| | ||||||
| Deoxyribonucleic acid (DNA) Author: Robert Stewart, Ph.D. Theory |
| Nucleotides The fundamental chemical building block of deoxyribonucleic acid (DNA) is the nucleotide. A nucleotide consists of three parts:
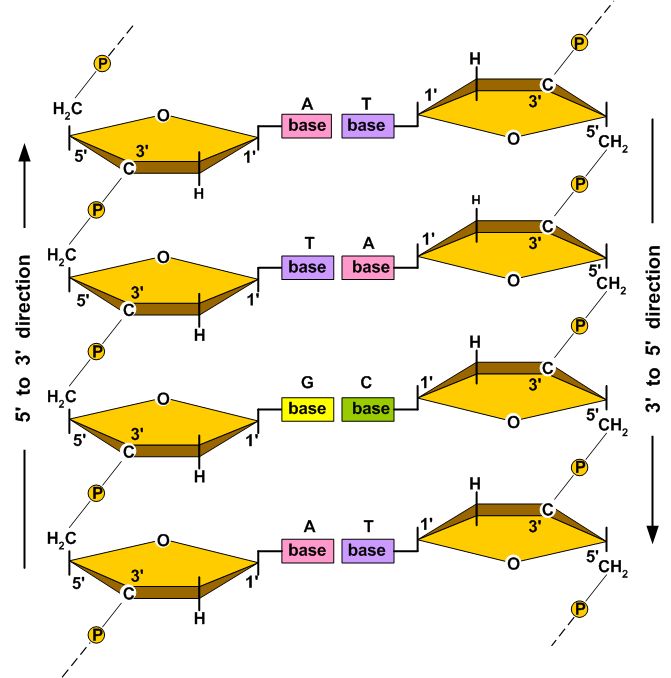
Each deoxyribose sugar unit contains five carbon atoms joined in a ring structure with an oxygen atom. The carbon atoms of the deoxyribose sugar are designated by numbering them sequentially from one to five. The first carbon atom, the 1´ carbon, is by definition the carbon atom covalently attached to one of four organic bases: guanine (G), adenine (A), thymine (T), or cytosine (C). Adenine and guanine are purines, and cytosine and thymine are pyrimidines. Phosphate groups are attached to the third (3´) and fifth (5´) carbon atoms. In DNA, the term nucleotide refers to the complete assemblage of a nitrogenous base (A, G, C, or T), a five-carbon deoxyribose sugar, and a phosphate group. Structure The diameter of the DNA helix is 2 nm and the vertical rise per base pair is 0.34 nm (Van Holde 1989). A DNA molecule is composed of two unbranched polynucleotide chains (strands) that wind about each other into a structure called a double helix, as illustrated in Figure 1. | |||||||||||||||||||||||||||||||||||||||||||||||||
|
Figure 1. Idealized schematic of the DNA double helix (courtesy Dr. R. K. Ratnayake 2004). Click on image to enlarge. | ||||||||||||||||||||||||||||||||||||||||||||||||
Other DNA conformations use the same nucleotides and molecular bonds, but the three-dimensional structure of the helix is different. At least six different DNA conformations (designated A, B, C, D, E, and Z) have been identified, but only the A, Z, and B conformations are found in nature (Wolfe 1993). B-DNA is the most common form of DNA found in living organisms. The average diameter of B-DNA is about 2.0 nm. Other DNA conformations have diameters that range from about 1.8 to 2.3 nm (Wolfe 1993). The average distance between adjacent nucleotides in the same strand of DNA (the vertical rise) is between 0.321 to 0.337 nm (Wolfe 1993). The B-DNA helix makes one full revolution approximately every 10.1 to 10.6 nucleotides (Wolfe 1993). The hydrogen bonding between complementary base pairs is such that the most energetically stable DNA configuration is achieved when adenine pairs with thymine and guanine pairs with cytosine. Thus although the spatial requirements of B-DNA potentially allow four complementary base pairs to be formed (i.e., G-T, G-C, A-T, and A-C), only the G-C and A-T base pairs are normally found in DNA. Three hydrogen bonds stabilize G-C base pairs and two hydrogen bonds stabilize A-T base pairs. Because hydrogen bonding between base pairs contributes to the stability of the DNA double helix, base sequence affects the stability of DNA. Namely, regions of the DNA with an abundance in G-C base pairs are more stable than A-T rich regions of the DNA. In some prokaryotes, the greater mechanical stability offered by G-C rich sequences make it possible for them to exist near thermal springs too hot for most terrestrial organisms. Composition and Mass The average mass of a base pair in DNA (see Table 1) is about 615 dalton (Da); a dalton (Da), named in honor of the British chemist John Dalton (1766 - 1844), is equivalent to 1/12 the mass of the 12C which equals 1.66053886E-27 kg (CODATA 2002), i.e., 1 Da = 1 atomic mass unit (amu). A useful mass-to-bp conversion factor is 979.91 Mbp/pg. In cells, the organic bases used in DNA are sometimes modified by the addition or alteration of chemical groups. One of the most common alterations is methylation of the 5´ carbon atom of cytosine. For example, Wolfe (1993) states that 2 to 8% of the 5´ cytosine carbon atoms are methylated in vertebrates. However in human DNA, this amount of methylation changes the average mass of a base pair by less than 0.07%. Table 2 lists the DNA content of several representative prokaryotes and eukaryotes (for a more complete list, see http://www.genomesize.com/). Table 1. The average mass of DNA and nucleotide sub-units as they appear in DNA (Useful conversion factor: 979.91 Mbp = 1 pg; see also Dolezel et al. 2003).
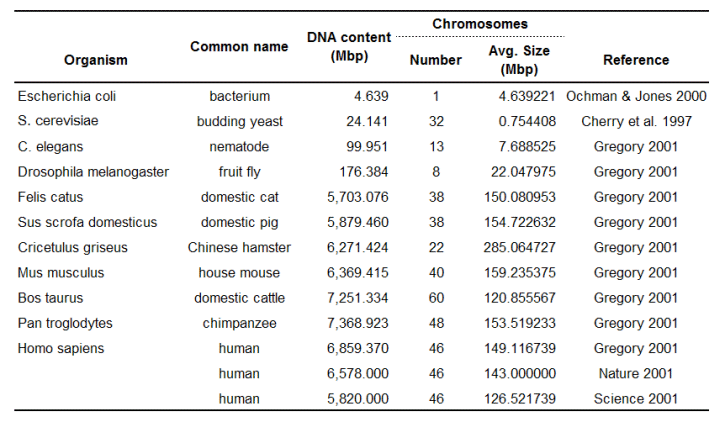
Table 2. DNA content and chromosome size for selected diploid cells (except E. coli which has one large circular chromosome). References
| |||||||||||||||||||||||||||||||||||||||||||||||||
| School of Health Sciences Purdue University Disclaimer | Last updated: 10 June, 2011 |