CS 261 Homework 6 - Huffman Encoding and Decoding
Due Tues Nov 18 at 11:59pm
Overview
In this assignment, you will pratice working with tree data structures to make one of the most useful kinds of tree: a Huffman coding tree. Huffman coding is a technique for performing data compression--that is, for taking data (such as txt files) and modifying it so that they take up less space. Huffman coding is particularly useful for text, though it can be applied to other forms of media (such as images) as well.
Huffman encoding uses the idea that all data in computers is written as a sequence of bits--that is, of 0s and 1s. With Huffman encoding, rather than using the same number of 0s and 1s for each piece of data (e.g., for each character in a text file), you instead use a smaller number of bits to store more common characters (like the letter 'e'), and a greater number of bits to store less common characters (like the letter 'x'). For example, instead of using 8 bits for every 'e' and 8 bits for every 'x', use 3 bits for 'e' and 12 bits for 'x'. Because 'e' shows up much more frequently in (English) text, encoding a large text file this way can significantly reduce its size.
Huffman trees are a type of binary tree used in performing this kind of conversion. A Huffman tree includes all the elements (characters) of your data, with more common elements found closer to the root. The distance and path away from the root is used to determine what bits (what 0s and 1s) are used to represent each character. This tree can be used both for encoding and for decoding--you can look up the Huffman coding for particular characters, and see what characters are associated with particular Huffman codes. In effect, the tree lets us map between characters and bits!
More details on Huffman trees can be found in the textbook in Section 6.1 and 6.6 (pg 345). You should look over this section carefully; it has details about the data structure and example code that may be informative for this assignment.
For this assignment, you will be implementing a Huffman Tree. You will also be implementing classes that use this tree to perform encoding and decoding--a system that can encode and decode data is called a codec. You will be creating codecs for processing simple Strings in and out of their bitwise representation (the 0s and 1s, what is called a bit string), and for encoding and decoding full text files.
This is a large assignment, involving a number of moving pieces and some new concepts (trees, bit strings, etc). However, most of the tasks should be straightforward--I have identifed almost exactly what methods you will need to write. Nevertheless, be sure to start early, and ask for help if you get stuck!
This assignment should be completed individually. You are welcome to ask for help from me, or from your classmates (but remember to follow the Gilligan's Island rule)!
Objectives
- To practice implementing and working with trees
- To learn about and understand bitwise representation and bit strings
- To practice utilizing previous data structures, such as queues and maps
- To utilize interfaces and polymorphism
- To practice with other classes for file processing
Necessary Files
You will need a copy of the Hwk6.zip file. This file contains a lot of classes and files you will need to import into Eclipse. (I am providing you with lots of "starter" code that handles some of the dirty details of working with files and such, so you can focus on dealing with the Huffman tree. That said, you will need to write some code to utilize your tree data structure).
The zip file contains the following classes. You should read through them carefully; the code is well commented, with TODO comments marking methods that you will need to complete. If there are any questions, let me know.
-
AbstractHuffmanTreeandAbstractBinaryTreeare interfaces that your HuffmanTree will need to implement. These contain lists of public methods that your HuffmanTree should have. Note that these are the only public methods your HuffmanTree should have, though you are welcome to make as manyprivatehelper methods as you like. You should not modify these classes.- In particular, because a HuffmanTree is a special kind of BinaryTree, we have a separate interface for each one---with the
AbstractHuffmanTreeextendingAbstractBinaryTreeThus with polymorphism you will be able to treat your specific implementation as anAbstractHuffmanTreewhen you need to consider how it works with different bits, and as aAbstractBinaryTreewhen you just care about the values of nodes in the tree structure! - More details about implementing the individual methods you'll need can be found below. Some of the
AbstractBinaryTreemethods you will find examples of in lecture code.
- In particular, because a HuffmanTree is a special kind of BinaryTree, we have a separate interface for each one---with the
-
HuffmanStringCodecis a class that provides functionality to encode and decode basic Strings using a HuffmanTree. This class will instantiate and call methods on your HuffmanTree. Note that I have provided some of the functionality for you--all you will need to implement are theencode()anddecode()methods. You will need to modify this class. -
HuffmanFileCodecis a class that provides functionality to encode and decode text files using a HuffmanTree. This class will instantiate and call methods on your HuffmanTree. I have provided some of the functionality for you, but again you will need to fill in theencode(), anddecode()methods.- See below for more specifics on how to implement these methods!
-
HuffmanTesteris a runner class for the codecs. This includes code to demonstrate that String encoding/decoding works, and some code to enable you to easily work with files. Uncomment the appropriate code based on what you are testing. You will also likely want to write your own tester to check indivdiual methods. -
BitStringFileis a class with two inner classes:BitStringFile.ReaderandBitStringFile.Writerwhich will help you read and write bit strings to files. The Reader acts similar to the Scanner--you can read either an individual line or the rest of the text file as a giant bit string (see below). The Writer does the opposite: you can write a single line (similar to using System.out.println()), or you can write a giant bit string to a file.
The zip file also contains a couple of files you can use to test your program: hello.txt is a tiny file which is great for testing (because it only has a few characters); gettysburg.txt is the text of Lincoln's Gettysburg address, which adds a few more complications; alice.txt is the complete text of Lewis Carroll's Alice's Adventures in Wonderland--this is the kind of large text file you can compress using your program!
The zip file also contains a secret message ("secret.encoded") that I encoded using this program; in the end, you should be able to decode this file and see what it says! (Note that this has not be robustly tested across systems; if you have problems (but everything else works), let me know).
And last but not least, the zip file also contains the README.txt for this assignment, which you will need to fill out.
Whew!
A Short Introduction to Bit Strings
Adapted from http://www.cs.duke.edu/csed/poop/huff/info/
In a computer, all data is encoded a sequence of bits--that is, as a list of 0s and 1s. These sequences, called bit strings, are binary numbers--numbers in base 2. So in effect, all data can be seen as a sequence of numbers.
You may recall from the LetterSet lab that it is possible to cast a char into an int, or to talk about the int representation of a char. For example, the int value of 'a' was 97. This is called the
Unicode value
or
ASCII value
(Unicode is like an extension of ASCII--supporting more strange characters).
Since 'a' is represented by 97, that means an 'a' in a String can also be represented by the binary value of 97: or 1100001. This list of 0s and 1s would be the bit string version of 'a'.
- Note that there are seven (7) 0s and 1s used to represent the character. This is because it takes 7 bits to represent a letter. (Really it takes 8 bits--a full byte--but in ASCII we don't use the "high" bit. So 'a' has a leading 0 that we're ignoring).
- Every character has a unique number and bit string that represents it (you can even see a full list in a nice browsable interface here).
Of course, we don't necessarily need the full 7 bits to represent some text. For example, the String "go go loggers!" only has 8 different characters (including the space and exclamation point), so we could encode these characters using only 3 bits each:
| char | ASCII | binary |
|---|---|---|
| g | 103 | 1100111 |
| o | 111 | 1101111 |
| l | 108 | 1101100 |
| e | 101 | 1100101 |
| r | 114 | 1110010 |
| s | 115 | 1110011 |
| ! | 33 | 0100001 |
| space | 32 | 0100000 |
| char | code | binary |
|---|---|---|
| g | 0 | 000 |
| o | 1 | 001 |
| l | 2 | 010 |
| e | 3 | 011 |
| r | 4 | 100 |
| s | 5 | 101 |
| ! | 6 | 110 |
| space | 7 | 111 |
The string "go go loggers!" would be written (coded numerically) as 103 111 32 103 111 32 108 111 103 103 101 114 115 32. Although not easily readable by humans, this would be written as the following bit string (the spaces would not be written, just the 0's and 1's):
1100111 1101111 0100000 1100111 1101111 0100000 1101100 1101111 1100111 1100111 1100101 1110010 1110011 0100001
This is how the computer sees the String! Note that this takes 14*7=98 bits (98 0s or 1s).
If we use the 3-bit encodings, we can write the same String (coded numerically) as 0 1 7 0 1 7 2 1 0 0 3 4 5 6, or as a bit string:
000 001 111 000 001 111 010 001 000 000 011 100 101 110
Again, the spaces wouldn't be included in the bit String. This only takes 14*3 = 42 bits (42 0s and 1s), which is less than half the size!
More space can be saved if we a variable number of bits. For example, if we only used 2 bits to encode the g, o, and space (which are used frequently), but used 4 bits to encode the l, e, r, s, and !, our bit string would only have (9*2)+(5*4)=38 bits. This is the essence of Huffman Encoding--an algorithm for determining an "optimal" number of bits based on the frequency of characters used.
Huffman Trees
A Huffman Tree is a binary tree (really a binary trie) that encodes bit strings for characters in the "path" from the root to that character. If you trace the branch from the root to the character, writing down a 0 whenever you go left and a 1 whenever you go right, you'll have written down the bit string for that character!
Huffman Trees are then constructed so that more frequent elements are at a higher level of the tree, so have a shorter path from the root. This means that they have shorter bit strings (in terms of the number of 0s and 1s), so take less bits to encode.
For example, we might produce the following Huffman tree that provides the following encoding (for the letters in "go go loggers!"):
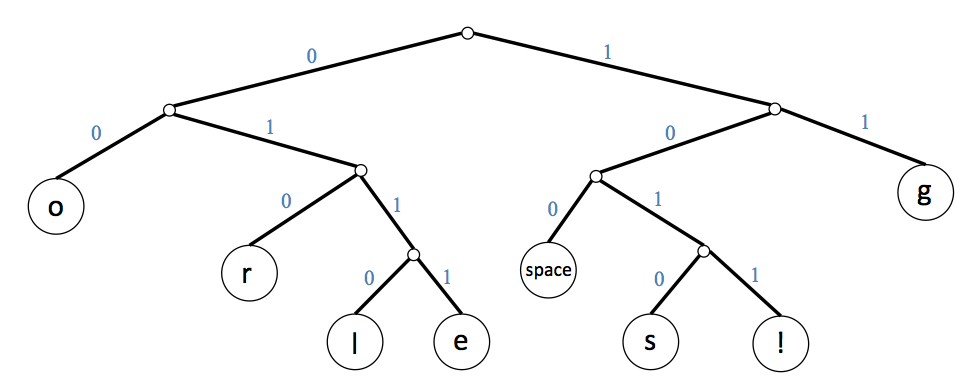
| char | bit string |
|---|---|
| g | 11 |
| o | 00 |
| l | 0110 |
| e | 0111 |
| r | 010 |
| s | 1010 |
| ! | 1011 |
| space | 100 |
You can decode a particular bit string using a Huffman Tree by starting at the root of the tree, and then traveling down the branches by following the bits in the bit string. Every time you come to a leaf (to a character), write down that character and go back to the root--and keep going through the bit string. This lets you convert bit strings back into letters!
For practice, try decoding the following bit string using the Huffman table above:
010001010011110011001111011001111010
Pro Tip: this table and bit string can provide good "known" values for you to test your code with!
Again, more details and examples of Huffman Trees can be found in the textbook, as well as at http://www.cs.duke.edu/csed/poop/huff/info/.
Assignment Details
Your assignment is to implement a HuffmanTree and complete the provided codecs, thereby allowing you to encode and decode both Strings and text files.
This assignment can be seen as being made up of three parts: implementing the HuffmanTree, completing the HuffmanStringCodec, and completing the HuffmanFileCodec. You will need to implement the HuffmanTree first; however, you may wish to work on the HuffmanStringCodec simultanously, in order to help test your tree's functionality.
First, have you carefully read and followed the above discussion of bit strings? You should have!
HuffmanTree
The main class you will be creating will be the HuffmanTree class. This class should be an ADT representing a Huffman Tree.
-
Your
HuffmanTreeclass should be a generic class (being able to encode a variable data type--not just Characters!). It should also implement theAbstractHuffmanTree<E>interface (and by extension, theAbstractBinaryTree<E>interface!. -
A
HuffmanTreeis a kind of BinaryTree. This suggests a few different ways to implement the ADT. One strategy would be to make it a subclass of the BinaryTree class we've discussed during lecture. Another strategy (the one demonstrated in the textbook) would be to have it include a BinaryTree as an instance variable, thus acting as a kind of "wrapper" class.However, the easiest and cleanest implementation for this assignment will be to make the HuffmanTree a brand new class that has the same structure (and some of the same methods) as a BinaryTree; similar to how your DecomposableShape was a double linked-list.
-
The
HuffmanTree's innerNode<E>class will need to have one additional piece of information: It should have an instance variable that is the bit string of the item that Node contains. While this information duplicates that established by the tree's structure (i.e., you can figure out the Node's bit string by traversing too it), storing the information will make it much easier and faster to fetch the codes for all the elements in the tree.- It might also be handy to give the Nodes a method that returns whether or not it is a leaf.
-
Your HuffmanTree will also need to have a "weight" instance variable (an
int), that will be used when building the HuffmanTree from a set of element frequencies. -
Important tip! Make sure that the root of your tree is never
null. You can have the data in that Node be null, but the root itself needs to point to a Node object!
-
The
Once you have the inner Node class, instance variables, and constructors put together, you can start implementing the methods required by the AbstractHuffmanTree interface. Details on the HuffmanTree specific methods are below:
-
void add(E element, String bitString)I recommend you implement this method first. This will allow you to create a HuffmanTree with an explicit set of elements and codes--for example, you could call this method multiple times to create the example tree and encoding table for "go go loggers!" described above. Such direct creation is very handy for testing!
-
For this method, you will need to iterate through the characters in the provided bitString. Use these characters to move a pointer to the "current node" down the tree, until you find the correct spot to add the element (this is a process somewhat similar to adding an element into an ordered linked-list!) If the character is a '0', go to the left. If the character is a '1', go to the right.
- Note that if the current node has no child where you want to move (e.g., you have a '0' so want to go left, but there is no left child), then you will need to create a new Node with no element inside it (data is null) in order to fill out the tree. This is expected behavior; only the leaves of Huffman Trees have data--the "inner" nodes (like the root) will be empty. Not having a path to go down tells you that you need to create that empty node!
- But the last node in the list will contain the element you are storing
- Remember to also assign the
bitStringto the node's instance variable!
- You can test this element by printing out the tree using one of the tree traversal printers, or by inspecting the nodes inside the debugger. The tree should have the same structure as the one pictured above!
-
For this method, you will need to iterate through the characters in the provided bitString. Use these characters to move a pointer to the "current node" down the tree, until you find the correct spot to add the element (this is a process somewhat similar to adding an element into an ordered linked-list!) If the character is a '0', go to the left. If the character is a '1', go to the right.
-
String getBitString(E element)A good next step is to implement the getBitString() method. This method should search the tree for the Node containing the given element, returning that Node's bitString when you find the node (see why we stored the bitString?)
- It is possible to perform this search recursively, using a depth-first search (similar to the traversals we've done in class, and that you did to print the elements of the tree). However, the whole point of the HuffmanTree is that we're more likely to encode elements that are near the top of the tree (that's why they are near the top). Thus instead you should use a breadth-first search for efficiency. This will let you check the top nodes (those with the shortest bitStrings and the most common) first, decreasing the amount of Nodes you actually need to look at.
-
Recall that a breadth-first search uses a queue to iterate through the nodes: push the root onto the queue. Then while the queue isn't empty, pop an element off the queue, check if that's what you're looking for, and if not push its children onto the queue.
- You can use the
Queueclass that we implemented in lecture, or you can just use aLinkedList, with theaddLast()method acting as push and theremoveFirst()method acting as pop.
- You can use the
- Again, you can test this method with the example table above. Build your HuffmanTree using the previous add() method, and then test that getting each character gives you the bitString you expect (the one in the table)!
-
String getCodeList()Once you've written the getBitString() method, it's a quick step to figure out the getCodeList() method.
- This method should also use a breadth-first traversal (with a queue)--but in this case you'll be visiting all the nodes, and building a String of the elements and their codes.
- It is very, VERY important that you get the format of the returned String correct. Look carefully at the provided JavaDoc for what this String should look like. (File encoding and decoding will depend on this!)
-
It should be easy to test this method--just print out the returned String and make sure it looks correct! You can keep using your same testing table.
- In fact, once you have this method, it will become an invaluable tool for testing the rest of your program!
-
void createFromFrequencies(Map<E, Integer> frequencies)The last HuffmanTree method is the most involved. It fills the tree from the provided frequency map.
-
The algorithm for building the tree from a set of frequencies is described on page 348 of the textbook (along with a detailed example, and even sample code!). The basic idea is to use a Priority Queue of "subtrees" (where each subtree initially has a single element and frequency or "weight"), and then combine the trees with the smallest weights to make a single tree with a bigger weight. Put that bigger tree back in the priority queue and keep going until you've combined everything into a single tree. That remaining tree is your completed HuffmanTree. To restate the textbook:
make new HuffmanTree for each item push all the trees into a PriorityQueue while the priority queue has more than 1 item pop the first two trees set them as the subtrees of a new HuffmanTree whose weight is the combined weight of the children push the new tree back into the queue-
The Java Collections framework has a built-in
PriorityQueue
class that you can use for this purpose. This PriorityQueue will order items by their "natural ordering"
- Note that the
PriorityQueueclass calls pushoffer()and poppoll(). - In order to give the HuffmanTree class a "natural ordering," you'll have to make it implement the
Comparable<HuffmanTree<E>>interface. The compareTo() method should return a number based on the difference in weights of the trees (so ifthis.weight < other.weight, return -1, etc). - Remember a class can implement multiple interfaces by separating them with a comma!
- Note that the
- Once you've collapsed everything down to a single HuffmanTree object, you can have the current tree "take over" that by having
this.rootpoint to that tree's root! The wonders of pointers and Nodes!
-
The Java Collections framework has a built-in
PriorityQueue
class that you can use for this purpose. This PriorityQueue will order items by their "natural ordering"
-
There's actually one more piece to this, which is an appropriate use of a helper method. After you've built the HuffmanTree, you'll need to go through and make sure that each of the leaf nodes have stored their proper bitString (for use with the getBitString() method you wrote earlier).
- You might call this method
assignCodes()or something similar. Make it private, since it is just a helper method. - The easiest way to assign these codes is to recurse through the tree, building up each bitString as you go, and then assigning that bitString whenever you hit a leaf (which is also when you stop recursing). Note that your method will actually have two recursive calls--one that goes down the left branch and one that goes down the right.
- The textbook has an example of this recursive algorithm in the "printCode()" method described on page 351. Use that as a starting point!
- Remember to make a launcher for this method so it has a nice interface, and to call the method at the very end of your
createFromFrequencies()method!
- You might call this method
-
This method is a bit harder to test. Try calling it with the frequencies listed in the book's examples, or with the frequencies from the "go go loggers!" example (in fact, you can use some of the
HuffmanStringCodecmethods to do this easily).- You can make sure your HuffmanTree looks accurate by inspecting the bitstring codes via the previously implemented methods. Do the most common letters have shorter bitStrings?
-
The algorithm for building the tree from a set of frequencies is described on page 348 of the textbook (along with a detailed example, and even sample code!). The basic idea is to use a Priority Queue of "subtrees" (where each subtree initially has a single element and frequency or "weight"), and then combine the trees with the smallest weights to make a single tree with a bigger weight. Put that bigger tree back in the priority queue and keep going until you've combined everything into a single tree. That remaining tree is your completed HuffmanTree. To restate the textbook:
Be sure and test and comment your class thoroughly. Once this is tested and working, you can put it aside and just finish up the codecs!
HuffmanStringCodec
The HuffmanStringCodec and the HuffmanFileCodec have 3 primary methods: createTree() which sets up a HuffmanTree, encode() which encodes a message using the HuffmanTree, and decode() which takes an encoded message and converts it back to normal.
-
With both classes, the createTree() method has been provided for you, (since the real work in setting up the tree occurs in your createFromFrequencies() method).
- And since this method already exists, you can use it to test your createFromFrequencies() method!
-
String encode(String input)This is a straightforward method to write: simply iterate through the provided String, and convert each character into a bitString using the HuffmanTree. Combine all those bitStrings and return them.
-
This method only makes sense if the HuffmanTree has been created. If it has not (i.e., if the variable is
null), you should have the method throw anIllegalStateException. See the getEncoding() method at the bottom of the class for an example (which is provided as a debugging tool).- Be sure that your Exception includes an informative message about what the exception is!
- You can test this method with the same sample HuffmanTree and inputted Strings; see if you get the bitString you expect!
-
This method only makes sense if the HuffmanTree has been created. If it has not (i.e., if the variable is
-
String decode(String bitString)This method will require you to interact closely with the HuffmanTree. In order to decode a bit string, you'll need to iterate through each bit, and use whether that is a 0 or a 1 to "traverse" down a branch (a subtree) of the HuffmanTree. Once you hit a leaf, you can add the letter contained in that leaf to your output String.
- This is the very algorithm that was described in the section above, and is the core of the HuffmanTree usage. Note that this algorithm is also explained and demonstrated in the textbook on page 352. In fact, your code will look very similar to that!
-
This method only makes sense if the HuffmanTree has been created. If it has not (i.e., if the variable is
null), you should have the method throw anIllegalStateException. See the getEncoding() method at the bottom of the class for an example. - This should be easy to test--simply check that the bitString you've generated gives back the original message.
HuffmanFileCodec
For the HuffmanFileCodec, the createTree() methods (there are two versions!) are provided for you, in order to help handle some of the file processing.
-
void encode(File input)With this method, you will produce a HuffmanTree for the given file, then read through each character of the file, get the bitString of that character, and then write the entire bitString of the file to a second, output file. There are a few extra details necessary as well for encoding the file properly.
- The first thing you should do is create a HuffmanTree for the given file. Use one of the provided
createTree()methods. -
You'll then need to read through the file again in order to turn its contents into a giant bitString.
-
The
Scannerwon't let you read through a file character by character. So the easiest solution is to instead use a FileReader to do this (similar to what is done in thecreateTree()method. -
You can read a single character using the
read()method of this class. However, this doesn't actually return achar, but instead anint--you'll need to cast it into achar.- If the
read()method returns a -1, that means that there was nothing left to read!
- If the
- As you read each character, convert it into a bit string using your HuffmanTree, and then append that bit string to your overall bitString (I recommend using a StringBuilder for this).
-
Lastly: files will be encoded with a special character
EOTwhich marks the end of the file (this is necessary because there are a few extra 0s used as padding, and we don't want to mistake those for an extra letter!). Thus you should append the bitString for theEOTcharacter (defined as a constant) to your giant bitString. The createTree() method already makes sure that theEOTcharacter is in your HuffmanTree - Remember to close() the reader when you're done!
-
The
-
You'll now need to write the encoded data to a file.
-
The file should have the same name as the one you read, but with a different extension. You can look up the String and File methods to do this, but one technique is:
File output = new File(input.getPath().substring(0, input.getPath().lastIndexOf('.'))+".encoded");
-
You should use a
BitStringFile.Writerobject to write to the file; the constructor takes the file to write to as a parameter. -
The first thing you should write to the file is a single line containing the
codeList. This will allow you to decode the file later (because you'll have saved the encoding in the file itself).- You can get the codeList using an appropriate method from the HuffmanTree class.
-
Once you've gotten that String however, you will need to make one minor addition: we want everything to be on a single line, so you'll need to replace any newline characters (which themselves are encoded!) with "placeholder" text--e.g., replace "\n" with "<newline>". This will allow you to actually write the entire codelist on a single line. You'll need to do this for both kinds of newline characters:
codeList = codeList.replace("\n", "<newline>"); codeList = codeList.replace("\r", "<return>");
- Write the codelist to the file using the
writeLine()method
-
Now you're ready to write your giant bitString to the file. Try using the
writeBitString()method.
-
The file should have the same name as the one you read, but with a different extension. You can look up the String and File methods to do this, but one technique is:
To test this method, you can try printing our your giant bitString for a short textfile (e.g., "hello.txt") and manually check that you're getting the right encoding.
- The first thing you should do is create a HuffmanTree for the given file. Use one of the provided
-
void decode(File encodedFile, PrintStream out)This last method read in the encoding from the given file, construct a HuffmanTree from that encoding, read in the bit string that is the rest of the file text, and then decode that bit string using the HuffmanTree. Finally, you should print() the decoded text to the provided
outvariable (which can either be a differentFileorSystem.out).- In order to read from the encoded file, you should use a
BitStringFile.Readerobject. The constructor for this object takes as a parameter the file you want to read. -
Start by reading in the first line of the encoded file, which will be the codeList (that you wrote out in your encode method). You can read this with the
readLine()method.- You'll need to replace the placeholder
<newline>and<return>labels with the appropriate newline characters, reversing the process that you did when encoding. - Take the corrected codeList and use it to create a HuffmanTree using the appropriate
createTree()method
- You'll need to replace the placeholder
-
You can then read in the rest of the text file as a giant bitString using the
readBitString()method. -
Now that you have the bitString and the HuffmanTree, you can decode it into text using the same strategy (and even much of the same code) as in your StringCodec class!
- There is just one complication: remember that
EOTcharacter? If you ever decode that character, you need to stop reading through the bitString (basically quit out of your loop)--this will keep you from treating any left over 0s as letters!
- There is just one complication: remember that
-
Finally, take your decoded text and output it. Note that this method takes in a
PrintStream
as a parameter--a PrintStream is basically a place we can output characters.
System.outis one such PrintStream; so you can imagine that someone has passed theSystem.outobject as a parameter! A file can also have a PrintStream, so that we can "print" to a file the same way you would to System.out.- In other words: take the character you've decoded and
print()it to the PrintStream!
- In other words: take the character you've decoded and
You can test this method by trying to decode the file you previously encoded, and making sure you get the same thing back again! If you don't, you can try following the individual bits (0s and 1s) and see if they are letting you navigate your tree correctly.
- In order to read from the encoded file, you should use a
And that should do it! Make sure all your methods and classes are fully functionally and documented. If there are any problems, let me know.
Timeline
This is a long, involved assignment. There are a numerous pieces, but you should be able to get them all done in the time allotted if you work diligently. An (admittedly) aggressive timeline is as follows:
- Start by reading through the assignment carefully, particularly checking that you understand the idea of a bit string and how the HuffmanTree will work. Do this on Thursday Nov 06.
- Start by creating the
HuffmanTreeclass. Fill in the inner Node, the BinaryTree methods it will use (you can adapt the code from the lectures, found on Moodle), and filling in the skeleton of any required methods. Do this by Fri 11/07. - Implement the
add()method next; this helps with testing. Do this by Sun 11/09 - Implement the
getBitString()method by Mon 11/10 and thegetCodeList()method by Tues 11/13. - You should implement the
createFromFrequenciesmethod and otherwise finish up your HuffmanTree by Wed 04/07. - Next implement the two methods for the
HuffmanStringCodec. You should be able to do this by Fri 04/09 (they're pretty straightforward). - Finally, implement the encode and decode methods of the
HuffmanFileCodec. These are not too much harder, and you should be abe to finish them by the deadline.
Extensions
There are a couple of places you could improve or extend this assignment. These alterations can be worth a few points of extra credit.
- One of the flaws with this approach is that we need to store the codelist in the file; this takes up extra room. There are other ways to store the codelist such that it takes up less room. For example, rather than writing out the whole bitString, you might write out a number representation. For example:"g:3,o:0,l:6,e:7,r:2,s:10,!:11, :4" You'll need to handle leading 0s...
-
Huffman encoding can be applied to more than just txt--as I mentioned in class, it is part of the common JPG compression scheme. You can encode an image by applying the encoding algorithm to the colors of pixels, rather than to the characters of a String. Then simply store a list of the "encoded" pixel colors, and decode by reading them out to refill the pixel array (e.g., using a BufferedImage).
- You can use your same (generic) HuffmanTree, just write a new codec!
- You will get better compression with black and white images, since they are more likely to have "frequent" colors that give you the compression.
- Indeed, a naive approach to this often won't provide much space savings. Independent research can find the ways to do more effective Huffman encoding on images--it involves taking a "difference" between an image and an "average" of the nearby pixels.
Submitting
BEFORE YOU SUBMIT: make sure your code is fully documented and functional! If your code doesn't run, I can't give you credit! Your name should be in the class comment at the top of each class.
Submit all your classes to the Hwk6 submission folder on vhedwig. Make sure you upload your work to the correct folder!. You should upload your entire src folder with all your classes. Be sure to complete the provided README.txt file with details about your program.
The homework is due at midnight on Sun, Nov 16. Note that we also have the second exam the following Monday; getting the homework done earlier will give you more chance to study!
Grading
This assignment will be graded out of 38 points.
- Functionality (32pt)
- [2pt] Your HuffmanTree is implemented as a binary tree with appropriate constructors and instance variables
- [1pt] Your HuffmanTree implements the required interface(s)
- [1pt] Your HuffmanTree has a working add() method
- [1pt] Your add() method creates new (possibly empty) nodes as appropriate
- [1pt] Your add() method assigns the given bitString to the Node's instance variable
- [1pt] Your HuffmanTree has a working getBitString() method
- [1pt] Your getBitString() method uses a breadth-first search
- [1pt] Your HuffmanTree has a working getCodeList() method
- [1pt] Your getCodeList() method returns a properly formatted String
- [2pt] Your HuffmanTree has a working createFromFrequencies() method, following the given algorithm
- [1pt] Your HuffmanTrees are Comparable
- [2pt] Your createFromFrequencies method assigns appropriate bitStrings to each Node
- [2pt] Your HuffmanStringCodec has a working encode() method
- [3pt] Your HuffmanStringCodec has a working decode() method
- [1pt] Your HuffmanStringCodec traverses the tree as a BinaryTree, without inappropriate casting
- [1pt] Your StringCodec methods throws informative exceptions if the tree is not created
- [1pt] Your FileCodec's encode() method creates a HuffmanTree from a file
- [2pt] Your FileCodec's encode() method encodes the file character by character
- [1pt] Your FileCodec's encode() method writes the codeList to file, with replaced newline characters
- [1pt] Your FileCodec's encode() method writes the encoded bitString to a
.encodedfile - [1pt] Your FileCodec's decode() method creates a HuffmanTree from an encoded file
- [1pt] Your FileCodec's decode() method reads in the bitString from a file
- [1pt] Your FileCodec's decode() method stops at an EOT character
- [1pt] Your FileCodec uses the HuffmanTree to decode the file
- [1pt] Your FileCodec prints the decoded file to a PrintStream
- Style (3pt)
- [1pt] You have appropriately used generics in your program
- [1pt] You have used descriptive method names (that indicate how the method will be used!)
- [1pt] You have written extensible code, so that your HuffmanTree can be used for different data formats
- Documentation (3pt)
- [1pt] All methods include JavaDoc comments with appropriate JavaDoc tags (
@paramand@return). - [1pt] You have included sufficient inline comments explaining your code.
- [1pt] The README is completed