Research Overview
Universality and Average-Case Algorithm Runtimes
Let H > 0 be a positive-definite N × N matrix, and let x0 be an N-dimensional random vector. The power method to compute the largest eigenvalue of H iterates:
- yj = xj−1 / ‖xj−1‖2
- xj = H yj
- μj = xj* yj
Then μj → λmax as j → ∞. With P. Deift, we considered H = X X*/M as a sample covariance matrix with independent entries having mean zero and variance one.
Theorem: There exists a distribution function Fβgap(t) and a constant c depending only on d such that the rescaled halting time converges in distribution. The distribution is identified as the limiting distribution of the inverse of the top gap in the real (β = 1) and complex (β = 2) cases, giving both universality and average-case behavior. Similar results hold for the inverse power method, the QR algorithm, and the Toda algorithm.
Gibbs Phenomenon in PDEs
Consider the initial value problem i qt = ω(−i ∂x) q on ℝ × (0, T), with q(x, 0) = qo(x). When qo is piecewise continuous, with G. Biondini I found a short-time expansion computable numerically with high accuracy.
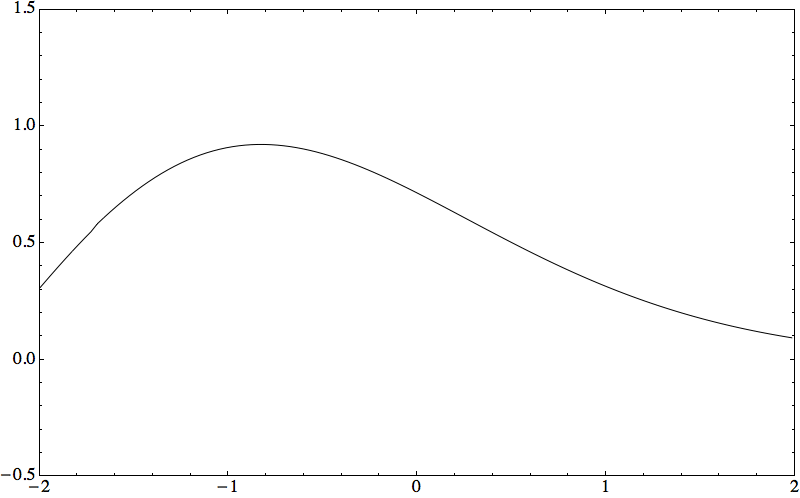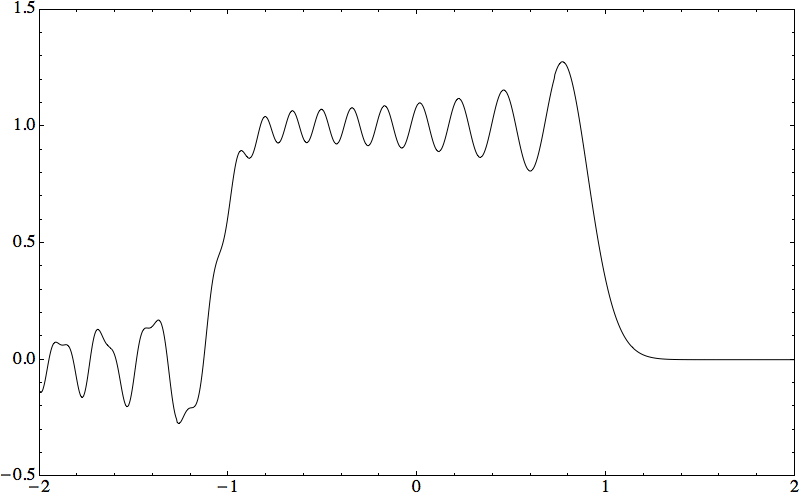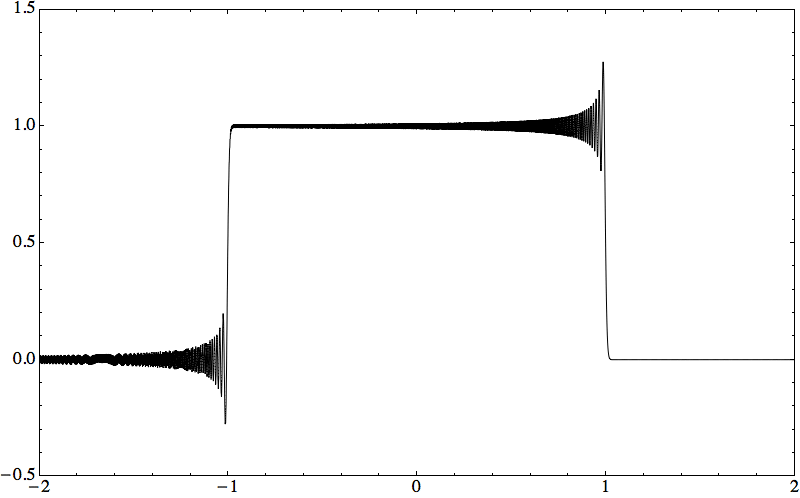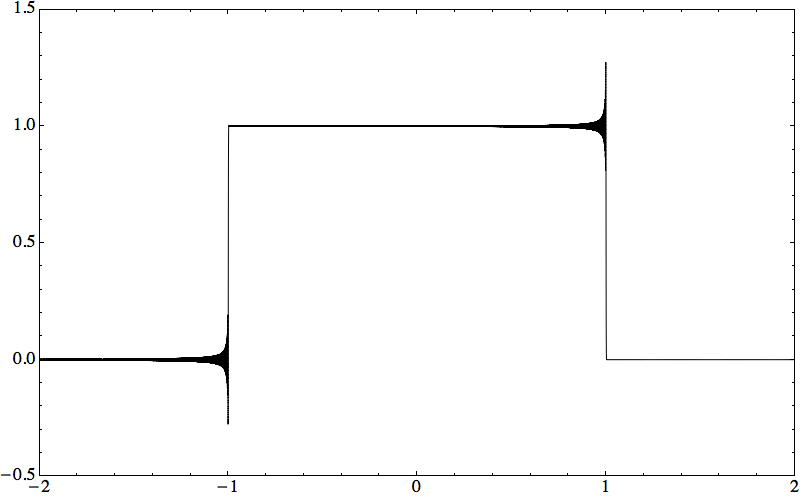
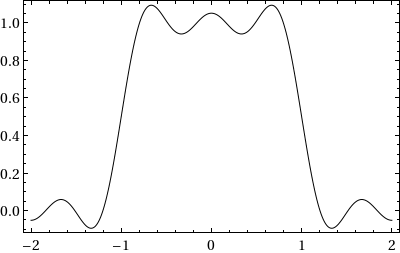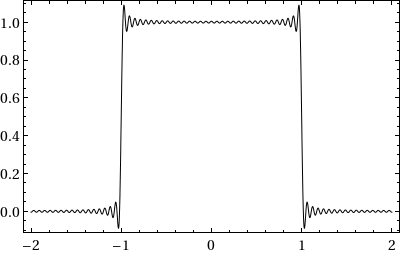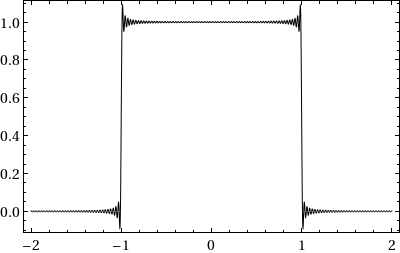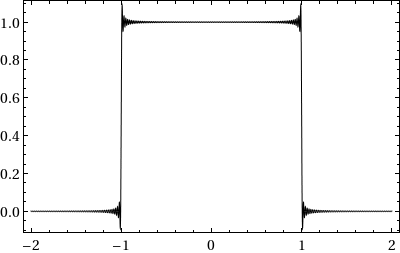
Theorem: Let qn(x, t) solve i qt = (−i ∂x)n q with step initial condition. Then the same Wilbraham–Gibbs constant governs overshoots and undershoots of the PDE solution near discontinuities.
Numerical Nonlinear Steepest Descent
Effective computation of the inverse scattering transform, orthogonal polynomials, Painlevé transcendents, and other nonlinear special functions is accomplished by combining Deift–Zhou nonlinear steepest descent with a numerical Riemann–Hilbert solver. This produces uniformly and spectrally convergent approximations over large parameter ranges.
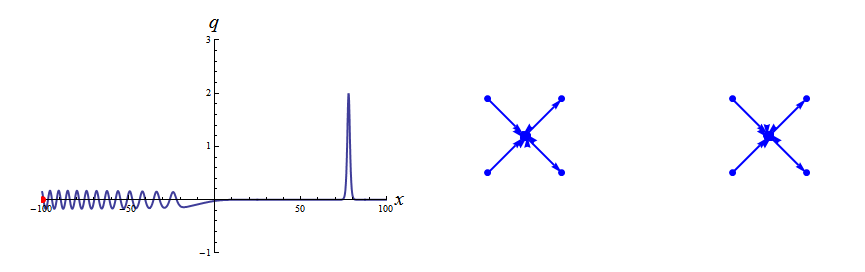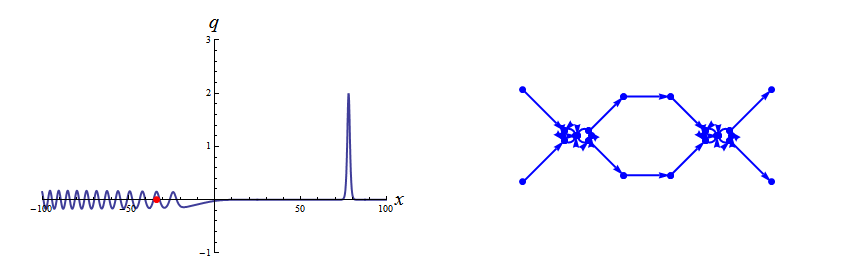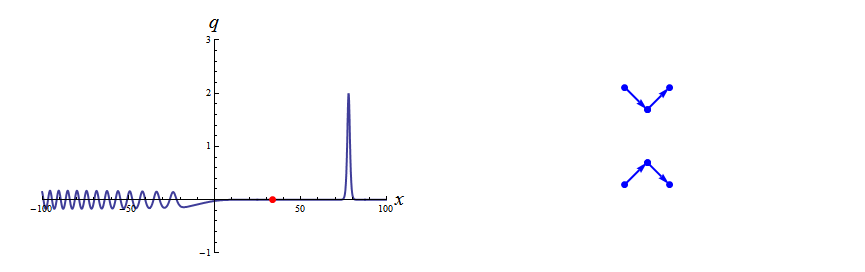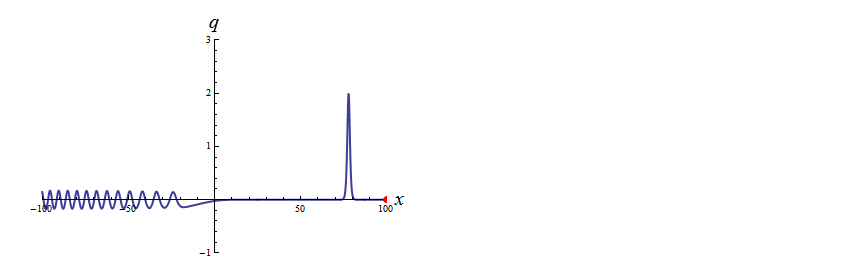
Finite-Genus KdV
Riemann–Hilbert methods yield representations of finite-genus KdV solutions as an alternative to the classical theta function approach, by converting scalar functions on a hyperelliptic Riemann surface into vector-valued functions on a cut complex plane.

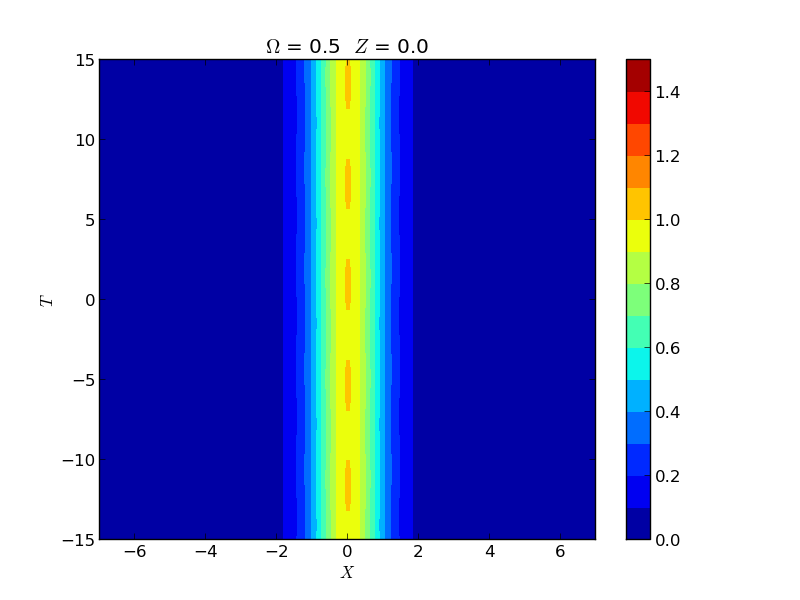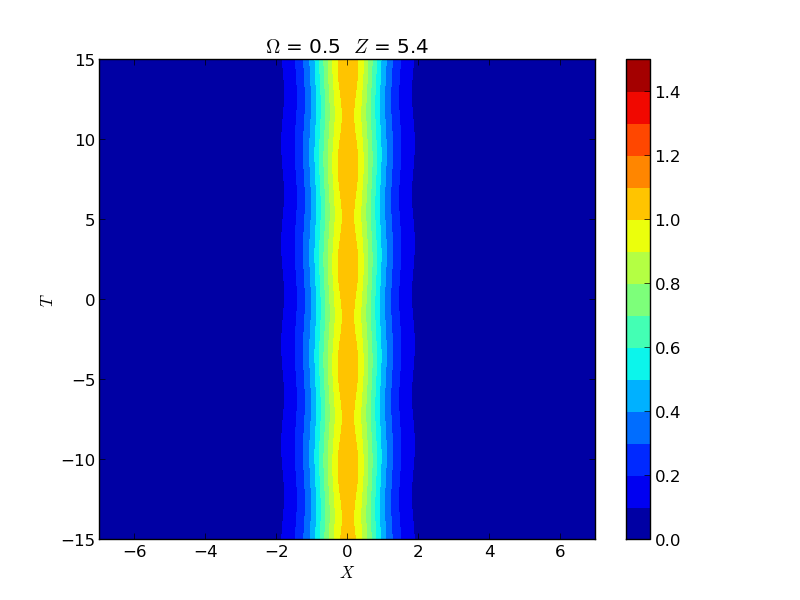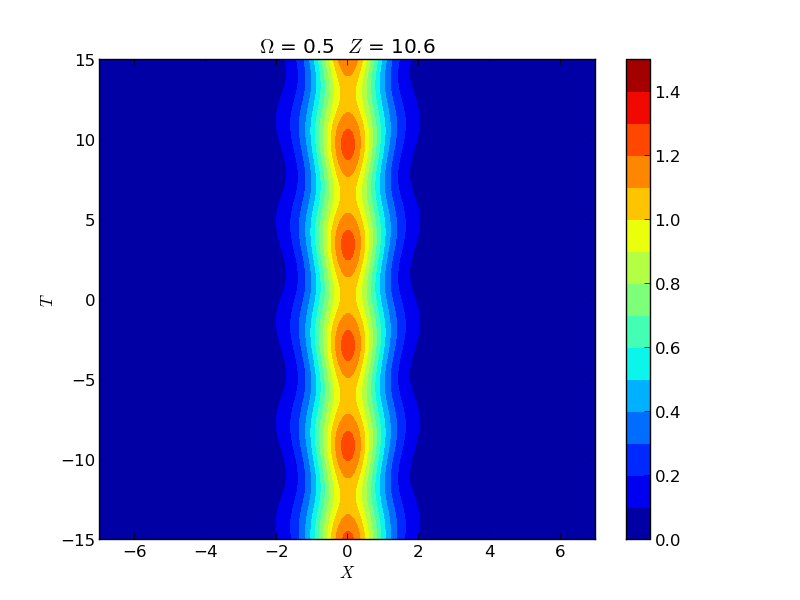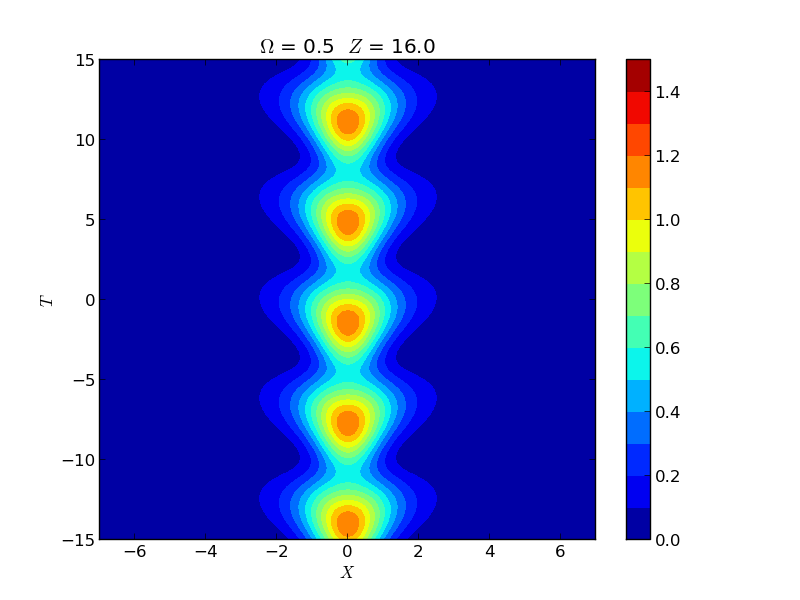
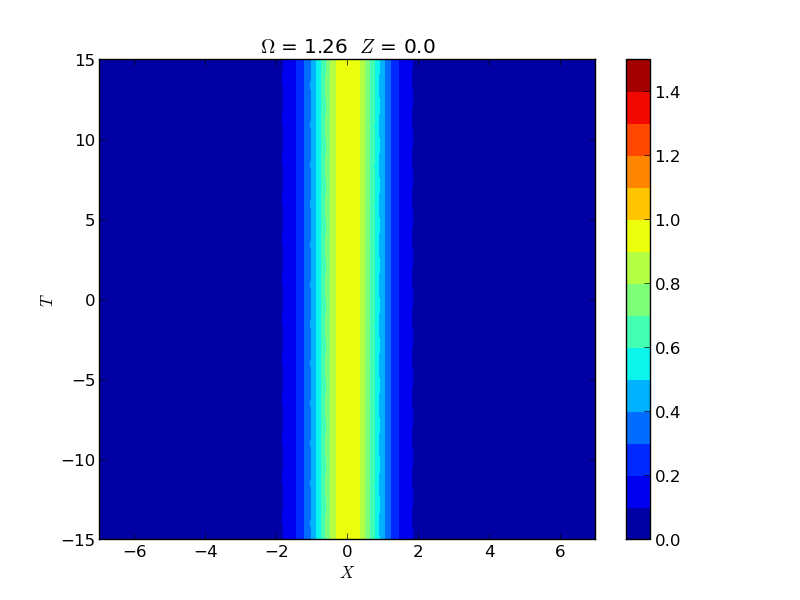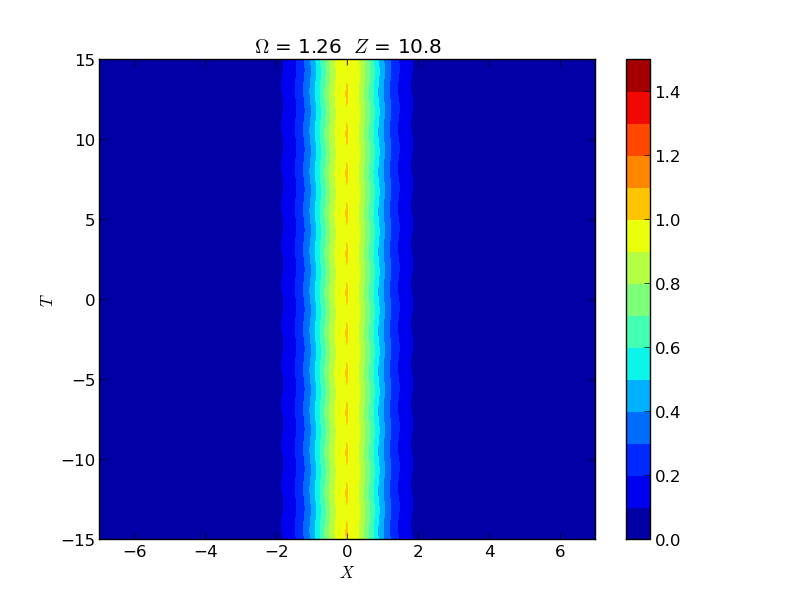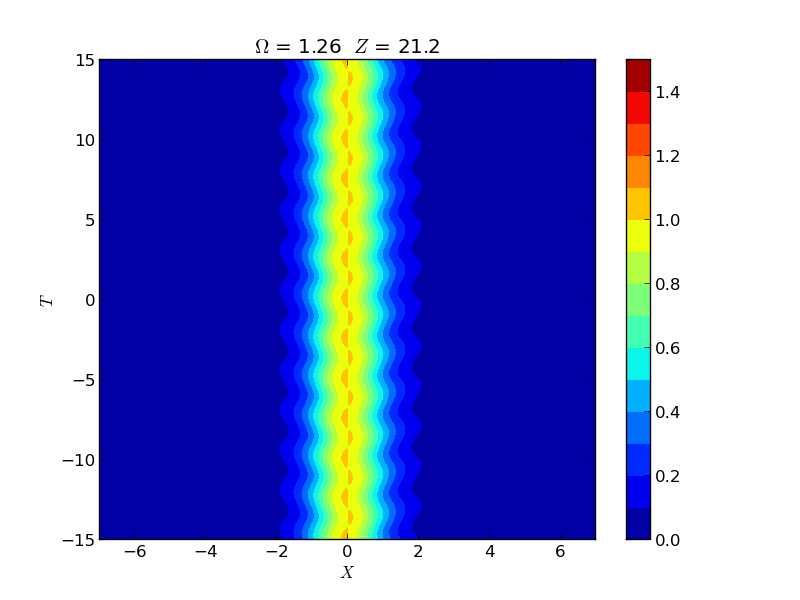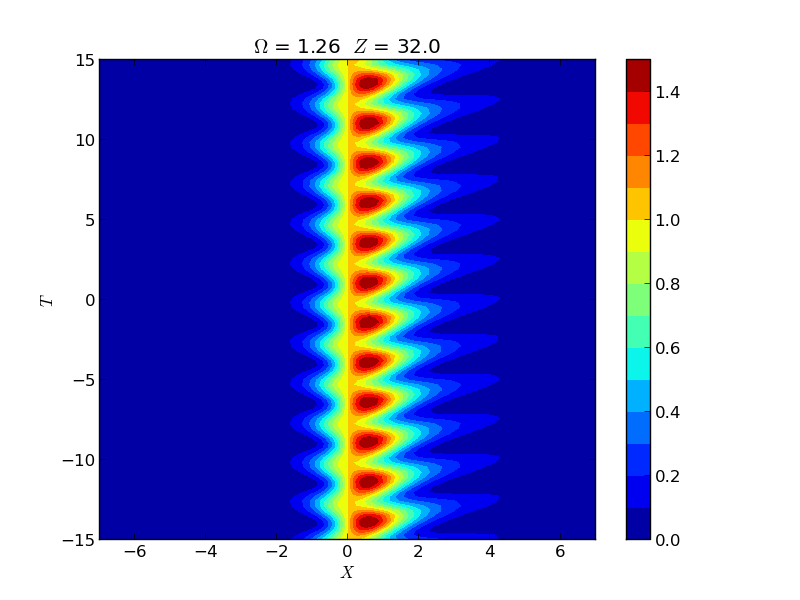
Instability of Spatial Solitons
Instabilities of spatial solitons in a (2+1)-dimensional nonlinear Schrödinger equation were studied via Hill's method, capturing growth rates in the snake, oscillatory snake, and oscillatory neck instability regions. These rates were experimentally verified by the group of M. Haelterman using a 2D waveguide array.