Results of double-sized synthetic data sets
- Mixture of Gaussian with 470 genes:
The size of each class is doubled, and the mean vector and covariance
matrix of each class are used to generate 10 replicates of synthetic
data sets with size doubled.
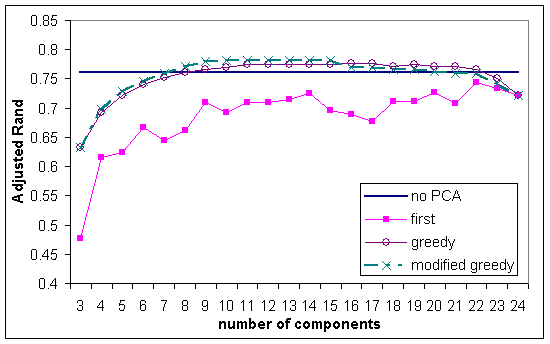
Figure 1: Average Adjusted Rand index against the number of components using CAST and correlation on the double-sized mixture of Gaussian synthetic data sets
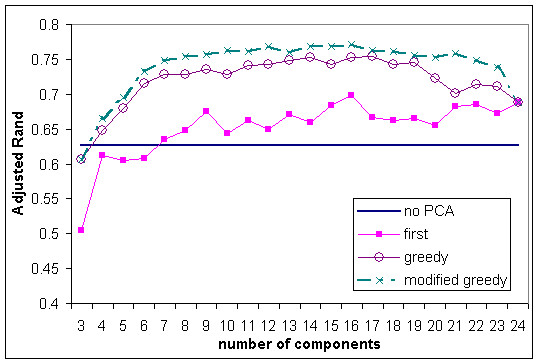
Figure 2: Average Adjusted Rand index against the number of components using k-means and correlation on the double-sized mixture of Gaussian synthetic data sets
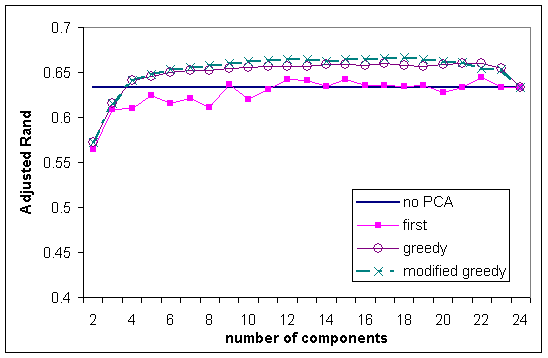
Figure 3: Average Adjusted Rand index against the number of components using k-means and Euclidean distance on the double-sized mixture of Gaussian synthetic data sets
Cyclic data with 470 genes:
Ten clusters are produced using the same form as the cyclic data described
in the paper.
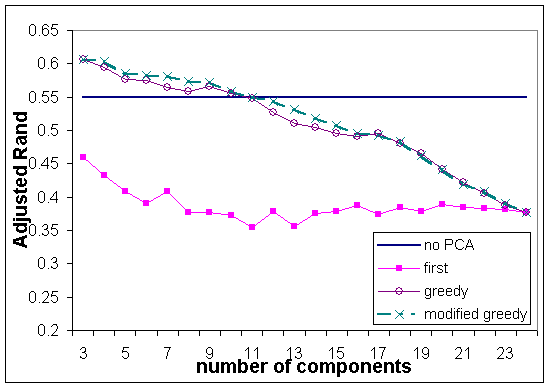
Figure 4: Average Adjusted Rand index against the number of components using CAST and correlation on the double-sized cyclic synthetic data sets
Figure 5: Average Adjusted Rand index against the number of components using k-means and Euclidean distance on the double-sized cyclic synthetic data sets
![[BACK]](button_return.gif) Back to the main page of the supplementary web site.
Back to the main page of the supplementary web site.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}