadata to faciliate searching, browsing, and discovery. focuses on the information aspects of those features and experiences, including what information a system needs to expose, how it will be structured, what metadata needs to be maintained about it, where the information will come from, how it will be presented in an interface, and how it will be searched, browsed, and navigated. The video above gives an overview of some of the many tasks that information architects do, ranging from designing site navigation, choosing labels, and designing database schemas for a website. Continuing our Netflix example, an information architect might be responsible for defining movie genre categories, ensuring movies have consistent metadata about directors and actors, and envisioning new ways for users to search and browse content, in collaboration with UX designers. Information architecture has closest affinities to academic disciplines such as library and information sciences.
Whereas UX research involves discoveries about technology use, UX design involves envisioning new products, and information architecture involves site maps, taxonomies, labels, and database schemas, software engineeringsoftware engineering: Writing computer programs to implement a design. involves implementing designs with code. In the video above, an Airbnb engineer describes her work to make the Airbnb reservation process stable, fast, and reliable, and helping to prioritize features and bug fixes. Similarly, at Netflix, a software engineer might be responsible for improving streaming reliability, building the user interfaces for the numerous platforms on which Netflix runs, implement search, and maintain all of this functionality as operating systems and platforms evolve. Software engineering has its closest affinities to the academic discipline of computer science.
Most information systems are more than just data and code; in fact, many of the ways that we experience information are first through the visual elements of interfaces, from typographic choices like fonts, layout, and spacing, to graphical choices, like images, textures, and illustrations. Graphic designsgraphic design: Creating visual and typographic forms of information. involves defining these visual experiences, choosing fonts, defining layouts for screens and print, and creating graphics and other content consistent with an organization’s brand and values. For example, in the video above, an illustrator at Dropbox describes her role creating content for the Dropbox brand. Similar, at Netflix, graphic designers maintain the logo, the colors, and the various textures on the website, and ensure consistency with marketing or sales efforts. Graphic design has its closest affinities to the academic discipline of visual and communication design.
Once an information system is available for use, most organizations need to understand how users are using it, where they are getting stuck, and what might be improved about the experience. These problems of product evaluation often fall to people in data gathering roles. This might include UX researchers, who might be charged with using interviews, surveys, observations, and other methods to try to understand customers’ experiences with a system. Another role often charged with this task is data sciencedata science: Using data and code to answer questions. , which involves using data sets such as logs of user activity to gather data, analyze it, and use it to answer questions that a UX designer or product manager might have. For example, in the video above, a data scientist (creatively given the title “Product Scientist”) at Medium describes his work to understand reader behavior on the website to help designers improve reading experiences. Data science draws from the academic disciplines of statistics, computer science, and information science.
UX researchers and data scientists aren’t the only roles that gather insights about people’s experiences with information systems. Customer experiencecustomer experience: Educating customers about an information technology’s functionality and use. —also known as customer support —involves responding to user feedback, write technical support and documentation, and moderate online communities. Because they work so closely with users, they often have the deepest insights into what is and isn’t working about an information system. For example, in the video above, a community director describes her work to help customers, while gathering and sharing insights with people across her company to influence product design. At Netflix, such roles might respond to customer confusion about billing, organize feature requests, and monitor social media for complaints and feedback. Customer experience draws from the academic disciplines of communication and marketing.
When teams get big enough, project managementproject management: Organizing teams of people to work more productivity to meet deadlines. becomes necessary to keep teams productive. Note that project managers are different from product managers in that project managers oversee people and their needs on a project, whereas product managers manage the product and it’s ability to meet a need in a marketplace. Therefore, while a product manager is worrying about customers, their needs, and how information systems an organization is creating are meeting them, a project manager is worrying about the designers, researchers, and engineers they are managing. They ensure that teams are working well together, that they have the resources they need from the organization to do their job, and that they feel safe giving feedback about problems they’re seeing, and solving those problems with their teammates. Whereas product managers are trying to make the business work, project managers are trying to make people work. The video above with the head of Pinterest’s engineering team shows that much of his time is spent recruiting and hiring new engineers, making sure they’re working well together, ensuring the team sets and achieves its goals. The same role at Netflix might ensure the group of site reliability engineers can work together productively to ensure that Netflix never goes down. Project management draws from the academic disciplines of business, but also relies on content expertise. For example, teams of engineers are often best managed by engineers who’ve developed project management skills.
Importantly, all organization divide up this work in different ways, using different titles, and grant different powers and responsibilities. In some organizations, engineers might also play the role of product manager, making decisions about product strategy and features; for example, Facebook CEO Mark Zuckerberg is known to frequently make product decisions, even though Facebook has a Chief Product Officer in charge of such high level decisions. In some organizations, there might not be any designers of any kind, leaving graphic design, experience design, and information architecture to sales teams, marketing teams, or engineers. Some organizations might combine roles; for example, Microsoft has many software engineers who are largely responsible for project management, and sometimes product management, while also contributing to code. Selecting an information career therefore isn’t about choosing a specific title, but developing a set of skills and finding organizations that need them, however they’ve decided to organize the work and label their roles.
Whereas all of the roles above are common in for-profit and not-for-profit organizations, as well as government, another crucial part of shaping information systems is researchresearch: Answering questions that have not yet been answered by humanity. . Academic researchers, not to be confused with UX researchers, aren’t focused on questions specific to products or businesses, but on questions that are relevant to all organizations and all of society. For example, the video above features Information School professor Jason Yip’s research on youth perspectives on information technology in homes. His research shapes design education, and also informs the work of product designers in industry who might be envisioning technologies for families, as well as policy makers who might be regulating information technologies that enter homes. Without research, there would be less knowledge about how to design information systems, less knowledge to teach information systems design, and fewer critical questions about what impact information technology is having on our lives. Organizations in industry therefore depend on academia to develop information system skills, to deepen our understanding of how to do those skills well, and to ask challenging moral, ethical, and philosophical questions about what systems we make and why. Books like this one would have few reliable facts, theories, or insights to share without research, and colleges and universities would have little to teach.
Lastly, and perhaps most importantly, are information educators . There are really two significant places that information education appears in public education around the world. The first is through librarians, who often take on the primary role of helping youth understand computing, information, and society. Librarians are typically trained by pursuing a masters degree in library and information science aa For example, the University of Washington’s MLIS program , which prepares people to be information educators in library contexts. , specializing in school or children’s librarianship, and then join primary schools, secondary schools, or public libraries as librarians. These teaching roles are often informal, reaching students when they come to librarians with an information need, though some librarians will teach classes. The other place that information education appears is in computing education, such as computer science classes, or classes in other subject areas that integrate computer science concepts or skills. Primary and secondary teachers who teach these subjects often teach skills involved in all of the careers above, but also literacy about computing and information in society. Primary and secondary CS educators are typically trained by getting an undergraduate or graduate degree in education to earn their teaching certificate bb For example, the University of Washington’s STEP CS program , which is a partnership between the The College of Education, The Information School, and the School of Computer Science & Engineering that prepares people to teaching computing in critically conscious ways. . These roles are often formal classroom teaching, but can involve informal roles also, such as supervising after school and summer programs.
Research and teaching are particularly important parts of powering information careers. Without researchers, we wouldn’t make as much progress on solving information and computing problems. And without teachers, we won’t have a public that understands and can use information.

Organizational contexts for information work
While many of the videos and roles above might sound like they all belong in for-profit contexts, that’s actually not the case. There are developers that work for for-profit companies big and small, developers that work for not -for-profits big and small, developers that work for governments, and developers that volunteer for communities that aren’t formal organizations. There are developers that even work for themselves. All of the roles above are orthogonal to the kinds of organizations one might work in.
For-profit enterprises are the perhaps the most visible, since for-profit organizations often make enough profit to spend money on recruiting. The distinguishing characteristic of for-profit organizations is that they are primarily driven by capitalismcapitalism: A system of commerce organized by government to optimize trade and profit above all other concerns. : the parts of economic and political parts of some countries that are owned privately, rather than by the government, and are centrally motivated by profit rather than other goals. While the responsibilities might be the same in a for-profit as a not-for-profit, the capitalist profit motive heavily shapes the priorities of ones work. For example, product managers in for-profit companies have the ultimate goal of making a company more money; designers and engineers need to create products and services that customers will by and subscribe to; there are even academic researchers in for-profit companies (e.g., Microsoft Research ) who make discoveries like the inventors in academia, but do so with the ultimate goal of informing products and services that will generate profit. The profit motive is even at play in organizations that might have a social mission; for example, Airbnb started as a company motivated by building community and exploration, but as a for-profit company, that mission comes second to making money.
Not-for-profit enterprises can have all of the same roles, but are primarily driven by human values rather than profit. For example, the Bill & Melinda Gates Foundation focuses on improving health and education in Africa, China, India, as well as communities in wealthier Western nations in Europe and North America. Product managers in organizations like the Gates Foundation aren’t focused on profit, but rather making people healthier, smarter, and more secure; designers and developers create information systems that make these goals possible. User researchers at the Gates Foundation might study existing solutions and how they are or are not meeting health and education goals, whereas academic researchers in not-for-profits might conduct rigorous long term studies of the efficacy of interventions. Revenue in these organizations still matter—some not-for-profits even make profit through products and services—but revenue in these organizations is secondary to achieving other goals. For example, universities are not-for-profit, but still charge tuition and fees in order to pay their faculty and staff. The experience of information careers in not-for-profits is thus often one of fewer resources, but the ability to align one’s own values to their work.
There are also product managers, designers, developers, and researchers of all kinds in governments. After all, governments maintain many information systems with the goal of sustaining human civilization by keeping residents safer, healthier, smarter, more mobile, and more prosperous. These include systems for interfacing with the justice system, law enforcement, social services, and infrastructure like roads, bridges, internet, and more. Product managers, designers, engineers, and researchers in government ensure that these large scale, long term services are meeting ever evolving needs. As with not-for-profits, governments do not prioritize profit, but rather efficient, transparent use of public revenue through taxes. The experience of working in government is often one of scale and diversity, as governments need to serve everyone, not just a particular market or community.
Lastly, all three types of organizations above can be of different sizes. Some organizations and governments are massive, and have been around for centuries. The work in these organizations is often one of maintenance, repair, and incremental change, but often with greater scale and resources than smaller organizations. Others organizations are startups, whether for-profit startups trying to make profit, new not-for-profits trying to meet an unmet need in society, or new parts of governments (or even entirely new governments) that are creating new information systems to serve society. The work in these smaller organizations is often overwhelming but more dynamic and nimble.

Developing skills and interests
For anyone considering careers in information in any of the types of organizations above, it is easy to imagine the roles above as out of reach. In fact, many students come to college with beliefs that they are intrinsically bad at particular subjects (e.g., “I can’t code”). These beliefs, however, do not stem from innate inabilities. Rather, they often come from shame created by peers and teachers, or deterrence from cultural stereotypes or social stigmas 5 . The result is that many have what researchers call a fixed theory of intelligencefixed intelligence: A false belief that one’s intelligence is fixed at birth. and a fixed theory of interestfixed interest: A false belief that one’s interests are discovered rather than developed. : beliefs that abilities and interests are innate from birth 1,4 . Neither beliefs are true—we are all born with the ability to learn new skills and develop new interests—but society often reinforces fixed theories of intelligence and interest by propagating myths that certain individuals or groups are better or worse at particular academic subjects. These fixed mindsets limit our desire to explore new skills and interests, creating a destructive and false belief that talents and passions must be “found”.
The reality is that talents and passions must be developed grown over time. The majority of differences in human ability come from deliberate practice, not innate talent 2 , and interests come from our social and cultural experiences and opportunities, not our DNA 3 . The work of developing skills and interests is not about discovering innate talents or interests, but cultivating them. This might entail taking classes to learn new skills, and recognizing that any difficulties encountered in that learning are more a product of the quality of instruction and your practice, rather than any innate inability. And developing interests might entail finding supportive, inclusive communities with mentors and activities that catalyze new interests that you did not have before. Growing a passion is hard, effortful, long-term work.
Because abilities and interests are not innate, there is no right answer. This is particularly important to remember in information careers, where advances in research and industry on information technology mean that the skills required to contribute are constantly changing, and organizations are constantly finding new ways to organize work. One might begin with an interest in software engineering, but later become enamored with data science or design; ten years into a career of information architecture, one might develop an entrepreneurial spirit, and decide to become a CEO. These many career pivots are a normal byproduct of learning, joining new communities, and developing new interests. There is no right role for any one person, just the roles that fit their current skills and interests. And since those skills and interests will change, so will the roles that fit.
Of course, communities can also suffocate learning and deter interests. Consider, for example, the conflict in 2020, with algorithmic bias expert Timnit Gebru. She had spent a long career studying electrical engineering, then worked at Apple on signal processing algorithms. She later earned her Ph.D. doing research on bias in image collections. This led to an interest in AI ethics, and eventually to a position at Google, where she worked as both a researcher of AI ethics, but also an advocate for justice in addressing issues of systemic bias in facial recognition, language processing, and other AI technologies. Her public advocacy, her research, her insistence on transparency, Google’s apparent resistance to publishing research critical about AI, led her to be fired, threatening her ability to pursue her carefully cultivated skills and interests. Organizational conflicts like this—as well as the many other issues of sexual harassment, abuses of power, and disagreements about organizations’ moral and ethical stances on information systems—mean that choosing information careers also means investing in ways of making organizations more diverse, equitable, inclusive, and just, so that the systems we make reflect everyone’s needs.

Pursuing careers in information, as much as it is an individual choice, is also a social and communal choice. After all, choosing an organization to work for means adopting its values, missions, and tactics as well. Thus, choosing a career is fundamentally about answering central questions of power. Who decides what we make? What values shape what we make? And when the people involved in making them disagree with an organizations strategic direction, what power do they have to resist that decision? Careers in information can be impactful, lucrative, and meaningful, but because of the increasing power given to information systems and the organizations that create them, organizations can also be sites of cultural tension and moral responsibility. What information problems do you want to solve in the world. Why? Which organizations can help you do that? And if there aren’t any, are you willing to make your own?
Podcasts
- Timnit Gebru Tells Her Story, In Machines We Trust, MIT Technology Review . Gebru describes the toxic work environment at Google that punished advocacy, community organizing, and ultimately scientific progress on AI ethics.
- Amazon Black Stories: Taurean Jones, Amazon Design . Taurean Jones talks about design leadership at Google, discussing allyship, mentorship, and representation.
- Does Google Actually Want to Hire Black Engineers?, What Next TBD, Slate . Discusses the problematic and incrementally effective partnership between Google and HBCU’s.
- Project Maven, Recode Daily, Vox . Discusses a Google Department of Defense weapons contract and an internal effort by some Google employees to protest and resist the project, resulting its cancellation.
- A Union Drive at Amazon, The Daily, New York Times . Discusses the extreme employee surveillance at Amazon warehouses, and how those surveillance activities led to unionization efforts at one warehouse in Bessember, Alabama.
- Hired by an Algorithm, In Machines We Trust, MIT Technology Review . Discusses the rapid adoption of AI by companies to filter job applications, and how those filters encode and amplify gender, race, and cultural bias.
References
-
Carol S. Dweck (2008). Mindset: The new psychology of success. Random House Digital, Inc..
-
K. Anders Ericsson, Ralf T. Krampe, and Clemens Tesch-Römer (1993). The role of deliberate practice in the acquisition of expert performance. Psychological Review.
-
Suzanne Hidi, and K. Ann Renninger (2006). The four-phase model of interest development. Educational Psychologist.
-
Paul A. O’Keefe, Carol S. Dweck, and Gregory M. Walton (2018). Implicit theories of interest: Finding your passion or developing it?. Psychological Science.
-
Steven J. Spencer, Christine Logel, and Paul G. Davies (2016). Stereotype threat. Annual Review of Psychology.