
Data, encoding, and metadata
Every ten years, the United States government completes a census of everyone that lives within its borders. This census, mandated by the U.S. Constitution, is a necessary part of determining many functions of government, including how seats in the U.S. House of Representatives are allocated to each state, based on population, as well as how federal support is allocated for safety net programs. Demographic information, such as age, gender, race, and disability, also informs federal funding of research and other social services. Therefore, this national survey is about distributing both power and resources.
When I filled out the census for the first time in the year 2000 at the age of 20, I wasn’t really fully aware of why I was filling out the survey, or how the data would be used. What struck me about it were these two questions:
- What is your sex? ☐ Male ☐ Female
- What is your race? ☐ White ☐ Black, African Am., or Negro, ☐ American Indian or Alaska Native, ☐ Asian Indian, ☐ Chinese, ☐ Filipino, ☐ Japanese, ☐ Korean, ☐ Vietnamese, ☐ Native Hawaiian, ☐ Guamanian or Chamorro, ☐ Samoan, ☐ Other Pacific Islander, ☐ Some other race
I struggled with both. At the time, I wasn’t definitely uncomfortable with thinking about myself as male, and it was too scary to think about myself as female. What I wanted to write in that in that first box was “Confused, get back to me.” Today, I would confidently choose female , or woman , or transgender , or even do you really need to know ? But the Census, with its authority to shape myriad policies and services based on gender for the next twenty years of my life, forced me into a binary.
The race question was challenging for a different reason. I was proudly biracial, with Chinese and Danish parents, and I was excited that for the first time in U.S. history, I would be able to select more than one race to faithfully represent my family’s ethic and cultural background. Chinese was an explicit option, so that was relatively easy (though my grandparents had long abandoned their ties to China, happily American citizens, with a grandfather who was a veteran, serving in World War I). But White ? Why was there only one category of White? I was Danish, not White. Once again, the Census, with its authority to use racial data to monitor compliance with equal protection laws and shape funding for schools and medical services, forced me into a category in which I did not fit.
These stories are problems of data, encoding, and metadata. In this chapter, we will discuss how these ideas relate, connecting them to the notions of information in the previous chapter, and complicating their increasingly dominant role in informing the public and public policy.

Data comes in many forms
As we discussed in the previous chapter, datadata: Analog or digital symbols that someone might perceive in the world and ascribe meaning. can be thought of as any form of symbols, analog or discrete , that someone might perceive in the world. Data, therefore, can come in many forms, including those that might enter through our analog senses of touch, sight, hearing, smell, taste, and even other less known senses, including pain, balance, and proprioception (the sense of where our bodies are in space relative to other objects). These human-perceptible, physical forms of data might therefore be in the form of physical force (touch), light (sight), sound waves (hearing), molecules (smell, taste), and the position of matter in relation to our bodies (balance, proprioception). It might be strange to imagine, but when we look out into the world to see the beauty of nature, when we smell and eat a tasty meal, and when we listen to our favorite songs, we are perceiving data in its many analog forms, which becomes information in our minds, and potentially knowledge.
But data can also come in forms that cannot be directly perceived. The most modern example is bitsbit: A binary value, often represented as either 1 or 0 or true or false. , as Claude Shannon described them 11 , building upon George Boole’s idea of truth values 5 , true , and false , or 1 , and 0 . Shannon and Boole imagined these as abstract ideas, but for bits to be data, they must be concretely embodied in some physical form. Early technologies for encoding bits included vacuum tubes, which passed an electric current between two electrodes to represent true , whereas no current represented false . These were soon replaced with the transistor 9 , which used high or low voltage to represent true and false , but in a much smaller package. The history of the transistor since has largely been to shrink them, to the point where we can now fit billions of transistors on a chip that’s just a few centimeters square. Whatever the form, the data storage capability is the same: either true , or false .
Of course, binary, bits, and transistors were not the first forms of discrete data. Deoxyribonucleic acid (DNA) came much earlier. A molecule composed of two polynucleotide chains that wrap around each other to form a helix shape, these chains are composed of sequences of one of four nucleobases, cytosine, guanine, adenine, and thymine. DNA, just like transistors, encodes data, but unlike a computer, which uses bits to make arithmetic calculations, life uses DNA to assemble proteins, which are the complex molecules that enable most of the functions in living organisms and viruses. And just like the transistors in a microprocessor and computer memory are housed inside the center of a computer, DNA is fragile, and therefore carefully protected, housed inside cells and the capsid shell walls of viruses. Of course, because DNA is data, we can translate it to bits 10 , and use them to advance any science concerned with life, from genomics and immunology to health and wellness.
Because computers are our most dominant and recent form of information technology, it is tempting to think of all data as bits. But this diversity of ways of storing data shows that binary is just the most recent form, and not even our most powerful: bits cannot heal our wounds the way that DNA can, nor can bits convey the wonderful aroma of fresh baked bread. This is because we do not know how to encode those things as bits.

Data requires encoding
The forms of data, while fascinating and diverse, are insufficient for giving data the potential to become information in our minds. Some data is just random noise with no meaning, such as the haphazard scrawls of a toddler trying to mimic written language, or the static of a radio receiving no signal. That is data, in the sense that it conveys some difference, entropy, or surprise, but it has little potential to convey information. To achieve this potential, data can be encodedencoding: Rules that define the structure and syntax of data, enabling unambiguous interpretation and reliable storage and transmission. , giving some structure and syntax to the entropy in data that allows it to be transmitted, parsed, and understood by a recipient. There are many kinds of encodings, some natural (such as DNA), some invented, some analog, some digital, but they all have one thing in common: they have rules that govern the meaning of data and how it must be structured.
To start, let’s consider spoken, written, or signed natural language, like English, Spanish, Chinese, or American Sign Language. All of these languages have syntax, including grammatical rules that suggest how words and sentences should and should not be structured to convey meaning. For example, English often uses the ending -ed to indicate an action occurred in the past ( waited , yawned , learned ). Most American Sign Language conversations follow Subject-Verb-Object order, as in CAT LICKED WALL . When we break these grammatical rules, the data we convey becomes harder to parse, and we risk our message being misunderstood. Sometimes those words and sentences are encoded into sound waves projected through our voices; sometimes they are encoded through written symbols like the alphabet or the tens of thousands of Chinese characters and sometimes they are encoded through gestures, as in sign languages that use the orientation, position, and motion of our hands, arms, faces, and other body parts. Language, therefore, is an encoding of thoughts into words and sentences that follow particular rules 2 .
While most communication with language throughout human history was embodied (using only our bodies to generate data), we eventually invented some analog encodings to leverage other media. For example, the telegraph was invented as a way of sending electrical signals over wire long distances between adjacent towns, much like a text messages 4 . Someone would bring a message to a telegraph operator, and then they would translate the message into a series of telegraph codes that encoded the message as periods of positive and negative voltage along a wire. On the other end, another telegraph operator would listen to a sonification of the voltage bursts, writing them down as a written pattern, then translate that pattern back into natural language. There were dozens of encodings one could use: the Chappe code, Edelcrantz code, Wig-wag, Cooke, and the more popular and standardized Morse code, all mirroring our other systems of symbolic communication, such as the Roman and Greek alphabets that inspire many western languages today.
This history of analog encodings directly informed the digital encodings that followed Shannon’s work on information theory. The immediate problem posed by the idea of using bits was how to encode the many kinds of data in human civilization into bits. Consider, for example, numbers. Many of us learn to work in base 10, learning basic arithmetic such as 1+1=2. But mathematicians have long known that there are an infinite number of bases for encoding numbers. Bits, or binary values, simply use base two. There, encoding the integers 1 to 10 in base two is simply:
| Binary | Decimal |
|---|---|
| 1 | 1 |
| 10 | 2 |
| 11 | 3 |
| 100 | 4 |
| 101 | 5 |
| 110 | 6 |
| 111 | 7 |
| 1000 | 8 |
| 1001 | 9 |
| 1010 | 10 |
That was simple enough. But in storing numbers, the early inventors of the computer quickly realized that there would be limits on storage 12 . If a computer had 8 transistors, each storing one bit, how many possible numbers could one store? The long way to find out is to simply keep counting in binary as above until one reaches 8 digits. The short way is to remember from mathematics that the number of possible permutations of a sequence of 8 binary choices can be computed as 2 to power 8, or 256. When you see references to 32-bit processors or 64-bit processes , this is what those numbers refer to: the number of bits used to store chunks of data, such as numbers.
Storing positive integers was easy enough. But what about negative numbers? Early solutions reserved the first bit in a sequence to indicate the sign, where 1 represented a negative number, and 0 a positive number. That would make the bit sequence 10001010 the number -10 in base 10. It turned out that this representation made it harder and slower for computers to do arithmetic on numbers, and so other encodings - which allow arithmetic to be computed the same way, whether numbers are positive or negative - are now used (predominantly the 2’s complement encoding ). However, reserving a bit to store a number’s sign also means that one can’t count as high: 1 bit for the sign means only 7 bits for the number, which means 2 to the power 7, or 128 possible positive or negative values, including zero.
Real numbers (or “decimal” numbers) posed an entirely different challenge. What happens when one wants to encode a large number, like 10 to the power 78, the latest estimate of the minimum number of atoms in the universe? For this, new encoding had to be invented, that would leverage the scientific notation in mathematics. The latest version of this encoding is IEEE 754 , which defines an encoding called floating-point numbers, which reserves some number of bits for the “significand” (the number before the exponent), and other bits for the exponent value. This encoding scheme is not perfect. For example, it is not possible to accurately represent all possible numbers with a fixed number of bits, nor is it possible to represent irrational numbers such as 1/7 accurately. This means that simple real number arithmetic like 0.1 + 0.2 doesn’t produce the expected 0.3 , but rather 0.30000000000000004 . This level of precision is good enough for applications that only need approximate values, but scientific applicants requiring more precision, such as experiments with particle accelerators which often need hundreds of digits of precision, have required entirely different encodings.
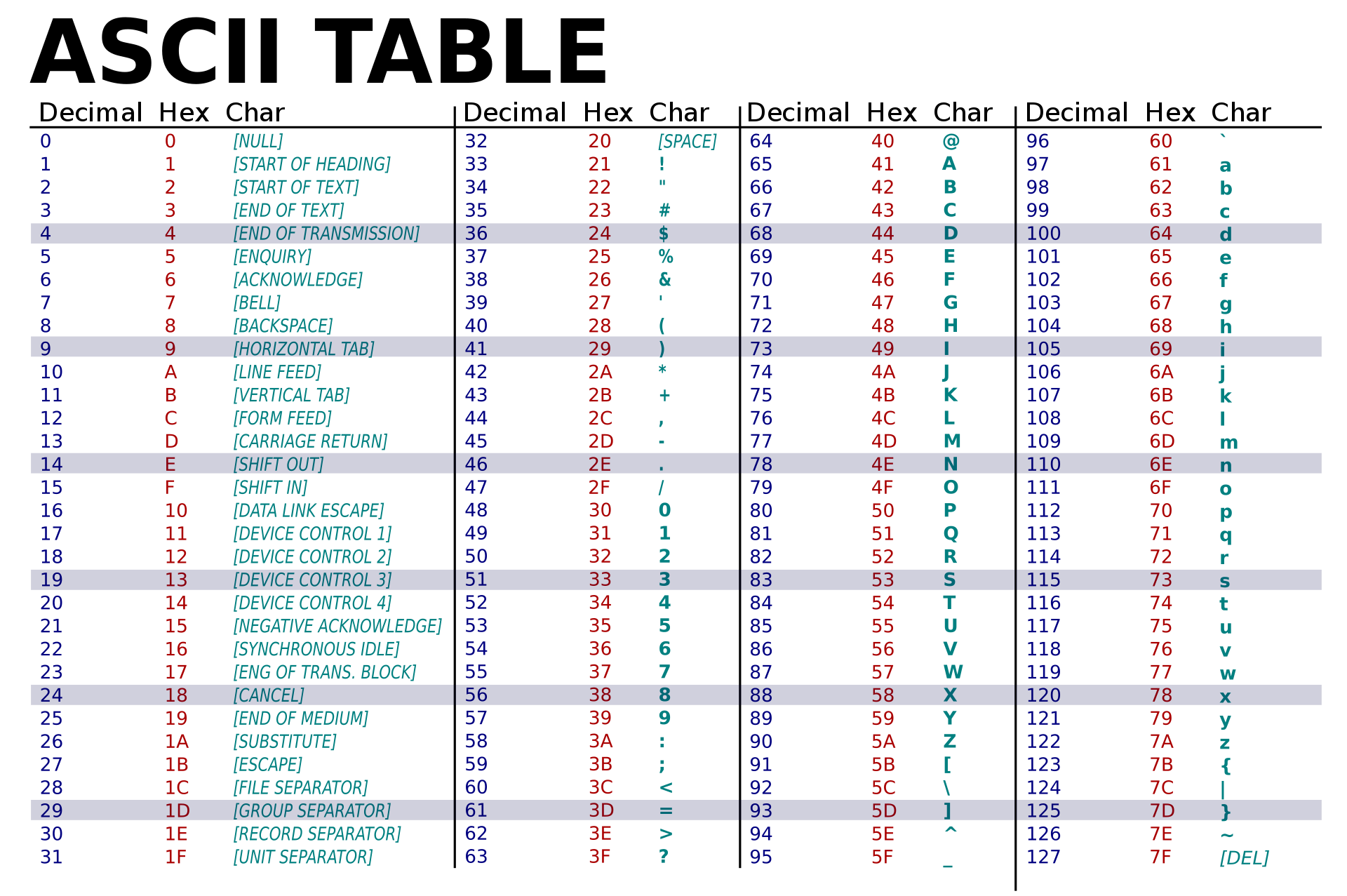
While numbers are important, so are other symbols. In fact, most of the Internet is text, and not numbers. So encoding text was an entirely different challenge. The basic idea that early inventors of computers devised was to encode each character in the alphabet as a specific number. This first encoding, called ASCII (which stood for American Standard Code for Information Interchange), used specific values in an 8-bit sequence to denote specific characters 8 : the decimal number 65 stood for A , 66 for B , 67 for C , and so on, with lower case letters starting at 97 for a . Therefore, to encode the word kitty , one would use the sequence of numbers 107 105 116 116 121 , or in unsigned binary, 01101011 01101001 01110100 01110100 01111001 . Five letters, five 8-bit numbers.
Of course, as is clear in the name for this encoding — American Standard — it was highly exclusionary: only western languages could be encoded, excluding all other languages in the world. For that, Unicode was invented, allowing the encoding of all of the world’s languages 7 . But it went beyond just established language, also including things like emoji, defining a community-based process by which individuals can propose new emoji for inclusion into the standard. Because everyone in the software industry has agreed on Unicode as the global encoding, and everyone agrees to accept revisions to the encoding, it has become the basis for all textual data exchanged through computers.
Numbers and text of course do not cover all of the kinds of data in the world. Images have their own analog and digital encodings (film photograph negatives, JPEG, PNG, HEIC, WebP), as do sounds (analog records, WAV, MP3, AAC, FLAC, WMA). And of course, software of all kinds defines encodings for all other imaginable kinds of data. Each of these, of course, are designed, and use these basic primitive data encodings as their foundation. For example, when the U.S. Census was designing the 2000 survey, the two questions I struggled with were stored as a data structure , with several fields, each with a data type:
| Data type | Description |
|---|---|
| boolean | true if checked male |
| boolean | true if checked White |
| boolean | true if checked Black |
| boolean | true if checked American Indian/Native Alaskan |
| boolean | true if checked Asian Indian |
| boolean | true if checked Chinese |
| boolean | true if checked Filipino |
| boolean | true if checked Japanese |
| boolean | true if checked Korean |
| boolean | true if checked Vietnamese |
| boolean | true if checked Hawaiian |
| boolean | true if checked Guamanian/Chamorro |
| boolean | true if checked Pacific Islander |
| text | encoding of handwritten text describing another race |
Each response to that survey was encoded using that data structure, encoding binary as one of two values, and encoding race is a yes or no value to one of twelve descriptors, plus an optional text value in which someone could write their own racial label. Data structures, like the one above, are defined by software designers and developers using programming languages; database designers create similar encodings by defining database schema , specifying the data and data types of data to be stored in a database .

Encoding is lossy
The power of encoding is that it allows us to communicate in common languages. Encoding in bits is even more powerful, because it is much easier to record, store, copy, transmit, analyze, and retrieve data with digital computers. But as should be clear from the history of encoding above, encodings are not particularly neutral. Natural languages are constantly evolving to reflect new cultures, values, and beliefs, and so the rules of spelling and grammar are constantly contested and changed. Digital encodings for text designed by Americans in the 1960’s excluded the rest of the world. Data structures like the one created for the 2000 U.S. Census excluded my gender and racial identity. Even the numerical encodings have bias, making it easier to represent integers centered around 0, and giving more precision to rational numbers than irrational numbers. These biases demonstrate that an inescapable fact of all analog and digital encodings of data: they are lossy, failing to perfectly, accurately, and faithfully represent the phenomenon they encode 1 . No matter how much additional precision we give to encodings, they will always be missing detail, emphasizing some details over others.
Nowhere is this more clear than when we compare analog to digital encodings of the same phenomena to the phenomena they attempt to encode as data:
- Analog music , such as that stored on records and tapes, is hard to record, copy, and share, but it captures a richness and fidelity. Digital music , in contrast, is easy to copy, share, and distribute, but is usually of lower quality. Both, however, cannot compare to the embodied experience of live performance, which is hard to capture, but far richer than recordings.
- Analog video , such as that stored on film, has superior depth of field but is hard to edit and expensive. Digital video , in contrast, is easier to copy and edit, but it is prone to compression errors that are far more disruptive than the blemishes of film. Both, however, cannot compare to the embodied experience of seeing and hearing the real world, even though that embodied experience is impossible to replicate.
Obviously, each encoding has tradeoffs; there is not best way to capture data of each kind, just different ways, reflecting different values and priorities.
Metadata captures context
One way to overcome the lossy nature of encoding is by also encoding the context of information. Context, as we described in the previous chapter, represents all of the details surrounding some information, such as who delivered it, how it was captured, when it was captured, and even why it was captured. As we noted, context is critical for capturing the meaning of information, and so encoding context is a critical part of capturing the meaning of data. When we encode the context of data as data, we call that metadatametadata: Data about data, capturing its meaning and context. , as it is data about data 13 .
To encode metadata, we can use the same basic ideas of encoding. But deciding what metadata to capture, just as with deciding how to encode data, is a value-driven design choice. Consider, for example metadata about images we have captured. The EXIF metadata standard captures context about images such as captions that may narrate and describe the image as text, geolocation data that specifies where on Earth it was taken, the name of the photographer who took the photo, copyright information about rights to reuse the photo, and the date the photo was taken. This metadata can help image data be better interpreted as information, by modeling the context it was taken. (We say “model”, because just as with data, metadata does not perfectly capture context: a caption may overlook important image contents, the name of the photographer may have changed, and the geolocation information may have been imprecise or altogether wrong).
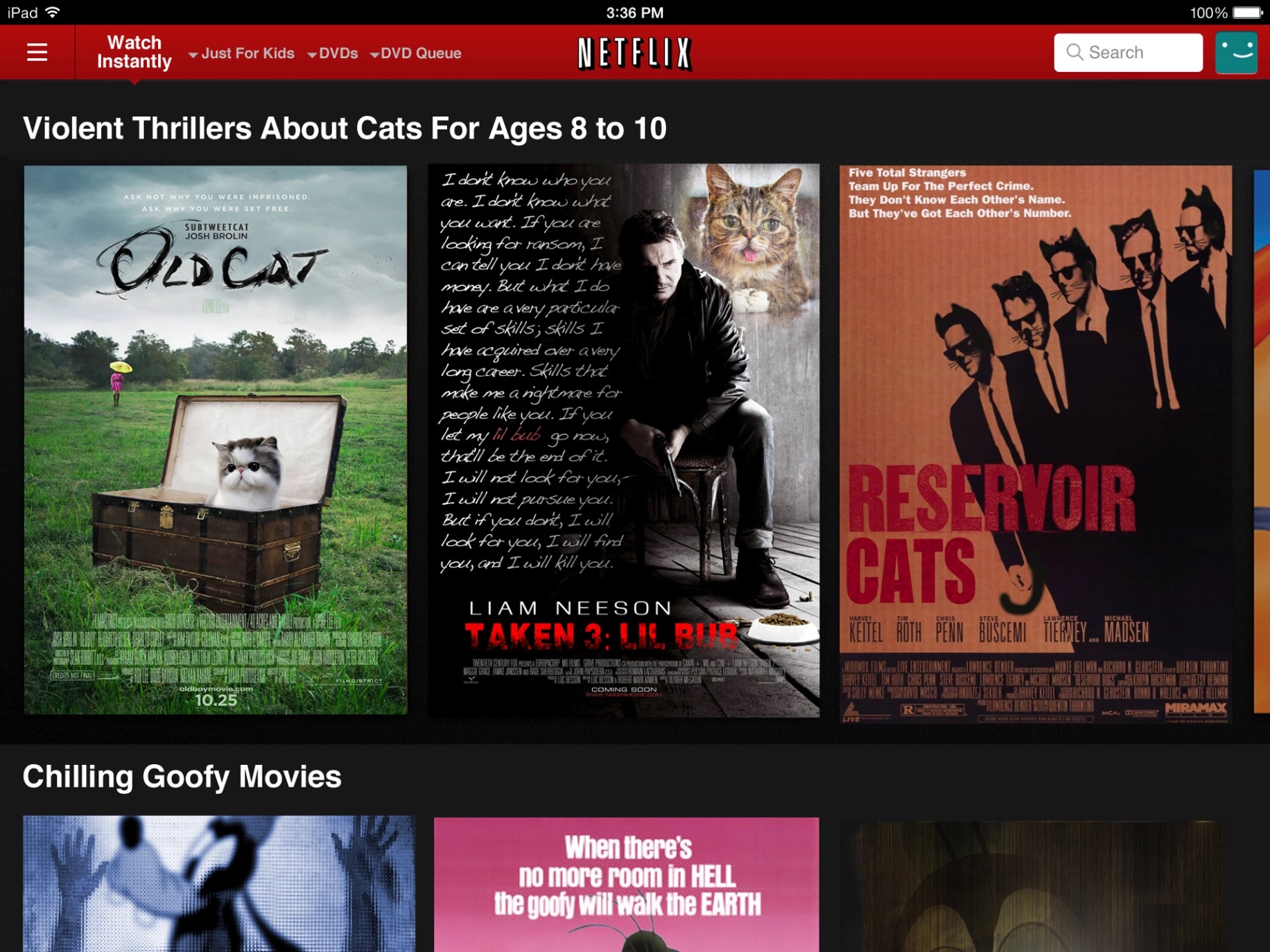
But metadata is useful for more than just interpreting information. It is also useful for organizing it. For example, Netflix does more than encode television and movies as data for streaming. It also stores and even creates metadata about movies and television, such as who directed it, who produced it, who acted in it, what languages it can be heard in, whether it is captioned, and so on. This metadata facilitates searching and browsing, as we shall discuss in our later chapter on information seeking. But Netflix also creates metadata, synthetically generating tens of thousands of “micro-genres” to describe very precise categories of movies, such as Binge-Worthy Suspenseful TV dramas or Critically Acclaimed Irreverent TV Comedies . This metadata helped Netflix make browsing both more granular and informative, creating a sense of curiosity and surprise through its sometimes odd and surprising categorizations. This is an example of what knowledge organization scholars called a controlled vocabularycontrolled vocabulary: A fixed collection of terminology used to restrict word choice to ensure consistency and support browsing and searching. , a carefully designed selection of words and phrases that serve as metadata for use in browsing and searching. Tagging systems like controlled vocabularies are in contrast to hierarchical systems of organization, like taxonomies, which strictly place data or documents within a single category.
While some metadata is carefully designed and curated by the creators of data, sometimes metadata is created by the consumers of data. Most systems call these taggingtagging: A system for enabling users of an information system to create descriptive metatdata for data. systems, and work by having consumers of data apply public tags to items, resulting in an emergent classification system; scholars have also called them folksonomies , collaborative tagging , or social classification , or social tagging systems 6 , distinguishing them from tagging systems that are controlled by some authoritative body such as a designer or a standard body. These have the benefit of having the classification scheme reflect users’ vocabulary and offer great flexibility to change tag metadata over time. However, they can also result in metadata that is too ambiguous, personal, or inconsistent to be useful to a wider audience.
Classification, in general, is fraught with social consequences. 3 We use them throughout society to categorize, label, and organize our environments, identities, and systems, but too often, the people who make these classification systems do not design them to include everyone, and so many of us end up not fitting the rigid categories prescribed by classification schemes. For example, we encode data using racial categories to prioritize resources; we use gender categories to inform sexist assumptions about lived experience and knowledge; we use categories about histories of incarcertation to deny people work. Classification, metadata, and data itself, is therefore not simply about bits and information, but morality, politics, and identity.

Thus far, we have established that information is powerful when it is situated in systems of power, that this power can lead to problems, and that information is likely a process of interpreting data, and integrating it into our knowledge. This is apparent in the story that began this chapter, in which the information gathered by U.S. Census has great power to distribute political power and federal resources. What this chapter has shown us is that the data itself has its own powers and perils, manifested in how it and its metadata is encoded. This is illustrated by how the U.S. Census encodes gender and race, excluding my identity and millions of others’ identities. This illustrates that the choices about how to encode data and metadata reflect the values, beliefs, and priorities of the systems of power in which they are situated. Designers of data, therefore, must recognize the systems of power in which they sit, carefully reflecting on how their choices might exclude.
Podcasts
Learn more about data and encoding:
- Emojiconomics, Planet Money, NPR . Discusses the fraught role of business and money in the Unicode emoji proposal process.
- Our Year: Emergency Mode Can’t Last Forever, What Next, Slate . Discusses the processes by which COVID-19 data have been produced in the United States, and the messy and complex metadata that makes analysis and decision making more difficult.
- Inventing Hispanic, The Experiment, The Atlantic . Discusses the history behind the invention of the category “Hispanic” and “Latino”, and how racial categories are used to encode race as a social construct.
- Organizing Chaos, On the Media . Reports on the debates about the Dewey Decimal System and it’s inherent social biases.
References
-
Ruha Benjamin (2019). Race after technology: Abolitionist tools for the new jim code. Social Forces.
-
Kathryn Bock, Willem Levelt (1994). Language production: Grammatical encoding. Academic Press.
-
Geoffrey Bowker, Susan Leigh (2000). Sorting things out: Classification and its consequences. MIT Press.
-
Lewis Coe (2003). The telegraph: A history of Morse's invention and its predecessors in the United States. McFarland.
-
James Gasser (2000). A Boole anthology: recent and classical studies in the logic of George Boole. Springer Science & Business Media.
-
Andreas Hotho, Robert Jäschke, Christoph Schmitz, Gerd Stumme (2006). Information retrieval in folksonomies: Search and ranking. European Semantic Web Conference.
-
Jukka K. Korpela (2006). Unicode explained. O'Reilly Media, Inc..
-
C.E. Mackenzie (1980). Coded-Character Sets: History and Development. Addison-Wesley Longman Publishing.
-
M. Riordan (2004). The lost history of the transistor. IEEE spectrum.
-
Michael C. Schatz, Ben Langmead, Steven L. Salzberg (2010). Cloud computing and the DNA data race. Nature Biotechnology.
-
Claude E. Shannon (1948). A mathematical theory of communication. The Bell System Technical Journal.
-
Jon Stokes (2007). Inside the Machine: An Illustrated Introduction to Microprocessors and Computer Architecture. No Starch Press.
-
Marcia Lei Zeng (2008). Metadata. Neal-Schuman Publishers.