Seeking information
I had a lot of questions when I was a child. Driving around Portland, Oregon, I would point to signs and objects and pose endless queries: “what is that?”, “who is that?”, “ why is that?” Nothing was mundane enough—I wanted to know it all. And when I started to read, I wanted to know the meaning of every word. I remember one particular night when I’d brought home a book from my 1st grade class about rabbits. I read it late at night in my bed, sounding out each word under my breath. I got to a sentence that had the word “laughing” and got stuck. I walked up to my parents’ bedroom, tip toed to their bed, and tapped my sleeping mother’s shoulder, and whispered, “ what is log...hing? ”, trying to pronounce this tricky English word.
My queries, of course, became more sophisticated. In high school, I remember encountering some of the web’s first commercial search engines, including Infoseek , Yahoo , WebCrawler , Lycos , Excite , AltaVista , AskJeeves , and eventually Google , mesmerized how, just like my parents, they would answer any question. Just like my parents, sometimes the answer was “I don’t know”, and quite frequently, the answers I got seemed like they were wrong, or just someone’s inexpert opinion. But unlike my parents, and unlike the library and its encyclopedias, these search engines could connect me with content about anything, and do it privately. Unfortunately, too few transgender people were out on the web for me to find many answers about my gender. It would take another decade before the communities and content I needed to make sense of my gender were online, discoverable, and something I felt safe querying.
Whether it’s a child’s simple questions of parents or life changing query about identity, our human desire for information means we are constantly seeking it. This activity, which we often describe as information behaviorinformation behavior: How people go about creating, finding, and interpreting information. 3 , involves people seeking, managing, sharing, and using information across all possible contexts. And, of course, our desire for information is everything we have discussed in this book so far: it’s why we create information systems, why we create technology to support those systems, why we encode data and metadata, why we create information, and why information has any power and peril. In this chapter, we’ll discuss how we seek it, and the narrow role of modern web search engines in answering our questions.

The many facets of information seeking
At a superficial level, it might seem like information seeking is as simple as questions and answers. And that’s a reasonable simplification of something all people do: we often first become aware that we want to know something when we have a question, and it often seems like the need is met once we have the answer. However, information seeking is a complex process, full of subtle, sometimes subconscious processes, all of which influence what we seek and what we do with what we seek.
Consider first the many things that come before a question. There is the contextcontext: Social, situational information that shapes the meaning of information being received. that we have for some information need, which includes our prior knowledge, the people around us, the factors governing our motivation, and our values and beliefs. For example, you might never seek to know the origin of the Czech pastry trdelnik until you visit Prague and see everyone eating them. And I didn’t want to know how to pronounce the word “laughing” until I encountered it in the middle of a very cute story about a bunny. Nobel Laureate Herb Simon described the importance of context in shaping our behavior with a parable of an ant on a beach:
We watch an ant make his laborious way across a wind- and wave-molded beach. He moves ahead, angles to the right to ease his club up a steep dunelet, detours around a pebble, stops for a moment to exchange information with a compatriot... Viewed as a geometric figure, the ant’s path is irregular, complex, hard to describe. But its complexity is really a complexity in the surface of the beach, not a complexity in the ant... An ant, viewed as a behaving system, is quite simple. The apparent complexity of its behaviour over time is largely a reflection of the complexity of the environment in which it finds itself.
Simon would therefore argue that information seeking, as with context in any behavior, is at least partly shaped by our environment.
Of course, context alone isn’t the only factor that shapes someones information needs. There are other factors, such as one’s psychological , sociocultural , motivational , and cognitive factors, which shape how much someone wants some information and what they might be willing to do to find it 13 . For example, imagine becoming curious about your family history. Some people, after reflecting on the work it might take to uncover that history by talking to family and consulting official records, might decide that they aren’t interested enough, or aren’t confident enough in their ability to unearth the truth. Others with a great curiosity, a confidence in their research skills, and some free time, might happily begin their search. Therefore, matters of perceived risk and reward, self-efficacy of information seeking skills, and motivation might all interact to shape whether one searches.

Another factor is how one conceives of a question. For example, I know now that if I want information about gender affirming health care, I can use concepts and phrases like “gender”, “transgender”, and “gender identity”, and I will be likely to find information of high relevance with web search. But back in the 1990’s, I had no idea what words to use; the closest concept I knew was “gay”, because many people had used it against me as an insult, and so I searched the web with the query “ am I gay? ” That didn’t answer my question about gender because I was asking the wrong question. This is an example of prior knowledge shaping the questions we ask: when we lack it, we may not know what to ask, leading to ineffective queries and unhelpful answers. It often takes someone else with expertise, such as a teacher or librarian, to help us find well-formed questions that are consistent with the information resources in a system, not only in terminology, but also in concept.
Of course, only once we have a question do we begin to engage in an iterative process information seeking. This process is usually called sensemakingsensemaking: The human process of gathering, interpreting, and synthesizing information into knowledge. 9 , because it involves not only gathering information, but making sense of it, integrating it into our understanding, and using that new understanding to shape further information seeking. Consider, for example, a scenario in which a college student registering for classes identifies needs to know what to take to help them maximize their chances of graduating on time. They might message a friend in the same major for advice, and get an unhelpful answer, and then just pick some things that seem interesting. But in that brief interaction, there was actually a lot going on:
- They identified a need (determine what to register for to minimize time to graduation).
- They chose an information source (their friend, likely because they were the easiest to reach and most likely to help quickly).
- They expressed that need (“What should I take next?”, which doesn’t perfectly express their need).
- The information system—their friend and the messaging system— retrieved an answer (“Not sure, ask the advisors.”, indicating that either the source didn’t want to help or didn’t have the answer.)
- Evaluate the answer received (“That wasn’t helpful, I don’t have time to meet with them”)
- Sensemake (“I don’t really know what to take and it seems hard to find out.”)
Throughout this process, information seeking is influenced by all of the other factors: needs might change, the costs and risks of accessing various sources might change, expressions of needs can be imprecise or use ineffective terminology, the information system used might not have the answer, or might have an unhelpful or incorrect answer, the student might evaluate the answer wrong, or they might struggle to make sense of the answers they are finding.
Herb Simon, once again, provides a helpful explanation for these challenges: satisficingsatisficing: Human tendency to seek as little information as is necessary to decide, bounding rationality. 11,12 . This is our tendency to only consider so much information, and only consider it so carefully, when trying to make decisions. Simon viewed human beings as information processors, taking in information from the world and using it to problem solve and decide. Simon observed that because there is so much information to consider, we need some strategy to filter, to prevent us from getting paralyzed. Satisficing is how we do that, considering what we have learned until we meet some subjectively acceptable threshold of confidence or understanding. It’s why when we do a Google search, we might only look at the first few results, rather than considering all of them, before deciding that one of the sources is “good enough” to answer our question.

Another idea that explains this seemingly lazy behavior in information seeking is information foraginginformation foraging: The observation that humans rely on metadata cues in information environments to drive searching and browsing. theory 8 . In this theory, people are imagined to forage for information like we do for food: we use information to learn where food (information) might be found; we use information to determine the best way to find food (information); we consider how much energy it might take to get that food (information); and we consider how much energy that food (information) might provide. This theory has been used to explain how we browse websites to find the information we want, using labels on links and headers to help us estimate the likelihood of finding what we need. When those words are accurate predictors of where information is, we might learn to trust a source more.
What these various ideas about information seeking reveal is that finding and making sense of information is about far more than just questions and answers: it is about who we are, what we want, what we know, the information systems we have in our worlds, how our brains conserve our attention, and how these many factors end up shaping the information that we seek and obtain.
Search engines
How do search enginessearch engine: Software that translates queries into a collection of documents related to a query. like Google fit in to all of this? In essence, search engines are software that take, as input, some query, and return as output some ranked list of resources. Within the context of information seeking, they feel like they play a prominent role in our lives, when in actuality, they only play a small role: the retrieval part of the sensemaking steps above. To reinforce that, here is the list again, and how search engines fail to help:
- Search engines don’t help us identify what we need—that’s up to us; search engines don’t question what we ask for, though they do recommend queries that use similar words.
- Search engines don’t help us choose a source—though they are themselves a source, and a heavily marketed one, so we are certainly compelled to choose search engines over other sources, even when other sources might have better information.
- Search engines don’t help us express our query accurately or precisely—though they will help with minor spelling corrections.
- Search engines do help retrieve information—this is the primary part that they automate.
- Search engines don’t help us evaluate the answers we retrieve—it’s up to us to decide whether the results are relevant, credible, true; Google doesn’t view those as their responsibility.
- Search engines don’t help us sensemake—we have to use our minds to integrate what we’ve found into our knowledge.
While search engines are quite poor at helping with these many critical aspects of information seeking, they are really quite good at retrieving information. Let’s consider how they work, considering web search engines in particular.
The first aspect of web search to understand is that the contents of the web are constantly changing. Therefore, the first and most critical part of a search engine is its web crawlercrawler: Software that navigates interlinked data collections to discover and index new documents. 4 . This component attempts to read the contents of every public web page on the internet as frequently as possible, so that it can keep an up to date record of its contents to support retrieval. Early web crawlers did this quite slowly because they only used one or two computers to do it; modern web crawlers maintained by Google use orders of magnitude more computers to crawl billions of pages. Crawlers also have to discover new pages, and they do this by following links in HTML, building a model of all of the pages on the web and how they link to each other. All of this is similar to what a human does when they browse the internet, starting from one page, and following links—computers just do it fast, do it systematically, and record immense amounts of information about what they find.
For each page that a web crawler finds, it must parseparse: Algorithms for translating encoded data into representations suitable for analysis. the page, reading its HTML, finding all of the words and links in the document, and in the case of modern search engines, likely parsing the natural language text of a page to obtain its syntactic structure 1 . This parsing allows the web crawler to segment the text into words, parts of speech, and other linguistic features, which can be used to predict what the page is about. At this stage, the crawler might also identify images, videos, and other embedded content.
From this parsing, the search engine creates an indexindex: A data structure that organizes documents by one or more facets of their contents or metadata. 2 . Much like an index at the end of a print book, which shows all of the significant words in the book and which pages they occur on, a web search index does the same, mapping key words and phrases from web pages to the specific URLs of web pages on which they occur. The index is the key part of mapping a user query on to a document, as it is the central mapping between ideas on a page to the page themselves.
After building an index, there must be some way of mapping a user’s query onto the subset of documents that match that query. The simplest approach is of course to search for the pages in the index that contain those words. For example, if a user searched for cat videos , it could use the index to retrieve all of the documents containing cat and, separately, all of the documents containing videos , then find the intersection of these two document sets, and return them in a list. This, of course wouldn’t be a very helpful list, because it would probably contain hundreds of millions of web pages, and it’s very unlikely that anyone would read them all. Therefore, search engines have to do something more helpful; that’s where rankingranking: Ordering documents in a collection by relevance. comes in.
Early ways of ranking computed the “importance” of different words and phrases in a document. For example, one measure called TFIDF , which stands for term frequency, inverse document frequency . Term frequency refers to how frequently a word occurs in a document; document frequency refers to the prevalence of the word in a set of documents. The inverse refers to the ratio between the two: the more frequent a word is in a document and the more rare it is across all documents, the more meaningful it might be. For example, if cat appeared a lot on a page, but didn’t occur on many pages overall, it might be an “important” word, and therefore should receive a higher TFIDF score. In contrast, the word the , even if it appears on a page many times, occurs on likely every English page, and so its score would likely be near zero. Finally, comparing the importance of the words in a query to the importance of the words in the documents using a cosign similarity of two vectors of all of the words in the query and pages produced a measure of importance and similarity, providing a helpful way to sort search results.
Another way to rank pages—and the one that made Google Search succeed over its dozens of competitors in the late 1990’s—was PageRank (a pun, cutely named after Larry Page, while also referring to web pages ). This algorithm, inspired by bibliometrics used by information scientists to identify impactful research publications and scientists, computed a measure of relevance based on the number of pages that link to a page. Conceptually, this was a measure of a page’s popularity. Using this measure to rank pages produced more popular results than TFIDF, which many users perceived as more relevant. Because Google Search is proprietary, we do not know if it still uses PageRank, but we do know that search ranking has advanced considerably with natural language processing 5 , knowledge graphs for question answering 6 .
Of course, all of the ideas above only work if this process is really fast. Modern web search relies on massive numbers of computers, constantly crawling, parsing, indexing, and pre-computing the answers to queries, and storing those answers redundantly across dozens of data centers worldwide. Without all of this optimization, a Google search would take minutes, if not days, instead of the less than 100 milliseconds that most searches take. What makes all of this possible is scale: most queries have been asked before, and so with enough users, it’s possible to know, in advance, most of the queries that one might encounter, and answer them in advance. Therefore, when you type a query into Google, it’s not answering your question in real time, it’s merely retrieving a ranked list of results already computed.
Of course, knowing all of the above, one thing should become obvious: search engines don’t really know anything. All they are really doing is retrieving content from the web that matches the words in a query. They do not know if content is biased, correct, harmful, or illegal. And in fact, because search engine ranking algorithms themselves have their own biased ideas about what “relevant” means, they can introduce bias of their own, surfacing results that perpetuate harmful stereotypes or erase the existence of important resources 7 . For example, it is “popular” to only hire older white cis men as CEOs, and so searching for images of CEOs returns results of white cis men. Popular, in this example, is simply a proxy for sexist.
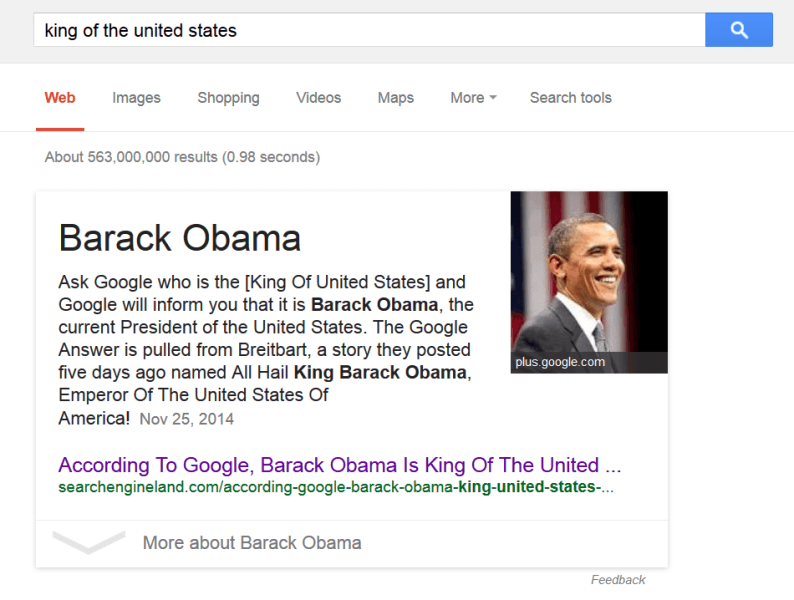
It’s easy to be impressed by the scientific and engineering feats that have produced web search engines. They are, unquestionably, one of the most impactful and disruptive information technologies of our time. However, it’s critical to remember their many limitations: they do not help help us know what we want to know; they do not help us choose the right words to find it; they do not help us know if what we’ve found is relevant or true; and they do not help us make sense of it. All they do is quickly retrieve what other people on the internet have shared. While this is a great feat, all of the content on the internet is far from everything we know, and quite often a poor substitute for expertise. But we are satisficers, and so this often seems good enough. But our desire for speed and ambience to truth has consequences, as we have seen.
Podcast
Learn more about information seeking and search:
- Who We Are At 2 a.m., Hidden Brain, NPR . Discusses the role of search engines in creating private spaces for learning.
- Bias and Perception, TED Radio Hour, NPR . Discusses bias, perception, and how search engines can perpetuate them.
- The Force of Google, Seriously, BBC . Discusses Google as a monopoly and the secrecy of the Google Search algorithm.
- Meet the Man Who Wants You to Give Up Google, Sway . Discusses how ad-supported search engines bias search results and the various tradeoffs of subscription-based alternatives.
References
-
Steven Bird, Ewan Klein, Edward Loper (2009). Natural Language Processing with Python. O'Reilly Media.
-
Sergey Brin, Lawrence Page (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems.
-
Karen E. Fisher, Sanda Erdelez, and Lynne E.F. McKechnie, Sanda Erdelez (2005). Theories of information behavior. ASIST.
-
Allan Heydon, Marc Najork (1999). Mercator: A scalable, extensible web crawler. World Wide Web.
-
Julia Hirschberg, Christopher Manning (2015). Advances in natural language processing. Science.
-
Maximilian Nickel, Kevin Murphy, Volker Tresp, Evgeniy Gabrilovich (2016). A Review of Relational Machine Learning for Knowledge Graphs. Proceedings of the IEEE.
-
Safiya Noble (2018). Algorithms of oppression: How search engines reinforce racism. NYU Press.
-
Peter Pirolli (2007). Information foraging theory: Adaptive interaction with information. Oxford University Press.
-
Daniel Russell, Mark J. Stefik, Peter Pirolli, Stuard K. Card (1993). The cost structure of sensemaking. ACM Conference on Human Factors in Computing Systems.
-
Herbert A. Simon (1963). The Sciences of the Artificial. MIT Press.
-
Herbert A. Simon (1972). Theories of bounded rationality. Decision and Organization.
-
Herb A. Simon (1978). Information-processing theory of human problem solving. Handbook of learning and cognitive processes.
-
Tom D. Wilson (1997). Information behaviour: an interdisciplinary perspective. Information Processing & Management.