Samples and Populations
The formulas on the previous page for variance and standard deviation
are appropriate when we have all the data we are interested in. That
is not usually the case. For example, suppose we wanted to know how
many hours of television the average American watched each week. There
is obviously no way we ask every person in the United States how many
hours of television they watched. Instead, we would ask a random
sample
of people how many hours they watched and then use the mean of that sample of
data to estimate the mean for the entire
population. The
mean for the entire population is usually represented by
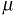 .
So far, so good.
.
So far, so good.
We would also want to estimate the spread of the number of hours of TV watched.
The difficulty, as we will demonstrate on the next page, is that the
standard deviation of the sample
calculated (as on the previous page) slightly underestimates
the true population standard deviation
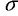 .
The difficulty arises because when we calculate squared errors, we would
really like to be subtracting the true population mean
,
instead of our sample mean
.
The difficulty arises because when we calculate squared errors, we would
really like to be subtracting the true population mean
,
instead of our sample mean
 .
We know that the sample mean makes the sum of squared errors as small as possible
for that particular sample. Hence, the true sum of squared
errors if we were able to use the population mean would necessarily be slightly
larger. It turns out that dividing the sum of squares by (n-1) instead of by
n is exactly the correction needed to remove the bias. That is,
.
We know that the sample mean makes the sum of squared errors as small as possible
for that particular sample. Hence, the true sum of squared
errors if we were able to use the population mean would necessarily be slightly
larger. It turns out that dividing the sum of squares by (n-1) instead of by
n is exactly the correction needed to remove the bias. That is,

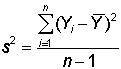
provides the most accurate estimate of the population variance. And the square
root of variance calculated in this way provides the best estimate of the
population standard deviation. So, if our goal is to estimate the true
spread in the population, the above formula is the one to use.
On the next page, the two formulas are compared in action.