Zhi-Qi Cheng, Ph.D.
My name is pronounced as Chéng Zhì-qí (approx. “Jer-Chee Chung”).
- Assistant Professor
- Computer Science and Systems
- Graduate Faculty (Doctoral)
- University of Washington Graduate School
- Director
- Multi-Foundation Intelligence Lab (MF-Lab)
- Visiting Faculty Researcher
- Meta AI AGI Team
Previously · Project Scientist and Postdoctoral Research Associate, Carnegie Mellon University

Short Bio
I am a tenure‑track Assistant Professor of Computer Science, jointly appointed in the Tacoma School of Engineering & Technology, University of Washington (UWT directory, UW directory search) and the Graduate School, University of Washington (Graduate Faculty Search). I direct the Multi‑Foundation Model Lab (MF‑Lab), supervise Ph.D. students in the Computer Science & Systems Ph.D. program. I also serve as a Visiting Faculty Researcher at the Meta AI AGI Team. My research focuses on Multimodal Generative AI, Embodied and Robotic Intelligence, and Intelligent Transportation—in collaboration with colleagues at the Paul G. Allen School and the PacTrans. My research has been published in top venues such as CVPR, ICCV, NeurIPS, ICLR, AAAI, IJCAI, and ACM MM, and has contributed to The Washington Post investigations that earned the 2022 Pulitzer Prize for Public Service.
Prior to joining the University of Washington, I spent seven years in the School of Computer Science, Carnegie Mellon University. I progressed from Post‑doctoral Associate to Project Scientist / Instructor, under the mentorship of Prof. Alexander G. Hauptmann and Prof. Teruko Mitamura. I collaborated closely with Prof. David R. Mortensen (KAIROS TA1) and Prof. Alan W. Black (KAIROS TA2). During this period, I served as technical lead for the DARPA KAIROS (and KAIROS‑Plus) projects, and contributed to the IARPA DIVA and NIST PSIAP Projects. Earlier, I held research internships at Alibaba DAMO Academy, Google Brain, and Microsoft Research, and was honored with the Intel Ph.D. Fellowship and IBM Outstanding Student Scholarship.
My research has been featured by The Washington Post, The New York Times, and CBS News, among other major media outlets, where it has informed public‑service reporting, safety analytics, and mobility policy discussions.
News
- 18 Sep 2025 | Our paper MaxSup: Overcoming Representation Collapse in Label Smoothing has been accepted as an Oral Presentation at NeurIPS 2025 (acceptance rate: 77 / 21,575 ≈ 0.36%). [arXiv] [NeurIPS]
- 03 Sep 2025 | Congratulations to Ph.D. student Yifei Dong on receiving the Carwein–Andrews Ph.D. Fellowship.
- 25 Jun 2025 | One paper accepted at ICCV 2025.
- 15 Jun 2025 | Dr. Cheng will join the Meta AI AGI team as a Visiting Faculty Researcher.
- 12 Jun 2025 | Invited keynote at CVPR 2025 Anti‑UAV Workshop; our survey Securing the Skies: A Comprehensive Survey on Anti‑UAV Methods, Benchmarking, and Future Directions wins the workshop’s Best Paper Award.
- 31 Mar 2025 | Incoming Ph.D. student Yifei Dong receives UW GSFEI Top Scholar Award 2025.
- 28 Mar 2025 | Dr. Cheng serves as Area Chair for NAACL 2025.
- 10 Feb 2025 | Four papers accepted at CVPR 2025 (2 main‑conference, 2 workshop papers).
- 05 Feb 2025 | One paper accepted at ICLR 2025.
- 20 Jan 2025 | Two papers accepted at AAAI 2025, including one Oral presentation.
Research Interests

Multimodal Foundation Models
AI that reads, sees, and generates across modalities.
- Vision–language pre-training
- Instruction & alignment
- Emotion reasoning & affective computing
- Efficient adaptation (LoRA/PEFT)

Embodied / Robotic Intelligence
Agents that perceive, reason, and act safely.
- Language-guided navigation & manipulation
- Sim-to-real robustness
- Multimodal sensing & scene understanding
- Human-aware planning

Intelligent Transportation
Mobility as a living lab—measuring real-world impact.
- Traffic-video analytics
- Risk & driver-state modeling
- Mobility simulation
- Edge AI for real-time perception
Selected Publications
View my full publication list on Google Scholar ↗
2025 Emotion-LLaMA – NeurIPS 24 ▼
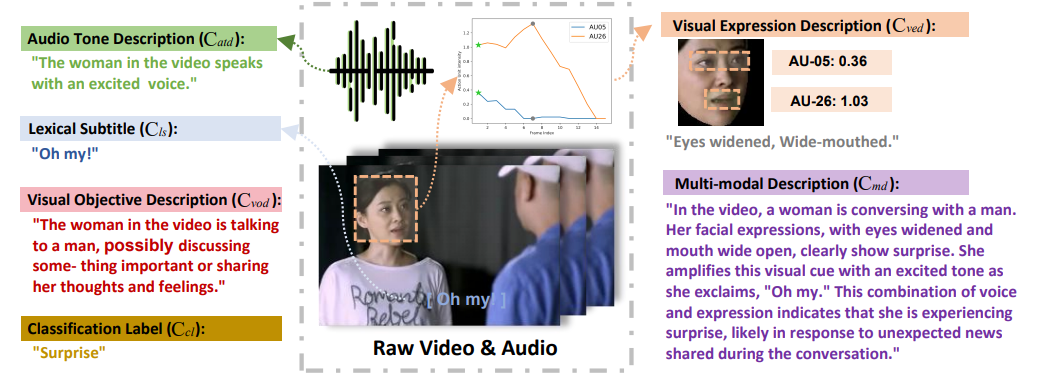
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
(NeurIPS 2024) Advances in Neural Information Processing Systems, 2024
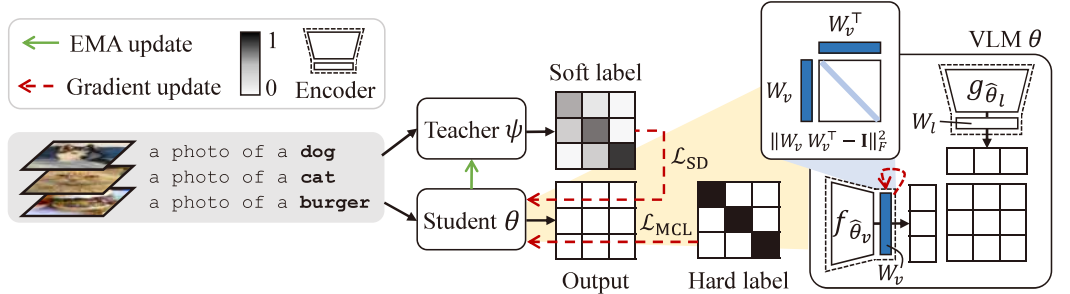
Towards Calibrated Robust Fine-Tuning of Vision-Language Models
(NeurIPS 2024; CMU 11775 course project) Advances in Neural Information Processing Systems, 2024
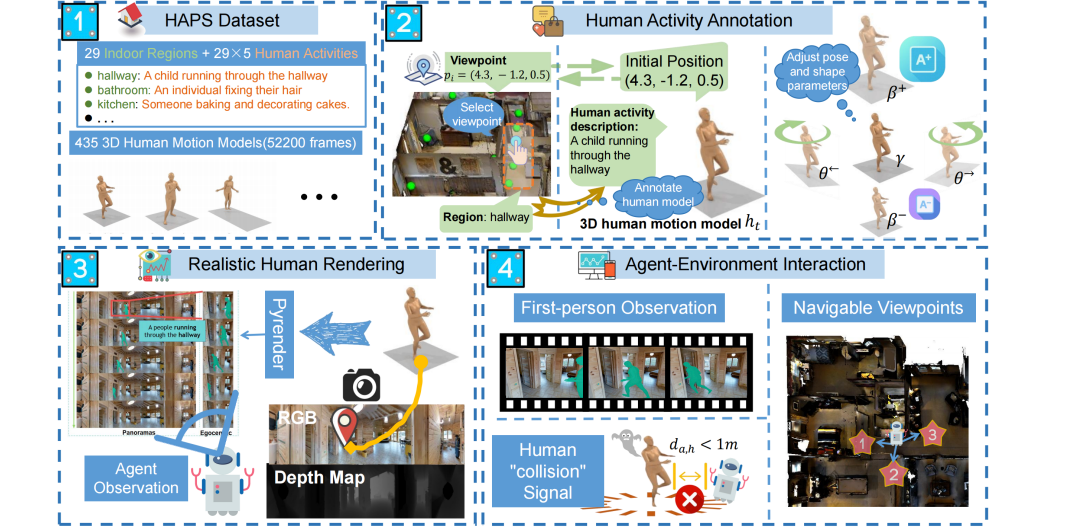
Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions
(NeurIPS 2024 Spotlight) Advances in Neural Information Processing Systems, 2024
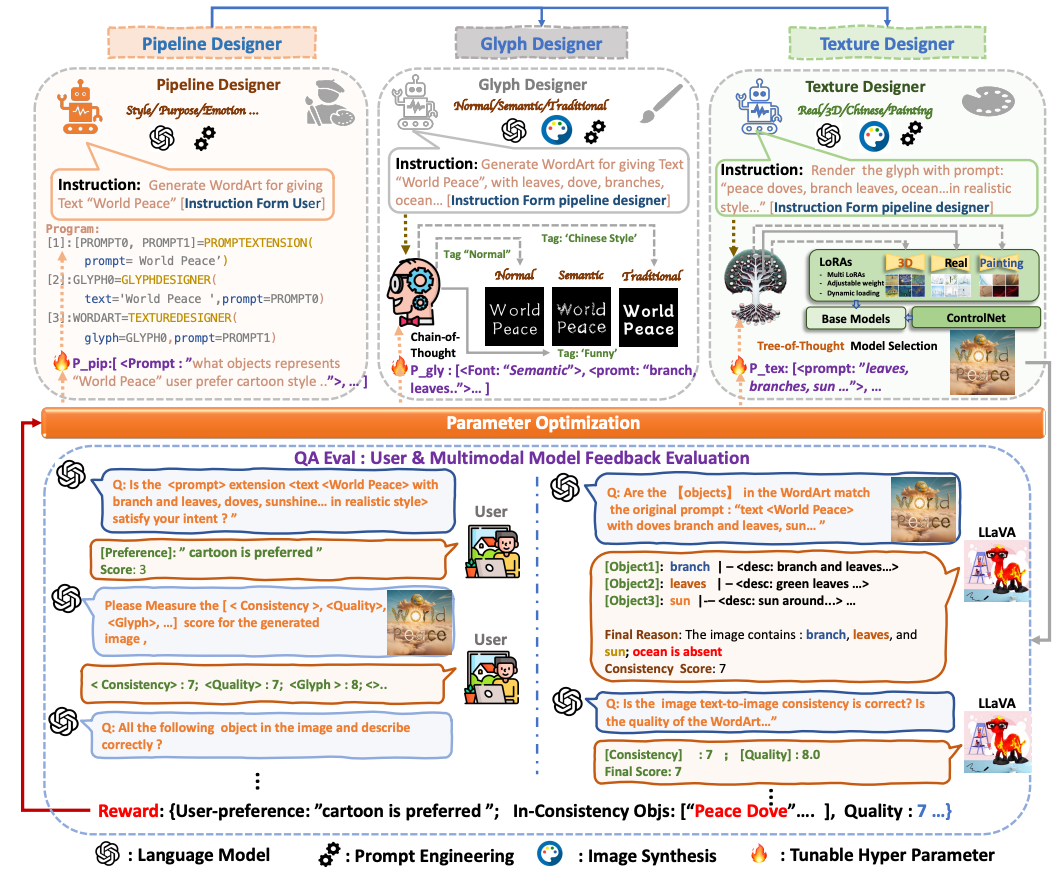
MetaDesigner: Advancing Artistic Typography Through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
(ICLR 2025; WordArt; ~1M visits) International Conference on Learning Representations, 2025
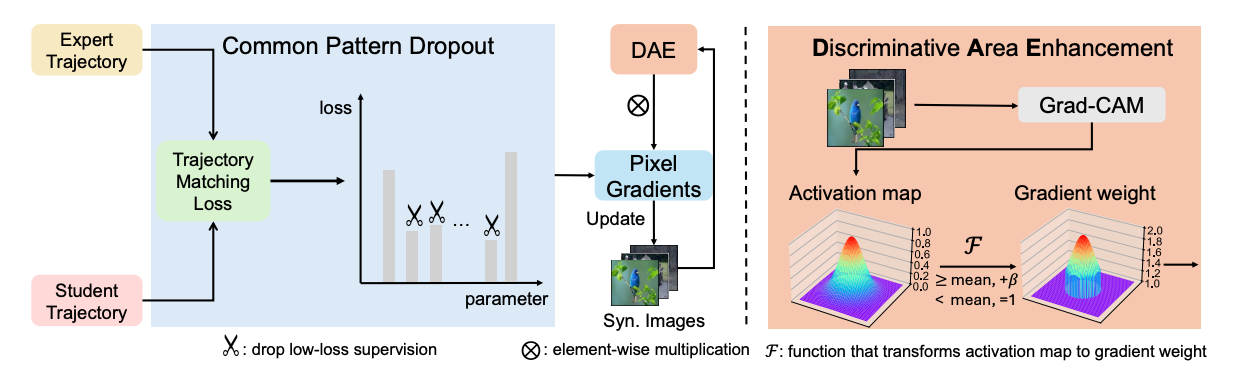
Emphasizing Discriminative Features for Dataset Distillation in Complex Scenarios
(CVPR 2025) IEEE/CVF Computer Vision and Pattern Recognition Conference, 2025
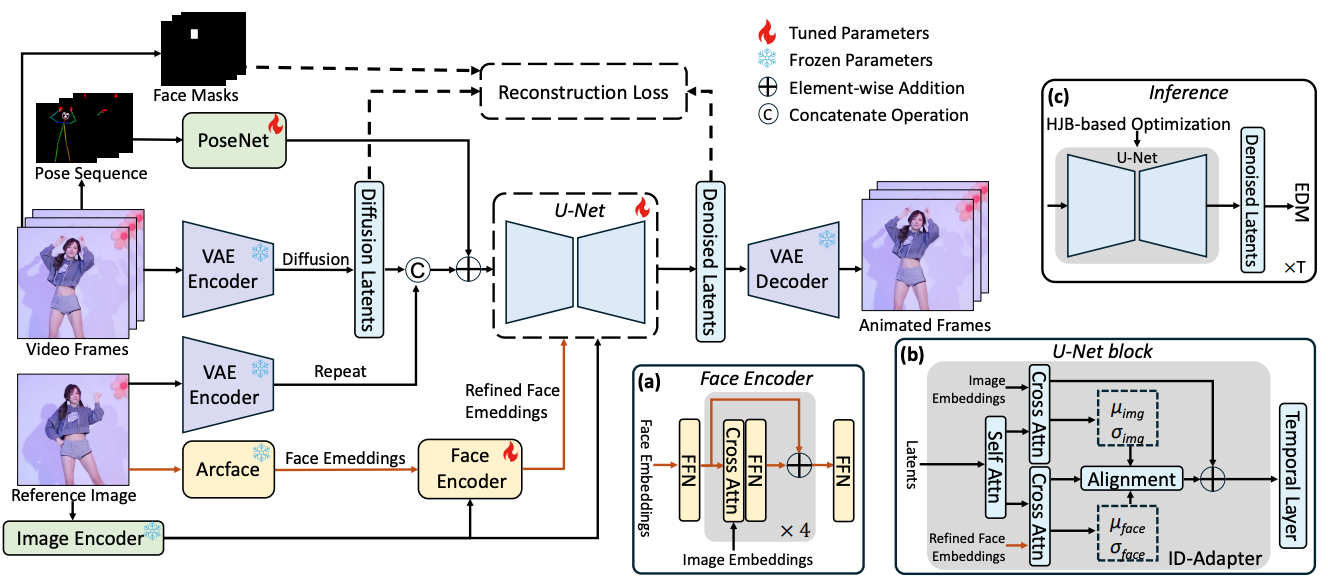
StableAnimator: High-Quality Identity-Preserving Human Image Animation
(CVPR 2025) IEEE/CVF Computer Vision and Pattern Recognition Conference, 2025
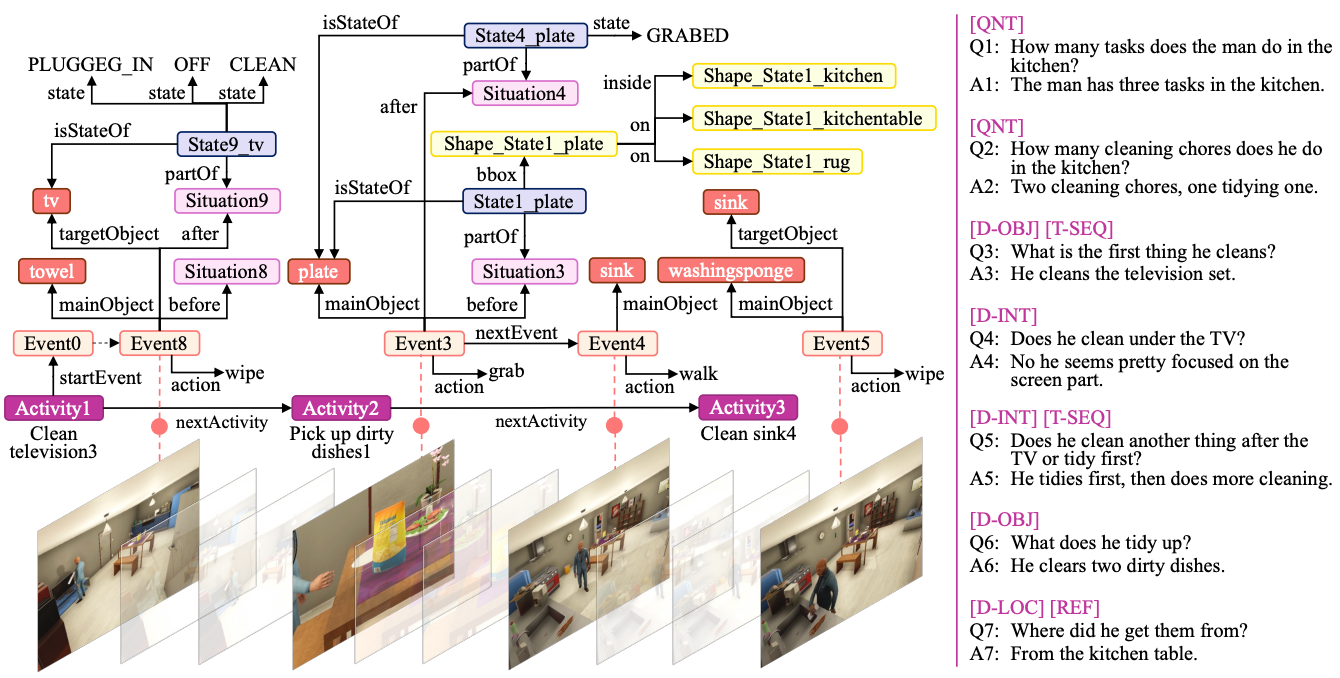
Video-Grounded Dialogue: New dataset and metric for event-driven QA.
(AAAI 2025 Oral) AAAI Conference on Artificial Intelligence, 2025
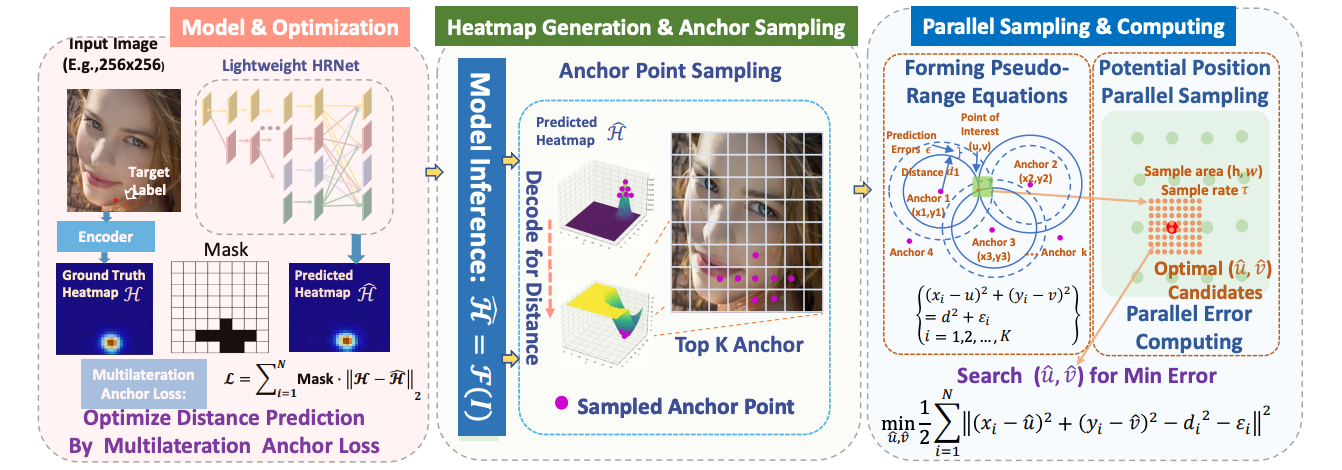
POPoS: Improving Efficient and Robust Facial Landmark Detection with Parallel Optimal Position Search
(AAAI 2025) AAAI Conference on Artificial Intelligence, 2025
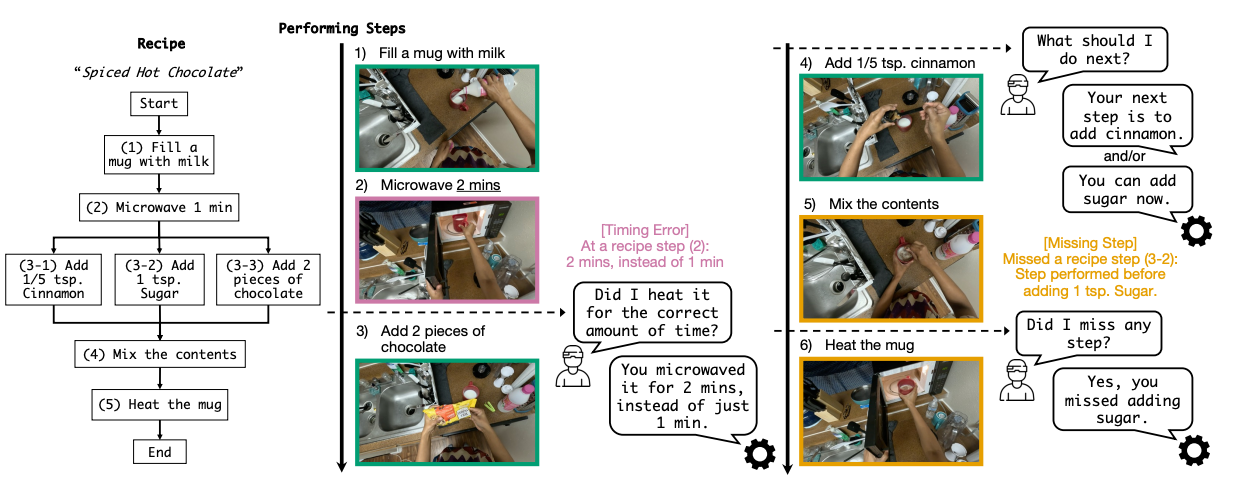
ProMQA: Question Answering Dataset for Multimodal Procedural Activity Understanding
(NAACL 2025 Oral) Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics, 2025
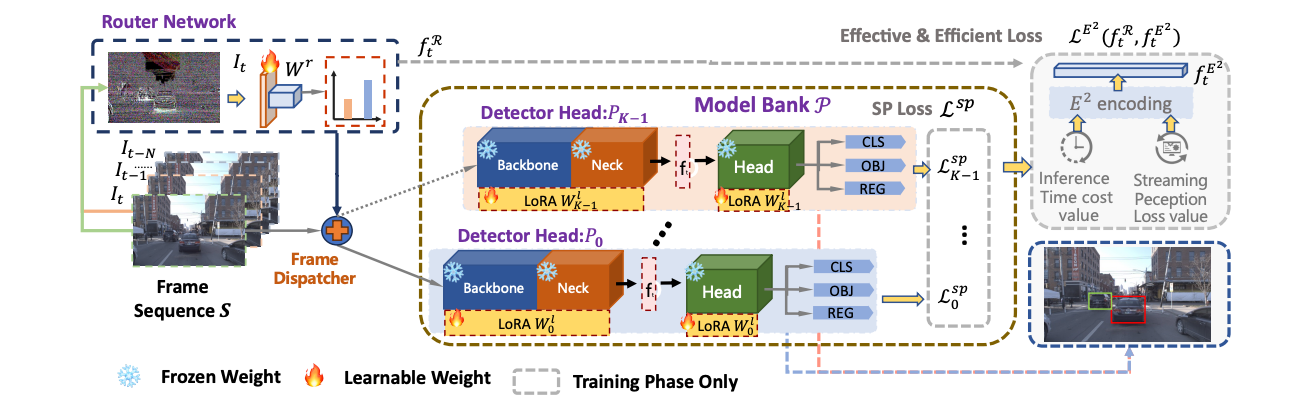
DyRoNet: Dynamic Routing and Low-Rank Adapters for Autonomous-Driving Streaming Perception
(WACV 2025) IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
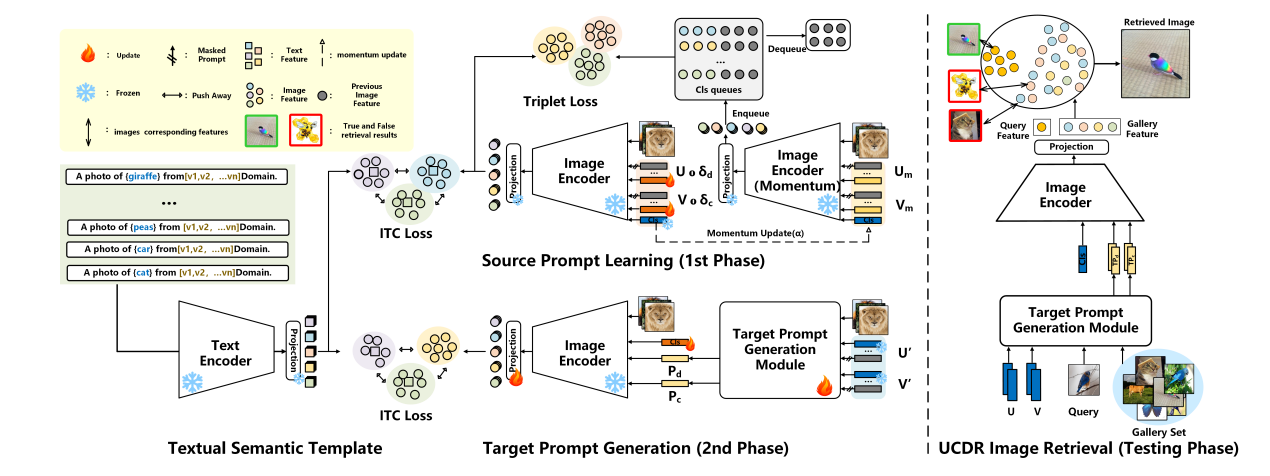
UCDR-Adapter: Exploring Adaptation of Pre-Trained Vision–Language Models for Universal Cross-Domain Retrieval
(WACV 2025) IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
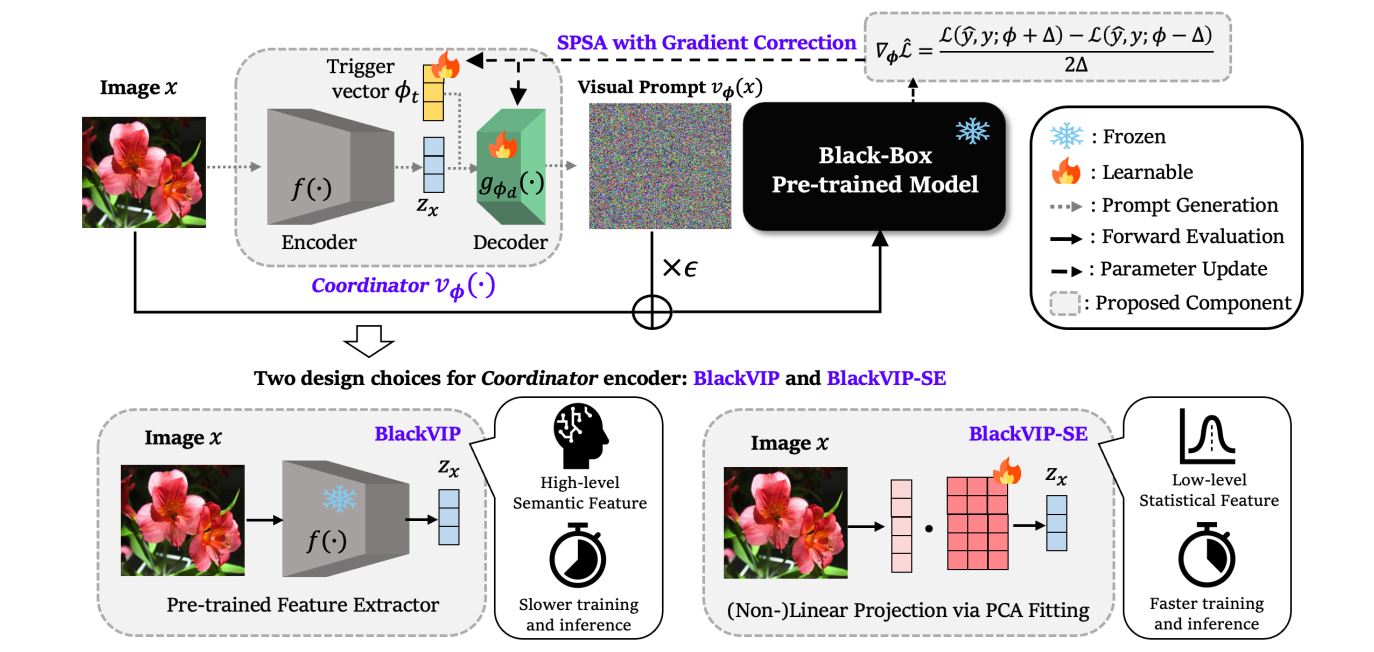
Black-Box Visual Prompting for Robust Adaptation of Foundation Models
(BlackVIP (CVPR'23 ext.), submitted to TPAMI) IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2024 BlockGCN - CVPR 24 ▼
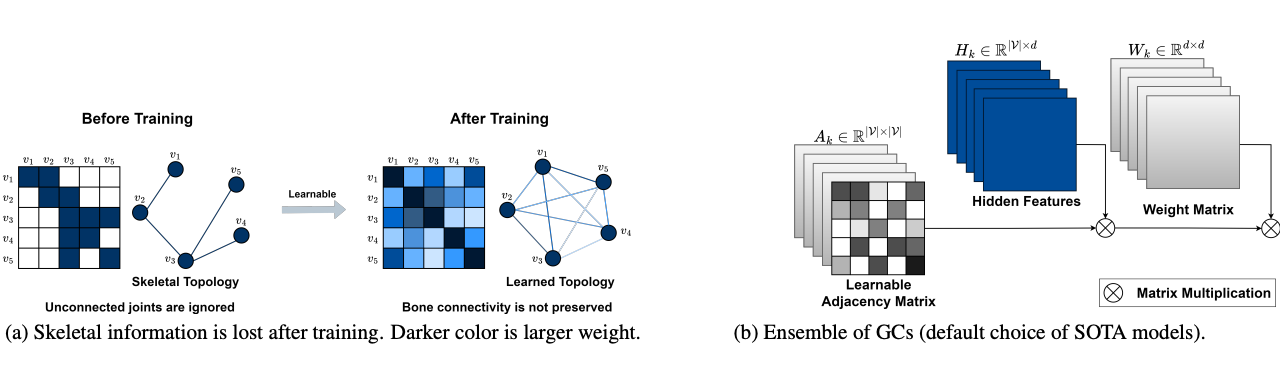
BlockGCN: Redefine Topology Awareness for Skeleton-Based Action Recognition
(CVPR 2024) IEEE/CVF Computer Vision and Pattern Recognition Conference, 2024
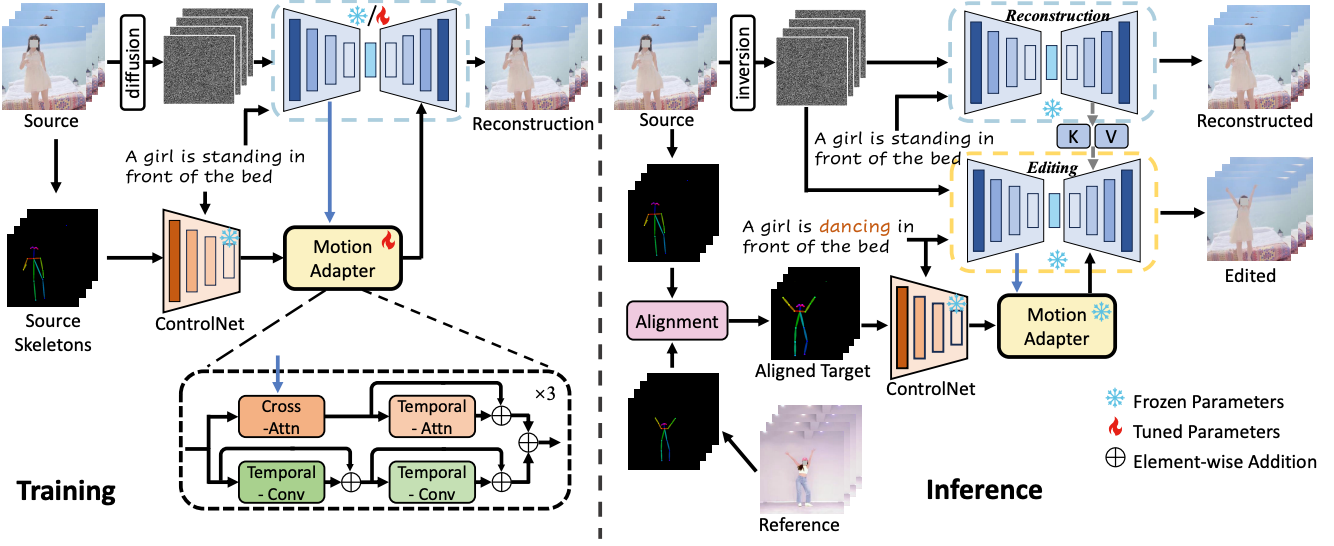
MotionEditor: Editing Video Motion via Content-Aware Diffusion
(CVPR 2024) IEEE/CVF Computer Vision and Pattern Recognition Conference, 2024
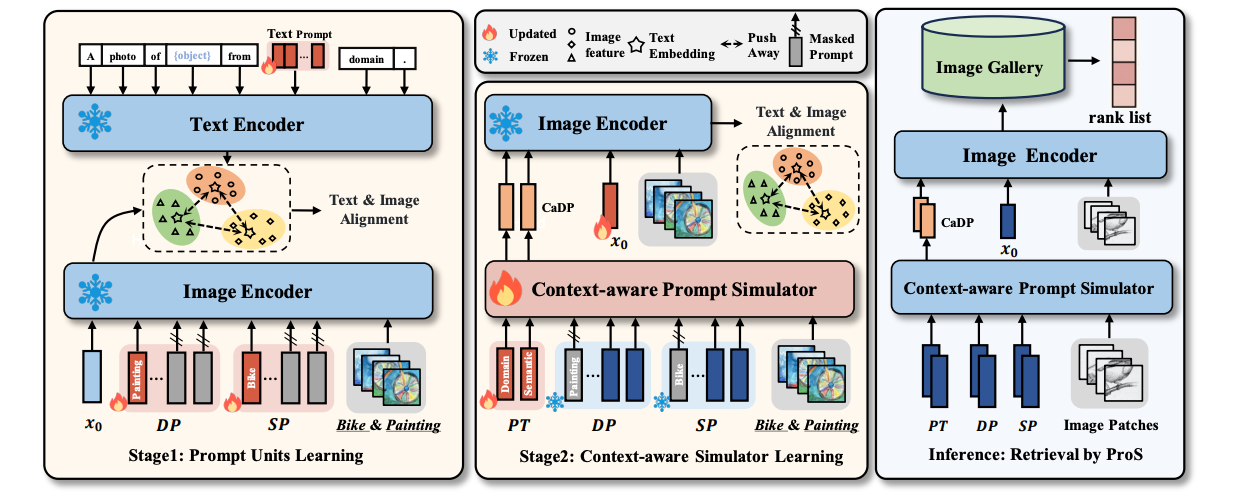
PROS: Prompting-to-Simulate Generalized Knowledge for Universal Cross-Domain Retrieval
(CVPR 2024) IEEE/CVF Computer Vision and Pattern Recognition Conference, 2024
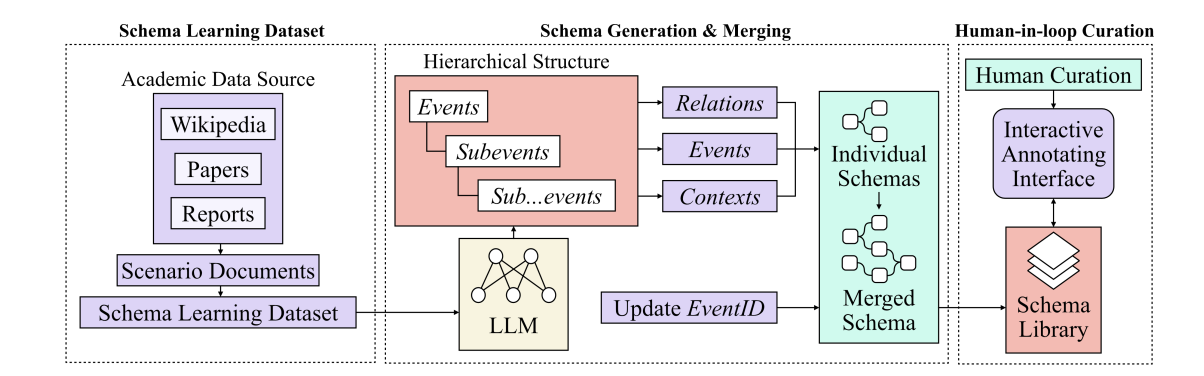
Shield: LLM-Driven Schema Induction for Predictive Analytics in EV Battery Supply-Chain Disruptions
(EMNLP 2024 Oral, Industry Track) Conference on Empirical Methods in Natural Language Processing, 2024
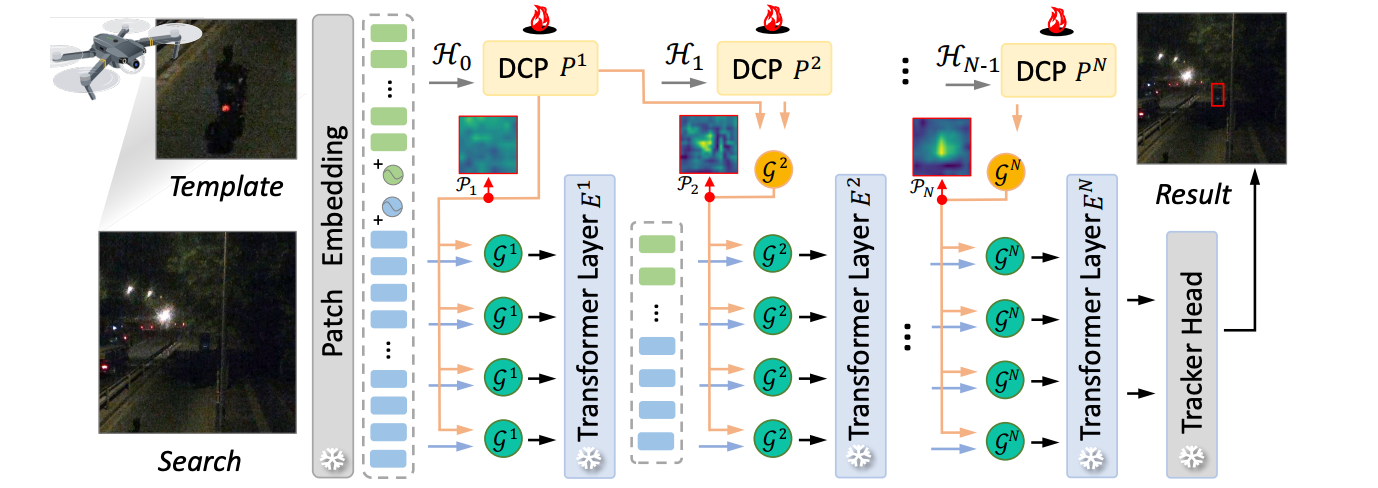
DCPT: Darkness Clue-Prompted Tracking in Night-Time UAVs
(ICRA 2024) IEEE International Conference on Robotics and Automation, 2024
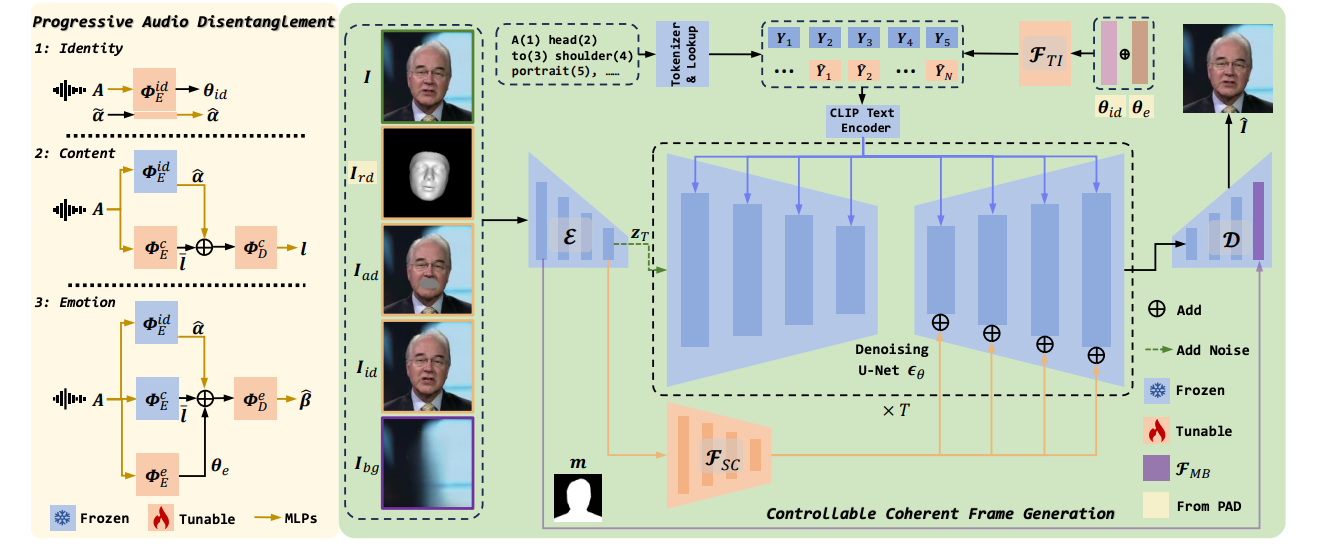
FaceChain-ImagineID: High-Fidelity Diverse Talking Faces from Disentangled Audio
(CVPR 2024; Part of FaceChain (9.3K GitHub stars)) IEEE/CVF Computer Vision and Pattern Recognition Conference, 2024
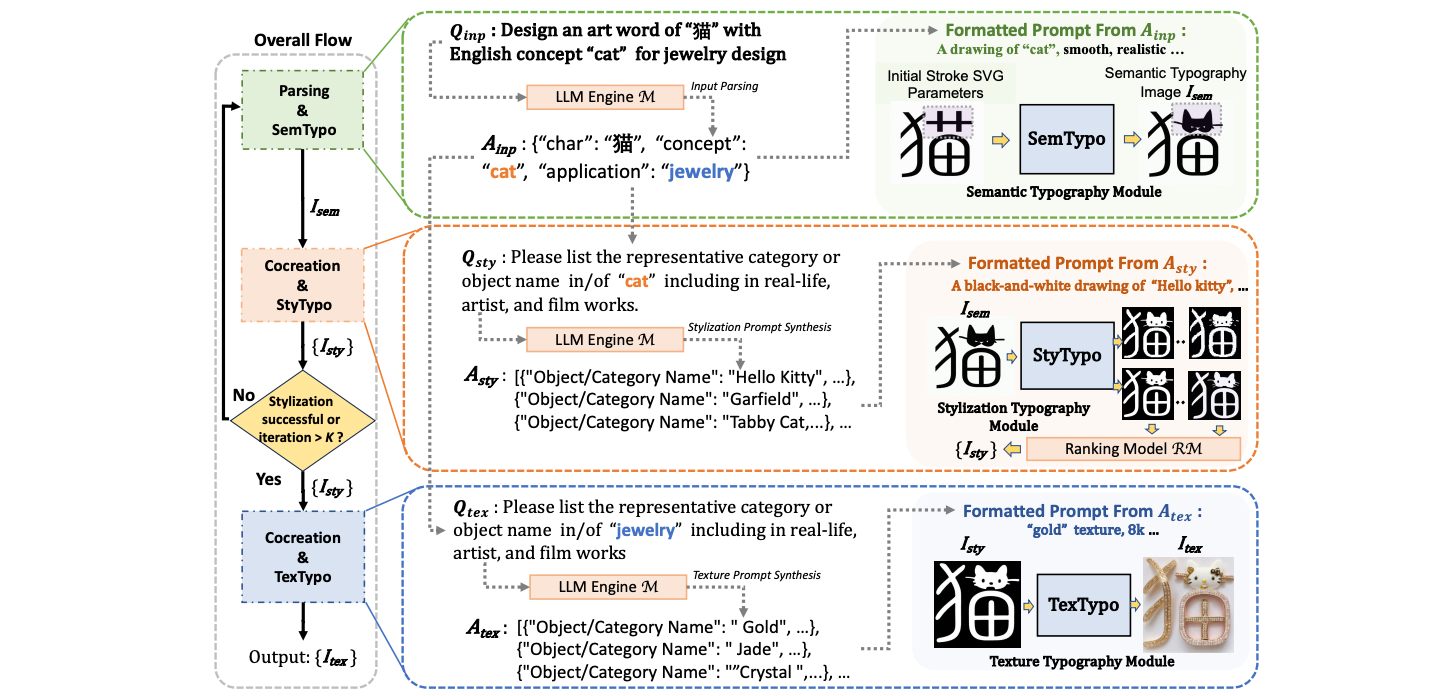
WordArt Designer API: Artistic Typography with LLMs on ModelScope
Spotlight @ NeurIPS ML4Creativity workshop
2023 DAMO-StreamNet - IJCAI 23 ▼
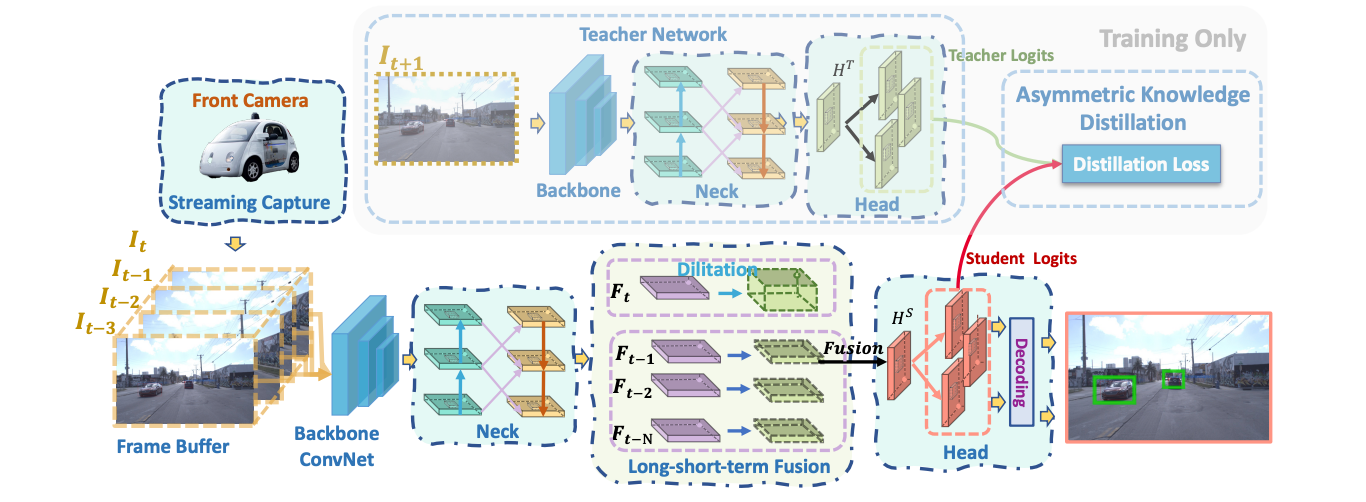
DAMO-StreamNet: Optimizing Streaming Perception in Autonomous Driving
(IJCAI 2023) International Joint Conference on Artificial Intelligence, 2023
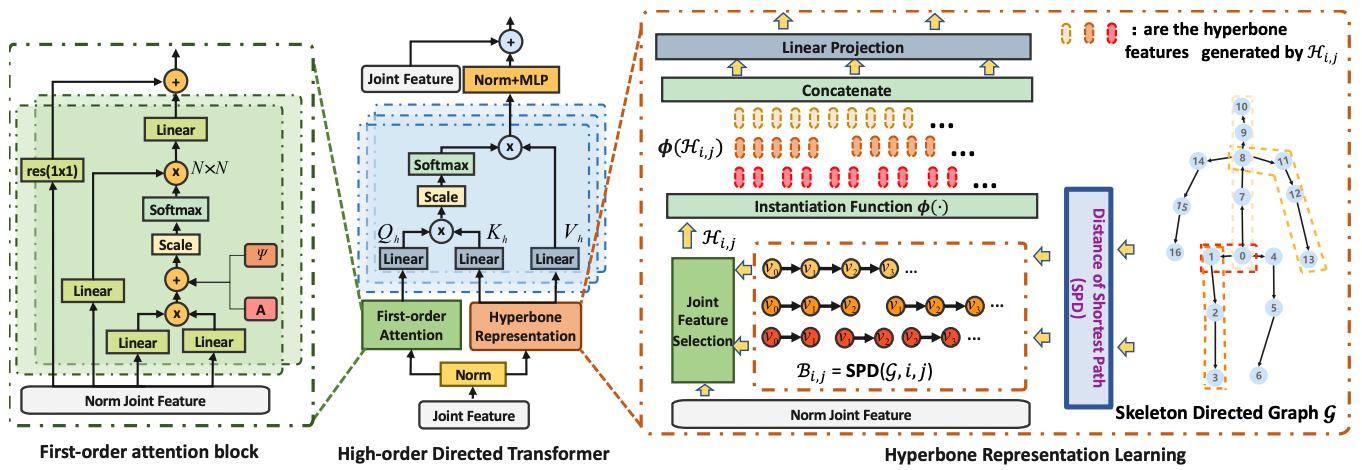
HDFormer: High-Order Directed Transformer for 3D Human Pose Estimation
(IJCAI 2023) International Joint Conference on Artificial Intelligence, 2023
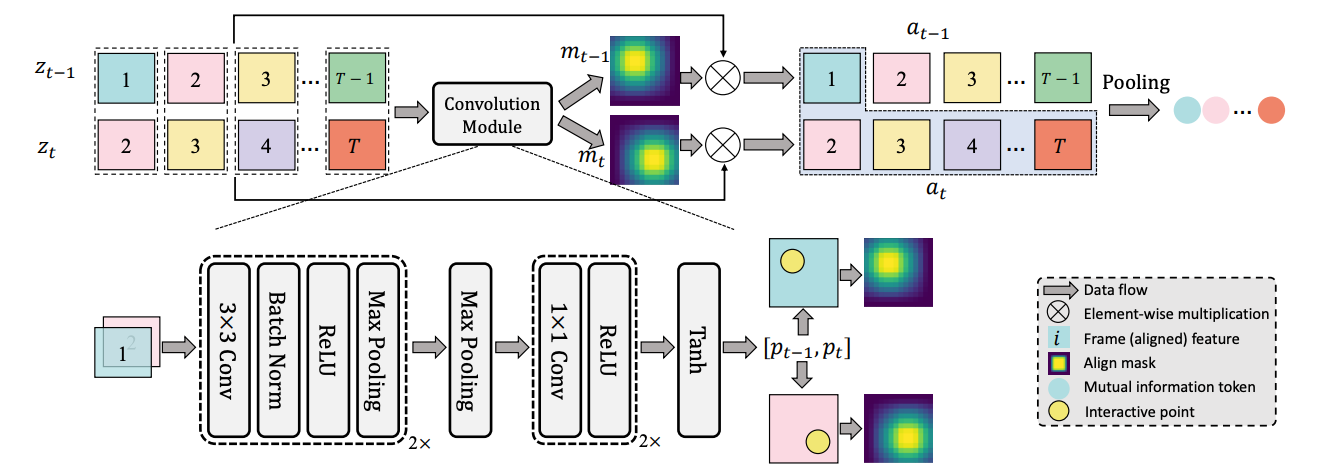
Implicit Temporal Modeling with Learnable Alignment for Video Recognition
(ICCV 2023 Oral) International Conference on Computer Vision, 2023
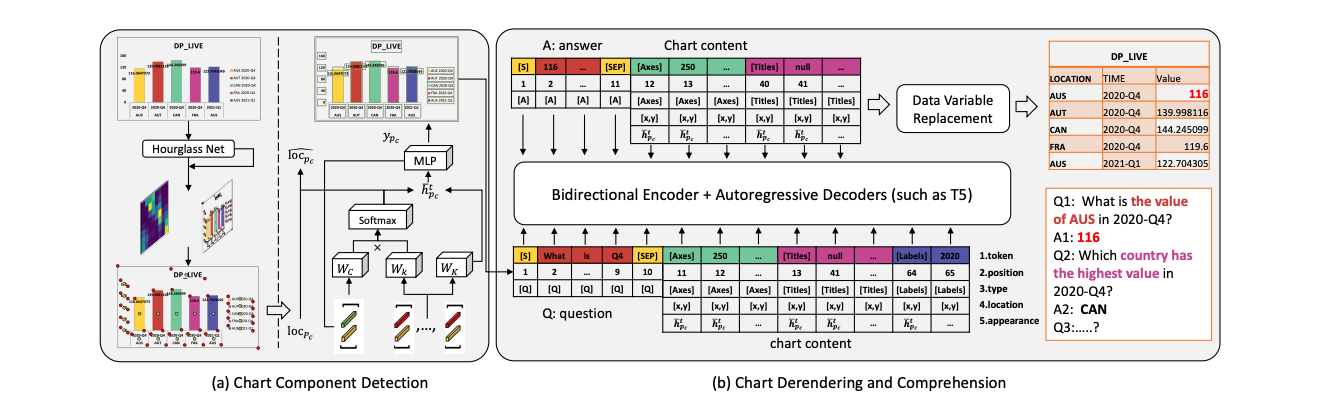
ChartReader: A Unified Framework for Chart Derendering and Comprehension Without Heuristic Rules
(ICCV 2023) International Conference on Computer Vision, 2023
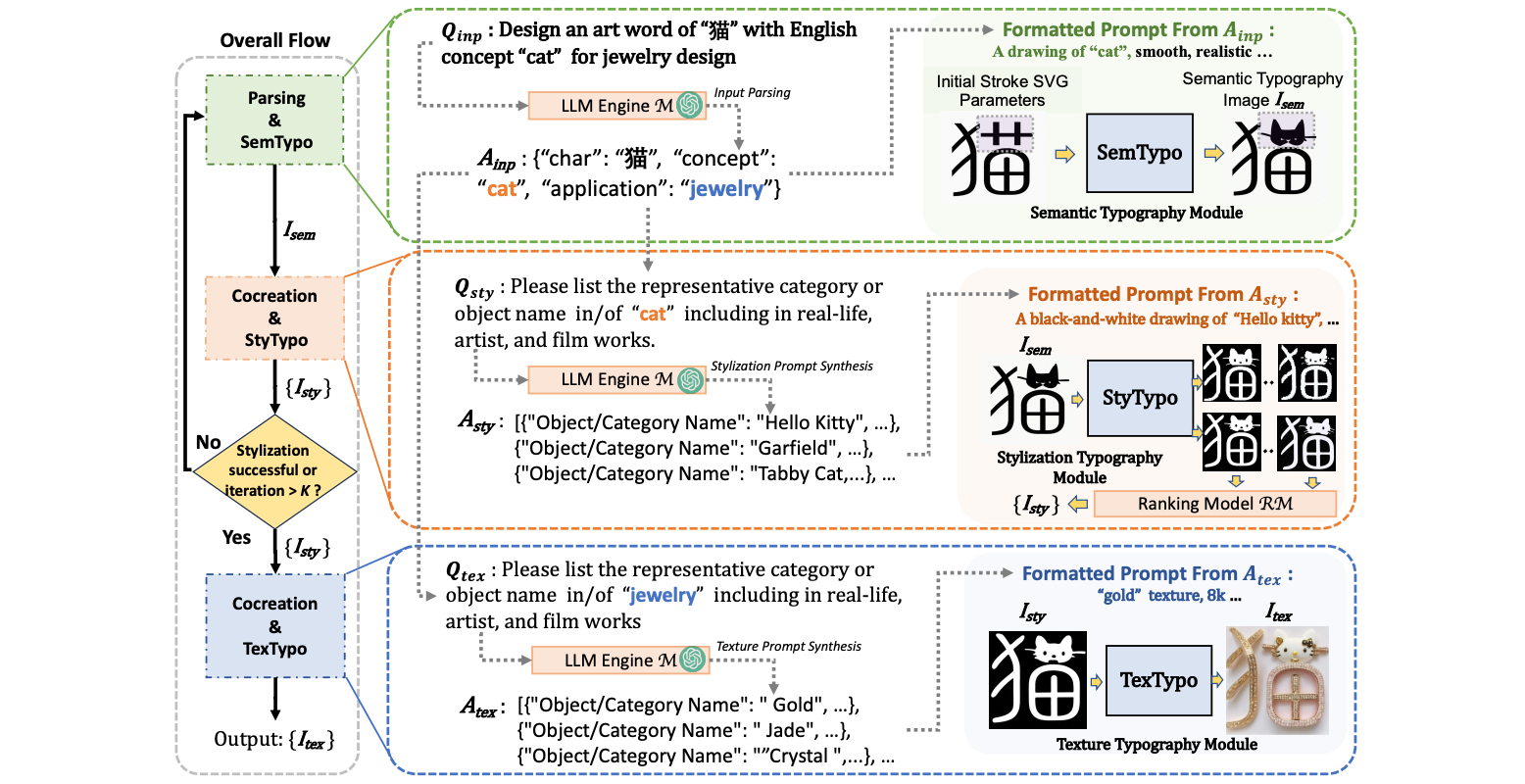
WordArt Designer: User-Driven Artistic Typography Synthesis Using Large Language Models
(EMNLP 2023, Industry Track) Conference on Empirical Methods in Natural Language Processing, 2023
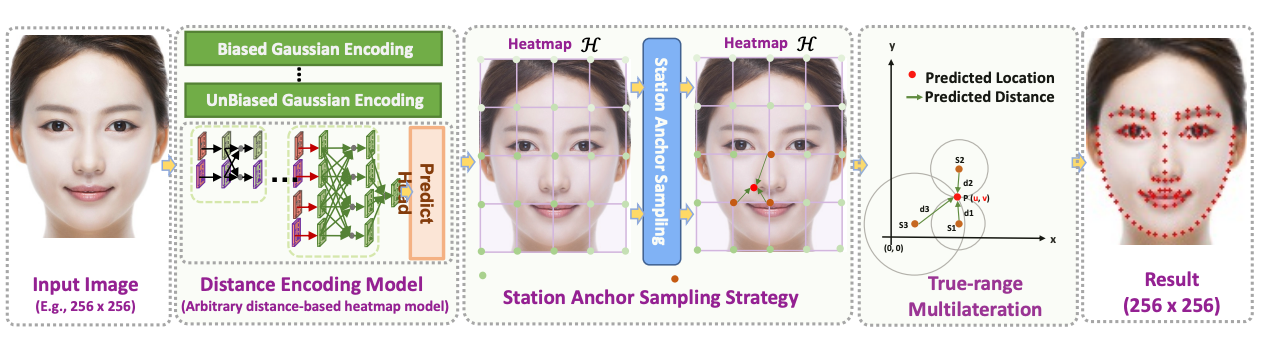
KeyPosS: Plug-and-Play Facial Landmark Detection through GPS-Inspired True-Range Multilateration
(ACM-MM 2023) ACM International Conference on Multimedia, 2023
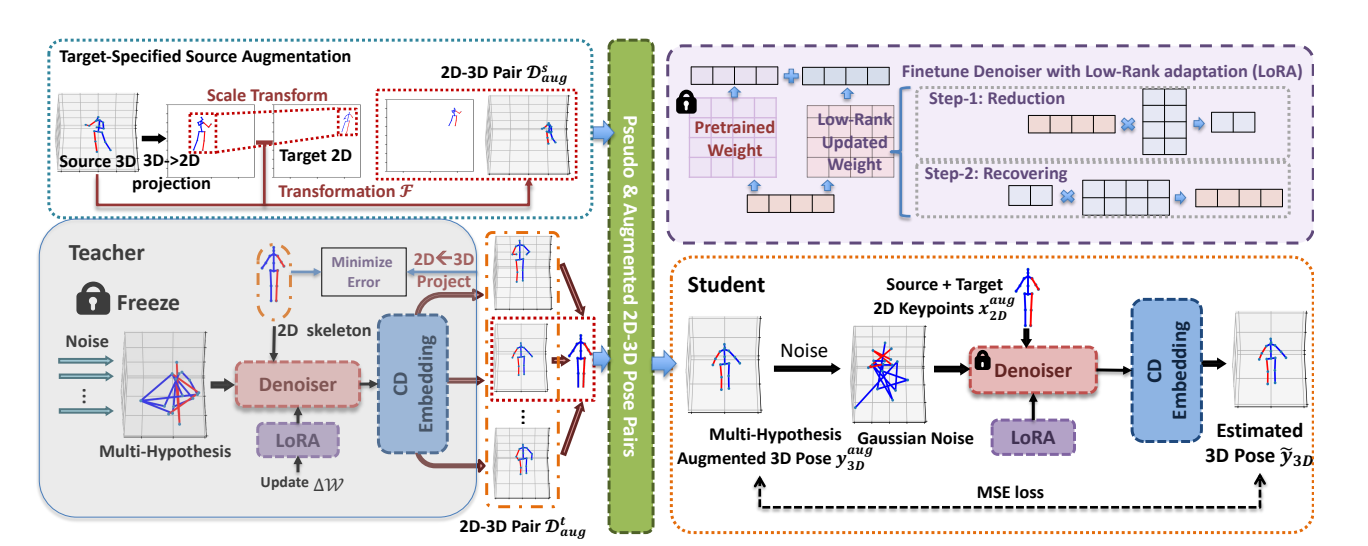
Posynda: Multi-Hypothesis Pose Synthesis Domain Adaptation for Robust 3D Human Pose Estimation
(ACM-MM 2023) ACM International Conference on Multimedia, 2023
≤ 2022 Rethinking Spatial Invariance – CVPR 22 ▼
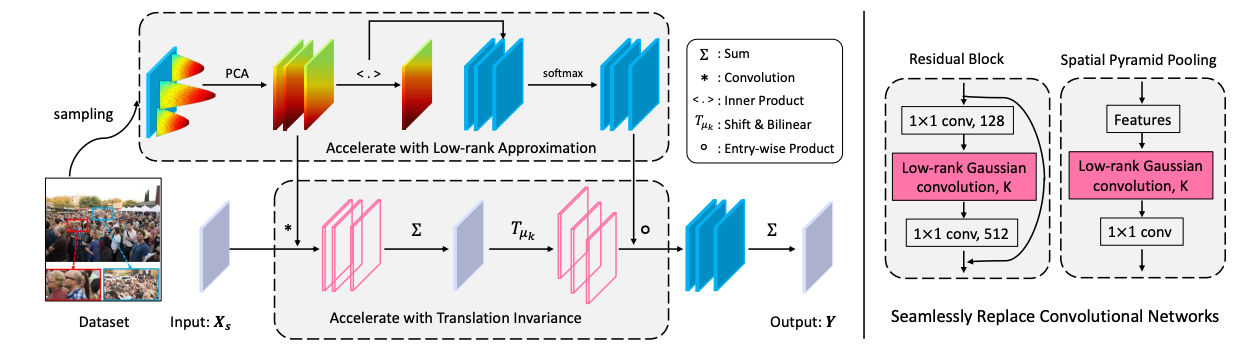
Rethinking Spatial Invariance of Convolutional Networks for Object Counting
(CVPR 2022; used for WaPo's Pulitzer coverage) IEEE/CVF Computer Vision and Pattern Recognition Conference, 2022
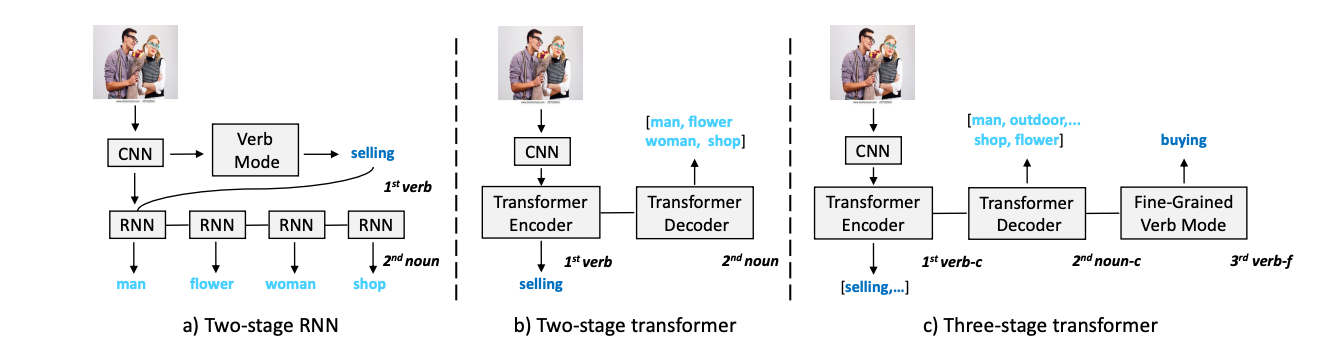
GSRFormer: Grounded Situation Recognition Transformer with Alternate Semantic Attention
(ACM-MM 2022 Oral) ACM International Conference on Multimedia, 2022
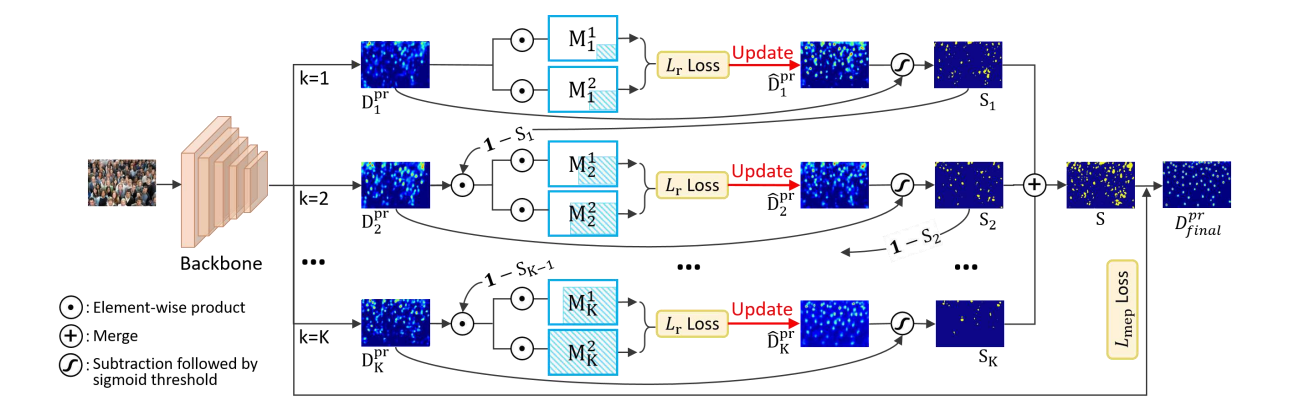
Learning Spatial Awareness to Improve Crowd Counting
(ICCV 2019 (Oral); CMU's INF-Public-Safety-Tools) International Conference on Computer Vision, 2019
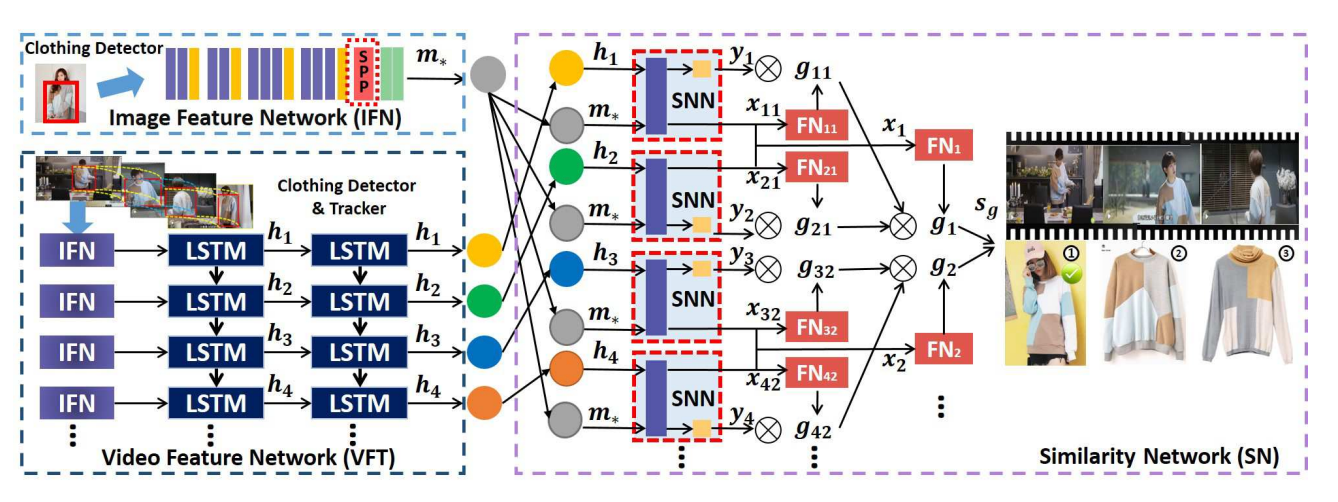
Video2Shop: Exact Matching Clothes in Videos to Online Shopping Images
(CVPR 2017; Alibaba Pailitao (~500M users)) IEEE/CVF Computer Vision and Pattern Recognition Conference, 2017
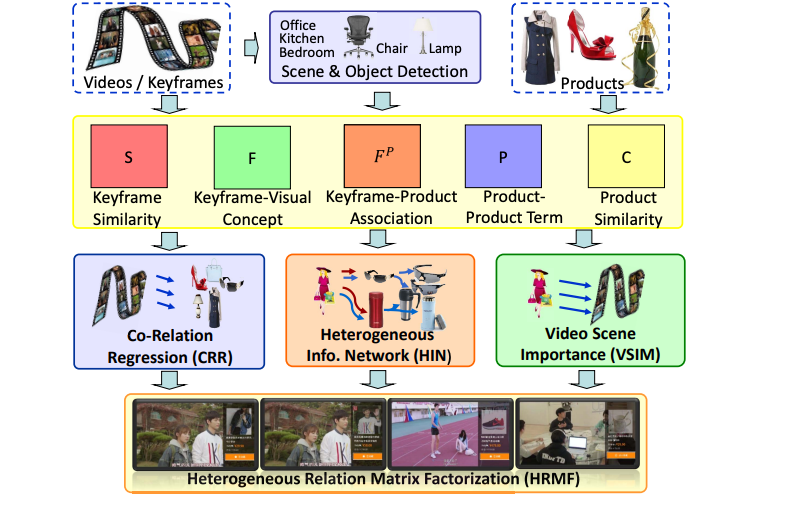
Video eCommerce++: Toward Large-Scale Online Video Advertising
(ACM-MM 2017 Oral; ACM-SCF Best Student Paper) ACM International Conference on Multimedia, 2016