The Post-Alphabetic Web
Abstract
“Post-alphabetic”
signals the evolution of Web content away from the paradigm of the print
document. Before the mid-1990s Web
content was commonly conceptualized as digitized versions of paper documents. The emergence of the post-alphabetic Web
recognizes that many Web pages now (1)
dynamically create content from distant sources, (2) modify language with
graphic elements, and (3) use non-print design strategies. This study proposes assessing the extent of
the post-alphabetic Web along these three dimensions. Empirical evidence of the post-alphabetic Web should spur new
avenues of information science research.
Introduction and Rationale
Dynamic Content Replaces Static Content
In the "late age of print" (Bolter, 1991),
the concepts and practices of paper documents continue to influence our
understanding of the major information utility of our age, the Internet and its
graphical component, the World Wide Web.
Conceptualizing Web pages as digitized paper documents is an example of
this influence. One convenient
implication of this conception is that legacy information retrieval methods are
directly transferable to the Web.
Recent Web technologies, however, have transformed
Web pages from containers of content to algorithmic producers of content. Since
the mid-1990s scripting and database technologies have dynamically augmented
static HTML content. Examples include
JavaScript “file include” methods and Active Server Pages database calls. These technologies have transformed Web
pages into mixtures of static content and remotely located “deep” (Sullivan,
August 2, 2000) content.
The discrepancy between the content hosted by a Web
page and the content presented by a Web page has been magnified by the “second-generation”
Web revolution (Bosak and Bray, 1999).
Second-generation Web technologies are specially designed for a modular,
distributed Web environment where a heterogeneous group of consumers use
different technological platforms (e.g., PCs, television monitors, hand-held
devices). In this environment the most
efficient strategy is the separation of content from the specifics of a
particular presentation. The presentation
of digital content has become a factor of the client device, its capabilities,
scripts employed, stylesheets applied and cookies that express user
preferences. For example, a source of
Web content may abbreviate the content for a hand-held device, format the
content especially to accommodate a television monitor, and reserve certain
interactive content for PCs.
The technological contingency of a particular
presentation is transparent to end users who believe that they are viewing the
“whole,” “complete,” or “real” document.
Information scientists, laboring under such a delusion, apply theories
that assume that Web presentations are visualizations of documents that exist
somewhere on the Web. An example
is “Finding Out About” (Belew, 2001):
This text is focused on the problem of "finding out about" (FOA): Identifying documents that help someone learn more about a topic of interest. "Information retrieval" (IR) is the name of a sub-discipline within computer science that has developed a number of core technologies for constructing a statistical characterization of words occurring in each document. This is used to efficiently search through very large textual corpora for documents that a user is likely to find "relevant."
This approach needs to be updated for a Web that is
not populated with “documents,” or a
world where the “same” document could have different words depending on how it
is viewed.
One ambition of this study would be the assessment of the ratio of static text residing in Web pages versus the total textual content presented by Web pages. A low ratio would indicate that Web pages do not contain the textual content they present. Such a finding would indicate the need for an update to the theoretical assumptions of information retrieval.
Uninhibited Post-Alphabetic Orthography
As the Belew quotation above illustrates, information science research rests on certain assumptions about the nature of language; for example, how to discover words in text. The legacy method of indexing documents automatically involves “the identification of all the individual words that constitute the documents” (Salton & McGill, 1983, p.71). Web crawlers and spiders have employed this strategy to analyze “the location and frequency of keywords on a web page” (Sullivan, June 26, 2001).
The alphabetic culture includes editors, style manuals and printers who have exerted a norming influence on the orthography of print documents, yet even in the conservative alphabetic culture orthography remains a fundamental impediment to online information retrieval (Brooks, 1998). The problem, simply put, is that a living language continues to change. At this moment, written language populates the Web, and the post-alphabetic Internet environment exhibits an uninhibited orthography. One of the democratizing characteristics of the Internet is that anyone can post a message to a listserv or write content for a Web page. There is no intervening editor or printer promoting a conservative orthography or verbal style.
Two factors contributing to the Internet’s uninhibited orthography are (1) The principle of least effort (Zipf, 1949) that suggests that written communication will gravitate towards the shortest possible expression (including abbreviations and graphic elements of language, e.g., smiley faces), and (2) The use of a private argot in the public sphere of the Internet. The latter was illustrated by the users of the music-sharing service, Napster, who attempted to foil government regulators by posting and sharing music by distorting names into pig latin (Schwartz, March 12, 2001).
The modification of language in the Web environment include:
- The rebus, which is a
combination of letters and numbers.
The use of numbers may play on their pronunciation as in “4 2sday
nite” [read: for Tuesday night], or their graphical appearance: 4
for A, 1 for I, and 3 for E as in “H4ck1ng f0r g1rl13Z” [read:
Hacking for girlies].
- The semantics of
numbers where the use of beepers has spawned a vocabulary of numbers with
special meanings: Examples include
“121” [I need to talk to you alone], “101” [I’ve got an easy question],
“411” [I need some information] (Lewin, April 29, 1998)
- The short text message
service where the 160-character limit forces writers to enrich their
communication by using abbreviations, rebuses and graphic elements
(Batista, May 25, 2001; Guissani, September 11, 2000). An example is:
txtin iz messin, / mi headn'me englis, / try2rite
essays, / they all come out txtis. / gran not plsed w/letters shes getn, /
swears i wrote better / b4 comin2uni. / &she's african
These examples illustrate that writing a computer algorithm to break text on white space in order to produce “words” may be naïve. Empirical evidence of the ratio of post-alphabetic word forms to a dictionary orthography is necessary to spur theoretical development of automatic indexing, especially strategies for finding word forms.
Post-alphabetic Design Strategies: “Webness”
The assumption that a Web page is a
digitized paper document has had a strong influence on the design of
information for the Web. A vast amount
of material exists describing print-culture Web page design (for example,
Usable Web at http://usableweb.com/
presents 1427 links about web usability).
The Yale Style Guide for Web pages (Lynch & Horton, 1999) explicitly
casts Web pages as presenting words and phrases in a format that resembles text
pages:
Readers see pages first as large masses of shape and
color (see below), with foreground elements contrasted against the background
field. Only secondarily to they begin to pick out specific information, first
from graphics if they are present, and only afterward do they start parsing the
"harder" medium of text and begin to read individual words and
phrases:
![]()
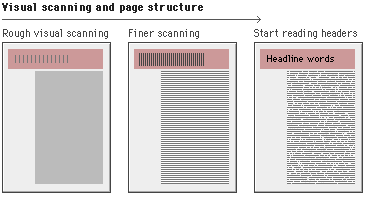
Available at http://info.med.yale.edu/caim/manual/pages/graphic_design100.html
Recently there has been a growing
recognition that a new aesthetic is needed for the design of Web pages, one
that incorporates text, graphics, sound and interactivity. Such an aesthetic need not be bound by the
legacy print culture.
Design techniques for static information are well
understood and discourse thorough and well evolved. But these techniques fail
when dynamic information is considered. There is a space of highly complex
systems for which we lack deep understanding because few techniques exist for
visualization of data whose structure and content are continually changing.
(Fry, 2000)
For lack of a better word .net
(http://prixars.aec.at/history/net/index_e.asp) judges Web sites on their “webness:”
an indication that a certain effect could only exist on the Web and not in the
legacy print culture. Other examples of
the extension of the print culture include novelists creating interactive
novels (Mirapaul, March 5, 2001) and artists creating digital works of art
(Mirapaul, August 6, 2001).
An example of a post-alphabetic Web design is the
following [I added the rectangle on the left of the image to indicate the
proportion of the Web page exposed at first viewing]. This page mixes text and images, dynamic and interactive content
in a design that exceeds the scope of the Yale style manual. It suggests the need for a new aesthetic for
the presentation of post-alphabetic content on the Web.

Available
at http://www.ndroid.com/
Objectives
The objective of this study is to assess the
emerging post-alphabetic culture of the Web.
A random sample of Web pages will be selected. The sample Web pages will be analyzed for their “post-alphabetic”
quality.
In this study, “post-alphabetic” will be measured by
(1) The ratio of permanently resident text to the total text presented on a
sample of Web pages, (2) The ratio of non-standard word forms presented on a
sample of Web pages, and (3) The ratio of Web pages using post-alphabetic
design strategies. In this study, a
post-alphabetic design strategy would be one that contravenes the etiquette
promoted by sources such as the Yale style manual.
The empirical results of the
proposed survey will be the source of several research papers proposing new
lines of information science research, as well as form the basis for a larger
writing project entitled “The Post-alphabetic Web.”
Procedure
Sample A stratified random sample of Web pages will
be drawn. The sampling strategy will attempt to collect both “conventional” and “avant garde” Web
pages. The source of sampling strata
will be (1) the Yahoo classification of Web pages, (2) Web pages receiving
accolades in the Webby Awards (http://www.webbyawards.com/main/
), and (3) The Daily Report ( http://www.zeldman.com/exit.html
), a list of Web pages with non-conventional designs.
Sampling within strata will be a
simple random sample. In the Yahoo
strata, a random selection of topics will be chosen and then a simple random
sample of Web sites will be chosen from the topical areas.
Processing
The three-part ambition of this
study leads to the following three-part processing:
One: The Ratio of Static Text to
Total Text Presented
Static Text Count: A Java program will be written to reduce a
Web page to its resident text. An
example of such a program is given in Java Network Programming
(O’Reilly, 2000, p. 251). This program
captures the source document at a URL and calculates the number of word forms
that are not part of HTML or JavaScript.
This procedure will permit a calculation of the amount of static text on
a Web page before a Web browser processes the Web page.
Dynamic Text Count: MS Word
can be pointed at a URL (it acts like a Web browser) and its word counting
function will count the number of words in the Web presentation.
This procedure will establish a ratio between the
static text resident in a Web page to the total amount of text presented on a
Web page.
Two: Post-alphabetic Orthography
The dictionary function of MS Word can be used to
locate non-standard word forms. A
reading of the text can establish the presence of graphic word forms and rebuses. This procedure will establish the proportion
of Web pages contributing novel word forms including rebuses and graphic word
forms.
Three: Post-alphabetic Web Page Design
The design of each Web page will be
examined for characteristics that contradict, vary or extend the principles of
Web page design as promoted by the Yale style guide, and other Web guides of
usability.
Time Schedule
Support is requested for one calendar year to begin
January 1, 2002.
Need for RRF Support
This grant establishes a new
research area that challenges conventional information science theory, and
therefore is unlikely to be considered by more conventional funding agencies.
The post-alphabetic Web agenda requires empirical
justification before announcement in the conventional scholarly media. This grant requests the support of an
assistant who could aid in the capture and processing of a large random sample
of Web pages.
This grant will also provide the essential empirical
research background for a larger writing project entitled “The Post-alphabetic
Web.” The University of Washington
press has already been contacted about this writing project.
Budget
01
Salary:
One undergraduate student, working
10 hours/week
during academic quarters (44 weeks)
at
$10.75/hr $
4, 730.00
07
Benefits:
Benefits calculated at 9.3% $440.00
Total $
5, 170.00
Literature Citations
Batista,
E. (May 25, 2001). Don’t Go Gently Into That SMS. Wired News Service. [Available at http://www.wired.com/news/print/0,1294,43782,00.html
]
Belew,
R.K. (2001). Finding Out About: Search
Engine Technology from a Cognitive Perspective. Cambridge University Press.
[Available at: http://www-cse.ucsd.edu/~rik/foa/]
Bolter,
J. (1991). Writing space: the computer,
hypertext, and the history of writing.
Hillsdale, NJ: Lawrence Erlbaum Associates.
Bosak, J. and
Bray, T. (May 1999). "XML and the second-generation Web," The Scientific
American at http://www.sciam.com/1999/0599issue/0599bosak.html [Accessed July 7, 2000]
Brooks, T.A. (1998). Orthography as a Fundamental Impediment to Online Information Retrieval" [pdf] [HTML] Journal of the American Society for Information Science, v.49 (8), 1998, 731-741.
Fry, B. (2000). Organic information design. Master’s thesis, MIT Media Lab.
Guissani, B. (September 11, 2000). “What’s Up 2Nite?” The Industry Standard, p. 140
Landow, G. (1992). Hypertext: the convergence of contemporary literary theory and technology. Baltimore: Johns Hopkins University Press
Lewin, T. (April 29, 1998). “In Beeptalk, The Words Add Up.” The New York Times.
Lynch,
P.J. & Horton, S. (1999). Web Style Guide: Basic Design Principles for
Creating Web Sites. Yale Univ Press.
Mirapaul, M. (March 5, 2001). “Beyond hypertext: Novels with
interactivity.” New York Times.
Mirapaul, M. (August 6, 2001). “Impressionists in cyberspace,
digital but diverse.” New York Times.
Salton, G. & McGill, M.J. (1983). Introduction to Modern
Information Retrieval. New York, NY;
McGraw-Hill.
Sullivan, D. (August 2, 2000). "The invisible Web gets
deeper." at http://searchenginewatch.com/sereport/00/08-deepweb.html [Accessed August 4, 2000]
Sullivan,
D. (June 26, 2001) “How Search Engines Rank Web pages” at http://searchenginewatch.com/webmasters/rank.html [Accessed August 23, 2001]
Schwartz,
J. (March 12, 2001). “After Napster, Falling Back on Pig Latin.” The New York
Times.
Zipf.
G. K. 1949. Human Behaviour and the Principle of Least Effort. Cambridge, MA; Adison-Wesley