Date |
Name |
Revision |
| 2/9/05 |
Mobus, G. |
Revised section 1.2 to better explain the process of problem space decomposition. |
| 10/13/04 | Mobus, G. | Added a paragraph in section 2 regarding convergent vs. divergent discourse. Added text to sections 2.4 and 2.5. Provide link in section 7.1 for the current project task list. |
| 9/10/04 | Mobus G. | Started expanding section 2 Started new section 10 for End notes. |
| 9/6/04 | Mobus, G. | Added example Discourse for Global Issues Network for global warming in section 8. |
| 9/2/04 | Mobus, G. | Added sections: 1.6, 4.7, 5.6, 5.7 all dealing with search and data mining |
| 8/27/04 | Mobus, G. | Initial release |
Globalization means many different things. But one aspect of the phenomenon is the connecting of geographically distributed actors with similar interests into networks for the purpose of identifying and/or solving issues of global importance. This connection is made feasible by the Internet. Today it is possible for a global-scale network of many hundreds, if not thousands, of individual actors to share ideas asynchronously. We call this capability "electronic discourse". Members of a virtual community can interact via software interfaces to conduct on-going conversations on topics of interest. Email listservs, usnet and discussion boards were first generation e-discourse applications. These applications impose a minimum structure on the process of discourse. They basically organize topics and maintain a threading structure that allows for responses to be tracked. Beyond this, they do not provide any internal structure that might further facilitate the discourse process in reaching some kind of conclusion. And, even more importantly, they do not provide any management of the explosion of information that comes from the combined contributions of a huge number of participants. On a global scale, and with possibly millions of participants in a virtual community, it is vital that information be meaningfully consolidated, or pruned (if found unhelpful) in order to keep the discourse focused and productive.
More recent entries to computer-mediated discourse systems, such as E-Delphi (see below) provide somewhat more structure, but require considerable human intervention for moderation. Even some of the email lists, usenet newsgroups and bulletin boards require a human moderator to filter, edit or summarize if they are to keep productive discourse going. Very little has been done in the area of computer-moderated, structured discourse support. This latter category goes beyond computer-mediated to actually include an intelligent moderator assistant. Such a facility may allow communities of interested parties to conduct true peer-to-peer collaborative, deliberative discourse without the time consuming and burdensome need for human moderators.
Communities of interested parties or actors often seek to carry on a discourse activity with the intent of coming to some kind of conclusion and consensus. Communities form around common interests and members share similar values, ideas and objectives. Thus, the potential for agreement is built into the nature of the community.
What is not part of the majority of e-discourse applications is an internal structuring that is designed to optimize the process and assist it in finding consensus views. The tool described in this document is proposed as an assistant to virtual communities in conducting a structured discourse on topics of interest. It supports a top-down group analysis of a subject domain, the accumulation of documentation that supports the process, and the initial stages of a bottom-up development of action proposals (problem solutions). ConsensUs extends the idea of threaded comment structure by introducing the concept of typed discourse structures and specifying an organization of these structures. The introduction of organization (internal structure) fosters keeping the community members "on-topic" without sacrificing flexibility. Members are able to pursue ideas in a semi free-form but kept within the domain of interest.
There are two new ideas in ConsensUs that facilitate arrival at consensus, or at least, nuclei of consensus. The first idea is based on learning and memory in brains, specifically short- and long-term memory effects. In this approach, each contribution (except for comments - see below) to the discourse is given a specified time to live in the database. If that element is reinforced with additional added contributions, as explained below, then the time to live value is increased and the item persists as part of the overall structure and is accessible to the community. If, however, the item is not reinforced by activity, it means that the community does not support it and its time to live value is decremented (daily). When it reaches zero, the element is archived and removed from the discourse structure. In this way, the structure emerges from the activity of the community and reflects what the community considers important.
The second new idea is the use of computational semantic analysis to assist finding common themes and what we will call nuclei of consensus. The details of this approach will be given later, but the central idea is to aggregate and collapse or coalesce comments whose semantic content indicates a high degree of similarity. Such an aggregation does two things. It first reduces the information load by providing a weighted comment that represents a commonality of ideas, values, and objectives. Community members can grasp the core of the theme by reading a single comment that represents the nucleus rather than having to read, and recall all of the comments that seemed to agree. The second thing it does is provide members with a sense of how strong the consensus is for a particular theme (nucleus). This may aid in members being swayed in the direction of the perceived consensus. But of course, it may simply invigorate their efforts to move the discourse in a different direction.
We often find on-line or virtual communities forming in an ad hoc manner in several media. Usenet provides an ample number of examples of communities of interested parties spontaneously forming in existing usenet groups. Members discover common interests, usually in some sub-topic of the named group, and at some point decide to form a new newsgroup within the usenet hierarchy.
Increasingly we see ad hoc communities of peer members arise where each member is seen as an equal actor or contributor to the discourse. In addition, the increasing size of some of these communities make it potentially untenable to consider serving the community from a central server. In the last few years we have seen a number of peer-to-peer (P2P) technologies arise that provide a distributed computing environment that supports data and processing cycle sharing across a large number of members. Witness the "success" of networks like Napster, or the clever distribution of a computationally expensive process like looking for signature signals (of extraterrestrial intelligence) in a huge matrix of data in seti@home.
A P2P platform solves a major problem in the Internet in allowing nodes with dynamically assigned IP addresses to maintain a persistent (even if intermittent) identity presence in the network. Each node becomes both a client and a potential server. Data can be distributed variously throughout the network so that redundant access is possible. Additionally, some platforms, such as JXTA (see below) provide security features that could be useful in maintaining a secure community.
With this in mind, we propose to build ConsensUs on top of a P2P platform.
In a given ConsensUs application, the community organizers can decide on the issue of member identity, whether members will be identified by real names (full transparency) or by pseudonyms (moderate anonymity). We do assume that some measure of control over the joining of a peer group will be maintained. But the ability to have "frank" discussions by hiding real names might be a plus.
In this section we describe the process by which a community of interested
parties (or community) can explore a subject space and through a process of
discovery, map out the dimensions and positions taken in the space.
The overall process of
structured discourse can be described as being similar to the
top-down analysis of a problem space. It is not dissimilar in
form to the process of outlining used in composition. A top-level
subject is broken down into a set of next-level sub-topics through
iterative deliberation on the nature of the top-level subject.
You ask the question: "What are the main sub-topics that need further
refinement?" In structured discourse, this question is expanded
through discourse with multiple participants who themselves, submit
candidate sub-topics, ask questions or raise issues, and supply
commentary on the issues and sub-topics proposed.
A subject or topic is identified by a noun or noun phrase, it's name, which to some greater or lesser degree captures the semantic quality of the subject. This identifier (in some sense similar to function identifiers in programming languages) is the abstraction of the full semantic space of the subject. It should capture and convey the collection of elements within that space. For example, the subject "Global Warming/Climate Change" (see example below in Section 8) is a general rubric subsuming a whole constellation of ideas that need to be teased out. Every area of interest can be given a topic heading or name.
But then, a topic, if it is an abstraction, can be broken down into a set of sub-topics (just as this document is organized). With analysis, careful thought and deliberation, represented in the issues and commentary supplied at a given level, the sub-topics, all being of about the same level of detail, will emerge from the discourse. That is they will represent the right level of structural decomposition of the topic. Again to follow the example, global warming might be broken down into the sub-topics (not meant to be exhaustive, just illustrative):
Recursively, a community of interest can decompose a subject/topic into increasingly refined sub-topics. The process ends when no one in the group can think of a lower level sub-topic.
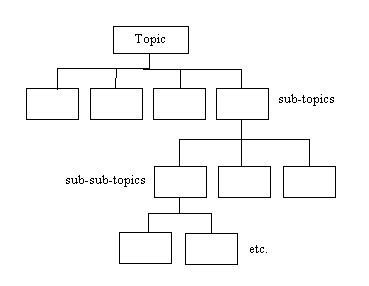
The subject is decomposed into a
subject tree where each level of the tree represents
a more refined level of detail in the subject space. This tree
structure (Fig. 1)
is the basis for the structured discourse in ConsensUs. The
figure leaves out the issue and comment objects (which are leaf nodes
attached to each topic node shown - also see Figure 5 in section 3.0 to
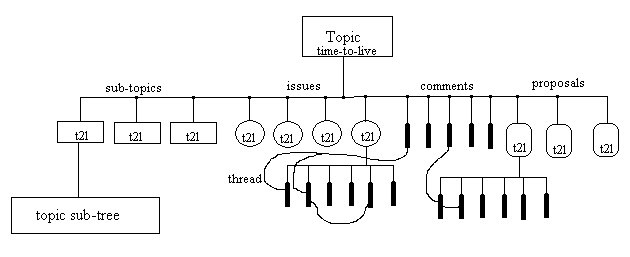
see the structure of a filled-out topic node.)
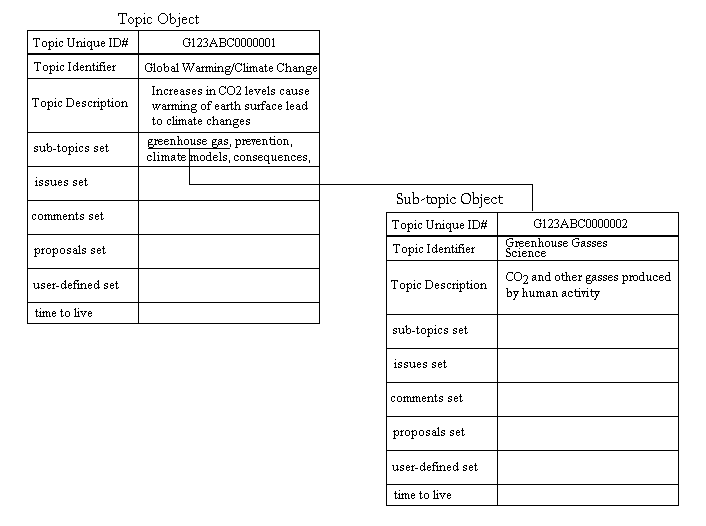
The topic/sub-topic tree forms the skeleton framework for the ConsensUs discourse structure. All other discourse objects (described below) are children nodes from one of the topic nodes. As shown in Figures 2 and 3, there are additional sets of objects associated with each topic node. The addition of nodes (through the same kind of nomination process as described above) add additional children to each of the interior nodes of the discourse (topic) tree. These additional node types provide the basis for analysis of the subject (semantic) space as mentioned earlier. Essentially, over time the topic tree emerges from the discourse of the community.
The topic/sub-topic hierarchy forms a skeleton for the discourse that will put "meat on the bones". In this section we describe the dynamics of subject space emergence from group participation. We then describe the "fleshing out", as it were, of the skeletal topic structure. We view this as a top-down analysis of the subject space, an analysis conducted by the community in collaboration. Later, we will consider the nature of a bottom-up process (also collaborative) to find action proposals or solutions to the problems identified in the top-down analysis.
In the following description we will
discuss each kind of discourse object seperately. It is important
to note that the evolution of the topic structure (tree) is a very
dynamic process whereby much time and energy may be spent on one level
of the tree, with members generating many issues and comments before
resolving the sub-topics to be later explored. We envision
communities deliberating at a given level to explore most of the
important issues under the topic before growing the tree through the
addition of new sub-topics. However, it is also possible to grow
one or more branchs of the tree, proceeding to a deeper level, if that
is the "path of least resistence". There are no restrictions on
the order in which levels get added to the tree. Additionally, we
plan to provide mechanisms that will allow the restructuring of the
tree if the community decides that a given branch should be promoted to
a higher point in the tree, or demoted to become a child of some other
node that is a descendent of the one to which it is currently an
offspring. The process of discourse should be flexible but always
produce a tree structure, whether balanced or not.
The explication of the subject space is accomplished by iterative decomposition and community nominations. To anticipate the detailed description, later, of one of the mechanisms of consensus, we mention here the dynamics of how the topic tree comes to represent a "best view" of the subject space. In essence, though any CM may nominate a sub-topic under any existing topic/sub-topic, in fact, the community as a whole may not agree with that nomination. We will describe the process of commenting later. But for now, note that when there is little or no support by the community for the nominated topic, then over the course of time that topic will simply disappear. This is accomplished in a straightforward manner.
Each new topic added to the tree is assigned a default time-to-live (t2l) value (a long integer) measured in days. Each day that the nominated topic does not receive some form of community support (described below) the t2l value is decremented. If it reaches zero, then the nominated item is removed from the set (perhaps after archiving for audit trail support). If, on the other hand, the community provides support for the item, then it's t2l value is incremented by a non-unit value and it continues to live in the structure. In fact, when the t2l value exceeds some agreed upon limit, the item can be made permanent. This means that the community has agreed that the item is a genuine and important sub-topic and that it is at the appropriate level in the tree.
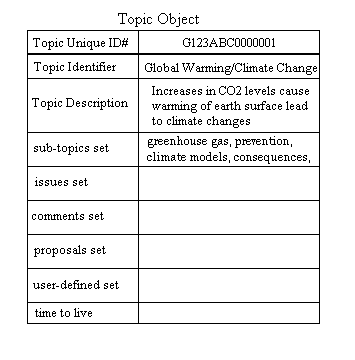
Support for any given sub-topic obtains from CMs adding structures to the topic. Once such structure is the topic object described before. Adding topic objects to the sub-topic set of a topic indicates interest and support for the parent node. But topics alone do not define the knowledge space of a subject. CMs may also support a topic by adding additional types of objects to the appropriate sets in the topic object. In Figure 2, above, there are four additional sets containing object types: issues, comments, proposals, and a user-defined type.
Under any topic the community may deliberate on a number of related issues or questions. Often, in fact, these will be expressed as questions. For example, following the global warming topic above, an issue might be: " Is human activity (the burning of fossil fuels) the major source of CO2 increase in the atmosphere?"
Whereas sub-topics identify the
subject structure and act to organize the
hierarchy of ideas, issues identify the particular concerns that need
to be
addressed by the community. These are questions that need to be
answered or
problems that need to be solved. The process of discourse will
likely produce a number of issues under any given
topic/sub-topic. These will be discussed in commentary (comment
objects also linked under the topic alongside the issues). Issues
are seen as the drivers behind further decomposition and will, as well,
be instrumental in formulating proposals for action (section 1.5 below).

The addition of issues to a topic node are support for that topic and the topic t2l is incremented accordingly. In fact, if the topic is a sub-topic then the incrementing propagates up the topic tree to the root.
But issues do more than merely support a topic. They begin to add substance and direction to the discourse of the community. Identifying (discovering) the important issues at any level in the topic tree is a major part of the process. Adding comments to the issue is the means by which the community proceeds to this identification.
Issues are the heart and viscera of the discourse structure. Comments are the muscle, sinew, arteries and veins.
Comments are, as with any discourse system, free-form text (although in ConsensUs we envision support for graphics, applets and multi-media) that capture all of the relevant ideas, reasoning, observations, data, etc. that support the other structures. Comments are about one of the other structures and therefore, every other structure type has a comments set.
In ConsensUs, comments are threaded in three dimensions. First, comments are threaded within the level and object to which they are rooted. This is essentially the form of threading one finds in a listserv or discussion board. Secondly, comments may be threaded across object types at a given level. That is, a comment may be about both an issue and a sub-topic. Finally, comments are threaded between levels, so, for example, a comment thread may start in the parent topic node and extend down to comments in the issues, sub-topics or proposals nodes. This threading structure allows a CM to pickup and follow a comment thread from many different perspectives.
Another feature of ConsensUs is that comments can be subjected to group voting. Not every comment needs to be voted on, but comments that act as propositions of position, fact, etc. may be more valuable to the discussion if the CMs are allowed to weigh in on the content. As such ConsensUs provides a mechanism to let CMs rate attributes such as relevance, importance and validity, on a Likert scale (0 to 10). Comments receiving good ratings on these scales contribute more to the incrementing of the t2l variable for the interior nodes from their parent back to the root. The voting mechanism keeps track of who (see identity transparency/anonymity above) has voted already so that repeat voting does not occur.
Comments are also the basis for the second kind of consensus building that we are interested in. The aggregate of comments (especially within a thread) may be analyzed for semantic content to determine if some measure of consensus is developing. The theory here is that if many people are saying very similar things (within or across threads) then it may indicate the development of agreement about the discourse object of interest. That is to say, if there are a large number of comments within a given topic that are effectively similar (see below for discussion of semantic analysis) then there could be a growing consensus within the topic.
Periodically, then, comments are analyzed to determine if a consensus pattern is emerging. As will be described below, a semantic center to a comment cluster (if it is found) is computed and the comment closest in space to that center is put forth as the representative of the idea finding consensus. Perhaps at that point, a designated CM would provide a summary, edited version of the comment, tagged as being representative and weighted in some way to indicate the level of consensus. The visualization of the topic tree would then be modified so that, where they exist, the representative comment is all that appears, from that cluster, when one expands the comment set. The comment appears (on examination) along with a header marking it as a representative and a numerical value or weight indicating how "good" a representative it is (essentially how tight is the cluster). Another value can indicate the proportion of total comments that are within the representative's cluster. Thus a CM has an ability to judge the weight to give to the idea that a consensus is forming. [On double clicking a representative you can get access to the entire cluster for auditing.]
In effect then, a large number of comments can be collapsed or coalesced into a single representative comment that reduces the amount of text that a CM would have to peruse to get the jist of the consensus idea. It is believed that such a process (which does not throw out information but merely hides it from immediate view) would greatly reduce the information overload experienced by participants in many other kinds of discourse systems.
We should note that it is more than likely that within the comment set of an object the analysis may identify more than one cluster of similar ideas. Also such clusters may be more tightly or loosely defined. We would advocate a threshold (user-defined) that would have to be met before a cluster is declared. In any event, the existence of multiple clusters in a given set would be indication that more discussion was needed!
Thus far we have been concerned with the process of discovering the subject space and developing the topical analysis of that space. We have also added considerable detail to the discourse structure as we went. As envisioned, this process in basically a top-down, but also iterative in that CMs can easily revisit and revise upper levels of the tree. There are no constraints on when one can add issues, comments, etc. to the tree.
But the general purpose of a subject discourse is to come to some kind of conclusion, propose actions to take or solutions to problems (as identified in the issues) or goals to be achieved. In that vein, ConsensUs adds the Proposal object to the discourse structure. Structurally it resembles an Issue object but it can also have a voting attachment like a comment. In this case the attributes are desirability and feasibility [Note: other attributes may be defined by the community.]
There is no absolute rule about when a proposal can be added to a topic. However, as envisioned, proposals will most likely be added after a substantial amount of discourse under that topic has been completed. And, in fact, one can easily see how proposals could be added starting from the bottom-most level of the tree -- solving the more detailed, immediate problems contribute to solving the higher-level problems.
In general, then, proposals support a bottom-up approach to answer the issues/questions posed in the topic. As with topics and issues, proposals have a comment set and comments added to the set provide interest support for the proposal. Voting for proposal comments and for the proposals themselves influences the incrementing of the t2l variable propagating back up the tree.
Several tools are available to CMs to further allow the exploration of the evolving subject space. A standard indexed database search engine will be provided. This allows a CM to quickly search the various discourse objects for key words. CMs can then browse pages generated from these objects. Searches can be conducted just within one type of discourse object (say comments), a combination of types, or within all types. The search engine must run on one or more dedicated peer nodes acting as search servers.
The second tool is a personal search agent. This tool differs from the search engine in that it does not search an indexed database (which requires a dedicated server as indicated above). Instead, this agent conducts an on-going search of the P2P network for objects that contain key words indicated by the CM. The search is conducted on all archived objects (comments), not just visible objects.
What is unique about this tool is that the agent learns additional terms/phrases that help refine the search process. When a search agent finds an object meeting the key word criteria of the CM, it returns the object for review by the CM. If the CM indicates that the object is particularly useful, then the agent saves additional significant words that if finds in the document. If, it finds these terms in other objects that the CM indicates are worthwhile, then it can recommend these words to the CM as additional key words for future searches. Together, these tools may help CMs to discover further patterns of consensus or trends in thinking of the group.
Finally, provisions are made to export object contents to a standard relational database format so that conventional and future data mining tools can be used in ways not currently envisioned.
This section discusses some prior work in developing systems of community discourse. This is not a comprehensive coverage. It does not, for example, cover systems such as Robert's Rules of Order for meetings, or public debate, or any number of in-person, synchronous methods for allowing people to participate in meaningful discourse.
Rather, this will provide a brief review of some of the more important aspects of (particularly asynchronous) discourse systems, with special reference to electronically supported methods.
Additionally, the concern we have is for the support of what might be described as "convergent" discourse as opposed to "divergent" discourse. The former involves both an intent (on the part of the participants) to reach agreement or consensus and a process to support achieving it.
One could argue that one purpose of participative discourse is to try to reach general agreement, if not consensus, on the nature of the problem and what should be done to solve it. In essence, then, communities seek to understand the problem(s) they face by asking key questions:
Thus, with the exception of the need to involve "experts" in the process, the Delphi method provides an reasonably structured process for attacking some, if not all of the questions posed above.
The method was conceived as providing experts with an unbiased approach to reaching agreement, or at least, finding areas of disagreement for further work. The reason experts are considered as the community of interest is that, presumably, experts will remain focused, and on topic. This stands in stark contrast with many unmoderated usenet groups where the voices of non-experts often drown out those of experts (or at least serious students) trying to carry on a dialogue.
Another aspect of the Delphi method is the need for a moderator or facilitator to coordinate the production of proposals or questionnaires, to summarize the responses and to provide the feedback to the community. The need for human intervention can cause significant delays over many iterations of the discourse. Though Delphi is meant to be an objective exploration of the subject space, in fact, the influence of the facilitator (or whoever formulates the questions/propositions) can lead to biases, if not inefficiencies in discovery. Too often, the facilitator can inadvertently guide exploration in certain directions or use up valuable time asking irrelevant questions.
More recently, attempts at automating the communications aspects of the Delphi method have been made. There is at least one Web-based version available [HERO 2001].
The reliance on human moderation/facilitation seriously limits the scalability of the method. Clearly, really large communities of interest cannot be served. Finally, for subject spaces involving new sets of questions, new problems for which there are no experts around, the method does not offer much help.
Electronic discourse systems (EDS) have been developed almost from the first time two computers were hooked together via a network. Bulletin boards and email were rapidly put to work in the service of community discourse. The latter by virtue of listserv software/protocols. Usenet came on the scene in short order.
Most of these systems were designed to let communities conduct an open asynchronous discussion with a minimum of constraints. Listservs and usenet provided support for human moderation. And some forms of automated filtering have been developed. But for the most part these systems have been more useful for supporting on-going, open-ended discussions. A common aspect of the dynamics of these discussions is the forking of threads of commentary. Community participants are free to follow any or all threads within the framework. There is no necessary relationships established or tracked between various threads. Such discourse is considered divergent.
While useful to conduct on-going discussions, there is no structural support, beyond moderation, in these systems to focus discourse for the purpose of coming to decisions. The next generation of EDS involved the incorporation of some form of internal structure that accomplishes the goal of providing direction and focus. E-conferencing (e.g., Web conferences) systems provide an environment that allows conferees to be widely distributed, generally have topic (not just thread) support, and provide mechanisms for enforcing exchange norms (who gets to respond, to what and when). A number of the commercial tools available attempt to replicate the milieu of a real-time, in-person conference (in some cases including video and audio streaming). As such, they are not always useful for asynchronous communications.
Decision Support Systems (DSS) are a family of computer-based tools that allow groups with interest in arriving at a decision for action. There are commercial products available that are used, for example, in the enterprise context to make effective business decisions. Some of the newer offerings are coupled with data mining facilities (or can import structured information from other products), user graphics tools that allow construction of semantic maps, and other features. The purpose of these systems is to facilitate the communication of ideas (comments), proposals, options, etc., collection of these text objects in some knowledge base, and (generally) provide for various forms of voting on those objects. These systems are highly structured internally, which helps to focus the ensuing discourse. Such systems are used by many companies to examine marketing strategies, financial portfolios and many other complex problems that require many inputs, facts, opinions, views, etc. That such systems have specialized data requirements tends to make them less flexible for use in an open discourse setting. Finally, of course, the commercial products that are available tend to be rather pricey so are precluded from general distribution.
Among the newest Web-based discourse systems is the Wiki Web [Cunningham, 2004]. This tool allows participants to create and edit web pages served from a central server repository. The major advantage of using HTML is the ability to include hyperlinks to any resource so that semantic linkages can be constructed or evolved over time. This tool, being maximally flexible, can be used for any number of applications (not just discourse). See for example the now renowned Wikipedia, an on-line user developed encyclopedia. And, most importantly, it is free!
This highlights one of the major weaknesses of EDS. Those who study the content of discourse in electronic media are quick to point out the narrow bandwidth of text files compared with the full range of human-human communications in person (body language, etc.). Effective use of EDS will require participants to enter into the process with full understanding that they need to be deliberative.
The development of an EDS such as ConsensUs will need extensive study of how people actually work with the system. We will look to invite researchers involved in the usage issues to help refine the functionality of the system.
A good example of a highly structured deliberative, collaborative discourse, often conducted electronically, is the standards setting process used by a number of communities. A good example of this process is that of the W3C (World Wide Web Consortium). Evolving standards for Web-based technologies are worked out via this process.
The process is structured in that it involves the promulgation of standards (technical) proposals by a limited group of experts. Generally these standard involve fairly complex technical issues and must be broken down into a hierarchical structure (like an engineering specification) so that attention can be focused on whatever detail is required.
There follows a period of open comment where members of the community may offer their observations, suggestions, etc. These are collated by a team of experts who extract useful information from the texts and edit the proposal(s) to incorporate the information. The modified proposals now go out for another round of comment.
This is an iterative process that may go on for several rounds. As such, one expects to find a convergence of ideas as the standards emerge. Such convergence often represents a fair amount of compromise to reach consensus. And, it does happen that some processes do not converge and no standard is arrived at. Still, more often than not, the process yields significant results. Even failures sometimes provide a basis for later attempts. A great deal of credit for the success of this process comes from the degree of structure in it. Of course a significant amount of credit must go to the fact that the topic area is quite technical and involves experts. Never the less, the structure enhances the likelihood for success and certainly increases the efficiency of the process.
Another form of stuctured, collaborative discourse is the open source software development process. One might not always consider software development as discourse, but in fact it does entail the capture of ideas in a language (even if a formal one) and disseminating those ideas to a community for review and modification.
Below we provide a peek under the hood at the various types of discourse structures used in ConsensUs. We use an object oriented description. Objects are defined by a class declaration. We use a Java-like syntax.
The structures defined here, constitute a representation of the discourse knowledge developed from the acts of the community members.
This class is the base class from which all discourse objects are extended. This class contains the instance variables that provide identification, authorship, text for name and description and a link to the parent node (or null if the node is the root). [Note: The class definitions given here are only for instance data and do not necessarily reflect all such data, i.e., with the exception of the timeDateStamp field, no maintenance/overhead variables are shown.]
abstract class DiscourseNodeAn Id object is essentially a global URN (JXTA) assigned at creation time. The author variable can be either a ConsensUs antonymous name or the actual name of the participant (group member) depending on how the system is set up when the P2P network is created. The text field carries the terse name/identification for the derived object. For example, in a Topic object (see below) this would be the topic title field. The description field is generic for all derived object types. Finally, the parent is a back reference to whatever node is the parent for the instantiated, derived node. The DiscourseNode is abstract, meaning that it cannot be instantiated as an object.
Id id // JXTA URN-based ID
String author // anonymous or attributed
String text // discourse text
String description // short explanatory description if needed
DiscourseNode parent // back reference to parent node
DateTimeStamp created
DateTimeStamp last_edited
end class
class Topic extends DiscourseNodeAs shown in Figure 2, a Topic class object extends the DiscourseNode class by adding a timeToLive (previously referred to as t2l) variable. In this definition it is shown as a primitive long integer. In actual practice this variable may be a reference to an Adaptrode-like object that acts like a memory trace device in a discourse object. This will be part of the on-going research effort for this project.
long timeToLive
Set<Topic> subtopics // set of subtopics
Set<Issue> issues // set of issues under this topic
Set<Comment> comments // set of comments under this topic
Set<Proposal> proposals // set of proposals under this topic
Set<UserDefined> other
end class
The Topic class adds five Set (a generic container in Java) objects to the DiscourseNode. Each set contains a single instance reference to a distinct DiscourseNode of types Topic (recurrent reference), Issue (see below), Comment (see below), Proposal (see below) and a generic user-definable DiscourseNode extended type. Each set contains references to children nodes of the respective types as defined below.
Topics may be non-editable. Since topics can die from non-support, a poorly worded topic may be abandoned and will just go away. Rather than allow editing, a new (reworked) topic may be nominated that better states the nature of what is being discussed. The thought here is that CMs will be very careful in how they construct topic nominations if they know they cannot edit them.
If the topic hierarchy forms the skeleton of the discourse structure, then Comments could be said to provide the muscles.
Comments are the least restricted text object in the ConsensUs application. CMs are free to write anything that they feel is appropriate to the on-going discussion. However, structurally, comments are attached to a specific topic (or, as seen below to an issue or a proposal also) which implies that they should be about the topic at hand - the age-old problem of being "on topic" takes on specific meaning in this context.
The author of a comment may nominate it for "voting". Doing so causes the instantiation of a CommentScales object as a member variable (see below). The display of a comment will show a set of horizontal slide bars with scales from 0 to 10. These values are initialized to 0. A CM can set the bars at whatever point on the scale they deem appropriate and then, when satisfied, submit their vote. Voting will probably need to be managed by selected rendezvous nodes (a JXTA term for peers that provide message brokering services) to ensure fairness, security, etc. Each CM gets to vote once on any one comment that has been nominated. The vote tally, the value of the scale, is updated frequently so that all other CMs can have a fairly recent view of the weight of support for a given comment.
Comments are also threaded. Each comment is assumed to possibly be in response to either a comment from a higher level in the hierarchy, a comment in the same set as itself or a comment in a set from one of the other discourse objects at the same level in the tree. All comments can only refer to one previous comment. However, any comment may have many other, later comments, refer to it. The ThreadLine class provides for the maintenance of these various threads and ConsensUs provides a means to traverse these threads to track through the related comments.
As described previously, when comments are semantically analyzed and found to be within the boundary of a developing nucleus of consensus, those comments are coalesced into an archive and only the most representative comment (or an edited version) is left visible in the Topic tree. Representative comments will carry a weight variable, ranging between 0 and 1, to indicate the relative level of consensus represented. This will depend on the total number of comments in the set and what fraction of that total is within the boundary and how "tight" that boundary is. Or, in other words, how small the radius of the cluster is. Only representative comments will be shown with a consensus weight value.
class Comment extends DiscourseNode
CommentScales votes
ThreadLine thread // comment thread
float weight // consensus weighting (0 - 1)
end class
class ThreadLine
Set<Id> immediateResponsesTo
Id respondingTo
end class
class CommentScales
float relevance // ave. of Likert scale (0-10)
float importance
float validity
end class
In deliberative, collaborative discourse it is important to make statements about what should be deliberated, what questions need to be answered, what problems need to be solved. The Issue object is used to make these statements/questions explicit. There are no hard rules about what can be put into an Issue text. It is assumed the purpose and dynamics of interactions of the community will establish the norms of what should be called an issue.
As conceived here, an issue might be related to a sub-topic at its same level in the topic tree. Thus, the CM nominating the issue would indicate this link. It is not the case that sub-topics have to have been posted prior to nominating an issue, and the relatedTo link may be updated if the issue subsequently appears to be related to a newly nominated topic.
Often, issues under one topic may be related to issues under a different topic. Such issues are called cross cutting because they involve more than one aspect of a topic tree. This class supports a set of Ids that allow nominators to identify issues from other topics that are related, in some way, to the current issue. CMs can then browse the set of issues that appear to be related and offer comments (threaded) to address these relationships. Similarly, CMs that find some issue that they belive is related to an issue under a different topic may add those issues to each others crossCuttingIssues set. Adding a cross cutting issue to an Issue object increments its t2l variable in the same way that adding a comment does.
class Issue extends DiscourseNode // also called a Question
long timeToLive
Topic relatedTo // sub-topic
Set<Id> crossCuttingIssues // links to issues under other topics
Set<Comment> commentsAbout // comments about Issue
end class
The purpose of this class is to allow CMs to nominate answers, solutions, actions, etc. As with the other objects discussed, there are minimal constraints on what can be put into the text of this object. Comments about proposals are referenced in the commentsAbout set and each comment made about a proposal increments its t2l variable.
Proposals are "voted" on by the community in two ways. Like topics and issues, a proposal needs support by getting comments in order to live long. But, in addition, a proposal invites additional voting in the form of two (at least) attributes: desirability and feasibility. These are rated by the same Likert-scale method as used in Comments. High ratings in these areas will strongly affect the incrementing of the t2l variable.
Comments associated with a proposal may actually contain links to various kinds of documents such as action plans. Thus, ConsensUs can work to coordinate projects intended to solve problems, construct artifacts, etc.
class Proposal extends DiscourseNode
Set<Comment> commentsAbout // comments about proposal
ProposalScales votes
long timeToLive
end class
class ProposalScales
float desirability
float feasibility
end class
We will reserve this class to allow community organizers to create a discourse structure type that is not specifically provided in the ConsensUs system.
class UserDefinedType extends DiscourseNode
Object userFields // reference to an object of user's fields
long timeToLive
end class
In a large community of diverse actors, and for some subject domains it may not always be feasible to reach a consensus. This tool can not guarantee that a consensus opinion will emerge. However, it is possible to use this tool to identify areas where sub-groups form consensus around themes.
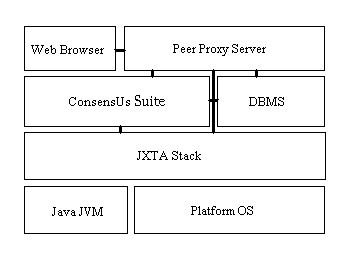
The user interface for ConsensUs will be a standard graphical Web browser. All interactions between the user and other peers in the network will be through this device; however, the browser may launch helper apps - such as a media player - when called upon to do so. Other interactivity will be through applets (e.g. the Topic tree browser frame), Javascript and forms, and various server-side scripts to present page information and collect user input. These server-side scripts will reside and run on the peer, being served by the peer proxy server as servlets.
The presentation of the UI will consist of HTML that is dynamically generated from the servlets, and then rendered with CSS. The collection of data will be through standard HTML forms. Ideally, the presentation will be compatible and will display correctly in any current web browser; this can be achieved through the use of CSS filters, which allow a great deal of control over the rendering of HTML elements in different browsers.
Interfaces to view, add, edit, delete, and search for discourse objects, as well as interfaces to register an account for a given subject domain (a ConsensUs group), to login, to manage account information, and to configure the ConsensUs application will need to be provided. Also, if a user belongs to more than one subject domain, an interface that lets the user choose and switch subject domains should be implemented. These interfaces drive actions the other components of the ConsensUs architecture will take; for example, adding a new discourse object will run a servlet on the peer proxy server to parse the object’s information from the submitted HTML form, which then gets passed to the ConsensUs Suite for addition to the appropriate local database and propagation to other ConsensUs peers via the JXTA network.
The peer proxy server in the ConsensUs architecture acts as a personal web server for the peer. It is responsible for running the server-side scripts that present the ConsensUs discourse data to the user, as well as collecting the user's input for storage in the local databases and publication in the ConsensUs peer groups by the ConsensUs Suite.
Jetty is the most likely candidate for the peer proxy server, and is included with the standard JXTA distribution. It is a Java-based HTTP server and a servlet container that acts as a single component, able to be embedded into Java applications. With it, servlets will act as the server-side scripts, generating dynamic HTML populated with requested ConsensUs discourse data for presentation to the user; also, they will collect information from the user, such as a new discourse object, and format this information for local storage and remote publication.
There is a choice of languages for developing the servlets, such as JSP and PHP. However, which language is used is more or less arbitrary. JSP is an obvious candidate, in sticking with the Java-theme of the ConsensUs platform; however, the current ConsensUs prototype was developed in PHP, and the Java Servlet SAPI for PHP is designed to run the PHP engine as a servlet (see http://www.php.net/manual/en/ref.java.php for more details). Thus both are possible options.
The local databases in the ConsensUs architecture will provide persistent storage and local access to the discourse data within the user’s subject domain. Advertisements and messages in JXTA come and go, having relatively short lifetimes; the local databases are designed to be repositories of the discourse information they carry, so that this information persists.
The DBMS used for the local databases will be MySQL. It will contain one or more pairs of databases, where each pair corresponds to current and archived discourse data for a subject domain the peer participates in. Each one of these databases will carry tables that store information about topics, root topics, issues, proposals, comments, and other users. The ConsensUs Suite will manage these databases, providing an interface to the servlets on the peer proxy server for accessing and storing data in the databases, and providing an interface to the ConsensUs peer group services that will update and add data to the database through discovered advertisements.
In the case that more than one ConsensUs user for a given peer exists, if those users all belong to the same ConsensUs subject domain, the DBMS will contain only one pair of databases; if they belong to different subject domains, the DBMS will contain a pair of databases for each domain. Also, if a single user belongs to more than one subject domain, the DBMS will contain a pair of databases for each domain. Thus the DBMS will contain a single pair of databases for each ConsensUs subject domain that the peer participates in; the database pairs are not mapped to users.
JXTA, at its core, is a set of protocols that allow devices to communicate and collaborate as peers. ConsensUs, at its core, will rely upon the JXTA platform to distribute and manage discourse data, in a decentralized way, among ConsensUs users. Due to JXTA’s complexity and its importance to ConsensUs, Section 6.4.1 will provide an overview of the JXTA platform. Building upon this overview, Section 6.4.2 will then offer a more detailed design of how ConsensUs - namely the ConsensUs Suite - will leverage the JXTA platform.
Central to JXTA are the JXTA protocols, which define the ways in which peers interact, and provide a basis for applications and services to utilize a P2P network. There are six JXTA protocols:
Only two of these protocols, the PRP and the ERP, are required to be implemented on every peer; these are the JXTA Core Protocols. The rest of the protocols – the JXTA Standard Protocols - are optional, though useful. All of the JXTA protocols employ a common messaging layer, which is what binds them to specific network transports.
All communication that takes place via the JXTA protocols is conducted with messages, the basic unit of data exchange in JXTA. A message is an object that contains an ordered sequence of name/value pairs, where the value can be of any arbitrary data type. Messages may be sent as XML documents, or binary data, depending on the physical resource constraints of the peers implementing the JXTA protocols. In either case, they act as an envelope for the transfer of any type of data. Because the message is tagged as name/value pairs, each peer can choose to process a subset of the message that it is interested in.
<?xml version="1.0" encoding="UTF-8"?>
<jxta:DiscoveryQuery>
<Type>2</Type>
<Threshold>1</Threshold>
<Attr>Name</Attr>
<Value>*sidus*</Value>
<PeerAdv>
<?xml version="1.0"?>
<!DOCTYPE jxta:PA>
<jxta:PA xmlns:jxta="http://jxta.org">
<PID>
urn:jxta:uuid-59616261646162614A7874615032503304BD268FA4764960AB93A53D7F15044503
</PID>
... remainder omitted for brevity ...
</jxta:PA>
</PeerAdv>
</jxta:DiscoveryQuery>
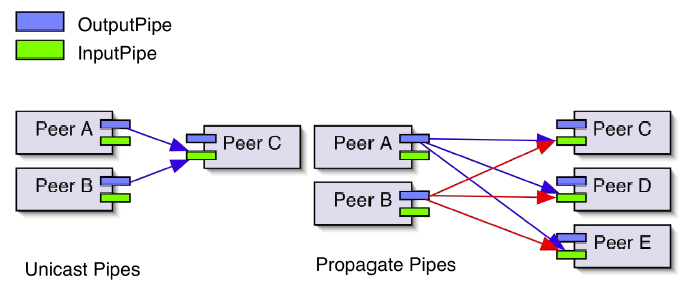
To send and receive messages, as well as other kinds of data, peers create pipes, which are virtual communication channels independent of physical network topology and peer location. There are several different types of pipe – asynchronous uni-directional (which is required for the JXTA protocols), synchronous request/response, bulk transfer, streaming, and secure – which use two different modes of communication: point-to-point or propagation. Point-to-point pipes connect two different peers together, while propagate pipes connect one peer to many different peers. To connect peers, pipe endpoints – called output pipes and input pipes, for the sending and receiving ends, respectively – bind to available peer endpoints, or network interfaces, on the peers. This process is achieved dynamically by the PBP at runtime. Once this has been achieved, the PBP will search for other peers (one or more, depending on the type and mode of the pipe) that are bound to the other end of the pipe, and attempt to resolve the connection(s) so that communication can begin. All pipes are represented by pipe advertisements, which are published by peers wishing to establish connections and then discovered by other peers. Pipe advertisements contain information about the pipe, such as a unique pipe ID and the type of pipe, and are used by peers to create pipes.
The peers in the JXTA network are any connected device that implements the JXTA protocols. (Note that peers are not the same thing as users in this case, although in many applications, they may be synonymous.) In JXTA, peers are independent and asynchronous of each other, and may be one of four types: a minimal edge peer, a full-featured edge peer, a rendezvous peer, or a relay peer.
Minimal edge peers can send and receive messages, but they do not cache advertisements they publish or discover through the PDP, and they do not participate in the routing of messages for other peers. Full-featured edge peers are typically the same as minimal edge peers, with the exception that they cache advertisements, and hence respond to discovery requests made by other peers through the PDP (though they do not forward them to other peers). Rendezvous peers have the same functions as full-featured edge peers with a few exceptions: they are used to propagate messages to other peers, and they maintain a list of other known rendezvous peers, called a PeerView, so that they may propagate messages to a wider number of peers. Finally, relay peers maintain routing information to other peers, and help route messages. The relay peer is queried by peers for routing information needed to send a message to other peers, and is able to forward messages to peers that are not directly addressable (such as peers behind firewalls or NAT devices). Any peer may implement the services needed to be a rendezvous or relay peer, and a single peer can be both; however, full-featured peers will typically make up the majority of peers, because rendezvous peers and relay peers require more physical resources. Peers are discovered and represented by peer advertisements, which contain metadata about the peer, such as its name, a unique peer ID, and available network interfaces (peer endpoints) over which the peer communicates. Peers are also responsible for publishing advertisements for every other kind of resource in the JXTA network, such as pipes, peer groups, and peer services.
JXTA allows peers to self-organize into collections called peer groups. A peer group is defined as a set of peers that have agreed upon a common set of services (functionality built on top of the JXTA protocols). JXTA specifies six core services for peer groups:
These six core services are not required, but are very useful. The core services can be implemented in any peer group, and are available in the default NetPeerGroup (the root group that all peers must join) using the JXTA reference implementations. If additional functionality is required, other services can be developed to provide the peer group with the desired functionality. Any additional services are either pre-installed or discovered via the PDP, and include peer services, which only run on the peer publishing those services, and peer group services, which run on multiple members of the peer group. A service corresponds to modules, abstractions that represent any piece of code used to implement a behavior in the JXTA network. Modules are described by several types of advertisements and are discovered through these advertisements as well.
Peer groups, coupled with these core services, essentially form more or less secure (depending on the security policy chosen) logical regions in the JXTA network. This allows published information and services to be protected against unauthorized access by peers outside the peer group. Peer groups also provide a scope for the services implemented inside them; it should be noted that all the core services listed above, and any developed peer group services, operate only in the context of the peer group. For example, in a ConsensUs peer group, the discovery service will only search for advertisements among the advertisements other member peers have published within the group. Peer groups are discovered by peers through peer group advertisements, which are published to the parent group and the group itself. Like all other advertisements, peer group advertisements provide metadata about the groups they represent, such as the group’s name and unique peer group ID.
As previously mentioned, resources in the JXTA network are advertised with XML documents called advertisements. Advertisements are the most common document exchanged via the JXTA protocols, and are used to represent and describe peers, peer groups, pipes, services, and any other resource that peers can discover. They are either created locally, to publish resources of the peer generating the advertisement, or discovered remotely via the PDP. In either event, they are cached locally on the peer (unless the peer is configured not to do so), and each advertisement possesses a lifetime in order to purge it when it becomes outdated. To extend the lifetime of an advertisement, it is republished before it expires. The JXTA protocols define eight base advertisement types:
Of these eight base advertisements, only five are required to be used in instances of JXTA: the peer advertisement, the peer group advertisement, and all three module advertisement types. This is due to the fact that the core JXTA protocols – PRP and ERP – depend on these advertisements. Other kinds of advertisements may be defined by sub-typing existing advertisement types or by creating a new advertisement type from scratch, enabling different types of resources to be advertised. Each resource possesses a unique URN-based JXTA ID, in order to uniquely identify it and refer to it in the context of the network, peer group, and peer.
Codats, a concatenation of the phrase “code and data”, are a resource that represents any kind of code or data that may be shared among peers. They exist only within the scope of a peer group, and are uniquely identified by a codat ID. Each instance of a codat is a copy of a codat, and may exist on one, multiple, or all peers of the peer group. By replicating a codat among multiple peers, it is insured to be more readily available, since peers often have a transient existence on the network. Each codat is able to be represented by a content advertisement.
Peers in the JXTA network operate on a role-based trust model, where authority to perform certain actions is given to a peer by another trusted peer. JXTA mandates that four basic security requirements must exist to guarantee security among communicating peers:
The XML messages that peers use for communication have the ability to add security metadata, such as credentials, certificates, digests, and public keys, in order to satisfy these security tenets. Digests guarantee the data integrity of messages; encryption of messages with public keys allows for confidentiality and refutability; signing messages with certificates allows for confidentiality and refutability; and credentials can provide the identity of peers for authorization. All of these security measures may be deployed within a peer group to safeguard communication and access to peer group resources.
The ConsensUs Suite will, among other things, leverage the JXTA protocols to distribute discourse data among all users of ConsensUs. By doing so, ConsensUs will not be relegated to deploying central servers to store all of the discourse information for a community and to handle all of the connections necessary to access that data – potentially resource-intensive tasks given a large amount of data and a large number of users – and will be able to provide security and redundant access to discourse data.
This section begins with a general discussion about the JXTA entities that will exist within the ConsensUs Suite, and then discusses what types of peer group services will be implemented and how they will be used. The ConsensUs Suite is arguably the heart of the ConsensUs architecture and the component with the most complexity; because of this, none of the information here is meant to be a part of a complete and finalized design. Rather, its purpose is to get the wheels of the design process moving, to lay a foundation on which greater detail will be built.
In terms of ConsensUs and the JXTA network, every peer will be each device the ConsensUs architecture is deployed on. In many deployments, a single user may be the only user of the peer; however, this is not guaranteed to be true, so a user and peer should not be mapped to each other.
A ConsensUs peer will either be a full-featured edge peer, a rendezvous peer, or a relay peer. The choice is left up to the user or administrator of the peer during the initial configuration of the ConsensUs application. As mentioned in the JXTA overview, most peers will usually be full-featured edge peers, but rendezvous and relay peers will be required for message propagation and routing across network barriers (such as firewalls and NAT devices). A peer may choose to change its type by reconfiguring the ConsensUs application.
It should be noted that at least one rendezvous peer is required for a peer group.
Each peer using ConsensUs will belong to a ConsensUs peer group. These peer groups will provide a context for the communications and services driven by the ConsensUs Suite, and will serve as a logical container for the ConsensUs community. Different ConsensUs peer groups will exist within the JXTA network, each one corresponding to a different subject domain; a peer that participates in one of these subject domains will both possess and provide access to the discourse data for that domain. Because each ConsensUs peer group maps to a given subject domain, a peer may be a member of many ConsensUs peer groups, and will be both a client and server to the information within each. Each peer group will have a peer group advertisement that provides metadata about the group, such as its unique ID, name, description, module spec ID, and a list of services that it provides. Each of these advertisements will be published to the NetPeerGroup for discovery, as well as to the peer group itself.
In a typical use case of a peer already belonging to a peer group and starting up the ConsensUs application, the ConsensUs Suite will initialize the JXTA platform and join the NetPeerGroup. From there, the NetPeerGroup’s discovery service will be used to read in the peer group advertisement of the ConsensUs subject domain to which the peer belongs. Using this advertisement, the ConsensUs Suite will create a local instance of the peer’s ConsensUs peer group and join it using its membership service, after supplying any necessary credentials. The peer will then be able to access the other services provided by the peer group and begin to share discourse data with other peers in the group.
The ConsensUs Suite will provide implementations of all the services required within a ConsensUs peer group. These services utilize the JXTA protocols to allow peers to organize into peer groups and communicate with each other. The JXTA reference implementations of these services should provide all the necessary functionality required of the ConsensUs peer groups, simplifying the task of development; however, custom implementations will allow for greater functionality, control, and optimization.
The Peer Info Service is not mentioned here, because it is not deemed necessary for any operations that may take place in a ConsensUs peer group. The ConsensUs Suite will utilize the membership service, discovery service, and access service to a greater degree than the other services; however, the other services are required, to provide support to these services and any additional functionality.
All of the interfaces and classes mentioned can be found in the Java JXTA API.
The ConsensUs Suite will provide an implementation of the MembershipService interface so that peers may join a ConsensUs peer group. The membership service allows a peer to establish an identity within the peer group by applying to the group, and allows it to join once being authenticated. It also allows peers to resign from the peer group.
When the ConsensUs peer group is instantiated on the peer, the peer is given a temporary identity by the peer group so that it may establish its “true” identity. Using the peer group’s membership service, a peer applies to the group by submitting an initial Credential object that specifies the type of authentication used and the peer’s identity information. The membership service returns an Authenticator object if the type of authentication specified is accepted (in ConsensUs, a username and password challenge), and this object is completed with more information, if necessary (such as an email address, which is how users are invited to join ConsensUs). Then peer joins the group by sending the Authenticator back to the membership service. If the Authenticator object has been completed correctly, the membership service returns a new Credential object to the peer with the peer’s “true” identity in the context of the peer group. It is possible to save this Credential object locally as an XML document so that it may be reused.
To store the usernames and passwords of all valid peer group members, this information can encrypted and stored in the peer group advertisement. The membership service will then need to be able to decrypt the list of username/password combinations to check if a peer’s username and password are valid; it will also need to be able to encrypt the list and modify the peer group advertisement when a new peer joins the peer group.
The ConsensUs Suite will provide an implementation of the DiscoveryService interface so that peers can discover and publish resources in the peer group. The discovery service allows a peer to discover and/or publish other peers, pipes, modules, codats, etc. by finding or creating their advertisements; the ConsensUs implementation will also discover and publish advertisements designed to represent discourse additions, updates, and deletions. These latter types of advertisements will be created by either sub-typing an existing advertisement type, such as the abstract ExtendableAdvertisement class, or by creating them from scratch.
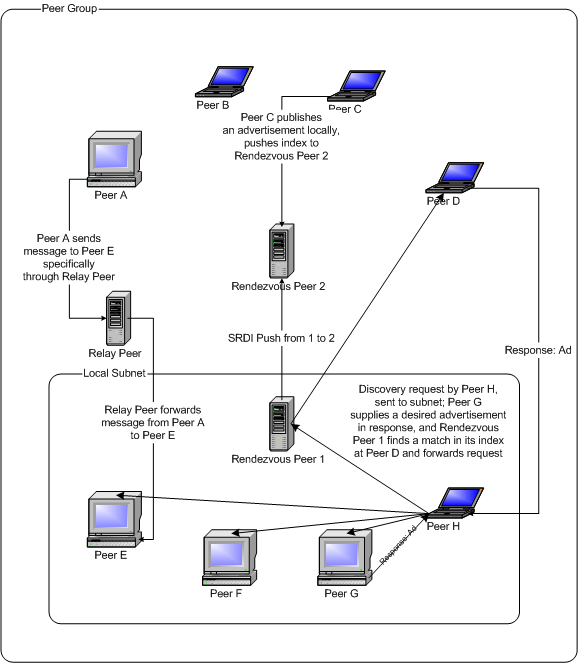
The scope of the discovery service will be the ConsensUs peer group to which the peer belongs. Discovery request messages will specify a name/value pair used to find qualifying advertisements, and will specify a maximum number of advertisements that a single peer can send in response. After receiving responses via the getRemoteAdvertisements() method of the discovery service, the received advertisements may be processed in two ways: they can be cached locally and retrieved via the getLocalAdvertisements method, or they may register the implementing object as a DiscoveryListener and be notified asynchronously of responses. The ConsensUs Suite should use the former method, in order to provide increased redundancy and availability for published advertisements, especially discourse advertisements, so that they have a better chance of being spread to every peer in the peer group. After discourse advertisements are discovered via received DiscoveryResponse messages, the data contained within them is parsed and handed off to the discourse update component of the ConsensUs Suite, in order to update the appropriate local database.
Discovery requests will typically take place when a user chooses to view a discourse object in the UI. These requests will be conducted localany child objects have been added, or to see if any child objects have been updated or deleted. If this operation places too great a load on the peer group (due to the frequency of this action on one peer, spread over all the peers in the group), or impacts the user experience by causing lengthy delays, these requests may take place at some arbitrary time interval. Discovery requests for discourse information will also take place when a user logs in through the UI, so that all of the changes to the subject domain since the peer was last connected will be discovered. Thus, after the user logs in and the peer retrieves all of the updates, the user’s current view of the subject domain should be up-to-date and complete.
As previously mentioned, the ConsensUs peer group’s discovery service will also be used to publish advertisements. Like discovery, publishing is both local and remote. Local publishing adds the published advertisement to the peer’s cache and indexes it; this index is then published to connected rendezvous peers or upon connection to a rendezvous peer, so that rendezvous peers may point other discovering peers in the right direction. Remote publishing does not add the advertisement to the local cache, but attempts to propagate an advertisement using unsolicited DiscoveryResponse messages and the rendezvous service. Generally, the first type of publishing should be used, because propagation of messages is expensive; by pushing an index of the advertisement to a rendezvous peer, the rendezvous peer can share this index with other rendezvous peers it knows about, enabling many edge peers to discover the location of a new advertisement. However, propagating messages to the local network and to peer group members is not expensive, and remote publishing may be used if it propagates advertisements in this way.
The discourse advertisements used by the ConsensUs Suite should be of three types: addition, update, and deletion. Addition advertisements will provide the information of the new discourse object, such as its type, ID, title, abstract, body, time and date of creation, time to live, and any parent discourse objects it has. Update advertisements will contain identifying information for the discourse object – its type and ID – as well as a list of elements that have been changed. Deletion advertisements will only contain the type and ID of the discourse object to be deleted.
The ConsensUs Suite will provide an implementation of the RendezVousService interface to allow peers to connect to, disconnect from, convert back and forth from, and utilize the propagation abilities of rendezvous peers. Using the service, peers can connect to and become subscribers of rendezvous peers, enabling any messages sent to the rendezvous peers to be propagated to the subscribing peers. Rendezvous peers can also send messages to other rendezvous peers, such as their indices of advertisements on edge peers, so that edge peers subscribing to one rendezvous can discover advertisements published by edge peers subscribing to another rendezvous. Other services and protocols, such as the PRP, utilize the rendezvous service to disseminate messages to multiple peers. Propagated messages are handled by specific services that implement the QueryHandler interface, and dictate if the message should be further propagated or instead processed.
The propagate() method of the rendezvous service is very expensive, according to the Java JXTA API, and should not be used frequently. More efficient is the Shared Resource Distributed Index, or SRDI, which is the previously mentioned method of publishing and sharing indices of advertisements on rendezvous peers, allowing searches to take place when necessary instead of a flood of propagated messages. However, the propagateToNeighbors() method, which uses broadcasting or multicasting to propagate the message on the local network, and the propagateInGroup() method, which attempts to propagate the message to as many peer group members as possible, are not expensive. Therefore, the discovery service implemented by the ConsensUs Suite and used in ConsensUs peer groups should use these methods when remote publishing discourse advertisements.
While not commonly used directly, an implementation of the EndpointService interface will be required in the ConsensUs Suite. The endpoint service provides for the sending and receiving of messages between peers, and is used directly or indirectly (through the pipe service) by the other peer group services as a foundation for communication between peers.
The ConsensUs Suite will provide an implementation of the AccessService interface, in order to determine if peers are able to perform certain actions in the context of the peer group. The access service implementation utilizes PrivilegedOperation objects, which tie actions to credentials in order to determine if a peer has the ability to perform the action. In the ConsensUs peer groups, these access checks will take place in a number of situations, whenever a particular action is tied to a specific user level. A few examples:
To check to see if the peer has access privileges to a certain action, the doAccessCheck() method is passed the PrivilegedOperation object and the peer’s Credential object. An instance of AccessResult is returned, which defines if the action is permitted or not.
The ConsensUs Suite will provide an implementation of the ResolverService, which is utilized by the other services to send queries and responses. The resolver service itself does not process the queries or compose responses, but it ensures that the tags of the messages are unique, that messages are sent to the right destination, that rogue messages are dropped, and that the credentials of peers sending the messages are verified. The actual task of processing queries and composing responses is left up to handlers, services that send and receive messages, which the resolver service registers. To match queries to responses, queries are given a unique query ID when they are sent from a peer, and this same query ID is present in any received responses. Here are examples of the query message format and the response message format from the Java JXTA API:
<?xml version="1.0" standalone='yes'?>
<ResolverQuery>
<handlername> name </handlername>
<credentialServiecUri> uri </credentialServiecUri>
<credentialToken> token </credentialToken>
<srcpeerid> srcpeerid </srcpeerid>
<queryid> id </queryid>
<query> query </query>
</ResolverQuery>
<?xml version="1.0" standalone='yes'?>
<ResolverResponse>
<handlername> name </handlername>
<credentialServiecUri> uri </credentialServiecUri>
<credentialToken> token </credentialToken>
<queryid> id </queryid>
<response> response </response>
</ResolverQuery>
The ConsensUs Suite will provide an implementation of the PipeService interface so that peers will be able to exchange messages between their peer group services. Pipes are the fundamental mechanism for sending messages between services, enabling messages like the DiscoveryRequest message to be sent. Pipes correspond to pipe advertisements, which define the type of pipe being used and represent the pipe for the duration of its lifetime in the JXTA network. The pipe service utilizes three different types of pipe: unicast, which is unreliable and not secure; unicast secure; and propagate, which is unreliable and not secure. Other types of pipe exist outside of the pipe service, and may be used independently or within a custom pipe service.
Additional services may be required by ConsensUs peer groups to provide functionality not found in the core services above. Like those services, the implementations of these additional services will be provided and utilized by the ConsensUs Suite, and will be listed in the peer group advertisement.
When new peers join a ConsensUs peer group for the first time, they do not have any discourse information; their local databases are empty. Rather than to try to discover and process every discourse advertisement ever published within the peer group, so that the databases may be populated with an up-to-date view of the subject domain, a bootstrap service may be created, in order to bootstrap the peer’s local databases in a more efficient manner.
Upon instantiating the bootstrap service, the new peer will use it to send a BootstrapQuery message to a remote peer, such as a rendezvous peer. The instance of the bootstrap service running on the remote peer will handle the query and compose a BootstrapResponse message, which contains, among other information, all of the current tables in the remote peer’s pair of databases. The new peer receives the response, and passes the database tables to another portion of the ConsensUs Suite, which injects them into the new peer’s databases. The new peer then has an up-to-date view of the subject domain, and may begin contributing to the discourse.
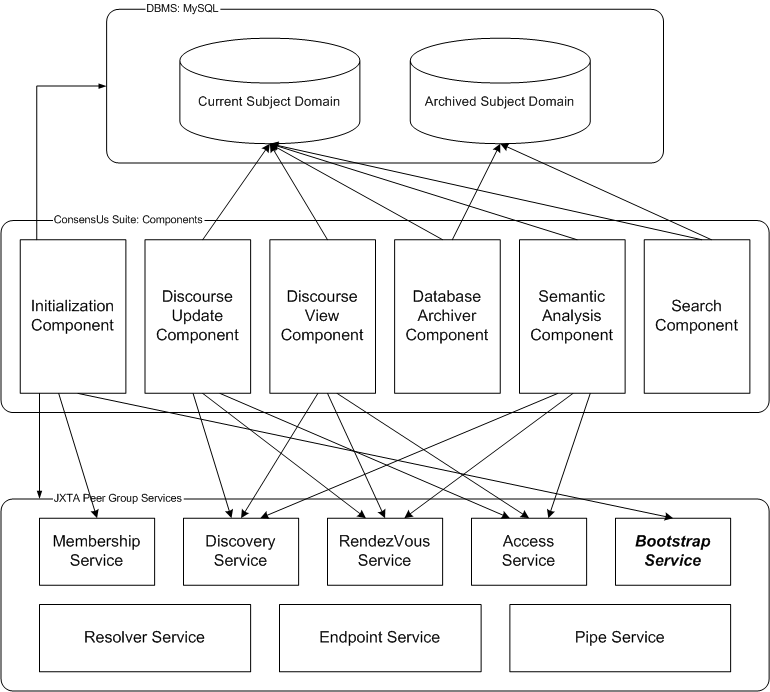
The ConsensUs Suite is the core of the ConsensUs architecture, providing the operations necessary for the peer proxy servlets to gather and store discourse data for the user, and providing the operations necessary to drive the peer’s actions on the JXTA platform. Components of the suite will include an initialization component, a discourse update component, a discourse view component, a database archiver component, a semantic analysis component, and a search component. All of these components will be part of the overarching ConsensUsSuite class, and may be thought of as behaviors of that class.
The initialization component of the class will first be responsible for initializing the JXTA platform and joining the ConsensUs peer group to which the peer belongs. This entails creating or reading in configuration information that has been previously specified through a UI interface, creating and joining the NetPeerGroup, and creating and joining the ConsensUs peer group. If this is the first time the peer has been run, the peer will use the NetPeerGroup’s discovery service to find the peer group advertisement of the group the peer is to join, create an instance of the peer group from the advertisement, and use its membership service to establish an identity and join the group. If it is not the first time, then the peer will read in or discover the advertisement from the local cache instead of discovering it remotely. In any case, the peer will then attempt to connect to one or more rendezvous peers.
Secondly, the initialization component will be responsible for creating the handles used by the other components to access the pair of local databases. This is done using the aforementioned configuration information. Once this is completed, if the peer has just joined a ConsensUs peer group for the first time, then the bootstrap service will be used to bootstrap the databases with the discourse information of the subject domain.
Lastly, the initialization component will be responsible for instantiating the other components, passing them the ConsensUs peer group object and the local database handles as necessary.
The discourse update component will provide the means to update the current local database with new discourse information, and to publish the new discourse information to the ConsensUs peer group. New discourse information can consist of new discourse objects, edits of existing discourse objects, a new voting score for proposals, and deletion of discourse objects. When these events occur, both the local database for the current view of the subject domain and the peer group will be updated with the information. For the peer group, an advertisement corresponding to the type of discourse update will be made, and published both locally and remotely.
The discourse update component will also manage propagated discourse updates originating on other peers, requests for discourse information from other peers, and discovery of new discourse advertisements. These situations will be satisfied asynchronously through a DiscoveryListener, which listens for DiscoveryEvents. If the message contained within the DiscoveryEvent contains a discourse update, the information will be taken from the event, parsed, and incorporated into the local database in which it belongs; if the message is a discovery request, the requested discourse advertisement will be supplied and sent in response. In the latter situation, a discovery request will be made by searching for new discourse advertisements at either some fixed time interval or when a discourse object is viewed through the discourse view component, and any discovery responses will be handled asynchronously by the DiscoveryListener.
The discourse view component will be responsible for supplying discourse information for the peer proxy servlets to display. If the discourse update component does not poll the peer group for discourse advertisements at a fixed time interval, then the discourse view component will use the discourse update component to poll the peer group for new discourse advertisements before any information is returned to the servlets. In this case, the new discourse advertisements will have their information incorporated into the local database; then the desired discourse information to be displayed will be gathered from the database and passed to the servlets.
The database archiver component will run as a thread that periodically checks the local database of the current subject domain for discourse objects that have expired. Any expired discourse objects are then moved to the archived subject domain database meant to solely hold expired objects.
The semantic analysis component will run as a thread that periodically checks clusters of comment objects belonging to each topic object to see if a consensus is emerging within the topic or a group of topics. See Section 1.4 for more information. This component may change in its design, but the description below is a possibility of how it may function.
If the semantic analysis component finds a semantic center to the cluster of comments, the topic or groups of topics will be flagged as having a semantic center, and the list of qualifying comments gathered. This information will then be published as a special type of advertisement with the discourse update component, a pending semantic center advertisement, and spread throughout the network. When a CM discovers this advertisement and the discourse update component integrates its information into the local database for the current subject domain, the peer proxy servlets will present a visible marker/link when the topic or topics are viewed by the CM. The CM will then be able to click this link, and the discourse view component will display the cluster of comments that represent the semantic center, as well as a form to create a summary comment. This summary will added to the CM’s database and published via the discourse update component as a resolved semantic center advertisement. Other ConsensUs users will see the summary comment after discovering and processing the advertisement, and viewing the topic or groups of topics.
The search component will allow a user to search over a number of different parameters for discourse information stored in the pair of databases for the subject domain. Discourse objects that match the search parameters will be passed to the servlets for display. This includes both archived objects and current objects, since both databases are searched. See Section 1.6 for more information.
This project will need a wide array of researchers, architects, developers and even CS-type talents such as linguistics, psychology, sociology and others! We plan to continue the current architecture and functional specification development as a collaborative project using some current Web-based approach. When it is time to start development we plan to start an open source process to develop the code.
We plan to prototype much of the functionality of ConsensUs using existing Web (client-server) technology. This prototype will not have all of the features of the system as described here. However, we will be able to test much of the key functionality, namely the consensus generating features of voting, promoting time to live, and semantic analysis of comments.
Our plan is to provide a test bed service to an as yet unidentified virtual community and monitor their pattern of uses and results. This exploratory research will be followed by determining improvements and another round of testing. This phase will not preclude development of the JXTA-based version.
We will be recruiting individuals who are well grounded in Web technology to participate in this phase.
Semantic analysis is still very much a
research area. Latent Semantic Analysis (LSA) appears to have
many of the properties we would like to have for the process of
analysis and consensus-finding that was described above.
See: An Introduction to Latent Semantic Analysis, Landauer, Foltz & Laham.
In this sub-project we will be
looking for a graduate student who is interested in exploring the
possibilities for LSA (or some variant) for a capstone project.
The objective is to develop a semantic analysis algorithm that finds
clustering of comments where the density of the cluster meets some
threshold value, indicating that there is a high level of
agreement. It includes finding the "centroid" of such a cluster
and the comment that comes closest to that centroid. This comment
will be used to represent the cluster as a whole - a kind of canonical
comment - that can be used to encapsulate all of the other comments in
the cluster. We will investigate various metrics and fringe
conditions to determine if this approach will provide a reasonable
representation of the body of commentary.
If you are interested in pursuing this research area, please contact
George Mobus at: gmobus@u.washington.edu. Also see
SemanticAnalysisResearch to see what is going on in this project.
For an example of the ConsensUs system applied to a Global Issues Network, in this case one devoted to the problem of global warming, see Global Warming GIN.
Please note that this example only shows some of the page layouts for Topic/Sub-topic, Issue and Comment pages. The "Add" buttons are shown but do not invoke actual pages for entering those objects yet. Provided in this example are:
As of this version of the example, no Proposal page has been developed.This site conforms to the following standards: