CS 261 Homework 3 - Baby Names
Due Mon Oct 06 at 11:59pm
Overview
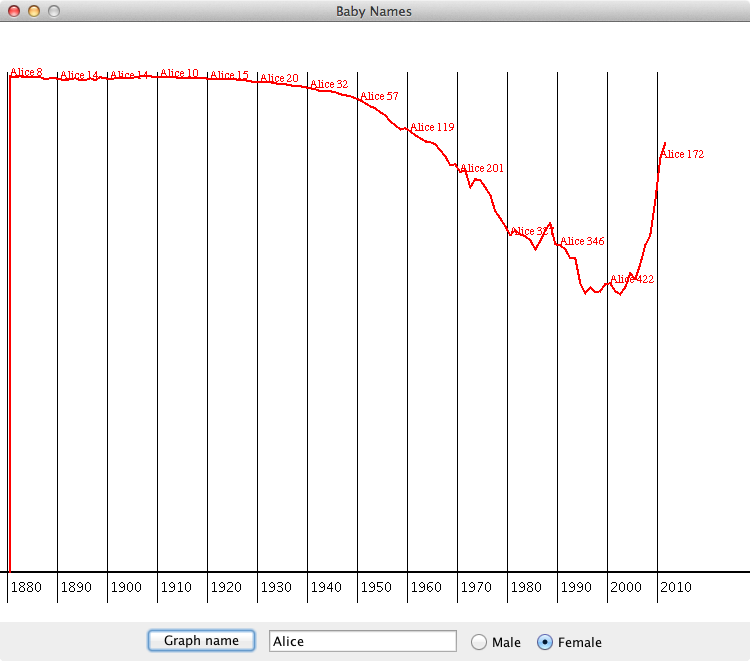
The Social Security Administration (SSA) provides annual information about the popular of particular names for babies. They have a website that allows you to look up the popularity of a particular name. You will be writing a program that provides similar functionality, allowing the user to look up a baby name and see a graph of its popularity over time:
This assignment should be completed individually. You are welcome to ask for help from me, or from your classmates (following the Gilligan's Island rule)!
Objectives
- To continue practing implementing ADTs and working with maps
- To practice with file IO and parsing, using large real-world data sets!
- To practice with GUIs, graphics, and drawing, including some new classes with help of the Java API and tutorials
Necessary Files
You will need to download the cs261-hwk3.zip file. which contains a few GUI classes to help get you started (and make sure you can get finished in the time allotted!) Read through the code in these classes to make sure you understand what is going on.
It also contains the README.txt for this assignment--be sure and answer the questions thoroughly for full credit!
Additionally, you will also need to download the data set of national baby name rankings from the SSA's website at http://www.ssa.gov/oact/babynames/limits.html. This is a 7mb zip file, with full name data for the years 1880 through 2013. Be sure and extract the files from the zip folder for processing.
The Data
One of the neat things about this project is that you will be using real data (and lots of it!). This has not been filtered or simplified by the professor; you are working with actual, real numbers. This data set includes pretty much every name ever given in the United States over the past 130 years!
The data can be found in multiple text files, each named in a format like "yob2013.txt"--the number in the filename represents the year. Each file contains a list of baby names ordered by popularity--that is, the first name in the file is the most popular female name, the second name is the second most popular female name, etc. Female names are listed before male names, so the first male name listed in the file would be the most popular male name, etc.
Each name entry is a comma separated list that looks like has the following format:
Joel,M,2697The first item is the name, the second is the sex (M for male and F for female), and the third is the total number of people born with that name in that year.
- Note: for this assignment, we are not interested in the absolute numbers, but rather in the rank, which is indicated by the order of the names! When doing data processing like this, it is pretty common to "throw out" or ignore certain pieces of data.
Note that the data just includes literally what people put on the forms, so there are things like "A" and "Baby" recorded as names (the data is more cleaned up in the later years). We will not worry about that, and we will not combine names that are similar in some sense – "Cathy" and "Catherine" and "Kathryn" and "Katie" and "Kati" will all count as different names.
Assignment Details
You will be developing this program mostly from scratch, though I will give you some guidance on how to structure the classes and the algorithms. There are really two parts, each of which is moderately complex, but doable. There will be bugs (oh yes, there will be bugs), so make sure to get started early so you don't run out of time!
1. Loading the Names
Your first step will be to load the data from the data file into a format that you are able to work with. You should use two classes for this: NameRecord and NameDatabase. NameRecord objects hold all of the ranking data for a particular name (e.g., the ranking of that name for all years), and the NameDatabase object will hold a collection of NameRecords and provide methods that allow the user to find the data on a particular name.
-
NameRecord:This class will act as an ADT and encapsulate all of the ranking data for a given name and gender. Each NameRecord will have the data for a single name from all the years--so the "Joel (male)" record would have the popularity in 1880, 1881, 1882... and so on. In effect, theNameRecordwill provide a mapping between a year and the name's ranking that year (so that you can look up a ranking by year for a particular name).- Think about what attributes (instance variables) your ADT will need. What parameters will your constructor take? What components make up an "entry" in the data file?
-
You will also need a getter that lets you get the ranking for a particular year (remember, the
NameRecordholds data for all the years!), as well as a setter to set the rank for a given year. A toString() method may be helpful for debugging.- For practice: your code should throw an
IllegalArgumentExceptionif a getter or setter is called with a year that is outside of the accepted range.
- For practice: your code should throw an
- Avoid using "magic variables"! Instead, make constants to help keep your code readable and easily extendable. For example:
int MIN_YEAR(1880),int MAX_YEAR(2013),char MALE('M'), andchar FEMALE('F'), andint MAX_RANK(e.g., 1000). -
Note that the rank for any particular year should be represented by a value between 0 and the MAX_RANK (e.g., 1000). A rank of 1 means that the name was the most popular for that year, while a rank of 997 was not very popular. To keep the program from getting too big, you should start by only including the 1000 most popular names should be given rankings (that's your max rank); a rank of 0 means that the name didn't score in the top 1000 that year at all.
- Your ranks for all years should "default" to 0. Note that if you make a new
int[], it already has default values of 0!
- Your ranks for all years should "default" to 0. Note that if you make a new
-
NameDatabaseThis class will act as an ADT for the the entire list ofNameRecords. It will need to provide two pieces of functionality: (1) it will parse the data files and produce a list of NameRecords, and (2) it will provide an interface for searching the name records.- Always start by thinking about what attributes your class should have, and filling in the constructor so that it assigns values to those variables. (Will your constructor want any parameters?)
- You can use any of the Lists or other data structures that we've discussed in class to store your NameRecords. Note that in effect, you will be creating a kind of map that lets you look up NameRecords by name; you can use an ArrayList to structure this, similar to the
ArrayListMapwe discussed in class. More details are below. - This class's public interface will need to include a
getRecord()method that returns aNameRecordfor the given name (ignoring case) and sex. - You will also likely want to make a
readDataFiles()helper method to help keep your code organized (see below)
The biggest (and hardest) part of this assignment will be parsing the data files. You should write a readDataFiles() method in your NameDatabase that does this work, and then call that method from elsewhere (such as inside the constructor).
- I recommend passing in the path to the data directory as a parameter, but you can also prompt the user to choose the directory using a JFileChooser; similar to what we discussed in class and what was used in the MovieLibrary project.
-
Your method will need to read through all of the files in the data directory. You can get an array of these files inside a directory by using the
listFiles()method (a directory or folder is also represented by a File object. You can get the name of the file by using thegetName()method, and extract the year from that by usingsubstring()andInteger.parseInt(). Your program should not assume that all years are present in the data set!- It's straightforward to loop through files; I recommend you start by processing just one file, make sure that works, and then add in a loop to do all the files.
- It is also not a bad idea to test and debug your program with only a portion of the data set. Maybe just the years 2003-2013. You can temporarily remove all the other years, and adjust your MIN_YEAR and MAX_YEAR constants to compensate.
- For each file in the directory, you'll want to use the Scanner to read through each line of text (following the iterator pattern we talked about in class).
-
You'll also want to use a counter to keep track of which "rank" the current line of the file represents. Start this number at 1, and increase it for each name you process.
- You will want to keep track of male and female names separately, or to reset the counter when you get to the other sex.
- You will also want to be sure and not process names beyond the MAX_RANK---we're only interested in the top 1000 names of each sex for each year (for now...). Make sure you don't try to "process" any names beyond the MAX_RANK; it will drastically slow down your program!
- After you have read each name line, you will need to "parse" that String to pull out the name and gender (you should already have the rank at this point). You can do this using
indexOf()andsubstring(), creating aScannerfor the string, or using thesplit()method of the String class. -
This is the tricky part: think about it carefully! This has to do with how NameDatabase acts as a map, and how that map can be made efficient.
Generally, when you read in a name you'll want to create a new NameRecord for that name. However, what happens if we created a name record for "Alice" in 1880, and then we come across "Alice" again in 1881? We don't want to create a new record (because one record holds information for all the years)--instead, we want to update the existing "Alice" record to record the rank for 1881. Think about how you can solve this problem (and quickly!)--if you need help, check the spoiler below!
- Start by searching through your current list of NameRecords to see if you find one that matches the current name and sex. If so, that is the record you will want to update.
- If you do not find an existing NameRecord to use, create a brand new NameRecord with the current name and sex, and update that record.
- You'll want to make sure to not keep searching through the list once you've found a NameRecord--the searching will get increasingly slow as your name list grows, until eventually you'll be looking through 7500 names everytime you want to record a new rank (which you'll do a few thousand times each year)! Make a separate method to do this search and have it return the NameRecord once it is found, or set up your loop so that you can exit it as soon as you've found the right record.
Note that processing all of these files might take a few seconds, or even longer if something is wrong! Your program should print out when it is done loading the files and how long the loading took. Test with a small set of files, and use the debugger or print statements to trace what is going on if your program seems to be stuck.
You should think about ways you can speed up this process: for example, how could you make searching the map faster? Implementing a more efficient data structure (and so allowing for a larger number of MAX_RANKS within the same load time) is worth some extra credit!
-
At this point you should be able to instantiate a NameDatabase that includes all the data on name rankings since 1880.
- Test your program by just using a few years (say, 2003-2013) and then manually "spot-checking" that the leading names (like Emily, Madison, Jacob, and Michael) have rank values that look appropriate.
2. Drawing the Graph
The next step is to be able to draw the graph of a given name. To do this, you'll need to modify the provided NameFrame and NameGraph classes.
The NameGraph
- Your NameGraph class will need to know what NameRecord to draw. You will probably want to make a method that lets you set that.
- The provided NameGraph class already draws the axis bars for the graph. Take some time to look over this code and make sure you understand the math and geometry it is using! Remember that the y axis points down in graphics.
-
In order to draw the graph, you will need to go through each rank year, calculate where that year should show up on the graph, and then draw a line between consecutive years.
-
Calculating where to plot each data point has two parts: the x (the year) and the y (the rank).
For the x, you might notice from the previous math that each decade (10 years) is 50 pixels apart. So how many pixels apart is each year? Use this value and which "year number" (e.g, the 0th year considered, 1st year considered, etc) to figure out how far from the origin to draw your dot.
For the y, the 50 pixel "margins" at the top and bottom leave 500 pixels of vertical height. Since we have MAX_RANKS (e.g., 1000) possible ranks, it should be really easy to divide those MAX_RANKS ranks by a number so that they apply across the 500 pixels. Remember to include the 50px offset.
- Also remember that if the rank is 0, you should draw the line at the bottom of the screen, not the top!
-
Drawing the line is going to use a similar strategy to the Painter lab: start by calculating the location of the first year, storing that x and y. Then go through the rest of the years; for each year, calculate that years's (x,y), and draw a line between the previous (x,y) and the current (x,y). Then store the current (x,y) as the previous (x,y), so that the previous is updated for the next time through the loop.
-
Calculating where to plot each data point has two parts: the x (the year) and the y (the rank).
- If you want to conform to gender stereotypes, you might draw boy's names in blue and girl's names in pink (or red, which shows up better).
-
You should also draw a String next to each decade line reporting the name and rank at that particular decade, as in the sample image above.
- You can make the text smaller by setting the Font of the Graphics object.
- I recommend you "hard code" in a single name (your name?) for testing to make sure your graph is drawn, then you can add in the extra searching functionality of the NameFrame (described below).
The NameFrame
-
You will need to add a couple of control widgets to your NameFrame. These include:
-
A
JButtonto tell the program to graph a name. You know how to use these. -
A
JTextFieldto give the user a place to enter a name to graph.- You do not need to react when the user types anything into the JTextField, so no extra listeners are needed. You can get the text from the JTextField by using the (*gasp*)
getText()method.
- You do not need to react when the user types anything into the JTextField, so no extra listeners are needed. You can get the text from the JTextField by using the (*gasp*)
-
A pair of
JRadioButtonsto let the user select the sex of the name to graph.- Note that in order to have the radio buttons be "mutually exclusive" (so when you select one, the other deselects), you'll need to add them both to a ButtonGroup.
-
You can figure out if a button is currently selected using the (*drumroll*)
isSelected()method. - More details and exampels of using JRadioButtons can be found in the textbook (pg 721) and in the official Java documentation tutorial.
-
A
-
When the button is pressed, you should search your NameDatabase for the record that matches the typed in name and selected sex, and then tell the NameGraph to draw that record.
- Remember to tell the NameGraph to
repaint()so that it knows to redraw itself! - You can either erase previous lines, or draw over them.
- Remember to tell the NameGraph to
Note that as always, be sure and include plenty of comments on your classes, including full JavaDoc comments!
3. Exploring the Data
Once you have your program working, take some time to explore the data (to answer the questions in the README). There are all kinds of fun searches to do (examples from Nick Parlante):
- Type in your grandparents names. Names like Ethel and Mildred and Clarence sound old fashioned---and they are! But wait long enough and the come back. Emma! Hannah!
- Michael is very popular. To see the growing Spanish speaking influence in the US, look at Miguel. For a more recent immigration, look at Muhammad and Samir.
- Apparently Biblical old-testament names came back in the 1970's. A reaction to the 1960's maybe? Try Rachel and Rebecca. The pattern seems to generalize – Sarah, Abraham, Adam; Eve and Moses are out of luck for some reason though.
- Try historical names like Sigmund or Adolf. I was thinking Adolf would vanish in the mid 30's but it seems to vanish 10 years before that. In any case, Adolf is tricky, since there are a bunch of variant names like Adolph. Use the Search feature to find them.
- Why is Rock popular in 1950 and Trinity in 2000?
The sociology of baby naming is a really fascinating topic. Randall Munroe has a nice writeup about the Baby Name Wizard Blog which explores some of these issues, and might be a nice inspiration for searches.
Timeline
This assignment isn't as large as the previous, but there are more larger blocks of code you need to write. There are a number of moving parts and the file processing can be complicated. My advice, as always is to GET STARTED EARLY. Work on it for an hour each day and you should be okay.
- You should start by creating your NameRecord class. This is pretty straightforward (it's a simple ADT); try and do it by Fri 09/26.
- The next piece is the hardest part: the NameDatabase and the file processing. Work on this regularly, and you should have it done by Tues 09/30. If you haven't made any progress by Monday, be sure and ask for help (e.g., before or after lab).
- Drawing the graph and adding in the frame elements can take a lot of trial and error to get it looking nice, as well as time to figure out the math. If you work at it you can have that done by Fri 10/03. That leaves you the weekend to fix bugs, polish things, and complete extensions by the deadline!
Extensions
Due to time limitations, I've kept this assignment pretty basic. But there are lots of features and extensions you could add to this visualization. You can earn up to 10% extra credit by completing the extensions on this assignment--which is a good way to make up any lost points on earlier assignments if you have time! Note that these are all significantly outside the scope of the assignment.
Make sure to finish the assignment before writing extensions. If your base program doesn't work, you can't get credit for other things!
- Modify your GUI so that instead of graphing just one name, you can graph graphical names. Maybe each time the user "searches" that adds to a growing list of things on the graph (make sure you can remove things from the list as well!). Maybe you show all the results of a "search". Or maybe you just show both the male and female version of a name at once!
- Change the NameGraph so that instead of labeling the rank at each decade, it reports the rank at each "peak" or "trough" or the graph. This involves checking if a rank for a year is either less than the rank for the years on either side, or greater than the rank for the years on either side. You might even add a "threshold" so that really small changes in rank (like 2 or 3 spots) don't produce further labels.
- Modify your file parser to also collect the absolute number of babies given each name (e.g., the "4522" from the example at the top). Then modify your NameGraph so it can graph either the ranks or the absolute numbers. Note that you'll need to do some more complex math to get the graph lines to work right (for what it's worth, I believe that the highest number of babies with the same name in a given year was just under 100,000).
-
Add in some further interactions to make it easier to view the data. For example, maybe the line grows thicker when you mouse over it (to "highlight it"), or your program shows you the rank (and/or the number of babies) of a particular spot where your mouse is. This involves using a MouseListener, adjusting the draw method of the frame (and calling repaint() a lot), or using other widgets.
- Really, any further polishing of your visualization's interface--nicer colors, filling the space beneath the graph, etc--would be welcome!
- It's well outside the scope of this project (and I wouldn't try to do it in time alloted), but it could be fun to turn the graph into a stacked line chart similar to the Name Voyager (which is an absolutely amazing visualization).
Submitting
BEFORE YOU SUBMIT: make sure your code is fully documented and functional! If your code doesn't run, I can't give you credit! Your name should be in the class comment at the top of each class.
Submit your program to the Hwk3 submission folder on vhedwig, following the instructions detailed in Lab A. Make sure you upload your work to the correct folder!. You should upload your entire src folder with all your classes. Be sure to complete the provided README.txt file with details about your program.
The homework is due at midnight on Mon Oct 06.
Grading
This assignment will be graded out of 30 points:
- Functionality (22pt)
- [1pt] Your NameRecord class is a well-structured ADT, with appropriate instance variables and methods
- [1pt] Each NameRecord object stores ranking data for all years for a given name/sex
- [1pt] Your NameRecord methods throw
IllegalArgumentExceptions if a getter or setter is called with a year outside the accepted range - [2pt] Your program parses all the SSA data files in a data directory (which may be missing some years); your program should use a relative path to specify the location of this directory!
- [1pt] Your program parses each line of each file
- [1pt] Your program tracks/calculates rankings for each name
- [3pt] Your program is able to create NameRecords and/or add new rankings as they are read from the file
- [1pt] Your program prints how long it took to load the data files
- [2pt] Your NameDatabase class's public interface includes a working
getRecord()method - [3pt] Your NameGraph draws each ranking/year at an appropriate point, with a connecting line between points.
- [2pt] Your NameGraph shows a String for each decade reporting the rank of the name
- [1pt] Your NameFrame includes a textfield to enter a name
- [2pt] Your NameFrame includes RadioButtons to select the gender (one of which starts out selected)
- [1pt] Your NameFrame allows the user to search for a name, and displays the resulting graph
- Style (4pt)
- [1pt] You use constants and not "magic variables" where possible.
- [1pt] You have used appropriate and descriptive variable names
- [1pt] You use appropriate data structures inside your NameRecord and NameDatabase classes
- [1pt] You use private helper methods to break up your code when appropriate
- Documentation (4pt)
- [1pt] All methods include JavaDoc comments with appropriate JavaDoc tags (
@paramand@return). - [2pt] You have included sufficient inline comments explaining your code--both file parsing and drawing code!
- [1pt] The README is completed