 |
The regression line we've estimated from either the calculations
or from minimizing the error squares in the graph describes how one variable is
related to another. To understand that description, it is important to interpret
the parameters of the regression line, especially the slope. In the example of the
pre- and post-SKQ scores, the best-fitting line is
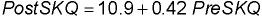
That is, the intercept is 10.9 and the slope is 0.42 for relating the initial scores
(pre-SKQ)
to the later scores (post-SKQ). The crosshairs in the graph
below show how the line relates pre-SKQ on the horizontal axis
to post-SKQ on the vertical axis.
|
|
| |
|
Move scrollbar to change horizontal axis variable
and observe changes in the predicted vertical axis variable.
|
|
|
|
|
|
To find out what post-SKQ score we would expect for a student whose pre-SKQ score was 11,
use the scrollbar to position the crosshairs so that pre-SKQ = 11.
(Due to screen resolution, you may not be able to hit 11 exactly.)
Thus, we would expect or predict that post-SKQ would
equal about 15.5 in that
situation. (A single person's score cannot of course be 15.5. More exactly, we expect
that if we had a group of people who had all scored 11 on the pre-SKQ, we would expect
their average score on the post-SKQ to be 15.5.)
To find out how much the predicted post-SKQ score would increase for a student scoring one
point higher, set pre-SKQ = 12. Now the predicted post-SKQ score
is about 15.9, an increase of .4 over the predicted score for someone with
pre-SKQ = 11. Note that the amount of the increase, .4, matches
(within round-off error)
the value for the slope of the line. That is the exact meaning of the slope in the
best-fitting line: the expected increase in the predicted variable (vertical axis)
for each increase
of one unit in the predictor variable (horizontal axis).
|
|
|

