| |
Formalities
You probably recognized on the previous page that
the shape of the sampling distribution for the slope was
close to the normal distribution.
Indeed, the sampling distribution for the slope is a normal
distribution with a mean equal to b and a standard
deviation equal to

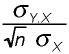
where
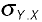
is the standard deviation of the errors from the model of Y using X; that is,
the typical distance from
an observation to the regression line.
Click on the Equations button for the mathematical details.
|
|
| |
The standard deviation of the sampling distribution tells us how wide the distribution
is, and this tells us how far off our estimate might be. The smaller the standard
deviation the narrower the sampling distribution. Just as in previous tests,
increasing the number of observations will produce a narrower distribution, so our slope
estimate will be more accurate. Also note that if X has a larger standard deviation
then the sampling distribution will also be narrower.
If we knew the population value of the standard deviation for the sampling distribution
of the slope, then we could calculate a z-score and use the normal distribution to
identify surprising values. However, we must estimate the sampling distribution's
standard deviation. So, just as was the case for the one-group and two-group
comparisons, we must instead use the Student t statistic.
The standard deviation of the sampling distribution for the slope is easy to
estimate from the data. The numerator is based on the typical model squared error--the
sum of the error squares divided by the degrees of freedom. This is sometimes
called the "mean squared error" (MSE) and is given by:
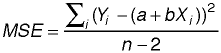
and the denominator is estimated by the square root of n
times the standard deviation for X. Putting everything together,
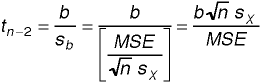
We will generally use the computer to calculate the Student t for the slope
so it is more important to understand the concepts in the above formula than the
computational details. The right-most expression tells us when the t for the
slope will be large--when the slope b is large, when the
number of observations n is large, when the standard deviation
of X (the predictor) is large, and when the aggregate error MSE
is small (i.e., the data points are close to the best-fitting line).
|
|
