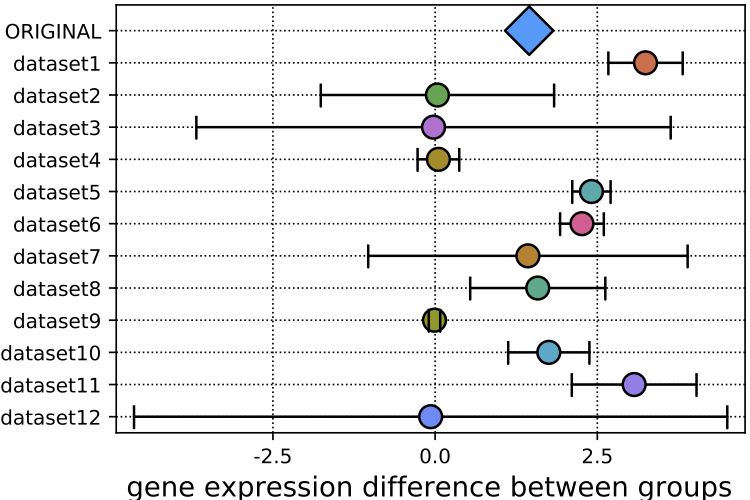
We are developing an end-to-end system for validating scientific claims against open data repositories using NLP, machine learning, and data integration techniques.

Bill Howe
Associate Professor, Information School
Adjunct Associate Professor, Computer Science & Engineering
Adjunct Associate Professor, Electrical Engineering
Co-Founding Faculty Director, Center for Responsible AI Systems and Experiences
Director, Urbanalytics Lab
Founding Program Director and Faculty Chair, UW Data Science Masters Degree
Founding Associate Director and Senior Data Science Fellow, UW eScience Institute
University of Washington
Short Bio |
Curriculum Vitae |
NSF-style biosketch |
NIH-style biosketch
billhowe at uw.edu | Office: MGH 310 in the iSchool DataLab
I am an Associate Professor in the Information School, Adjunct Associate Professor in Computer Science & Engineering and Electrical Engineering. I was Founding Associate Director of the UW eScience Institute where I remain a Senior Data Science Fellow. I currently serve as Faculty Director and Co-Founder of the Center for Responsible AI Systems and Experiences and Director of the Urbanalytics group. I am a co-founder of Urban@UW. I created a first MOOC on Data Science through Coursera, and I led the creation of the UW Data Science Masters Degree, where I serve as its first Program Director and Faculty Chair. I serve on the Steering Committee of the Center for Statistics in the Social Sciences.
My current research is in the epistemological foundations of AI, where we apply empirical methods and develop new algorithms to make AI safer for use in applications underserved by market forces, especially in the public sector and in the physical, life, and social sciences. My prior research was in developing systems and algorithms to make the techniques and technologies of data science broadly accessible especially in contexts where issues of equity, privacy, and compliance are paramount. Our methods and publications span three communities: AI, data management, and visualization, and my students have achieved recognition in all three fields. We are an applied, systems-oriented group, frequently sourcing projects through collaborations across campus and with local and state governments.
News
- July, 2025: Our paper Do Language Models Mirror Human Confidence? Exploring Psychological Insights to Address Overconfidence in LLMs led by Chenjun Xu was accepted to ACL 2025 (Findings).
- June, 2025: Our paper The Art of Refusal: A Survey of Abstention in Large Language Models led by Bingbing Wen was accepted to Transactions of the Association for Computational Linguistics (TACL) 2025.
- May, 2025: Our paper Fragments to Facts: Partial-Information Fragment Inference from LLMs led by Lucas Rosenblatt was accepted to ICML 2025.
- July, 2025: Two papers accepted to COLM 2025: Epistemic Alignment: A Mediating Framework for User-LLM Knowledge Delivery led by Nicholas Clark and Can Large Language Models Integrate Spatial Data? Empirical Insights into Reasoning Strengths and Computational Weaknesses led by Bin Han.
- June, 2025: Our preprint Escaping the SpuriVerse: Can Large Vision-Language Models Generalize Beyond Seen Spurious Correlations? led by Yiwei Yang was posted and submitted to NeurIPS 2025.
- August, 2024: Our paper Towards Zero-Shot Annotation of the Built Environment with Vision-Language Models led by Bin Han was accepted to ACM SIGSPATIAL 2024 (ACM DL).
- August, 2024: Our paper SARN: Structurally-Aware Recurrent Network for Spatio-Temporal Disaggregation led by Bin Han was accepted to ACM SIGSPATIAL 2024 (ACM DL).
- July, 2024: Our paper Dataset Scale and Societal Consistency Mediate Facial Impression Bias in Vision-Language AI led by Robert Wolfe was accepted to AIES 2024.
- July, 2024: Our paper ML-EAT: A Multilevel Embedding Association Test for Interpretable and Transparent Social Science led by Robert Wolfe was accepted to AIES 2024.
- July, 2024: Our paper Representation Bias of Adolescents in AI: A Bilingual, Bicultural Study led by Robert Wolfe was accepted to AIES 2024.
- July, 2024: Our preprint A Survey of the Fundamental Role of Abstention in Building Reliable Large Language Models led by Bingbing Wen was submitted to TACL (later published as the TACL 2025 survey above).
- September, 2024: Our preprint PathwayBench: Assessing Routability of Pedestrian Pathway Networks Inferred from Multi-City Imagery led by Yuxiang Zhang was submitted to the NeurIPS 2024 Datasets & Benchmarks track.
- March, 2024: Our paper Laboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings led by Robert Wolfe was accepted to ACM FAccT 2024 (arXiv).
- February, 2024: Our paper Label-Efficient Group Robustness via Out-of-Distribution Concept Curation led by Yiwei Yang was accepted to CVPR 2024 (PDF).
- August, 2023: Our paper on Epistemic Parity received a runner-up Best Paper award at VLDB 2023! This work was a collaboration with NYU, led by Lucas Rosenblatt, and involved the use of a large team of Ukrainian undergraduate researchers who are all co-authors. Congrats to the team!
- August, 2023: We had two applied papers accepted to HICCS. :)
- June, 2023: I gave a keynote at Human-in-the-Loop Data Analytics workshop (HILDA) co-located with SIGMOD 2023.
- May, 2023: I gave a keynote at Alberto Mendelzon International Workshop on Foundations of Data Management (AMW2023 in Santiago Chile.
- May, 2023: Our paper on Epistemic Parity, an approach to evaluating differentially private synthetic data using the scientific literature, was accepted to VLDB 2023.
- long break in updating due to COVID, family emergencies, and sabbatical...
- July, 2021: I gave the keynote at the fantastic ProvViz workshop.
- March, 2021: Our paper on data equity in relationship to COVID-19 has been released in DG.o.
- February, 2021: Our short paper describing data equity and data equity systems was published in EDBT
- February, 2021: My student An Yan's Equitensors paper has been accepted to SIGMOD 21.
- January, 2021: My student Sean Yang's JECL paper showing new state-of-the-art results for joint embeddings of image-text pairs has been accpted to ICPR.
- August, 2020: I'm pleased to be a co-author on Julia Stoyanovich's invited keynote paper on Responsible Data Management at VLDB 2020.
- July, 2020: Shana Hutchison's paper on optimizing linear algebra queries using relational algebra was published in VLDB 2020.
- April, 2020: My student An Yan's paper on fairness metrics for urban mobility applications has been accepted to AAAI.
- November, 2019: My student An Yan's short paper on fairness metrics in spatio-temporal settings (FairST) has been published at SIGSPATIAL.
- April, 2020: Our survey paper on algorithmic fairness and urban mobility (with my student An Yan) was published in a special issue of the Data Engineering Bullletin Our summary paper on the relationship between database repair and fairness is available in SIGMOD Record
- March, 2020: Our summary paper on the relationship between database repair and fairness is available in SIGMOD Record
- August, 2019: My student Sean Yang's ipaper quantifying how the use of visualizations varies across scienific disciplines has been released
- June, 2019: Our paper on algorithmic fairness (with Babak Salimi, Luke Rodriguez, and Dan Suciu) received the Best paper award at SIGMOD 2019!
- May, 2019: My student Dominik Moritz's (now at CMU!) paper on Falcon, demonstrating in-browser, interactive speeds for cross-linked visualizations on billion-tuple datasets received the Best paper award at VIs 2019!
- January, 2019: Our paper on data governance, privacy, and synthetic data was published at FAT 2019 (now FAccT)
- January, 2019: Our paper on the equity of dockless bikeshare systems, led by Stephen Mooney, was published in the Journal of Transport Geography
- August, 2018: My student Shrainik Jain's paper on using deep learning for vendor-agnostic workload management was accepted to CIDR 2019.
- July 26, 2018: I'm giving an invited talk at NSF on our work on algorithmic curation of science data repositories.
- July 21, 2018: Best paper award Our paper on DRACO using answer set programming to model visualization recommendation rules won best paper at InfoVis 2018! Congratulations to Dominik and the whole team!
- July 18, 2018: I presented our paper on EZLearn at IJCAI 2018 in Stockholm. EZLearn combines distant supervision and co-learning to avoid the need for training data in applications that have access to noisy free-text descriptions of data, especially in science.
- July 10, 2018: Congratulation to Kanit (Ham) Wongsuphasawat for defending his thesis on visualization recommendation systems! Ham is joining Apple as a Research Scientist.
- July 2, 2018: New workshop paper on removing bias from transportation data at BiDU - Workshop on Big Social Data and Urban Computing co-located with VLDB 2018
- June 21, 2018: I represented our BIGDATA grant on Foundations of Responsible Data Science and the West Big Data Hub at the combined BIGDATA PI meeting and Big Data Hubs meeting at NSF this week.
- June 14, 2018: New workshop paper accepted at DSDAH 2018, co-located with KDD, on Classifying Digitized Art by Type and Time Period
- June 14, 2018: Great discussion at our session on Responsible Data Science at SIGMOD 2018 in Houston
- June 11, 2018: New workshop paper accepted at BigScholar 2018, co-located with KDD, on Central Figure Identification for scientific papers.
- May 3, 2018: New blog post on nutritional labels for datasets and models is up at Freedom to Tinker. This post expands on our SIGMOD 2018 demo on Nutritional Labels for Rankings at SIGMOD 2018
- April, 2018: Congratulations to Maxim Grechkin for defending his thesis on algorithmic curation. Max joined facebook's integrity team working on claim verification as a research scientist.
Projects
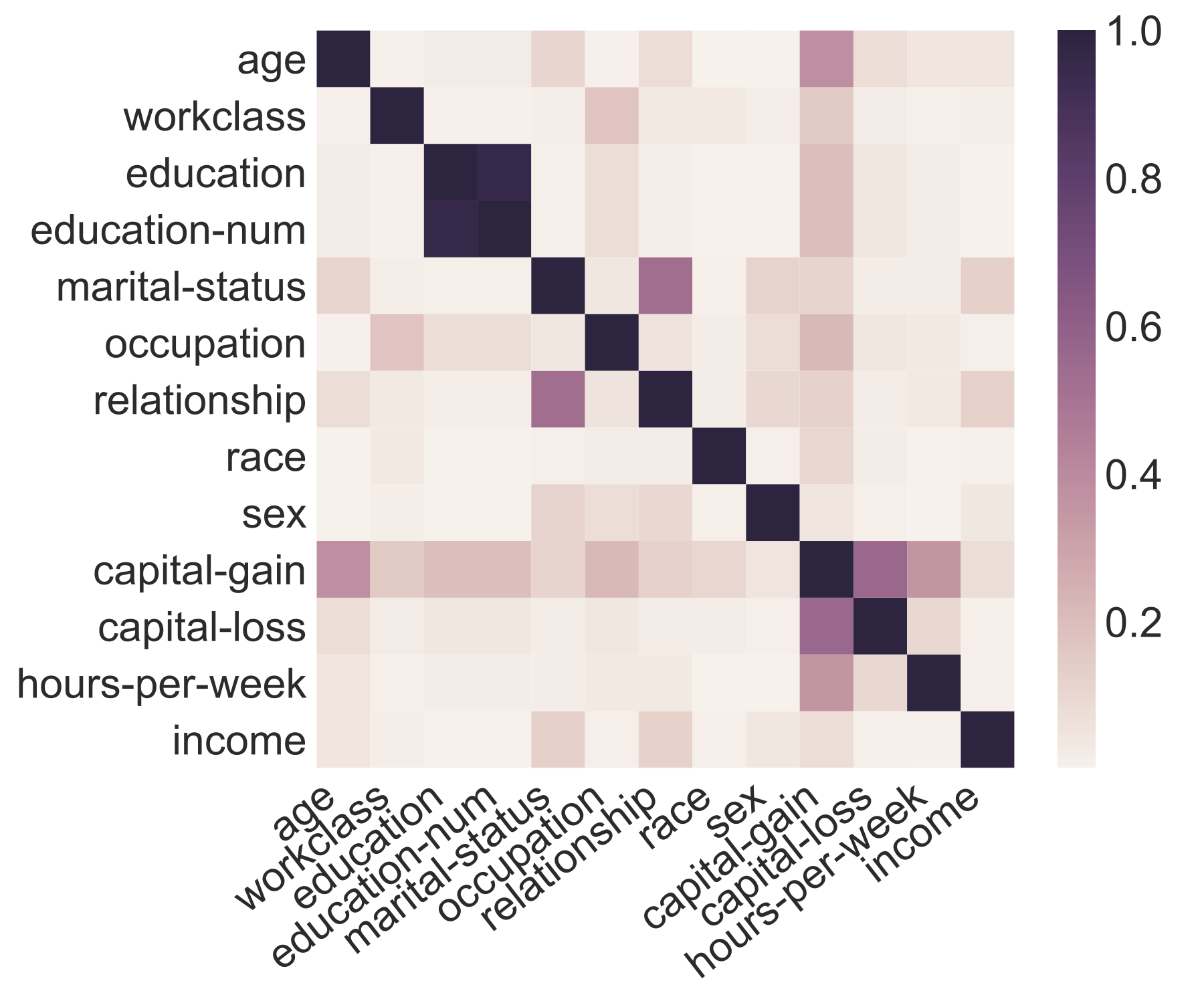
We are developing usable, general tools to generate shareable synthetic datasets with strong privacy guarantees from any input dataset.

Building on our data science incubator program and the University of Chicago's Data Science for Social Good program, we ran an interdisciplinary summer program for...
Machine vision, machine learning, and bibliometric analysis to understand how visualization is used to convey ideas in the scientific literature.
Part of the Myria project, RACO (the Relational Algebra COmpiler) is a polystore middleware system that provides query translation, optimization, and orchestration across complex multi-system...
Working at the intersection of network science, databases, and high-performance computing, we developed a series of novel parallel algorithms based on Infomap serial graph clustering...
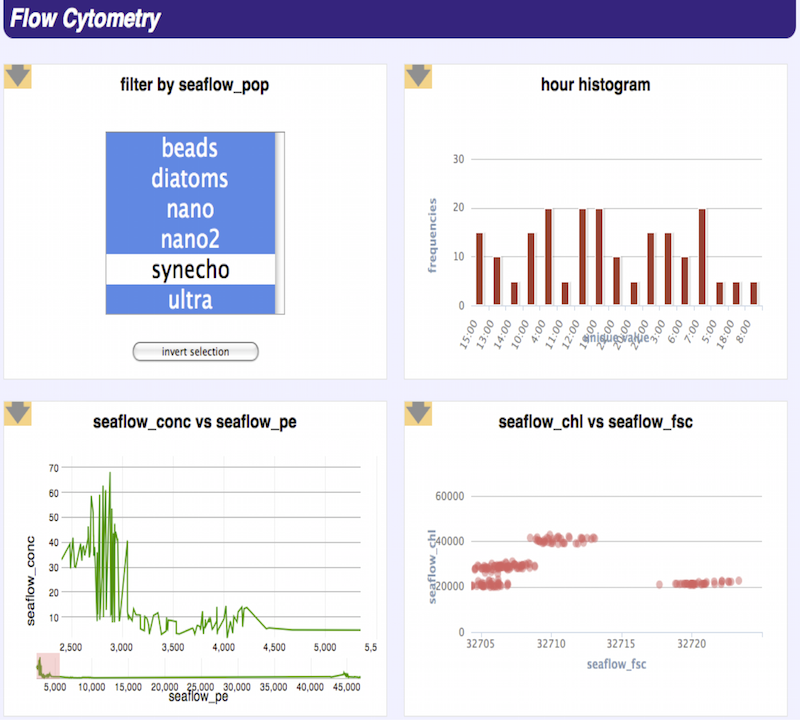
We have developed algorithms, methods, systems, and applications in support of the Seaflow project in the Armbrust Lab in the UW department of Oceanography.
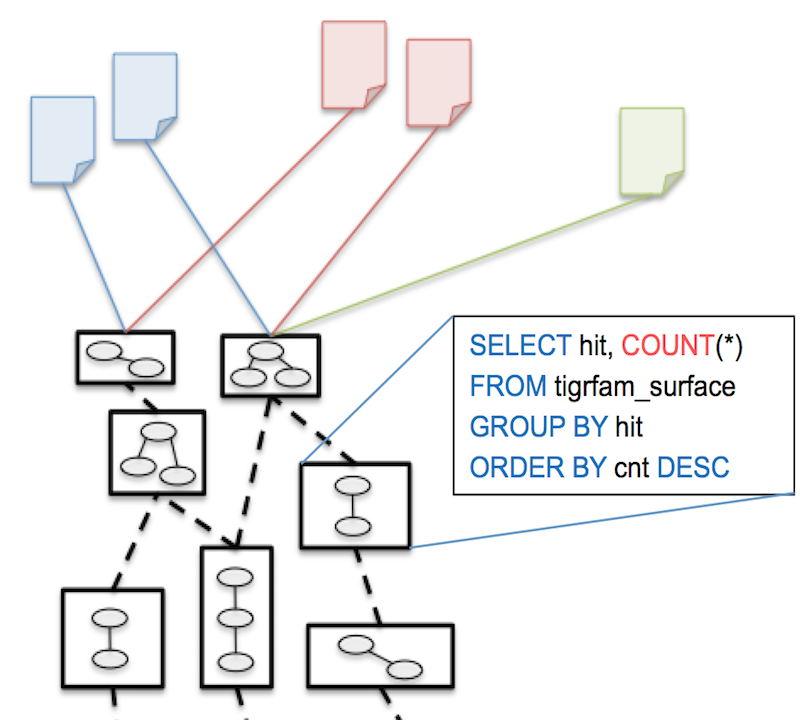
SQLShare aims to increase uptake of databases in data science and shed light on how data scientists work with data
VizDeck recommends visualizations based on the statistical properties of the data tempered by perception heuristics. Dashboards are assembled through a card-game UI.
With funding from EMC and NSF, we explore new approaches to scalable visualization making use of large-scale database and dataflow engines.
See all projects...
This webpage was built with Bootstrap and Jekyll. You can find the source code here. Last updated: Sep 10, 2018