
Interface Architecture
While the previous chapter discussed many of the seminal interaction paradigms we have invented for interacting with computers, we’ve discussed little about how all of the widgets, interaction paradigms, and other user interface ideas are actually implemented as software. This knowledge is obviously important for developers who implement buttons, scroll bars, gestures, and so on, but is this knowledge important for anyone else?
I argue yes. Much like a violinist needs to know whether a bow’s strings are made from synthetic materials or Siberian horse tail, a precise understanding of user interface implementation allows designers to have a precise understanding of how to compose widgets into user experiences. This helps designers and engineers to:
- Analyze limitations of interfaces
- Predict edge cases in their behavior, and
- Discuss their behavior precisely.
Knowing, for example, that a button only invokes its command after the mouse button is released allows one to reason about the assumptions a button makes about ability . The ability to hold a mouse button down, for example, isn’t something that all people have, whether due to limited finger strength, motor tremors that lead to accidental button releases, or other motor-physical limitations. These details allow designers to fully control what you make and how it behaves.
Knowledge of user interface implementation might also be important if you want to invent new interface paradigms. A low-level of user interface implementation knowledge allows you to see exactly how current interfaces are limited, and empowers you to envision new interfaces that don’t have those limitations. For example, when Apple redesigned their keyboards to have shallower (and reviled) depth , their design team needed deeper knowledge than just “pushing a key sends a key code to the operating system.” They needed to know the physical mechanisms that afford depressing a key, the tactile feedback those mechanisms provide, and the auditory feedback that users rely on to confirm they’ve pressed a key. Expertise in these physical qualities of the hardware interface of a keyboard was essential to designing a new keyboard experience.
Precise technical knowledge of user interface implementation also allows designers and engineers to have a shared vocabulary to communicate about interfaces. Designers should feel empowered to converse about interface implementation with engineers, knowing enough to critique designs and convey alternatives. Without this vocabulary and a grasp of these concepts, engineers retain power over user interface design, even though they aren’t trained to design interfaces.
States and Events
There are many levels at which designers might want to understand user interface implementation. The lowest—code—is probably too low level to be useful for the purposes above. Not everyone needs to understand, for example, the source code implementations of all of Windows or macOS’s widgets. Instead, here we will discuss user interface implementation at the architectural level. In software engineering, architecture is a high level view of code’s behavior: how it is organized into different units with a shared purpose, how data moves between different units, and which of these units is in charge of making decisions about how to respond to user interactions.
To illustrate this notion of architecture, let’s return to the example of a graphical user interface button. We’ve all used buttons, but rarely do we think about exactly how they work. Here is the architecture of a simple button, depicted diagrammatically:
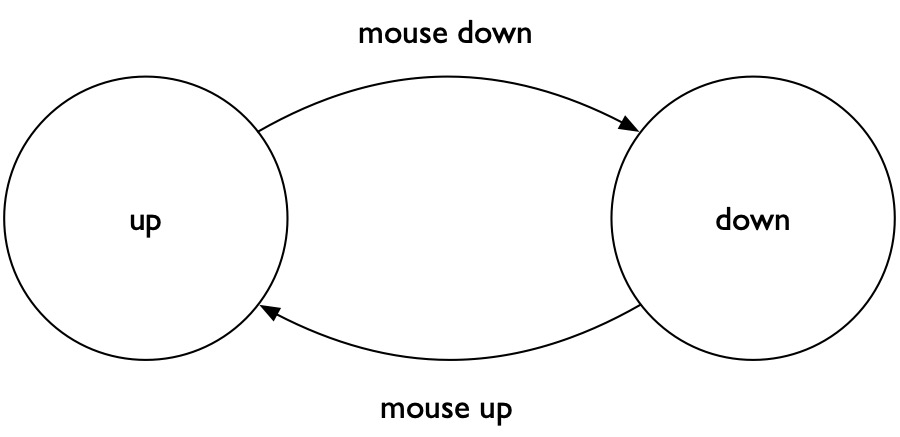
Computer scientists call this diagram a state machine , which is an abstract representation of different statestate: A particular mode or configuration of a user interface that can be changed through user input. For example, a button might be hovered over or not, or user on a web page might be logged in or not. that a computer program might be in. State machines also indicate the inputs that the can receive that cause them to move between different states. The button state machine above has two possible states: up (on the left) and down (on the right). In this state machine, there are two inputs that can cause changes in states. In user interface toolkits, these inputs are usually call eventsevent: A user input such as a mouse click, tap, drag, or verbal utterance that may trigger a state change in a user interface’s state. , because they are things that users do at a particular point in time. The first event is when the button receives a mouse down event, after a user clicks a mouse button while the pointer is over the button. This event causes the state machine to transition from the up state to the down state. The button stays in this state until it later receives a mouse up event from the user, when they release the mouse button; this causes the button to transition to the up state and also executes its command. This is about as simple as button statement machines get.
Representing a state machine in code involves translating the abstract logic as in the diagram above into a programming language and user interface toolkit. For example, here is an implementation of the button above in JavaScript, using the popular React framework:
class MyFancyNewButton extends React.Component {
// This function changes the button's "down" state to false.
// The function "setState" is a powerful React function, which
// tells React to update the state, and at some point in the future,
// call the "render" function below to update the view. It
// then executes the command for the button.
handleUp() {
this.setState({down: false});
this.executeCommand();
}
// Like "handleUp", this function changes the "down" state,
// but to true, and also causes React to call the "render"
// function below to update the view.
handleDown() {
this.setState({down: true});
}
executeCommand() {
// Do something exciting when clicked!
}
// This function renders the presentation of the button
// based on the value of the "down" property. If it's true,
// it renders a dark gray rectangle and the label "I'm down";
// if it's false, it renders a light gray rectangle
// with the label "I'm up".
render() {
if(this.state.down)
return <div
style={{background: "darkGrey"}}
onMouseUp={this.handleUp}>
I'm down!
</div>
else
return <div
style={{background: "lightGrey"}}
onMouseDown={this.handleDown}>
I'm up!
</div>
}
} To understand the code above, the comments marked with the text // are your guide. The render() function at the bottom describes how the button should appear in its two different states: dark grey with the text “I’m down” when in the down state and light gray with the text “I’m up” in the up state. Notice how the handleUp() and handleDown() functions are assigned to the onMouseUp and onMouseDown event handlers. These functions will execute when the button receives those corresponding events, changing the button’s state (and its corresponding appearance) and executing executeCommand() . This function could do anything — submit a form, display a message, compute something — but it currently does nothing. None of this implementation is magic — in fact, we can change the state machine by changing any of the code above, and produce a button with very different behavior. The rest of the details are just particular ways that JavaScript code must be written and particular ways that React expects JavaScript code to be organized and called; all can be safely ignored, as they do not affect the button’s underlying architecture, and could have been written in any other programming language with any other user interface toolkit.
The buttons in modern operating systems actually have much more complex state machines than the one above. Consider, for example, what happens if the button is in a down state, but the mouse cursor moves outside the boundary of the button and then a mouse up event occurs. When this happens, it transitions to the up state, but does not execute the button’s command. (Try this on a touchscreen: tap on a button, slide your finger away from it, then release, and you’ll see the button’s command isn’t executed). Some buttons have an inactive state, in which they will not respond to any events until made active. If the button supports touch input, then a button’s state machine also needs to handle touch events in addition to mouse events. And to be accessible to people who rely on keyboards, buttons also need to have a focused and unfocused state and respond to things like the space or enter key being typed while focused. All of these additional states and events add more complexity to a button’s state machine.
All user interface widgets are implemented in similar ways, defining a set of states and events that cause transitions between those states. Scroll bar handles respond to mouse down , drag , and mouse up events, text boxes respond to keypress events, links respond to mouse down and mouse up events. Even text in a web browser or text editor response to mouse down , drag , and mouse up events to enter a text selection state.
Model-View-Controller
State machines are only part of implementing a widget, the part that encodes the logic of how a widget responds to user input. What about how the widget is presented visually, or how bits of data are stored, such as the text in a text field or the current position of a scroll bar?
The dominant way to implement these aspects of widgets, along with the state machines that determine their behavior, is to follow a model-view-controllermodel-view-controller: A way of organizing a user interface implementation to separate how data is stored (the model), how data is presented (the view), and how data is changed in response to user input (the controller). (MVC) architecture. One can think of MVC as a division of responsibilities in code between storing and retrieving data (the model ), presenting data and listening for user input (the view ), and managing the interaction between the data storage and the presentation using the state machine (the controller ). This architecture is ubiquitous in user interface implementation.
To illustrate how the architecture works, let’s consider a non-user interface example. Think about the signs that are often displayed on gas station or movie theaters. Something is responsible for storing the content that will be shown on the signs; perhaps this is a piece of paper with a message, or a particularly organized gas station owner has a list of ideas for sign messages stored in a notebook. Whatever the storage medium, this is the model . Someone else is responsible for putting the content on the signs based on whatever is in the model; this is the view responsibility. And, of course, someone is in charge of deciding when to retrieve a new message from the model and telling the person in charge of the view to update the sign. This person is the controller .
In the same way as in the example above, MVC architectures in user interfaces take an individual part of an interface (e.g., a button, a form, a progress bar, or even some complex interactive data visualization on a news website) and divide its implementation into these three parts. For example, consider the example below of a post on a social media site like Facebook:
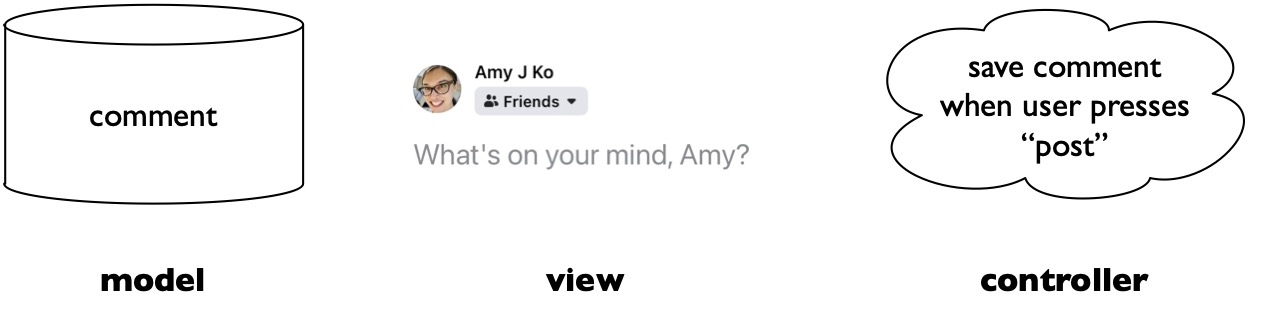
In this interface:
- The model stores the data that a user interface is presenting. For example, in the figure above, this would be the comment that someone is typing and posting. In the case of social media, the model might include both the part of memory storing the comment being typed, but also the database stored on Facebook’s servers that persists the comment for later display.
- The view visualizes the data in the model. For example, in the figure above, this includes the text field for the comment, but also the profile image, the privacy drop down menu, and the name. The view’s job is to render these controls, listen for input from the user (e.g., pressing the post button to submit the comment), and display any output the controller decides to provide (e.g., feedback about links in the post).
- The controller makes decisions about how to handle user input and how to update the model. In our comment example above, that includes validating the comment (e.g., it can’t be empty), and submitting the comment when the user presses enter or the post button. The controller gets and set data in the model when necessary and tells the view to update itself as the model changes.
View Hierarchies
If every individual widget in a user interface is its own self-contained model-view-controller architecture, how are all of these individual widgets composed together into a user interface? There are three big ideas that stitch together individual widgets into an entire interface.
First, all user interfaces are structured as hierarchies in which one widget can contain zero or more other “child” widgets, and each widget has a parent, except for the “root” widget (usually a window). For instance, here’s the Facebook post UI we were discussing earlier and its corresponding hierarchy:
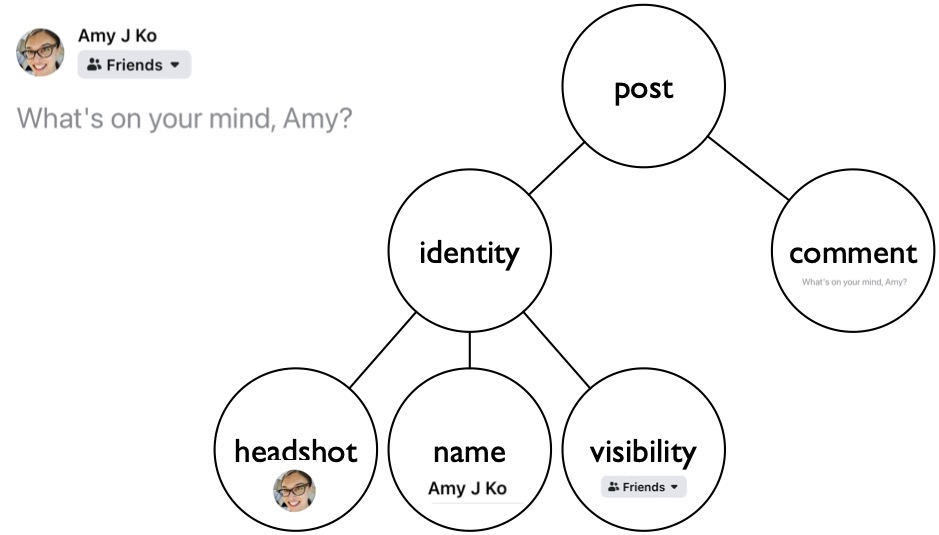
Notice how there are some components in the tree above that aren’t visible in the UI (the “post”, the “editor”, the “special input” container). Each of these are essentially containers that group components together. These containers are used to give widgets a layout , in which the children of each component are organized spatially according to some layout rule. For example, the special input widgets are laid out in a horizontal row within the special inputs container and the special inputs container itself is laid out right aligned in the “editor” container. Each component has its own layout rules that govern the display of its children.
Finally, event propagation is the process by which user interface events move from a physical device to a particular user interface component in a larger view hierarchy. Each device has its own process, because it has its own semantics. For instance:
- A mouse emits mouse move events and button presses and releases. All of these are emitted as discrete hardware events to the operating system. Some events are aggregated into synthetic events like a click (which is really a mouse press followed by a mouse release, but not a discrete event a mouse’s hardware). When the operating system receives events, it first decides which window will receive those events by comparing the position of the mouse to the position and layering of the windows, finding the topmost window that contains the mouse position. Then, the window decides which component will handle the event by finding the topmost component whose spatial boundaries contain the mouse. That event is then sent to that component. If the component doesn’t handle the event (e.g., someone clicks on some text in a web browser that doesn’t respond to clicks), the event may be propagated to its parent, and to its parent’s parent, etc, seeing if any of the ancestors in the component hierarchy want to handle the event. Every user interface framework handles this propagation slightly differently, but most follow this basic pattern.
- A keyboard emits key down and key up events, each with a key code that corresponds to the physical key that was pressed. As with a mouse, sequences are synthesized into other events (e.g., a key down followed by a key up with the same key is a key “press”). Whereas a mouse has a position, a keyboard does not, and so operating systems maintain a notion of window focus to determine which window is receiving key events, and then each window maintains a notion of keyboard focus to determine which component receives key events. Operating systems are then responsible for providing a visible indicator of which component has keyboard focus (perhaps giving it a border highlight and showing a blinking text caret). As with mouse events, if the component with focus does not handle a keyboard event, it may be propagated to its ancestors and handled by one of them. For example, when you press the escape key when a confirmation dialog is in focus, the button that has focus will ignore it, but the dialog window may interpret the escape key press as a “cancel”.
- A touch screen emits a stream of touch events, segmented by start, move, and end events. Other events include touch cancel events, such as when you slide your finger off of a screen to indicate you no longer want to touch. This low-level stream of events is converted by operating systems and applications into touch gestures. Most operating systems recognize a class of gestures and emit events for them as well, allowing user interface controls to respond to them.
- Even speech interfaces emit events. For example, digital voice assistants are continuously listening for activation commands such as “Hey Siri” or “Alexa.” After these are detected, they begin converting speech into text, which is then matched to one or more commands. Applications that expose a set of commands then receive events that trigger the application to process the command. Therefore, the notion of input events isn’t inherently tactile; it’s more generally about translating low-level inputs into high-level commands.
Every time a new input device has been invented, user interface designers and engineers have had to define new types of events and event propagation rules to decide how inputs will be handled by views within a larger view hierarchy.
Advances in Architecture
While the basic ideas presented above are now ubiquitous in desktop and mobile operating systems, the field of HCI has rapidly innovated beyond these original ideas. For instance, much of the research in the 1990’s focused on building more robust, scalable, flexible, and powerful user interface toolkits for building desktop interfaces. The Amulet toolkit was one of the most notable of these, offering a unified framework for supporting graphical objects, animation, input, output, commands, and undo 23 23 Myers, Brad A., Richard G. McDaniel, Robert C. Miller, Alan S. Ferrency, Andrew Faulring, Bruce D. Kyle, Andrew Mickish, Alex Klimovitski, Patrick Doane (1997). The Amulet environment: New models for effective user interface software development. IEEE Transactions on Software Engineering.
Krishna A. Bharat and Scott E. Hudson (1995). Supporting distributed, concurrent, one-way constraints in user interface applications. In Proceedings of the 8th annual ACM symposium on User interface and software technology (UIST '95).
Scott E. Hudson and Ian Smith (1996). Ultra-lightweight constraints. ACM Symposium on User Interface Software and Technology (UIST).
Scott E. Hudson and Ian Smith (1997). Supporting dynamic downloadable appearances in an extensible user interface toolkit. ACM Symposium on User Interface Software and Technology (UIST).
Research in the 2000’s shifted to deepen these ideas. For example, some work investigated alternatives to component hierarchies such as scene graphs 16 16 Stéphane Huot, Cédric Dumas, Pierre Dragicevic, Jean-Daniel Fekete, Gerard Hégron (2004). The MaggLite post-WIMP toolkit: draw it, connect it and run it. ACM Symposium on User Interface Software and Technology (UIST).
Eric Lecolinet (2003). A molecular architecture for creating advanced GUIs. ACM Symposium on User Interface Software and Technology (UIST).
W. Keith Edwards, Takeo Igarashi, Anthony LaMarca, Elizabeth D. Mynatt (2000). A temporal model for multi-level undo and redo. ACM Symposium on User Interface Software and Technology (UIST).
Other research has looked beyond traditional WIMP interfaces, creating new architectures to support new media. The DART toolkit, for example, invented several abstractions for augmented reality applications 9 9 Gandy, M., & MacIntyre, B. (2014). Designer's augmented reality toolkit, ten years later: implications for new media authoring tools. In Proceedings of the 27th annual ACM symposium on User interface software and technology (pp. 627-636).
Jason I. Hong and James A. Landay (2000). SATIN: a toolkit for informal ink-based applications. ACM Symposium on User Interface Software and Technology (UIST).
Benjamin B. Bederson, Jon Meyer, Lance Good (2000). Jazz: an extensible zoomable user interface graphics toolkit in Java. ACM Symposium on User Interface Software and Technology (UIST).
Tara Matthews, Anind K. Dey, Jennifer Mankoff, Scott Carter, Tye Rattenbury (2004). A toolkit for managing user attention in peripheral displays. ACM Symposium on User Interface Software and Technology (UIST).
Michael Bostock and Jeffrey Heer (2009). Protovis: A Graphical Toolkit for Visualization. IEEE Transactions on Visualizations and Computer Graphics.
Saul Greenberg and Chester Fitchett (2001). Phidgets: easy development of physical interfaces through physical widgets. ACM Symposium on User Interface Software and Technology (UIST).
Scott R. Klemmer, Jack Li, James Lin, James A. Landay (2004). Papier-Mache: toolkit support for tangible input. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
Nicolai Marquardt, Robert Diaz-Marino, Sebastian Boring, Saul Greenberg (2011). The proximity toolkit: prototyping proxemic interactions in ubiquitous computing ecologies. ACM Symposium on User Interface Software and Technology (UIST).
Kenrick Kin, Bjoern Hartmann, Tony DeRose, Maneesh Agrawala (2012). Proton++: a customizable declarative multitouch framework. ACM Symposium on User Interface Software and Technology (UIST).
Scott E. Hudson and Gary L. Newell (1992). Probabilistic state machines: dialog management for inputs with uncertainty. ACM Symposium on User Interface Software and Technology (UIST).
Jennifer Mankoff, Scott E. Hudson, Gregory D. Abowd (2000). Interaction techniques for ambiguity resolution in recognition-based interfaces. ACM Symposium on User Interface Software and Technology (UIST).
Julia Schwarz, Scott Hudson, Jennifer Mankoff, Andrew D. Wilson (2010). A framework for robust and flexible handling of inputs with uncertainty. ACM Symposium on User Interface Software and Technology (UIST).
While much of the work in user interface architecture has sought to contribute new architectural ideas for user interface construction, some have focused on ways of modifying user interfaces without modifying their underlying code. For example, one line of work has explored how to express interfaces abstractly, so these abstract specifications can be used to generate many possible interfaces depending on which device is being used 7,25,26 7 W. Keith Edwards and Elizabeth D. Mynatt (1994). An architecture for transforming graphical interfaces. ACM Symposium on User Interface Software and Technology (UIST).
Jeffrey Nichols, Brad A. Myers, Michael Higgins, Joseph Hughes, Thomas K. Harris, Roni Rosenfeld, Mathilde Pignol (2002). Generating remote control interfaces for complex appliances. ACM Symposium on User Interface Software and Technology (UIST).
Jeffrey Nichols, Brandon Rothrock, Duen Horng Chau, Brad A. Myers (2006). Huddle: automatically generating interfaces for systems of multiple connected appliances. ACM Symposium on User Interface Software and Technology (UIST).
James R. Eagan, Michel Beaudouin-Lafon, Wendy E. Mackay (2011). Cracking the cocoa nut: user interface programming at runtime. ACM Symposium on User Interface Software and Technology (UIST).
Wolfgang Stuerzlinger, Olivier Chapuis, Dusty Phillips, Nicolas Roussel (2006). User interface facades: towards fully adaptable user interfaces. ACM Symposium on User Interface Software and Technology (UIST).
W. Keith Edwards, Scott E. Hudson, Joshua Marinacci, Roy Rodenstein, Thomas Rodriguez, Ian Smith (1997). Systematic output modification in a 2D user interface toolkit. ACM Symposium on User Interface Software and Technology (UIST).
Amanda Swearngin, Amy J. Ko, James Fogarty (2017). Genie: Input Retargeting on the Web through Command Reverse Engineering. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
A smaller but equally important body of work has investigated ways of making interfaces easier to test and debug. Some of these systems expose information about events, event handling, and finite state machine state 15 15 Scott E. Hudson, Roy Rodenstein, Ian Smith (1997). Debugging lenses: a new class of transparent tools for user interface debugging. ACM Symposium on User Interface Software and Technology (UIST).
Brian Burg, Richard Bailey, Amy J. Ko, Michael D. Ernst (2013). Interactive record/replay for web application debugging. ACM Symposium on User Interface Software and Technology (UIST).
Mark W. Newman, Mark S. Ackerman, Jungwoo Kim, Atul Prakash, Zhenan Hong, Jacob Mandel, Tao Dong (2010). Bringing the field into the lab: supporting capture and replay of contextual data for the design of context-aware applications. ACM Symposium on User Interface Software and Technology (UIST).
Franziska Roesner, James Fogarty, Tadayoshi Kohno (2012). User interface toolkit mechanisms for securing interface elements. ACM Symposium on User Interface Software and Technology (UIST).
Conclusion
Considering this body of work as a whole, there are some patterns that become clear:
- Model-view-controller is a ubiquitous architectural style in user interface implementation.
- User interface toolkits are essential to making it easy to implement interfaces.
- New input techniques require new user interface architectures, and therefore new user interface toolkits.
- Interfaces can be automatically generated, manipulated, inspected, and transformed, but only within the limits of the architecture in which they are implemented.
- The architecture an interface is built in determines what is difficult to test and debug.
These “laws” of user interface implementation can be useful for making predictions about the future. For example, if someone proposes incorporating a new sensor in a device, subtle details in the sensor’s interactive potential may require new forms of testing and debugging, new architectures, and potentially new toolkits to fully leverage its potential. That’s a powerful prediction to be able to make and one that many organizations overlook when they ship new devices.
References
-
Benjamin B. Bederson, Jon Meyer, Lance Good (2000). Jazz: an extensible zoomable user interface graphics toolkit in Java. ACM Symposium on User Interface Software and Technology (UIST).
-
Krishna A. Bharat and Scott E. Hudson (1995). Supporting distributed, concurrent, one-way constraints in user interface applications. In Proceedings of the 8th annual ACM symposium on User interface and software technology (UIST '95).
-
Michael Bostock and Jeffrey Heer (2009). Protovis: A Graphical Toolkit for Visualization. IEEE Transactions on Visualizations and Computer Graphics.
-
Brian Burg, Richard Bailey, Amy J. Ko, Michael D. Ernst (2013). Interactive record/replay for web application debugging. ACM Symposium on User Interface Software and Technology (UIST).
-
James R. Eagan, Michel Beaudouin-Lafon, Wendy E. Mackay (2011). Cracking the cocoa nut: user interface programming at runtime. ACM Symposium on User Interface Software and Technology (UIST).
-
W. Keith Edwards, Takeo Igarashi, Anthony LaMarca, Elizabeth D. Mynatt (2000). A temporal model for multi-level undo and redo. ACM Symposium on User Interface Software and Technology (UIST).
-
W. Keith Edwards and Elizabeth D. Mynatt (1994). An architecture for transforming graphical interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
W. Keith Edwards, Scott E. Hudson, Joshua Marinacci, Roy Rodenstein, Thomas Rodriguez, Ian Smith (1997). Systematic output modification in a 2D user interface toolkit. ACM Symposium on User Interface Software and Technology (UIST).
-
Gandy, M., & MacIntyre, B. (2014). Designer's augmented reality toolkit, ten years later: implications for new media authoring tools. In Proceedings of the 27th annual ACM symposium on User interface software and technology (pp. 627-636).
-
Saul Greenberg and Chester Fitchett (2001). Phidgets: easy development of physical interfaces through physical widgets. ACM Symposium on User Interface Software and Technology (UIST).
-
Jason I. Hong and James A. Landay (2000). SATIN: a toolkit for informal ink-based applications. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson and Gary L. Newell (1992). Probabilistic state machines: dialog management for inputs with uncertainty. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson and Ian Smith (1996). Ultra-lightweight constraints. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson and Ian Smith (1997). Supporting dynamic downloadable appearances in an extensible user interface toolkit. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott E. Hudson, Roy Rodenstein, Ian Smith (1997). Debugging lenses: a new class of transparent tools for user interface debugging. ACM Symposium on User Interface Software and Technology (UIST).
-
Stéphane Huot, Cédric Dumas, Pierre Dragicevic, Jean-Daniel Fekete, Gerard Hégron (2004). The MaggLite post-WIMP toolkit: draw it, connect it and run it. ACM Symposium on User Interface Software and Technology (UIST).
-
Kenrick Kin, Bjoern Hartmann, Tony DeRose, Maneesh Agrawala (2012). Proton++: a customizable declarative multitouch framework. ACM Symposium on User Interface Software and Technology (UIST).
-
Scott R. Klemmer, Jack Li, James Lin, James A. Landay (2004). Papier-Mache: toolkit support for tangible input. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).
-
Eric Lecolinet (2003). A molecular architecture for creating advanced GUIs. ACM Symposium on User Interface Software and Technology (UIST).
-
Jennifer Mankoff, Scott E. Hudson, Gregory D. Abowd (2000). Interaction techniques for ambiguity resolution in recognition-based interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Nicolai Marquardt, Robert Diaz-Marino, Sebastian Boring, Saul Greenberg (2011). The proximity toolkit: prototyping proxemic interactions in ubiquitous computing ecologies. ACM Symposium on User Interface Software and Technology (UIST).
-
Tara Matthews, Anind K. Dey, Jennifer Mankoff, Scott Carter, Tye Rattenbury (2004). A toolkit for managing user attention in peripheral displays. ACM Symposium on User Interface Software and Technology (UIST).
-
Myers, Brad A., Richard G. McDaniel, Robert C. Miller, Alan S. Ferrency, Andrew Faulring, Bruce D. Kyle, Andrew Mickish, Alex Klimovitski, Patrick Doane (1997). The Amulet environment: New models for effective user interface software development. IEEE Transactions on Software Engineering.
-
Mark W. Newman, Mark S. Ackerman, Jungwoo Kim, Atul Prakash, Zhenan Hong, Jacob Mandel, Tao Dong (2010). Bringing the field into the lab: supporting capture and replay of contextual data for the design of context-aware applications. ACM Symposium on User Interface Software and Technology (UIST).
-
Jeffrey Nichols, Brad A. Myers, Michael Higgins, Joseph Hughes, Thomas K. Harris, Roni Rosenfeld, Mathilde Pignol (2002). Generating remote control interfaces for complex appliances. ACM Symposium on User Interface Software and Technology (UIST).
-
Jeffrey Nichols, Brandon Rothrock, Duen Horng Chau, Brad A. Myers (2006). Huddle: automatically generating interfaces for systems of multiple connected appliances. ACM Symposium on User Interface Software and Technology (UIST).
-
Franziska Roesner, James Fogarty, Tadayoshi Kohno (2012). User interface toolkit mechanisms for securing interface elements. ACM Symposium on User Interface Software and Technology (UIST).
-
Julia Schwarz, Scott Hudson, Jennifer Mankoff, Andrew D. Wilson (2010). A framework for robust and flexible handling of inputs with uncertainty. ACM Symposium on User Interface Software and Technology (UIST).
-
Wolfgang Stuerzlinger, Olivier Chapuis, Dusty Phillips, Nicolas Roussel (2006). User interface facades: towards fully adaptable user interfaces. ACM Symposium on User Interface Software and Technology (UIST).
-
Amanda Swearngin, Amy J. Ko, James Fogarty (2017). Genie: Input Retargeting on the Web through Command Reverse Engineering. ACM SIGCHI Conference on Human Factors in Computing Systems (CHI).