|
High Performance Scientific Computing
AMath 483/583 Class Notes Spring Quarter, 2011 |
|
|
High Performance Scientific Computing
AMath 483/583 Class Notes Spring Quarter, 2011 |
All the codes on this page can be found in the directory $CLASSHG/codes/particles/ (see Instructions for cloning the class repository for information on obtaining the class repository).
For Fortran versions of these codes, see Rotating particles and Fortran efficiency.
For more about the timings reported here and the computer used, see Timing and profiling computer codes. The main point of the example on this page is to show how implementing a Python code using a few basic principles can speed it up by a factor of 2000 relative to a first attempt. These principles apply equally well to Matlab codes (see Numerics in Python for more about Python vs. Matlab for numerical calculations).
For a general introduction to Python, see Python.
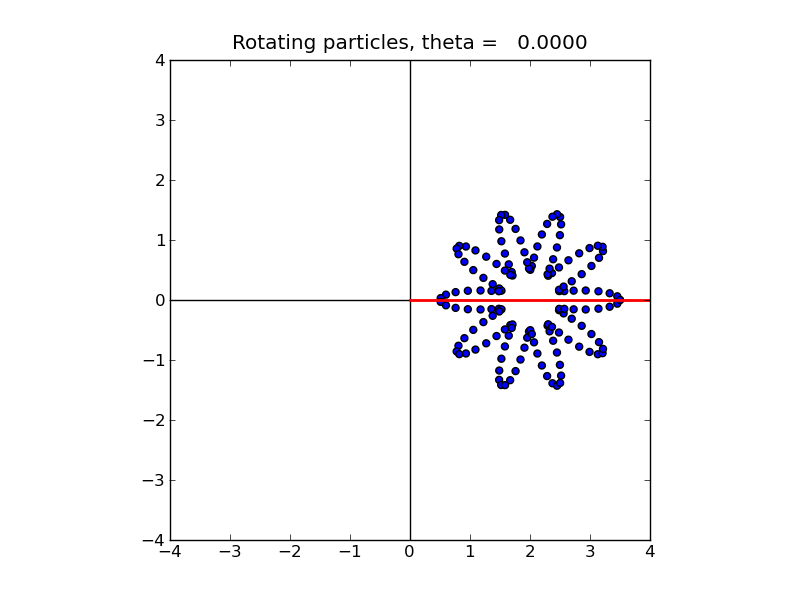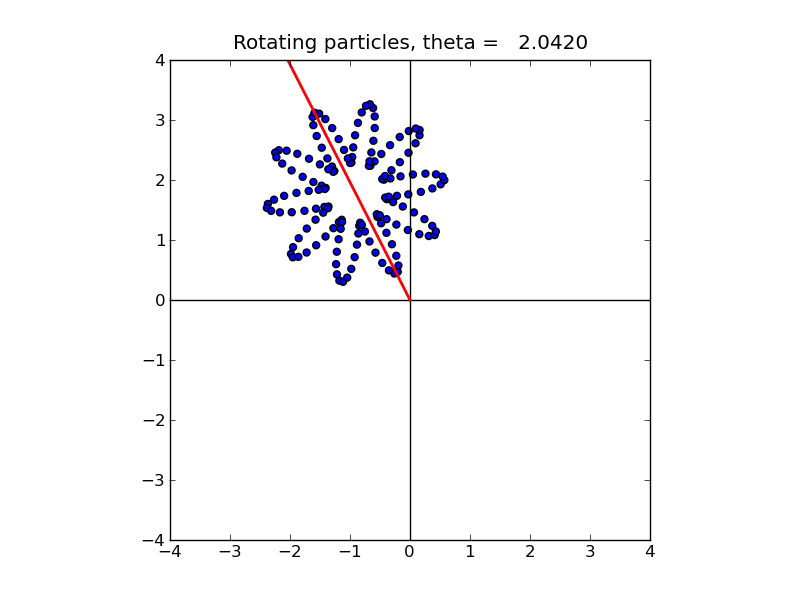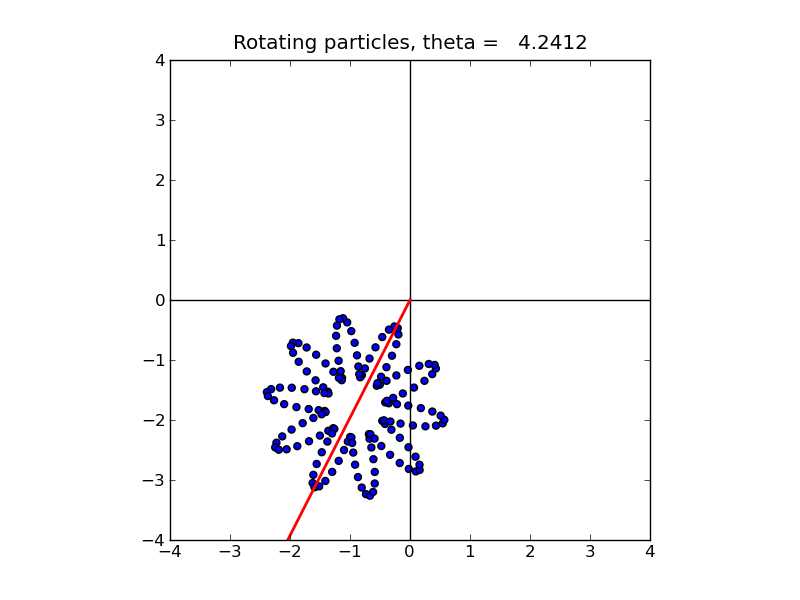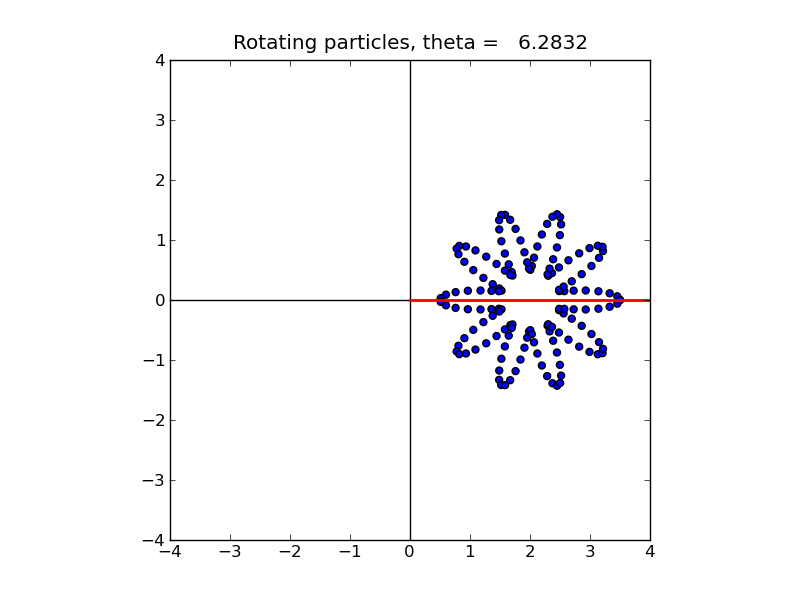
These examples solve the simple problem described in Section Particle methods.
Below is a Python program that computes the rotating particles and plots them at a number of revolution angles. Note that this program is not written at all efficiently, in fact it was designed to be nearly as bad as possible for what it does (though it could be made even worse, see Allocating memory in Python).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # $CLASSHG/codes/particles/rotate1.py
from numpy import *
from rotate_plotter import plot_particles
import time
tstart_cpu = time.clock() # start the CPU timer
N = 150 # number of particles
nsteps = 40 # number of rotation steps
dtheta = 2.*pi / nsteps # change in theta between steps
x = zeros(N) # array for x
y = zeros(N) # array for y
print "Rotating %s particles through %s theta values" % (N, nsteps)
for n in range(nsteps+1):
theta = n*dtheta
for j in range(N):
alpha = 2*pi*j / N
r = 1. + 0.5*cos(10*alpha)
x1 = 2. + r*cos(alpha)
y1 = r*sin(alpha)
x[j] = cos(theta)*x1 - sin(theta)*y1
y[j] = sin(theta)*x1 + cos(theta)*y1
plot_particles(x,y,theta)
t_cpu = time.clock() - tstart_cpu
print "CPU time: %12.8f seconds" % t_cpu
|
The file $CLASSHG/codes/particles/rotate_plotter.py is not included here but can be viewed here and is available in the repository. (See matplotlib and pylab for more about plotting.)
Running this code at the command line gives:
$ python rotate1.py
Rotating 150 particles through 40 theta values
CPU time: 7.27665200 seconds
It should also produce a sequence of figures similar to this animation.
The output above shows that running this code took 7.2 seconds of CPU time. You should be shocked at how long this took.
This is partly because plotting takes a lot of CPU time. This is an important issue in itself for scientific computing, see Visualization and graphics.
For now we do not want to be confused by this so let’s make a version of the code that leaves out the plotting and just computes the locations of the particles for each value of theta.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | # $CLASSHG/codes/particles/rotate2.py
from numpy import *
import time
tstart_cpu = time.clock() # start the CPU timer
N = 150 # number of particles
nsteps = 40 # number of rotation steps
dtheta = 2.*pi / nsteps # change in theta between steps
x = zeros(N) # array for x
y = zeros(N) # array for y
print "Rotating %s particles through %s theta values" % (N, nsteps)
for n in range(nsteps+1):
theta = n*dtheta
for j in range(N):
alpha = 2*pi*j / N
r = 1. + 0.5*cos(10*alpha)
x1 = 2. + r*cos(alpha)
y1 = r*sin(alpha)
x[j] = cos(theta)*x1 - sin(theta)*y1
y[j] = sin(theta)*x1 + cos(theta)*y1
t_cpu = time.clock() - tstart_cpu
print "CPU time: %12.8f seconds" % t_cpu
|
This takes much less time than the previous version:
$ python rotate2.py
Rotating 150 particles through 40 theta values
CPU time: 0.26613700 seconds
Note that this is much quicker, but is still painfully slow. All we are doing is computing 6000 particle locations on a machine that in priciple is capable of doing a few hundred million floating point operations per second (see Timing and profiling computer codes).
There are several major things wrong with this program. We will make some improvements by examing each in turn.
One problem with the code above is that the trigonometric functions cos and sin are being evaluated over and over again with the same arguments in the loops. Evaluating these functions takes longer than doing a single multiply or add and it is much better to evaluate the required values once and reuse them as needed.
Here is an improved version of the code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # $CLASSHG/codes/particles/rotate3.py
from numpy import *
import time
tstart_cpu = time.clock() # start the CPU timer
N = 150 # number of particles
nsteps = 40 # number of rotation steps
dtheta = 2.*pi / nsteps # change in theta between steps
x = zeros(N) # array for x
y = zeros(N) # array for y
print "Rotating %s particles through %s theta values" % (N, nsteps)
alpha = linspace(0., 2*pi, N) # vector of all the alpha values
r = 1. + 0.5*cos(10*alpha) # vector with radius for each alpha
x1 = 2. + r*cos(alpha) # vector of x unrotated
y1 = r*sin(alpha) # vector of y unrotated
for n in range(nsteps+1):
theta = n*dtheta
costh = cos(theta)
sinth = sin(theta)
for j in range(N):
x[j] = costh*x1[j] - sinth*y1[j]
y[j] = sinth*x1[j] + costh*y1[j]
t_cpu = time.clock() - tstart_cpu
print "CPU time: %12.8f seconds" % t_cpu
|
This cuts the time down by a factor of 10 or so:
$ python rotate3.py
Rotating 150 particles through 40 theta values
CPU time: 0.03809200 seconds
This may seem pretty good, but note that this is for only 150 particles. Real applications often involve millions of particles. If we scaled this up to 150,000 particles we’d expect it to take at least 100 times longer, as in fact we see if we modify N in rotate3.py:
$ python rotate3.py # after modifying N
Rotating 150000 particles through 40 theta values
CPU time: 35.73830700 seconds
The major problem with the code above is that the inner loop on j, where we loop over all the particles, is written as a loop. Loops should be avoided whenever possible with interpreted languages like Python or Matlab. Instead, it is much better to use vectorized operations that are applied to the vectors x and y rather than to individual elements.
An improved version takes the form:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | # $CLASSHG/codes/particles/rotate4.py
from numpy import *
from rotate_plotter import plot_particles
import time
tstart_cpu = time.clock() # start the CPU timer
N = 150000 # number of particles
nsteps = 40 # number of rotation steps
dtheta = 2.*pi / nsteps # change in theta between steps
print "Rotating %s particles through %s theta values" % (N, nsteps)
alpha = linspace(0., 2*pi, N) # vector of all the alpha values
r = 1. + 0.5*cos(10*alpha) # vector with radius for each alpha
x1 = 2. + r*cos(alpha) # vector of x unrotated
y1 = r*sin(alpha) # vector of y unrotated
for n in range(nsteps+1):
theta = n*dtheta
costh = cos(theta)
sinth = sin(theta)
x = costh*x1 - sinth*y1
y = sinth*x1 + costh*y1
t_cpu = time.clock() - tstart_cpu
print "CPU time: %12.8f seconds" % t_cpu
|
Note that we have kept N = 150000 here. Even so, this code executes in under 1 second:
$ python rotate4.py
Rotating 150000 particles through 40 theta values
CPU time: 0.27013900 seconds
One might also be able to replace the loop on theta values by vectorized operations to compute all the locations at all times, but if one wants to add back in the plotting or other operations to be done for each value of theta, this may not be advantageous.
It is possible to improve this even further, however, by applying a bit of linear algebra. The location of a single particle at each theta can be computed by taking its location (x,y) at the previous value of theta, when viewed as a 2-vector, and multiplying by a rotation matrix of the form
R = \left[\begin{array}{cc}\cos(\Delta\theta) & -\sin(\Delta\theta) \\ \sin(\Delta\theta) & \cos(\Delta\theta) \end{array}\right].
where \Delta\theta is the change in rotation angle, which is called dtheta in the code.
We do not want to loop over all particles doing this, however, or we will be back to a very slow code because of the loop. Instead, notice if that we define a 2\times N matrix B whose first row consists of the x vector and whose second row is the y vector (so that the j’th column is the location vector for the j’th particle), then we can update all particle locations simultaneously simply by computing the matrix-matrix product RB, where R is again the 2\times 2 rotation matrix. This gives the following (note that B is called xy in the code):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # $CLASSHG/codes/particles/rotate5.py
from numpy import *
import time
tstart_cpu = time.clock() # start the CPU timer
N = 15000000 # number of particles
nsteps = 40 # number of rotation steps
print "Rotating %s particles through %s theta values" % (N, nsteps)
alpha = linspace(0., 2*pi, N) # vector of all the alpha values
r = 1. + 0.5*cos(10*alpha) # vector with radius for each alpha
x1 = 2. + r*cos(alpha) # vector of x unrotated
y1 = r*sin(alpha) # vector of y unrotated
dtheta = 2.*pi / nsteps # change in theta between steps
cdt = cos(dtheta)
sdt = sin(dtheta)
xy = vstack((x1,y1)) # creates a 2xN matrix
R = array([[cdt,sdt], [-sdt,cdt]]) # the 2x2 rotation matrix
for n in range(nsteps+1):
xy = dot(R,xy) # multiply by rotation matrix
x = xy[0,:] # extract the 1st row, only needed for plotting
y = xy[1,:] # extract the 2nd row, only needed for plotting
t_cpu = time.clock() - tstart_cpu
print "CPU time: %12.8f seconds" % t_cpu
|
This gives slightly improved timing because Python takes advantage of special routines that optimize matrix-matrix multiplication:
$ python rotate5.py
Rotating 150000 particles through 40 theta values
CPU time: 0.16931200 seconds
This is about 200 times faster than the rotate3.py code, and probably about 2000 times faster than our original code would have been.
We might now get brave and try increasing N by another factor of 100, using 15 million particles:
$ python rotate5.py
Rotating 15000000 particles through 40 theta values
CPU time: 25.91272300 seconds
This is more like the speed expected from this computer! Note that doing the matrix-matrix multiply for the case with N particles requires doing 4N multiplies and 2N additions, so a total of about 240N floating point operations and hence 3.6 billion operations when N is 15 million. Dividing this by 25 seconds indicates that we have achieved a speed of about 144 Mflops (million floating point operations per second).
Further improvements are possible. In particular, this code as written is being executed on only one core on this dual core laptop, while the other sits idle. If we can take advantage of both cores, we may be able to cut the computing time in half. See Parallel Computing for more discussion of this. We will return to this example later in the quarter.
{kind=link}