Multiplier bootstrap and multi-stage estimator
Author: Yen-Chi Chen (University of Washington)
Date: 06/12/2026
- This note is an introduction to the multiplier bootstrap for researchers and graduate students who know the empirical bootstrap but may not have much experience with the multiplier bootstrap.
- We also discuss how to use a bootstrap method in a multi-steage procedure that the same data multiple times.
- For readers who already know regression adjustment and doubly-robust estimator, you may jump to this section.
We should use the coupled multiplier bootstrap, i.e., the weight of each observation stays the same throughout multiple stages. Do NOT use different weights at different stages for the same observation.
Introduction of multiplier bootstrap
The multiplier bootstrap is a popular method for assessing the uncertainty of an estimator from minimizing a (empirical) risk or solving a system of estimating equations.
We consider a simple regression model where our data consists of an univariate outcome and a (possibly multivariate) covariate . Our goal is to estimate the conditional mean .
Our data consists of IID
Suppose we place a model on that is indexed by a parameter , i.e., our model is . Our goal is then to estimate from the data.
Consider the traditional least square estimator:
where the quantity is the empirical risk.
Under very mild conditions, we know that
where is the parameter that minimizes the population risk
Conventionally, we work out the score and Hessian of and derive the asymptotic covariance matrix and construct an estimator of it. Note that this estimator often takes a form of , so it is often known as a sandwich estimator.
The bootstrap procedure bypasses the need of doing the math to work out the estimator of . Instead, we use resampling technique to numerically compute an estimator of .
In particular, the multiplier bootstrap uses the following procedure to compute an estimator of :
- We generate IID weights [1]
- We compute the weighted least-square estimator:
- Repeat the above two steps times, leading to
estimators. - We estimate the asymptotic covariance matrix using the sample covariance matrix of the bootstrap estimate:
- The reason why multiplier bootsrtap work is that the added noises fluctuates the loss function, which mimicks the actual sampling randomness.
- It is well-known that multiplier bootstrap works for a number of problems, not limited to regression. For instance, if we are fitting a parametric model to the data and we use the maximal likelihood estimator, we can use the multiplier bootstrap to estimate the asymptotic covariance matrix of our estimator.
A major benefit of the multiplier bootstrap (and other bootstrap variant) is that we do not need to work out the asymptotic covariance matrix and find an estimator to it. If we are able to compute the estimator once, we can easily modify the code with an extra for loop to assess the uncertainty.
Multiplier bootstrap versus empirical bootstrap
The empirical bootstrap samples with replacement of the original data to create a bootstrap sample and then compute the estimator using the bootstrap sample.
Both empirical and multiplier bootstrap are popular procedure in practice and in most cases, if one method works, we expect the other to work.
In terms of validity, empirical bootstrap is a lot easier to understand why it works:
The bootstrap sample from the empirical bootstrap is IID from the empirical distribution of the original data. Since we know that the empirical distribution converges to the true CDF under very mild conditions, we expect the bootstrap sample behaves like a new sample from the target distribution.[2]
The multipler bootstrap, however, becomes a better approach when we have incomplete observations and the same size is small. We will dsicuss more about this later.
Multi-stage estimator
The story becomes more complicated when we have a multi-stage estimator. In particular, we will consider a very simple missing-at-random (MAR) scenario.
Suppose now the response variable can be missing. So somtimes we only observe and sometimes we observe both . To deal with missingness in our probability model, we introduce a binary response variable such that if is observed.
The (MAR) assumption assumes that the missingness of is conditionally independent of the actual value of given the covariate , i.e.,
Now we consider a very simple problem: estimating the marginal mean of , i.e., we want to estimate .
Apparently, the naive estimator of using the mean value of observed is not going to be consistent because this naive estimator
Under the (MAR), it is known that we can use a regression adjustment method for estimating utilizing the fact that
Therefore, the regression adjustment (RA) estimator suggests to use
where is an estimator of the outcome regression model .
Note that the regression model is called a nuisance parameter.
The regression adjustment estimator has a simple interpretation: when is observed, we use its observed value; when is missing, we use the outcome regression model to predict its value.
If we use a parametric model like in the previous section, this estimator will be , where
Namely, we estimate the parameter using the complete data.
One should be careful that this RA estimator works only if our parameter of interest is the marginal mean . If the parameter of interest is other quantity, we have to use a different outcome regression model.
For , how can we estimate its uncertainty?
- The classical approach of doing asymptotic analysis still works and we are able to construct an estimator for asymptotic variance.
- The bootstrap method also works here but we have to be careful since we are using data twice: the first time is to estimate the nuisance and the second time
When we have incomplete observations and sample size is small, multiplier bootstrap is generally better than the empirical bootstrap. This is because our bootstrap sample may not contain enoough observations to reliably estimate the nuisance (in the above example, the outcome regression model). When our copmlete observations have a small sample size, the empirical bootstrap sample may end up with no complete observations! So we cannot even produce a bootstrap estimate of the nuisance estimator. On the other hand, the multiplier bootstrap still works in this case.
Two versions of multiplier bootstrap
Recall that we have used data twice here:
- The first time we use it for estimating the nuisance for the regression model .
- The second time we use it for the regression adjustment estimator .
When using a parametric model for the nuisance, using data twice is generally not too much of a problem since the model class is not too complex[3].
Now we want to use the multiplier bootstrap. A common question people asked is:
Since we have two estimators, should we use the same or different weights for each observation for the two estimators and ?
The simple answer to this problem is: we use the same weight for the same observation in both stages.
Namely, we only generate one set of IID random weights . Whenever is used (in any stage), we always use the same weight .
Why do we have to use the same weight? This is because the bootstrap attempts to recover the uncertainty of the total estimator. In the original estimator, the same individual is used in both stages. This creates a dependency between the nuisance estimator and the regression adjustment estimator. We want the bootstrap to recover such dependency.
If we use different weights, say when is used for estimating , and when is used for , this introduces independence between the two stages, so it underestimate the uncertainty in .
Here is a simple simulation illustrating this problem; the code for this experiment is at the end of this note:
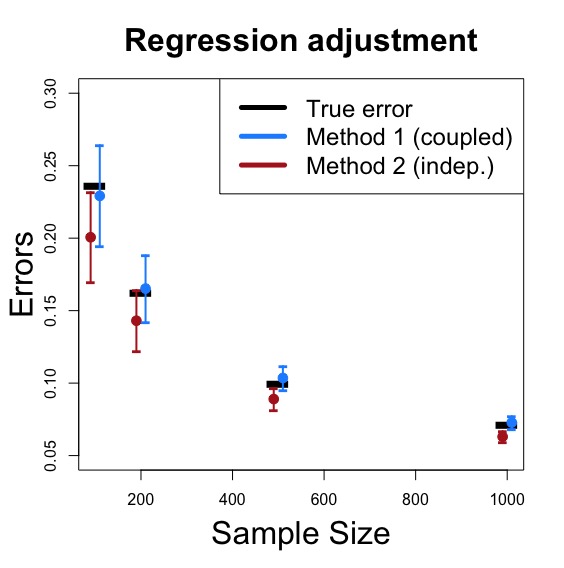
- The blue lines indicating the result from the correct method: coupled multiplier bootstrap.
- The brown lines indicating the result from the wrong method: independent multiplier bootstrap.
The black bar indicates the true errors. You can clearly see that the coupled multiplier bootstrap--we use the same weights for the two stages--recovers the true uncertainty while the independent multiplier bootstrap fails to recover it.
While here we consider the regression adjustment method, the same result occurs when we are using the inverse probability weighting estimator. The correct way of performing a multiplier bootstrap is to use the same weight in both stages.
Doubly-robust/one-step estimator
One may be wondering if the same biased result occurs for doubly-robust (DR) estimator. It turns out that if we are using DR estimators, using the different weights actually does not lead to a bias uncertainty estimate. However, using the correct procedure, the same weights across different stages, has a better finite sample performance.
Formally, the DR estimator is
where is the regression model on and is the propensity score model on . A common model for the propensity score is the logistic regresion: and we estimate by a logistic regression of .
In this case, the estimator is a three-stage estimator since we use data three times:
- First time: estimating the outcome model's parameter .
- Second time: estimating the propensity score model's parameter .
- Third time: computing the final estimator .
We consider again two variants of the multiplier bootstrap:
- [Method 1]: coupled multiplier bootstrap. Same weight for -th observation throughout the three stages.
- [Method 2]: indpendent multiplier bootstrap. We have three independent weights for each stage.
The following shows the result of using these two methods, assuming that both models are correct.
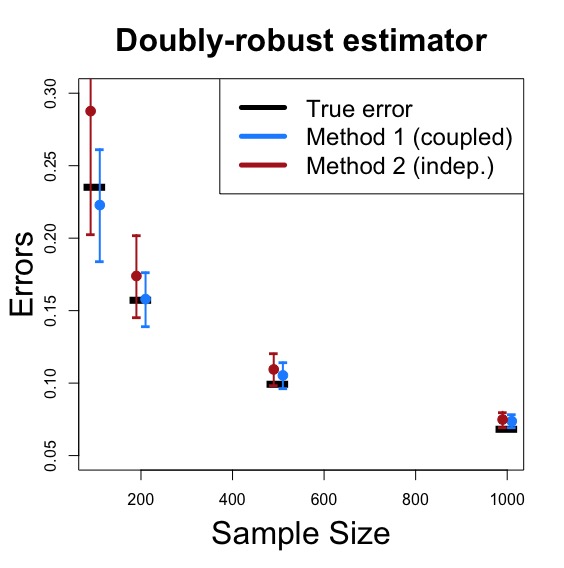
Now both methods are asymptotically valid when both models are correct while the coupled multiplier bootstrap is preferred since it approximates the actual uncertainty better.
The reason why both methods are valid is due to the fact that when both outcome regression and propensity score models are correct, the errors from these two nuisance models is negligible compared to the errors due to the final averaging process. Thus, while the independent multiplier bootstrap ignores the actual dependency of estimating the nuisance, such dependency contributes little to the overall uncertainty. So an inconsistent estimate of these uncertainties is fine.
However, despite the fact that both methods approximate the actual uncertainty, we still see that method 1, the coupled multipler bootstrap, is preferred since it better recovers the entire uncertainty, so it has a superior finite sample performance.
Appendix: R scripts
These R scripts are written by Gemini 3.1 pro.
For the regression adjustment estimator
# -------------------------------------------------------------------------
# 1. Data Generation
# -------------------------------------------------------------------------
set.seed(42)
n <- 1000
X <- runif(n, 0, 1)
E <- rnorm(n, 0, 1)
# True outcome
Y <- 3 + 4 * X + E
# Missingness mechanism (MAR)
# Note: Prompt stated P(M=1|Y) but formula only depends on X.
# We implement the formula as given, which correctly satisfies MAR.
prob_missing <- exp(2 * X) / (1 + exp(2 * X))
# Let M = 1 denote missing, M = 0 denote observed
M <- rbinom(n, 1, prob_missing)
# Create the observed Y vector (NA where M == 1)
Y_obs <- Y
Y_obs[M == 1] <- NA
data <- data.frame(X, Y_obs, M)
# -------------------------------------------------------------------------
# 2. Point Estimation (Original Data)
# -------------------------------------------------------------------------
# [Outcome regression]
fit_or <- lm(Y_obs ~ X, data = data)
# [Propensity score] (Included per prompt, though not strictly needed for g-comp)
fit_ps <- glm(M ~ X, data = data, family = binomial(link = "logit"))
# [g-compute] Estimator
# Impute missing Y using the outcome regression
Y_imputed <- data$Y_obs
missing_idx <- which(data$M == 1)
Y_imputed[missing_idx] <- predict(fit_or, newdata = data[missing_idx, ])
# Point estimate for the mean of Y
mu_hat <- mean(Y_imputed)
cat("Point Estimate (mu_hat):", round(mu_hat, 4), "\n\n")
# -------------------------------------------------------------------------
# 3. Multiplier Bootstrap Setup
# -------------------------------------------------------------------------
B <- 500 # Number of bootstrap replicates
# Initialize vectors to store bootstrap estimates
boot_coupled <- numeric(B)
boot_indep <- numeric(B)
for (b in 1:B) {
# Generate weights ~ Exp(1)
W_coupled <- rexp(n, rate = 1)
# For the independent variant, we need a second set of weights
W_indep_OR <- rexp(n, rate = 1)
W_indep_gcomp <- rexp(n, rate = 1)
# =========================================================
# Variant 1: Coupled Multiplier Bootstrap
# =========================================================
# 1. Weighted Outcome Regression
# (lm automatically drops NAs, so we just pass the full data and weights)
fit_or_coupled <- lm(Y_obs ~ X, data = data, weights = W_coupled)
# 2. Impute missing values
Y_imp_coupled <- data$Y_obs
Y_imp_coupled[missing_idx] <- predict(fit_or_coupled, newdata = data[missing_idx, ])
# 3. Weighted g-computation
boot_coupled[b] <- sum(W_coupled * Y_imp_coupled) / sum(W_coupled)
# =========================================================
# Variant 2: Independent Multiplier Bootstrap
# =========================================================
# 1. Weighted Outcome Regression (using W1)
fit_or_indep <- lm(Y_obs ~ X, data = data, weights = W_indep_OR)
# 2. Impute missing values
Y_imp_indep <- data$Y_obs
Y_imp_indep[missing_idx] <- predict(fit_or_indep, newdata = data[missing_idx, ])
# 3. Weighted g-computation (using W2)
boot_indep[b] <- sum(W_indep_gcomp * Y_imp_indep) / sum(W_indep_gcomp)
}
# -------------------------------------------------------------------------
# 4. The "Gold Standard" Monte Carlo Truth
# -------------------------------------------------------------------------
# We simulate the true sampling variance by generating 1000 entirely new datasets
M_sims <- 1000
true_sampling_distribution <- numeric(M_sims)
for (m in 1:M_sims) {
# Re-run the exact data generating process
X_sim <- runif(n, 0, 1)
E_sim <- rnorm(n, 0, 1)
Y_sim <- 3 + 4 * X_sim + E_sim
prob_missing_sim <- exp(2 * X_sim) / (1 + exp(2 * X_sim))
M_sim <- rbinom(n, 1, prob_missing_sim)
Y_obs_sim <- Y_sim
Y_obs_sim[M_sim == 1] <- NA
data_sim <- data.frame(X = X_sim, Y_obs = Y_obs_sim, M = M_sim)
# Point Estimate
fit_or_sim <- lm(Y_obs ~ X, data = data_sim)
Y_imputed_sim <- data_sim$Y_obs
missing_idx_sim <- which(data_sim$M == 1)
Y_imputed_sim[missing_idx_sim] <- predict(fit_or_sim, newdata = data_sim[missing_idx_sim, ])
true_sampling_distribution[m] <- mean(Y_imputed_sim)
}
true_se <- sd(true_sampling_distribution)
cat("\n--- The Moment of Truth ---\n")
cat("True Monte Carlo SE (Gold Standard):", round(true_se, 4), "\n")
cat("Coupled Multiplier Bootstrap SE: ", round(se_coupled, 4), " (Accurate)\n")
cat("Independent Multiplier Bootstrap SE:", round(se_indep, 4), " (Underestimated)\n")
For the doubly-robust estimator
# -------------------------------------------------------------------------
# 1. Data Generation
# -------------------------------------------------------------------------
set.seed(42)
n <- 1000
X <- runif(n, 0, 1)
E <- rnorm(n, 0, 1)
Y <- 3 + 4 * X + E
prob_missing <- exp(2 * X) / (1 + exp(2 * X))
M <- rbinom(n, 1, prob_missing)
R <- 1 - M # R = 1 means Observed, R = 0 means Missing
Y_obs <- Y
Y_obs[R == 0] <- NA
data <- data.frame(X, Y_obs, M, R)
# -------------------------------------------------------------------------
# 2. Point Estimation (Doubly Robust)
# -------------------------------------------------------------------------
# [Outcome regression] m_hat(X)
fit_or <- lm(Y_obs ~ X, data = data)
m_hat <- predict(fit_or, newdata = data)
# [Propensity score] pi_hat(X) = P(R=1 | X)
fit_ps <- glm(R ~ X, data = data, family = binomial(link = "logit"))
pi_hat <- predict(fit_ps, type = "response", newdata = data)
# [Doubly Robust Estimator]
# Note: When R=0, Y_obs is NA. We use ifelse to safely evaluate 0 * NA as 0.
dr_terms <- m_hat + ifelse(data$R == 1, (1 / pi_hat) * (data$Y_obs - m_hat), 0)
mu_hat_dr <- mean(dr_terms)
cat("DR Point Estimate (mu_hat):", round(mu_hat_dr, 4), "\n\n")
# -------------------------------------------------------------------------
# 3. Multiplier Bootstrap Setup
# -------------------------------------------------------------------------
B <- 500
boot_coupled_dr <- numeric(B)
boot_indep_dr <- numeric(B)
for (b in 1:B) {
# Generate weights ~ Exp(1)
W_coupled <- rexp(n, rate = 1)
# For independent, we draw separate weights for OR, PS, and Final Mean
W_indep_OR <- rexp(n, rate = 1)
W_indep_PS <- rexp(n, rate = 1)
W_indep_FINAL <- rexp(n, rate = 1)
# =========================================================
# Variant 1: Coupled Multiplier Bootstrap (DR)
# =========================================================
# Fit models using the SAME weights
fit_or_coupled <- lm(Y_obs ~ X, data = data, weights = W_coupled)
# quasibinomial suppresses warnings for non-integer weights
fit_ps_coupled <- glm(R ~ X, data = data, weights = W_coupled, family = quasibinomial)
m_hat_coupled <- predict(fit_or_coupled, newdata = data)
pi_hat_coupled <- predict(fit_ps_coupled, type = "response", newdata = data)
dr_terms_coupled <- m_hat_coupled + ifelse(data$R == 1, (1 / pi_hat_coupled) * (data$Y_obs - m_hat_coupled), 0)
# Weighted mean
boot_coupled_dr[b] <- sum(W_coupled * dr_terms_coupled) / sum(W_coupled)
# =========================================================
# Variant 2: Independent Multiplier Bootstrap (DR)
# =========================================================
# Fit models using INDEPENDENT weights
fit_or_indep <- lm(Y_obs ~ X, data = data, weights = W_indep_OR)
fit_ps_indep <- glm(R ~ X, data = data, weights = W_indep_PS, family = quasibinomial)
m_hat_indep <- predict(fit_or_indep, newdata = data)
pi_hat_indep <- predict(fit_ps_indep, type = "response", newdata = data)
dr_terms_indep <- m_hat_indep + ifelse(data$R == 1, (1 / pi_hat_indep) * (data$Y_obs - m_hat_indep), 0)
# Weighted mean using the third independent weight
boot_indep_dr[b] <- sum(W_indep_FINAL * dr_terms_indep) / sum(W_indep_FINAL)
}
# -------------------------------------------------------------------------
# 4. The "Gold Standard" Monte Carlo Truth
# -------------------------------------------------------------------------
M_sims <- 1000
true_sampling_distribution_dr <- numeric(M_sims)
for (m in 1:M_sims) {
X_sim <- runif(n, 0, 1)
E_sim <- rnorm(n, 0, 1)
Y_sim <- 3 + 4 * X_sim + E_sim
prob_missing_sim <- exp(2 * X_sim) / (1 + exp(2 * X_sim))
M_sim <- rbinom(n, 1, prob_missing_sim)
R_sim <- 1 - M_sim
Y_obs_sim <- Y_sim
Y_obs_sim[R_sim == 0] <- NA
data_sim <- data.frame(X = X_sim, Y_obs = Y_obs_sim, R = R_sim)
# Fit on simulated data
fit_or_sim <- lm(Y_obs ~ X, data = data_sim)
fit_ps_sim <- glm(R ~ X, data = data_sim, family = binomial)
m_hat_sim <- predict(fit_or_sim, newdata = data_sim)
pi_hat_sim <- predict(fit_ps_sim, type = "response", newdata = data_sim)
dr_terms_sim <- m_hat_sim + ifelse(data_sim$R == 1, (1 / pi_hat_sim) * (data_sim$Y_obs - m_hat_sim), 0)
true_sampling_distribution_dr[m] <- mean(dr_terms_sim)
}
# -------------------------------------------------------------------------
# 5. Results
# -------------------------------------------------------------------------
se_coupled_dr <- sd(boot_coupled_dr)
se_indep_dr <- sd(boot_indep_dr)
true_se_dr <- sd(true_sampling_distribution_dr)
cat("--- DR Estimator Standard Errors ---\n")
cat("True Monte Carlo SE: ", round(true_se_dr, 4), "\n")
cat("Coupled Multiplier Bootstrap SE: ", round(se_coupled_dr, 4), "\n")
cat("Independent Multiplier Bootstrap SE:", round(se_indep_dr, 4), "\n")
The exponetial random variable can be replaced by other random variable with mean and variance . ↩︎
A caveat here is: we need the parameter of interest to be a smooth quantity in the sense that changing the underlying population distribution will smoothly changes the parameter of interest; this is formally known as the Hadamard differentiability. ↩︎
This is due to a property call Donsker class. If we use a nonparametric estimator for , we generally need to avoid using data twice. ↩︎