CS 261 Homework 7 - Catching Plagiarists!
Due Mon May 13 at 11:59pm
A Fun Song
This seemed relevant: http://www.youtube.com/watch?v=UQHaGhC7C2E#t=0m49s
Overview
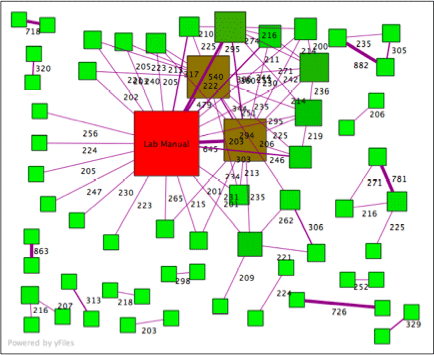
Below is an actual graph of lab reports submitted for Introductory Physics at a large University. This graph represents the data collected for about 800 lab reports. Each node in the graph represents one report (a document). Each edge indicates the number of 6-word phrases that are identical between the documents it connects--that is, both document have the same 6 words in the same order. To reduce “noise” a threshold of 200 common phrases has been set – so a document that shares fewer than 200 6-word phrases with all other documents is not shown. The "Lab Manual" is a style-guide for the lab report, and the two brown boxes are sample lab reports that were distributed (many people apparently "borrowed liberally" from these help materials). Notice the clustered trio in the top-right corner: those documents have an unusually large number of 6-word phrases in common with each other. It is likely that those people turned in copied large portions from each other. Plagiarism!
In this assignment ("borrowed liberally" from Baker Franke), your task is to analyze a set of documents and determine which documents have common word sequences, and so are likely instances of plagiarism. The input to your program will be a set of text documents, and the output will display how many n-length word sequences (also called an
n-gram)
your document has in common with every other document in the set.
In the end, you should identify "suspicious" groups of documents that share many common word sequences among themselves (but not with others), and thus likely include instances of plagiarism.
You can work on this project either individually or in pairs (I recommend you work in pairs--two heads are better than one!)
Objectives
- To review data structures and algorithms we've discussed in class.
- To practice picking/developing a data structure to match a problem.
- To practice writing algorithms with an eye towards their efficiency.
- To practice writing programs from scratch.
Necessary Files
You will want a copy of the Hwk7.zip file. This file contains sets of documents you can use to test your code (these sets were compiled from http://www.freeessays.cc/ which contains a number of really bad high school and middle school essays on a variety of topics). There are three (3) sets of documents:
- A small set containing about 25 documents (~34,000 words). This set is appropriate for testing that things work.
- A medium set containing about 75 documents (~90,000 words). This set can help test your program's scalability.
- A large set continaing over 1300 documents (~1.6 million words). This set will test that your program can work at massive scale, and will make data structure type and algorithm speed important!
The zip also contains a class DocumentReader.java, which has some simple file-parsing code to get you started (these files are encoded in a weird way, so you can't just use the scanner). You will need to modify this code--currently it just prints out n-grams of the documents! (For example, you might have the method construct and return your data structure).
And of course, the zip contains your friendly neighborhood README for the assignment, which you should fill out!
Details
You can think of your program as producing an N x N matrix (where N is the number of documents). Each cell in the matrix represents the number of n-grams that are found in both documents. Consider the table below:
A B C D E A - 4 50 700 0 B - - 0 0 5 C - - - 50 0 D - - - - 0 E - - - - -From this matrix you can conclude that paper A, C, and D have high similar scores, and that A and D almost certainly cheated. Your goal is to be able to produce a matrix or similar output that illustrates such values. However, printing an N x N matrix may be untenable for very large data sets. You could instead produce a list of documents ordered by the number of matching n-grams. For example:
700: A, D 50: A, C 50: C, D 5: B, E 4: A, B
How are you going to do this? The strategy is entirely up to you!
The brute-force solution (comparing each n-word sequence to all other n-word sequence) produces an O(n2) solution, where n is the total number of words in all the documents (so very big!). For a large set of documents this will work, it will just take a long time. If the small set (25 docs) takes 10 seconds, then the large set (1300 docs) will take 6 hours... and that's assuming that you can load all the documents into memory (which you might not be able to do for a large enough data set).
Instead, you'll want to come up with a more clever solution that can be more efficient. You'll need to consider both the run-time efficiency (i.e., the big-O for your algorithm), and the space efficiency (what can you fit into memory?). Think about the data structures and algorithms we've discussed.
You'll likely need to make your own "custom" data structure (that may be a combination or draw on aspects of other structures we've discussed). However, you are welcome to use anything in the core Java API.
You should think about this on your own, but if you need some inspiration, the following ideas might help:
Submitting
BEFORE YOU SUBMIT: make sure your code is fully documented and functional! If your code doesn't run, I can't give you credit!
- Please include a lot of detail in your documentation--since I don't know what structures/algorithms you'll be using, you'll need to explain them!
- Also note that style is worth a bit more for this assignment. Be careful about good style even when you're writing from scratch!
Also make sure you that have filled out the README.txt! There are actually some questions of note here that you will need to answer.
Submit your program to the Hwk7 submission folder on hedwig, following the instructions detailed in Lab A. You should upload all you classes, as well as the README.txt.
The homework is due at midnight on Mon May 13. Note that this is the Monday of finals week, the night of the exam (so you can put finishing touches on stuff after the exam).
Extensions
- You might make a graphical display of the documents and their similarities, similar to the picture above. You could even re-use your graph layout labwork to make things show up nicely!
- If you're feeling good about your program's scalability, why not try running it on larger and larger data sets? Maybe download some books from Project Gutenberg and see how many phrases are shared by famous authors. Note that this is a neat trick for discovering quotations (when do authors quote one another?), cliches (what are common phrases that get used a lot), when news is really a press release, and so forth!
Grading
This assignment will be graded based on approximately the following criteria:
- Your program calculates and reports the number of matching n-grams for a given document set [35%]
- Your program works with reasonable efficiency for the small document set [15%]
- Your program works with reasonable efficiency for the medium document set [10%]
- Your program works with reasonable efficiency for the large document set [10%]
- Your program demonstrates good Java style [15%]
- Program is fully documented with complete Javadoc comments [10%]
- The README is completed [5%]