Kun Su, Xiulong Liu, E. Shlizerman University of Washington
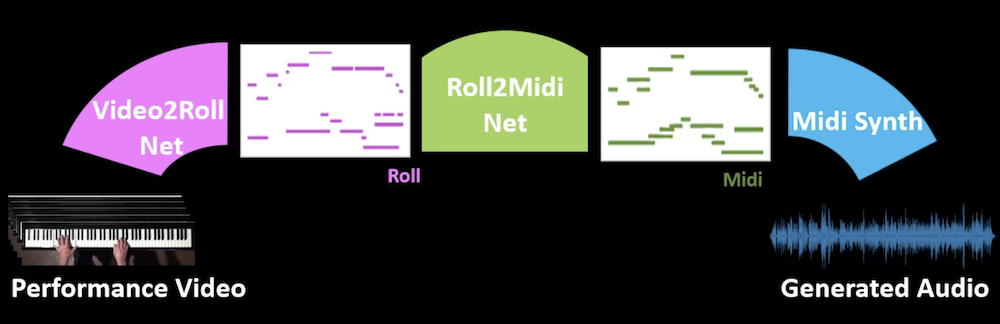
Audeo is a novel system that gets as an input video frames of a musician playing the piano and generates the music for that video. Generation of music from visual cues is a challenging problem and it is not clear whether it is an attainable goal at all. Our main aim in this work is to explore the plausibility of such a transformation and to identify cues and components able to carry the association of sounds with visual events. To achieve the transformation we built a full pipeline named Audeo containing three components. We first translate the video frames of the keyboard and the musician hand movements into raw mechanical musical symbolic representation Piano-Roll (Roll) for each video frame which represents the keys pressed at each time step. We then adapt the Roll to be amenable for audio synthesis by including temporal correlations. This step turns out to be critical for meaningful audio generation. As a last step, we implement Midi synthesizers to generate realistic music. Audeo converts video to audio smoothly and clearly with only a few setup constraints. We evaluate Audeo onin the wild'piano performance videos and obtain that their generated music is of reasonable audio quality and can be successfully recognized with high precision by popular music identification software.
Motivation
In the Audeo project we address the challenge of whether an AI system can hallucinate the music that is being played in a video. In the case of a piano recording, that would be building an AI system which gets as an input video frames of a musician playing the piano and generates the music for that video. Here is an example of such video:
More broadly, our main aim in this work is to explore how to approach the transformation from video to audio with AI tools. By succeeding to generate the music we are able to identify cues and components for the association of sounds with visual events. The discovery of these components shows a promise for a variety of applications when these components are being altered or further examined. We show an example for such application by generating different instruments music which corresponds to the piano music being played (timbre transform) and there is much more to explore in the future.
For more info please read the preprint of Audeo and watch the Youtube video that explains how Audeo is built. Below we provide several samples and short descriptions of each component.
Generated Samples
We generate a variety of full music pieces. Below we provide a few short samples. We propose to estimate the overall quality of the generated music by asking popular music identification software (Shazam, Soundhub) to identify the piece we get.
Joplin, Entertainer (MIDI to Music with Fluid Synth)
Joplin, Entertainer (MIDI to Music with PerfNet)
Schubert, Ständchen (MIDI to Music with Fluid Synth)
Schubert, Ständchen (MIDI to Music with PerfNet)
Tchaikovski, Valse Sentimentale (MIDI to Music with Fluid Synth)
Tchaikovski, Valse Sentimentale (MIDI to Music with PerfNet)
Audeo can generate the music as an interpretation being played by different instruments (timbre transform). For example, have you wondered how Bach's Prelude performed on Piano would sound as if it was performed with Guitar or Koto? Now Audeo can generate such new interpretation.
Bach, Prelude generated in Guitar Style.
Bach, Prelude generated in Koto Style.
Schubert, Ständchen generated in Brass Style.
Beethoven, Für Elise generated in String Ensemble Style.
The components are shown in the figure above. We describe each component separately below.
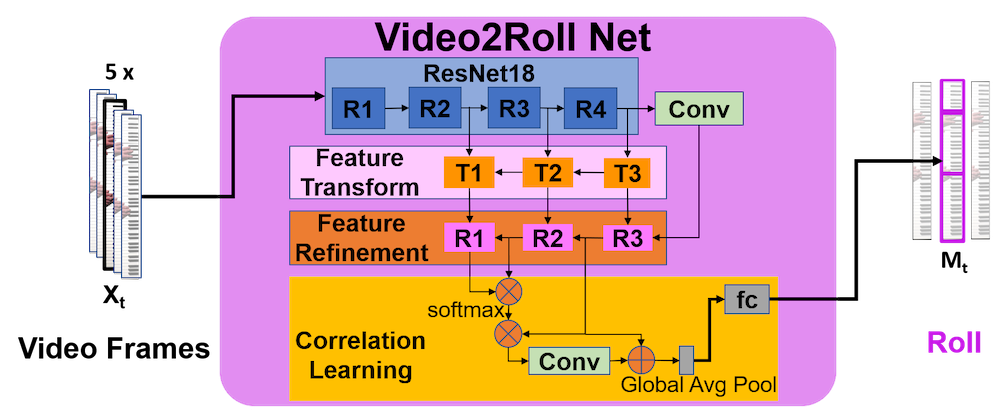
Pressed Key detection (Video2Roll Net)
We formulate this problem as a multi-label image classification problem. We use stacked five consecutive video frames as input into Video2Roll Net which outputs a prediction of the keys pressed in the middle frame (Roll). In addition to ResNet 18 being the backbone module, Video2Roll Net includes feature transform, feature refinement and correlation learning modules to detect the visual cues more precisely than solely ResNet 18 network. An example of visualized feature maps comparison between Video2Roll Net and ResNet 18 is shown below.
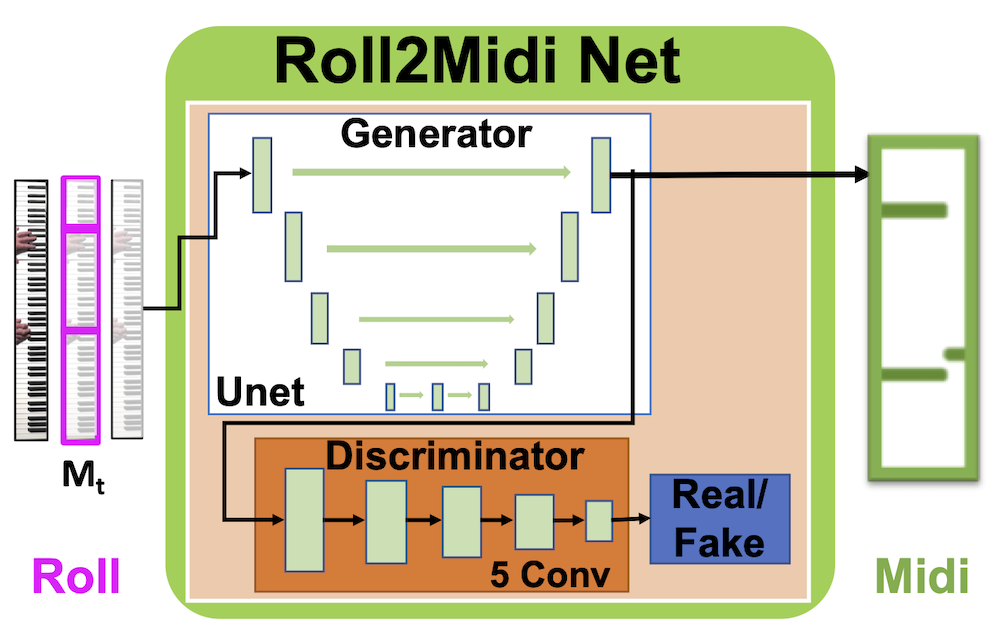
Adding Context (Roll2Midi Net)
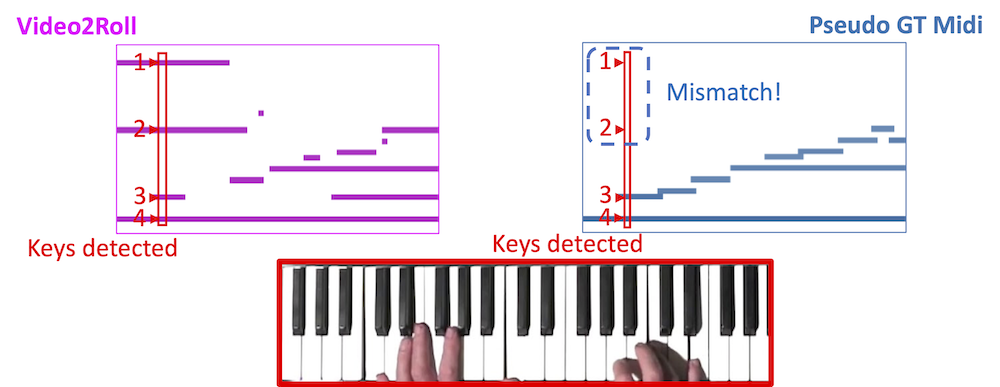
The Roll predictions of Video2Roll include only the mechnaical information on whether a key is being pressed in each frame. The Roll does not include temporal correlations accross frames and thereby generates a chopped and unclear audio if transfromed to music. In addition, the nature of sound is that over time it changes, for example, if performer sustains a key for sufficiently long time, the magnitude of the corresponding key (harmonic) will gradually decay to zero. These 'mismatches' between Roll and the Midi that we would like to generate are frequent. We show examples of such mismatches below. This means that we need to modify the Roll and create a Midi signal (also sometime called Pseudo Midi) that takes these effects into account. For the example of holding the key for long time, Pseudo Midi will mark that key as OFF at some point in time. We introduce a generative adversarial network (Roll2Midi Net) to perfrom this task of transformation from Roll to Midi to obtain a Midi signal that can be synthesized into music.
Synthesis (Midi Synth)
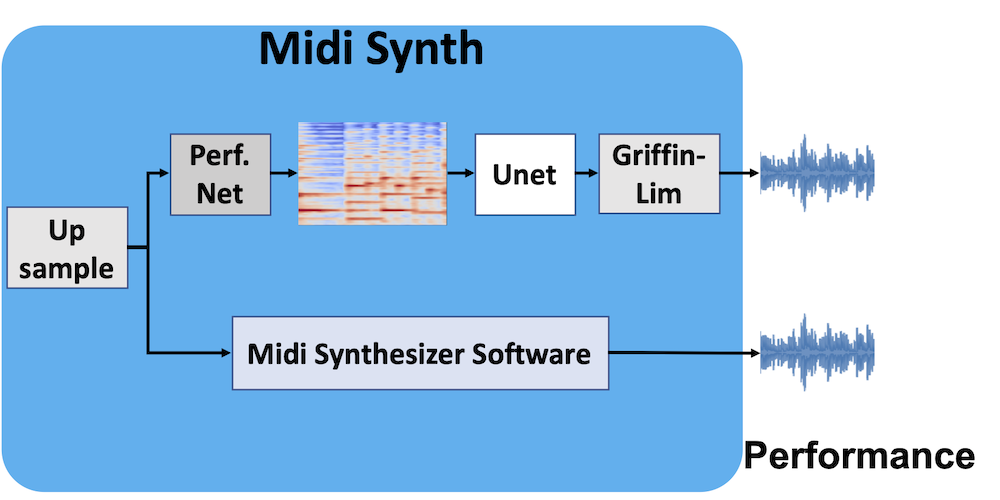
The last step is to generate music with the predicted Midi. We can use classical Midi synthesizers such as Fluid Synth to generate music. While these Midi synthesizers can provide clean, robust and reasonable music, the audio synthesized from them typically sounds more mechanical. To step further, we also investigate whether we can generate more realistic music via a synthesizer which uses deep learning. In particular, we use PerfNet, which is pre-trained with Ground Truth Pseudo Midi signals and forward propagate the Midi prediction to obtain initial estimated spectrograms. Then we use a U-net to do the refinement on the spectrogram level. As the last step, Griffin-Lim algorithm is used to convert the spectrogram to the audio waveform.
Summary Video
Citation
Acknowledgements
We acknowledge the support of Washington Research Foundation Innovation Fund, the partial support by the Departments of Electrical and Computer Engineering, Applied Mathematics, the Center of Computational Neuroscience, and the eScience Center at the University of Washington in conducting this research.
Contact
For more information, contact NeuroAI lab at University of Washington:
Eli Shlizerman (PI) shlizee@uw.edu